D-Lib Magazine
September/October 2016
Volume 22, Number 9/10
Table of Contents
Temporal Properties of Recurring In-text References
Iana Atanassova
Centre Tesnière, Université de Bourgogne Franche-Comté, France
iana.atanassova@univ-fcomte.fr
Marc Bertin
Centre Interuniversitaire de Rercherche sur la Science et la Technologie (CIRST), Université du
Québec à Montréal (UQAM)
bertin.marc@gmail.com
DOI: 10.1045/september2016-atanassova
Printer-friendly Version
Abstract
In this paper we study the properties of recurring in-text references in research articles and more specifically their positions in the rhetorical structure of articles and their age with respect to the citing article. We have processed a large scale corpus of approximately 80,000 papers published by PLOS (Public Library of Science). We examine the number and types of recurring in-text references, as well as their age according to positions in the IMRaD structure. (Introduction, Methods, Results, and Discussion). The results show that the age of recurring references varies considerably in all sections and journals. While they are especially dense in the Introduction section, most of them reappear in the beginning of the Results and the Discussion sections. We also observe that the beginning of the Methods and the Results sections share a significant number of recurring references.
Keywords: Bibliometrics; Information Extraction; IMRaD; Context of Citations; In-text References; Recurring Citations; Recurring In-text References
1 Introduction
In a scientific paper, the same work can be cited several times. To study this phenomenon of recurring references it is necessary to access and analyse the full text of papers, not only the bibliographic data. This study aimed to uncover some of the complexities of the relation between cited papers and citing papers by examining the age of recurring in-text references.
In recent years, the efforts in the field of bibliometrics have turned to the content of scientific articles. The study citation contexts takes on a new dimension by using approaches from the field of Natural Language Processing, and taking into account the full text of scientific papers. From a bibliometric point of view, the structure of scientific papers is of particular interest, especially the study of citation contexts. Indeed, full text analysis citation contexts can establish a link between the in-text references and the elements of the bibliography with the promise of bringing modality or semantic categories to allow the fine-tuning of bibliometric studies.
1.1 Background
Access to the full text of scientific papers has enabled many new projects and studies. Projects involving in-text references are of particular interest in the field of Bibliometrics. Two type of studies have been developed in this domain. The first type involves study of the phenomenon of in-text references in articles, primarily in the IMRaD (Introduction, Methods, Results, and Discussion) structure [2, 3, 5]. The second focuses on the study of citation contexts. For example, we can cite the analysis of verbal forms present in the context of citations (see [1]). A third dimension that remains to be examined is the phenomenon of recurring in-text references.
The major objective of this work is to provide the experimental grounds to lay the foundations of a theory of citation [4].
1.2 Research Problem
We consider recurring in-text references, i.e. works that are cited more than once in the same article. Such references are interesting from a bibliometric point of view because we can assume that references that are cited several times are more important than references cited only once.
The problem of the development of indicators around recurring in-text references has already been raised by Moed. His observations expand upon the works of Pinski and Narin (see [10]) who developed the idea that citations could have different weights. Moed emphasizes in his book (see [9, p. 311]) that:
"a recurrent citation measure would not a priori count a citation as 'one', but rather assign a weight to the citation, based on the number of times the citing document was itself cited. [...] The potentialities and limitations of recurrent citation impact indicators need to be thoroughly assessed."
Regarding the studies on the recurrence of In-text References, few results exist, as far as we know [7]. The recurring in-text references may be considered, as described in Zhao and Strotmann [12]:
"as a large sub-class of the class of in-text frequency weighted citation analysis schemes."
According to recent works around citation analysis, identifying recurring in-text references plays a role in the categorization of citations. In fact, recurring in-text references can be considered as a subclass of in-text references, and this approach can have implications for co-citation networks [6, 11] and information retrieval. Moreover, finding the reason for the presence of recurring references to a work in the different rhetorical sections of a paper is an important step in the understanding the construction of scientific discourse.
2 Method
The objective of our study is to determine the locations where recurring in-text references appear in the rhetorical structure of scientific articles. We examine the IMRaD structure, which is widely used in experimental sciences. We want to identify the positions in the IMRaD structure where sentences recurring in-text references are most likely to appear.
2.1 Dataset
We analysed a dataset of seven peer-reviewed academic journals published in Open Access by PLOS (Public Library of Science). Six of the journals are domain-specific (PLOS Biology, PLOS Computational Biology, PLOS Genetics, PLOS Medicine, PLOS Neglected Tropical Diseases, PLOS Pathogens) and the seventh is PLOS ONE, which is a general journal that covers all fields of science and the social sciences. We processed the entire dataset of approximately 80,000 research articles in full text published up to September 2013.
The dataset is in the XML JATS format, where the body of the articles consists of sections and paragraphs that are identified as distinct XML elements. The in-text references are also, for the most part, present as XML elements and linked to the corresponding elements in the bibliography of the article.
