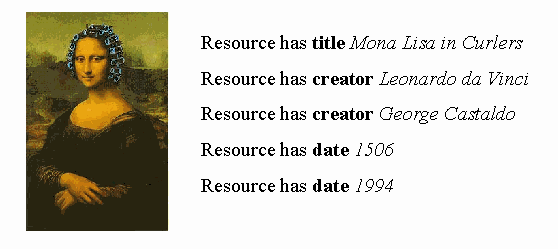| ||
D-Lib Magazine
|
|
|
Carl Lagoze |
![]()
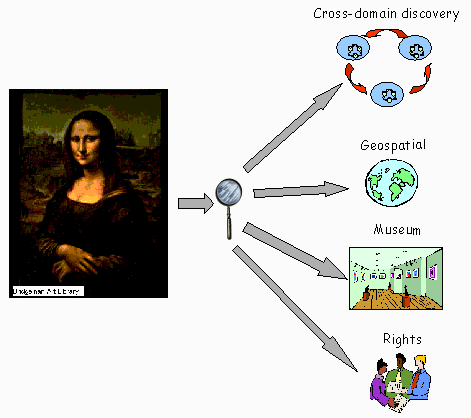
1 Order Making in the Internet CommonsReality is messy. Individuals perceive or define objects differently. Objects may change over time, morphing into new versions of their former selves or into things altogether different. A book can give rise to a translation, derivation, or edition, and these resulting objects are related in complex ways to each other and to the people and contexts in which they were created or transformed. Providing a normalized view of such a messy reality is a precondition for managing information. From the first library catalogs, through Melvil Deweys Decimal Classification system [1] in the nineteenth century, to today's MARC encoding [2] of AACR2 cataloging rules [3], libraries have epitomized the process of what David Levy calls "order making" [4], whereby catalogers impose a veneer of regularity on the natural disorder of the artifacts they encounter. The pre-digital library within which the Catalog and its standards evolved was relatively self-contained and controlled. Creating and maintaining catalog records was, and still is, the task of professionals. Today's Web, in contrast, has brought together a diversity of information management communities, with a variety of order-making standards, into what Stuart Weibel has called the Internet Commons. The sheer scale of this context has motivated a search for new ways to describe and index information. Second-generation search engines such as Google1 can yield astonishingly good search results, while tools such as ResearchIndex2 for automatic citation indexing [5] and techniques for inferring "Web communities" from constellations of hyperlinks [6] promise even better methods for focusing queries on information from authoritative sources. Such "automated digital libraries," according to Bill Arms [7], promise to radically reduce the cost of managing information. Alongside the development of such automated methods, there is increasing interest in metadata as a means of imposing pre-defined order on Web content. While the size and changeability of the Web makes professional cataloging impractical [8, 9], a minimal amount of information ordering, such as that represented by the Dublin Core (DC), may vastly improve the quality of an automatic index at low cost; indeed, recent work [10] suggests that some types of simple description may be generated with little or no human intervention. Metadata is not monolithic. Instead, it is helpful to think of metadata as multiple views that can be projected from a single information object. Such views can form the basis of customized information services, such as search engines. Multiple views -- different types of metadata associated with a Web resource -- can facilitate a "drill-down" search paradigm, whereby people start their searches at a high level and later narrow their focus using domain-specific search categories. In Figure 1, for example, Mona Lisa may be viewed from the perspective of non-specialized searchers, with categories that are valid across domains (who painted it and when?); in the context of a museum (when and how was it acquired?); in the geo-spatial context of a walking tour using mobile devices (where is it in the gallery?); and in a legal framework (who owns the rights to its reproduction?). Multiple descriptive views imply a modular approach to metadata. Modularity is the basis of metadata architectures such as the Resource Description Framework (RDF) [11, 12], which permit different communities of expertise to associate and maintain multiple metadata packages for Web resources. As noted elsewhere [13], static association of multiple metadata packages with resources is but one way of achieving modularity. Another method is to computationally derive order-making views customized to the current needs of a client. This paper examines the evolution and scope of the Dublin Core from this perspective of metadata modularization. Dublin Core began in 1995 with a specific goal and scope -- as an easy-to-create and maintain descriptive format to facilitate cross-domain resource discovery on the Web. Over the years, this goal of "simple metadata for coarse-granularity discovery" came to mix with another goal -- that of community and domain-specific resource