2.2 Processing
After parsing the documents, we identified all in-text references and their corresponding bibliography items. This process involved three different steps:
- identification of all xref elements in the XML documents that represent in-text references;
- full-text processing of the articles in order to identify any in-text references that were missed by the first step. In fact, a few of the in-text references in the PLOS corpus are not present as XML elements but exist in the text of the articles;
- identification of in-text reference ranges (e.g. '[4]-[7]') that are always rendered by two xref elements in the XML structure. We identified the 'implicit' citations and established the missing links with the corresponding bibliography items.
The IMRaD structure is used in the great majority of articles in the corpus. However, the four different sections, while present in an article, do not always appear in the same order. We performed an analysis of the section titles in order to classify them according to the four main section types. Thus, we were able to identify the exact position of each in-text reference within the IMRaD structure: the section in which the reference appears and its position in the section, expressed as a percentage of the text progression of the section. In the calculation of the positions of references we consider sentences as the basic unit to model text progression. This approach has already been used by Bertin et al. [3] who examine the overall distribution of references along the text progression.
To each recurring in-text reference we attribute a two-letter code (e.g. "IM", "RR", "MD") which stands for the two sections where the reference appears in the paper. If the reference has more than two occurrences, we attribute to it one two-letter combination for each of the couples of sections where it appears. We note with Rn the number of recurring in-text references that have n occurrences in an article, where n = 2; 3; 4; ...
To examine the temporal properties of in-text references, and in particular their age with respect to the citing paper, we calculate the difference between the publication year of the citing paper and the cited paper. We obtain as a result a non-negative number that we call age of the in-text reference. This characteristic allows us to study the question whether recurring in-text references cite works that are recent or not, and whether there are differences in this respect between the sections in the IMRaD structure.
3 Results
3.1 Number and Types of Recurring In-text References
If we consider the number of times that each reference appears in an article, we observe that references with two occurrences are the most numerous. While this result is not surprising in itself, the analysis of this phenomenon for the seven journals in the corpus has allowed us to observe the following tendency: the ratio between the number of references with two occurrences (R2) and those with three occurrences (R3) is almost the same in all seven journals: R2/R3 ≈ 2:8 with an error of less than 0.15. The same goes for R3/R4 ≈ 2:2, which is true with an error of less than 0.2, etc. The curves that we obtain are of the same nature as that described by Zipf [13].
Overall, we observe that Rn/Rn+1 ≈ cn with an error of less than 0.2 where cn is a constant for n = 2; 3; ..., 9.
Figure 1 presents the average number of recurring in-text references per article in the seven PLOS journals. The intensity of the color expresses the number of occurrences of the in-text references, from two to nine. References to more than nine occurrences were not considered, as they account for less than 1% of all in-text references in the corpus. This figure shows some significant differences between the journals, e.g. the journals PLOS Pathogens, PLOS Genetics and PLOS Computational Biology tend to have many more recurring citations that the four other journals.
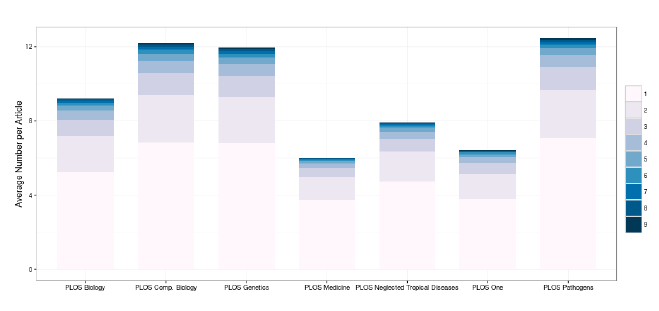
Figure 1: Recurring In-text References in the PLOS Journals
3.2 Age of In-text References
Considering the age of in-text references, our objective is to identify some new properties of the IMRaD structure. The main question is whether the different sections in an article display some specific behavior with respect to the age of recurring in-text references that appear in them.
Figure 2 presents the age of recurring in-text references for each couple of sections of the IMRaD structure. The vertical axis gives the age of the in-text references. The first four columns ("II", "MM", "RR" and "DD") account for recurring in-text references that occur in the same section. The rest of the columns show the recurring in-text references that occur in two different sections.