description and its attendant complexity. A notion of "qualified Dublin Core" evolved whereby the model for simple resource discovery -- a set of simple metadata elements in a flat, document-centric model -- would form the basis of more complex descriptions by treating the values of its elements as entities with properties ("component elements") in their own right. At the time of writing, the Dublin Core Metadata Initiative (DCMI) has clarified its commitment to the simple approach. The qualification principles [22] announced in early 2000 support the use of DC elements as the basis for simple statements about resources, rather than as the foundation for more descriptive clauses. This paper takes a critical look at some of the issues that led up to this renewed commitment to simplicity. We argue that:
2 Seeing a World of Document-like ObjectsThe Dublin Core effort began in 1995 in response to a recognized need for better resource discovery tools for the Web. Early meetings resulted in the fifteen-element Dublin Core, which has since then remained relatively stable [14-20]. This core includes some elements that are reasonably consistent across domains -- such as those relating to the creation, naming, and subject of resources -- while others arguably stand on the fringe of "core-ness," such as temporal and geospatial characteristics (Coverage) and intellectual property statements (Rights Management). Criticisms of the core elements have some validity, and a "better," more consistent set is conceivable, but that is not our focus here. The original target for Dublin Core description was simple Web documents written in HTML, generically called document-like objects, or DLOs. According to early thinking, Dublin Core metadata would be embedded within Web pages as a static descriptive record complete in itself, much like the paper card in a traditional library catalog. The exact nature of DLOs was never specified and, in fact, this fuzziness is central to its nature. The essence of a DLO is simplicity in structure and lifecycle; the DLO abstraction does not address issues such as compound sub-parts (e.g., chapters, sections) nor complex inter-relationships with other resources, physical or digital. The image of stand-alone objects described by static one-stop catalog records is perhaps better suited to shelves of books than to the Web -- few Web pages are stand-alone items, especially resources such as databases and video streams. On the other hand, the DLO is useful as a simple metaphor for characterizing the variety of Web resources that form the corpus for so-called cross-domain resource discovery. Treating a cross-section of resources as uniformly simple is a useful fiction that makes it possible to: 1) make simple statements about them with uniform structure, and 2) use these statements to search across the resources in a simple and uniform manner.
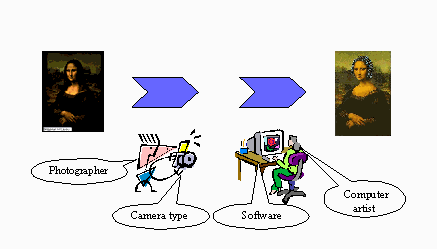
Tom Baker has characterized these simple descriptive statements as a metadata language similar to a pidgin [21]. In natural language, pidgins arise when individuals from different language backgrounds are mixed together, sometimes forcibly as in refugee communities or slave plantations. Inevitably, the members of such communities rapidly develop a simple declarative language for basic communication amongst themselves. Pidgins are also improvised by tourists who adopt a "phrase-book" language when traveling abroad (e.g., "I need a hospital" or "I want a train ticket"). Key to the simplicity of such pidgins is their limited vocabulary and basic declarative structure. Statements are generally in the present tense and lack sophisticated syntactic constructions such as subordinate clauses. For the purpose of example, consider George Castaldo's image Mona Lisa in Curlers, a modified version of Leonardo's original. This example may seem contrived, but resources that mix intellectual property in this way are common -- for example, Alfred Stieglitz's famous photograph of Daniel Burnham's Flatiron Building -- and will become more common due to the malleability of digital objects. As shown in Figure 2, this derivation is the product of several agents, tools, and events. A "complete descriptive record" for such a resource might document, for example, that a Nikon digital camera was used and that the photograph was altered using Adobe Photoshop.
Specific details such as these, however, are not particularly useful for cross-domain resource discovery, where simple statements about common attributes (e.g., title, creator, etc.) are more appropriate. Consider, for example, Figure 3, which shows the same resource, described by a set of pidgin statements using Dublin Core elements. (The metadata is represented here as statements of the general pattern "Resource has property X," where property is one of the fifteen core elements and X is a literal string value [21].) The statements would not necessarily be held in a single "Dublin Core record". Using the so-called "one-to-one rule", each of these objects -- the original painting, the digital photo, and the doctored image -- could be described in its own right, and the Dublin Core relation element would be used to characterize the relationships among these objects. But the actual containment of such statements in one "record" or in three is external to our argument here. In fact, there may be no physical record at all and such statements may be computationally derived in response to a client request. Collectively, such a collection of simple declarative sentences and the manner in which they flatten the chain of objects underlying a derivative resource constitute an excellent basis for simple resource discovery queries. They provide enough information to handle queries such as "find all resources created by Castaldo" or "find all resources created in 1506". The description is not rich enough to support a query such as "find all resources that are digitally enhanced modifications of Mona Lisa", but such specificity is arguably outside the scope of broad, cross-domain resource discovery. One can model the simple resource discovery query by extending the pidgin statement pattern with a single free variable and a query prefix: Find all rs such that r has creator George Castaldo. Such pidgin query statements can be linked using the familiar Boolean ands and ors to establish a simple resource discovery framework. We argue below that there is a need for more complex discovery frameworks tailored to specific user communities, but these need not and should not be created at the expense of this less functional but highly useful general solution. 3 Extending the Simple ModelEarly Dublin Core meetings revealed a division in the community between minimalists and structuralists. The former saw the value of Dublin Core as an agreed set of broad categories usable for simple, unadorned attribute-value metadata. The latter, in contrast, saw Dublin Core as the foundation of a richer and monolithic descriptive language -- an Esperanto of metadata. This push for greater complexity was motivated by a desire for a record format that could describe resources in the sort of detail found in a typical bibliographic database or library catalog. In 1997, it was agreed that Dublin Core could be extended and enriched with "qualifiers" that would add semantic specificity to Dublin-Core-based descriptions. We discuss below some of the problems and debates this issue has caused. Let us begin with the qualification model as it exists today. The current qualification model for Dublin Core [22] strictly limits qualification to making elements more specific in various ways -- and without adding complexity to the values, a possibility discussed below. One type of qualifier is called an "element refinement". For example, the museum community can define a painter, or the publishing industry an author, both as more specific sorts of creator. The other type of qualifier, called a "value encoding", specifies a context for interpreting the value of an element. For example, ISO8601 specifies that the value of a date is in the form 2000-12-01, and LCSH identifies the value of a subject as a member of the Library of Congress Subject Headings, a controlled vocabulary. These two forms of simple qualification are conceptually similar -- qualified forms stand in a "type of" relationship to the original element. For example, a painter is a type of creator and an ISO8601 date is a type of date. In the language model, both types of qualifier are like adjectives modifying the elements (nouns). Thus, the simple unqualified statement "Mona Lisa has creator da Vinci" might be made more specific as "Mona Lisa has painter creator da Vinci" -- an awkward-sounding but effective way of saying that da Vinci is a "painter sort of creator". Key to the interoperability of this qualification model is a principle called dumbing-down. The theory behind this principle is that consumers of metadata should be able to strip off qualifiers and return to the base form of a property. In the language model, one can picture this as "covering the adjectives" in a Dublin Core statement and reading the remaining sentence with unmodified nouns. In a world where local implementors develop their own qualifiers -- and experience shows that this is inevitable -- this principle makes it possible for client applications to ignore qualifiers in the context of more coarse-grained, cross-domain searches. For example, assume a client that harvests metadata showing that da Vinci is the painter of Mona Lisa and the author of Notebooks. If the client knows (either from the metadata itself or from a metadata schema registry on the Web) that painter and author are both specialized types of creator, then it can process searches for resources with creator "da Vinci" to yield both Mona Lisa and Notebooks. Such a query would be expressed as: Find all rs where r has property p that has value Leonardo da Vinci, where p is a qualified form of creator. This qualification model is a reasonable way to allow some extensibility of the basic model while permitting the dumbing-down that is key to maintaining the interoperability of DC as a tool for simple resource discovery. The notion is that communities make themselves understood to each other using the broad elements, while "qualifying" their statements amongst themselves. Of course, the model can be abused. Some communities may ignore principles and choose to use qualifiers that change rather than refine element semantics3. Preventing such abuse is impossible, but the DCMI has established a Usage Committee to provide guidance by judging the conformance of proposed qualifiers to general grammatical principles. 4 Stretched to the Breaking PointThis well-scoped qualification strategy emerged after some early implementors of Dublin Core experimented with using qualifiers as labels for, in effect, any relevant attributes related to a particular element. The classic case is contact information for creators, contributors, and publishers (generically, "agents"). Implementors often want to put, say, the email address, affiliation, and fax number of an author into the metadata record. If one looks to Dublin Core as a one-stop record template covering everything directly or indirectly related to a resource, then one is tempted to treat the creator element as an entity with multiple "sub-fields" or "component elements", such as creator.email, creator.affiliation, and creator.faxnumber, and to think of the labels email, affiliation, and faxnumber as "qualifiers" of creator. The problem with this model is in effect that it nests attributes within attributes -- a book HAS the creator Alison Lurie, and Alison Lurie in turn HAS the affiliation Cornell University, which in turn HAS the location Ithaca, NY -- and such constructs confound the simple statements that make "dumbing-down" easy to implement. Rather than the statement "Resource has creator Alison Lurie", we end up with statements like "Resource has creator Alison Lurie, who has affiliation Cornell University, which has location Ithaca NY". Consider the first panel of Figure 4, which shows simple metadata in HTML for a book by Alison Lurie, who is affiliated with Cornell University. The second panel shows metadata for a book by the author Gary Cornell. The third panel shows what happens if the qualifiers are ignored ("dumbed down") and the remaining tokens -- Alison Lurie and Cornell -- are indexed as values for Creator. A simple query on the creator field will yield false hits. While the problem may seem fixable for this particular example, the problem becomes intractable in the face of a huge number of records and the proliferation of such qualifiers by various communities. Designers of search engines would need to decide either to keep all qualified values -- making false hits the rule rather than the exception -- or systematically to throw them out, in effect balkanizing the corpus of Dublin Core records into "qualified" and "unqualified".
Such interpretations of the "qualification" idea have made clear that people want to be able to hang additional properties from properties -- in effect, to treat them as "nodes" or "schemas" as opposed to simple string values. How to accommodate such value complexity while maintaining the essential role of the DC as the basis of simple resource discovery? Resource Description Format (RDF), a W3C recommendation for modeling and exchanging metadata, may offer a possible solution. The RDF model [12] includes a so-called RDF:Value property for denoting the "principal value" of an entity with multiple properties. This can be used to designate a "default value" for a complex, nested value structure -- in effect offering a way to embed simple pidgin statements for resource discovery within descriptive constructs of arbitrary complexity. There are problems with this technique. While RDF offers real promise as a general model for Web metadata, it is still in a state of flux, its acceptance is far from widespread, and related software tools are rudimentary. At this point in time, it would be unwise to base general principles of Dublin Core, which should be deployable now, on particular capabilities of RDF. In the near term, the notion of a "default value" embodied in the RDF:Value idea cannot be generalized to the more common ways of recording and storing metadata in use today. Furthermore, although implementors may wish to broaden the concept of qualification to include individual "component elements" hanging off a Dublin Core element, the ability to search such complex, recursive structures is uncertain. Rather than yielding simple statements directly usable for queries, multi-attribute nodes present search applications with statements of arbitrary complexity. For example, the query "find all resources with a creator who is affiliated with an organization that is located in Ithaca, NY" multiplies the number of free variables in the query structure:Find all rs where r has property p that has value v, where p is a type of creator, where v has organization o, where o has location Ithaca, NY. Queries like this can be formulated in SQL and processed with existing relational databases. However, this off-the-shelf technology relies on structures fixed in known sets of "schemas". The Web environment, in contrast, is massively distributed, involving an arbitrary number of schemas, many of which will not be known. The querying of semi-structured and imperfectly understood data in such a diverse environment is a topic of research, not a readily deployable technology [23]. In the absence of stable representation forms and reliable query methods, encouraging the use of nested component values for Dublin Core elements risks a proliferation of non-interoperable structures that will be difficult for client applications such as search indexes to process. Rather than rushing ahead to embrace this level of complexity, we suggest adherence to the more careful approach addressed by the Dublin Core qualifier principles as they exist today. That is, we should stick to a qualification regime that is easily deployable and generalizable and resist the impulse to introduce greater complexity until its principles are understood and the tools to deploy it are stable. 5 Adding DimensionsLet us return to Mona Lisa in Curlers. Depending on institutional or application-specific requirements, a description of this object might need to include details about the related photographer, camera type, software, or computer artist. Even with the RDF:Value approach, it is not clear whether Dublin Core elements provide the best framework on which to hang such descriptive complexity. Because of the document-centric nature of Dublin Core elements, this manner of attachment models the document as "first-class" and the remaining entities (agents, events, etc.) as subsidiary to the document. Rather, the need for richer descriptions suggests a need for more expressive data models and vocabularies able to define and delimit multiple entities. The dimensions to be emphasized in such richer descriptions differ between user communities. The FRBR framework of the International Federation of Library Associations, for example, focuses on the lifecycle of intellectual content, distinguishing between abstract works, expressions of those works, manifestations of those expressions, and items produced from those manifestations [24]. The rights management community uses metadata to represent intellectual property transactions [25, 26]. The archival and record-keeping communities need detailed descriptions of process [27, 28]. Similar issues are addressed in the CIDOC/CRM standard of the museum community [29]. Our own work in the Harmony Project builds on these other efforts and argues that event-awareness is an important aspect of resource description [30, 31]. For example, the transition from work to expression implies a composing event. Making such events explicit in the metadata -- making them into first-class objects -- provides clear attachment points for attributes such as agency, dates, times, and roles. Defining such attachment points in a standard and unambiguous way makes it possible to specify the attributes of the 1994 event that added curlers to Mona Lisa. As with other experimental approaches, representing, manipulating, and querying such a model will require tools far more powerful than simple HTML META tags or existing relational databases. Such tools are currently the subject of extensive work by the RDF and XML communities in the W3C. 6 Considering the AlternativesMetadata is expensive to create -- especially the more complex varieties -- and the benefits need to be weighed against the costs. As Bill Arms suggests, simple low-cost metadata may be the most efficient strategy for addressing many resource discovery needs [32]. This has been a major consideration in the Open Archives Initiative4 (OAI) [33]. The OAI approach to metadata harvesting exemplifies the notion of metadata modularization, mandating simple Dublin Core metadata for cross-community interoperability while supporting, in parallel, community-specific metadata for "drill-down" searching within domains. The manner in which these parallel modules are used, their relative costs, and their relative functionality will become clearer over the coming year. The development of a well-scoped qualification model has defined an important niche for the Dublin Core in the larger metadata ecology. It is important to publicize this more prudent approach within the broader community, some of which has been confused over the past few years by mixed messages about Dublin Core and its scope. Equally important for the DCMI is the completion of the supporting documentation -- user guides, encoding guides, etc. -- needed to make the Dublin Core deployable with commonly available web tools. The completion of these tasks will allow the DCMI to free itself from an exclusive focus on the fifteen elements and explore, with partner communities, the roles and interaction of multiple metadata schemes in the Internet Commons. AcknowledgementsThis paper is a revised version of "Accommodating Simplicity and Complexity in Metadata: Lessons from the Dublin Core Experience", presented at the Seminar Metadata, Archiefschool, The Hague, June 8, 2000. Many thanks to Tom Baker for his advice on revisions and elaboration on the language metaphor. Support for the work in this document came from funding through NSF Grant 9905955. Notes(1) <http://www.google.com> (2) <http://citeseer.nj.nec.com/cs> (3) For example, there was discussion within one educational community to develop an audience qualifier for the coverage element. The coverage element is intended to express spatial or temporal characteristics of the subject matter of the resource. An audience qualifier, on the other hand, was meant to express the intended age or grade level of the resource; for example, a book intended for primary school readers. Audience, then, is not a "type of" coverage and its use would confound the dumbing-down principle. (4) <http://www.openarchives.org> References[1] Chan, L.M., et al., Dewey Decimal Classification: A Practical Guide. Second ed. 1996, Albany: Forest Press. [2] Furie, B., Understanding MARC Bibliographic: Machine-Readable Cataloging. 1998, Washington DC: Cataloging Distribution Office, Library of Congress. [3] Gorman, M., The concise AACR2, 1988 revision. 1989, Chicago: American Library Association. xi, 161. [4] Levy, D. "Cataloging in the Digital Order", in The Second Annual Conference on the Theory and Practice of Digital Libraries. 1995. [5] Lawrence, S., K. Bollacker, and C.L. Giles, "Digital Libraries and Autonomous Citation Indexing", in IEEE Computer, 1999. 32(6): p. 67-71. [6] Kleinberg, J., D. Gibson, and P. Raghavan. "Inferring web communities from link topology", in 9th ACM Conference on Hypertext and Hypermedia. 1998. [7] Arms, W.Y., "Automated Digital Libraries: How Effectively Can Computers Be Used for the Skilled Tasks of Professional Librarianship?" in D-Lib Magazine, 2000. 6(7/9). <http://www.dlib.org/dlib/july00/arms/07arms.html>. [8] Committee on Information Strategy for the Library of Congress, LC21: A Digital Strategy for the Library of Congress (2000). 2000, Washington, DC: National Academy Press. [9] Lagoze, C. "Business Unusual; How 'event awareness' may breathe life into the catalog", in Bicentennial Conference on Bibliographic Control in the New Millennium. 2000. Library of Congress, Washington DC. [10] Jenkins, C. and D. Inman. "Server-side Automatic Metadata Generation using Qualified Dublin Core and RDF", in Kyoto International Conference on Digital Libraries. 2000. Kyoto: IEEE. [11] Brickley, D. and R.V. Guha, "Resource Description Framework (RDF) Schema Specification". 2000, World Wide Web Consortium. <http://www.w3.org/TR/rdf-schema>. [12] Lassila, O. and R.R. Swick, Resource Description Framework: (RDF) Model and Syntax Specification. 1999, World Wide Web Consortium. <http://www.w3.org/TR/PR-rdf-syntax/>. [13] Lagoze, C., "From Static to Dynamic Surrogates: Resource Discovery in the Digital Age", in D-Lib Magazine. 1997. <http://www.dlib.org/dlib/june97/06lagoze.html>. [14] Weibel, S., "Metadata: The Foundations of Resource Description", in D-Lib Magazine, July 1995. <http://www.dlib.org/dlib/July95/07weibel.html>. [15] Weibel, S., R. Iannella, and W. Cathro, "The 4th Dublin Core Metadata Workshop Report: DC-4, March 3-5, 1997, National Library of Australia, Canberra", in D-Lib Magazine. June 1997. <http://www.dlib.org/dlib/june97/metadata/06weibel.html>. [16] Weibel, S. and E. Miller, "Image Description on the Internet: A Summary of the CNI/OCLC Image Metadata Workshop", in D-Lib Magazine. 1997. <http://www.dlib.org/dlib/january97/oclc/01weibel.html>. [17] Weibel, S.L. and C. Lagoze, "An Element Set to Support Resource Discovery: The State of the Dublin Core", in International Journal of Digital Libraries, 1997. 1(1). [18] Weibel, S., et al., "Dublin Core Metadata for Resource Discovery", 1998, Internet Engineering Task Force. ftp://ftp.isi.edu/in-notes/rfc2413.txt. [19] Weibel, S., "The Dublin Core: A simple content description format for electronic resources", in NFAIS Newsletter, 1998. 40(7): p. 117-119. [20] Dempsey, L. and S. Weibel, "The Warwick Metadata Workshop", in D-Lib Magazine, July/August 1996. <http://www.dlib.org/dlib/july96/07weibel.html>. [21] Baker, T., "A Grammar of Dublin Core", in D-Lib Magazine, 2000. 6(10). <http://www.dlib.org/dlib/october00/baker/10baker.html>. [22] Dublin Core Qualifiers. 2000, Dublin Core Metadata Initiative. [23] Abiteboul, S., P. Buneman, and D. Suciu, Data on the web: from relations to semistructured data and XML. 2000, San Francisco: Morgan Kaufmann. [24] Functional Requirements for Bibliographic Records. 1998, International Federation of Library Associations and Institutions. <http://www.ifla.org/VII/s13/frbr/frbr.pdf>. [25] INDECS Home Page: Interoperability of Data in E-Commerce Systems. [26] Rust, G. and M. Bide, The INDECS Metadata Model. 1999. <http://www.indecs.org/pdf/model3.pdf>. [27] Bearman, D. and K. Sochats, Metadata Requirements for Evidence. 1996, Archives & Museum Informatics, University of Pittsburgh, School of Information Science: Pittsburgh, PA. <http://www.lis.pitt.edu/~nhprc/BACartic.html>. [28] Bearman, D. and J. Trant, "Electronic Records Research Working Meeting May 28-30, 1997, A Report from the Archives Community", in D-Lib Magazine, 1997. <http://www.dlib.org/dlib/july97/07bearman.html>. [29] ICOM/CIDOC Documentation Standards Group, CIDOC Conceptual Reference Model. 1998, International Council of Museums. [30] Lagoze, C., J. Hunter, and D. Brickley. "An Event-Aware Model for Metadata Interoperability", in ECDL 2000. 2000. Lisbon. [31] Brickley, D., J. Hunter, and C. Lagoze, ABC: A Logical Model for Metadata Interoperability. 1999, Harmony Project. <http://www.ilrt.bris.ac.uk/discovery/harmony/docs/abc/abc_draft.html>. [32] Arms, W.Y., Digital libraries. Digital libraries and electronic publishing. 2000, Cambridge, MA: MIT Press. [33] Van de Sompel, H. and C. Lagoze, "The Santa Fe Convention of the Open Archives Initiative", in D-Lib Magazine. 2000. 6(2). <http://www.dlib.org/dlib/february00/vandesompel-oai/02vandesompel-oai.html>. (Corrected coding in link in the References section 8/31/05.) Copyright© 2001 Carl Lagoze |
|
|
Top
| Contents |
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/january2001-lagoze
|