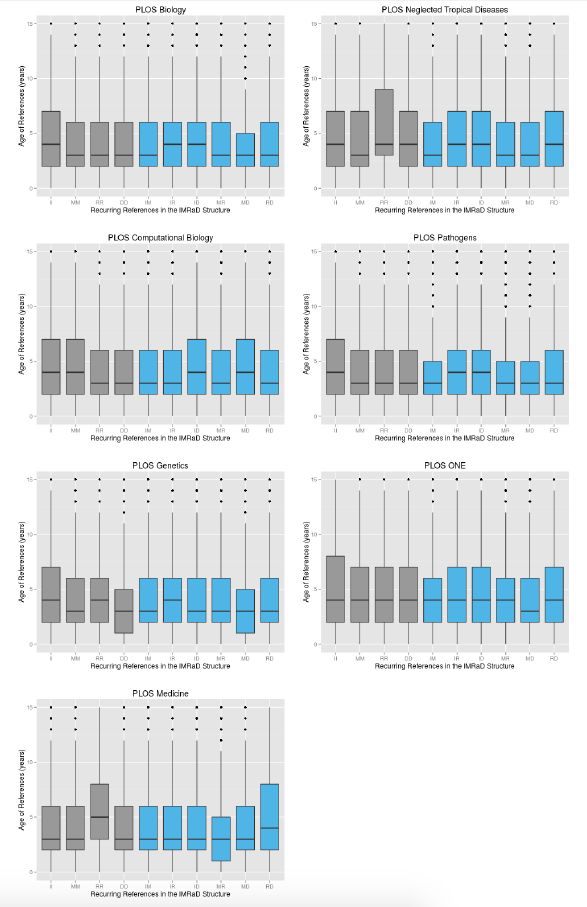
Figure 2: Age of In-text References
These results show that the age of the references varies considerably in all sections and journals. While there is no specific trend that can be observed, certain sections stand out in some of the journals. For example, the column "RR" for PLOS Medicine and PLOS Neglected Tropical Diseases show a clear tendency to cite older works in the Results section in these two journals. We also note that in the five other journals, the "II" column seems to have more dispersion, which is consistent with the idea that the Introduction section often contains a discussion of the "state of the art", and therefore wider variety of references than the rest of the sections.
3.3 Distribution of Recurring In-text References
Figure 3 shows a visualization of the recurring in-text references in the journal PLOS Biology. This visualization was obtained by using the CIRCOS application [8]. The circle represents the text progression along the IMRaD structure and the histogram in grey represent the density of in-text references in the text (single or recurring in-text references). The four sections are of different sizes that correspond to their average relative size as observed in the corpus. We have represented in red, outside the histogram, the recurring in-text references that occur in the same section, and in blue the recurring in-text references that occur in different sections. Each recurring in-text reference is given by a link between two positions in the circle that correspond to its position in the text progression of the article.
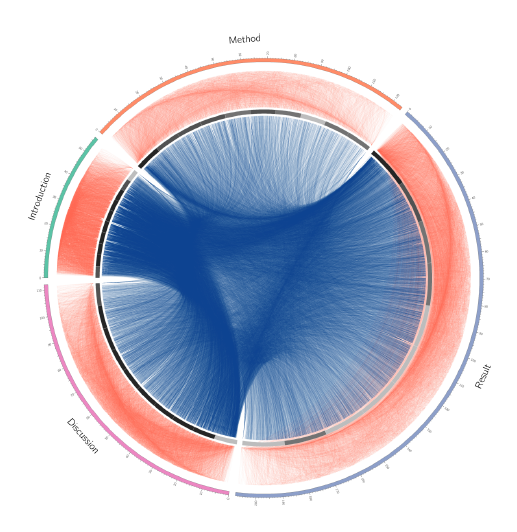
Figure 3: Recurring In-text References for PLOS Biology
This representation shows several new phenomena:
- The recurring in-text references are very dense in the Introduction section, and most of them reappear in the beginning of the Results and the beginning of the Discussion sections.
- The beginning of the Methods section and the beginning of the Results section share a significant number of recurring in-text references. The same goes for the beginning of the Results and Discussion sections.
- The recurring in-text references that occur only in the Methods and only in the Results sections are more numerous at the beginning of these sections than at the end.
The representation of scientific articles in a circular form seems particularly appropriate for this kind of study because the Introduction and the Discussion sections are next to each other. As we see in Figure 3, the Discussion section is strongly related to the Introduction section by a large number of common in-text references that appear all along the Introduction and especially in the beginning of the Discussion section.
4 Conclusion
This study confirms some preliminary results proposed by [7] who examined 350 papers from Journal of Infometrics. The behavior of the distribution of the occurrences of in-text references is confirmed by our study which was performed on a large-scale corpus of 80,000 papers. This allows us to highlight a singular phenomenon, that is the number variation of the recurring in-text references according to the number of occurrences (see Section 3.1).
This study also shows the relationship between the number of occurrences of in-text references and their age in the different journals with respect to the positions in the IMRaD structure.
Acknowledgements
We thank Benoit Macaluso of the Observatoire des Sciences et des Technologies (OST), Montreal, Canada, for harvesting and providing the PLOS data set.
References
| [1] |
M. Bertin and I. Atanassova. A study of lexical distribution in citation contexts through the IMRaD standard. In Proceedings of the First Workshop on Bibliometric-enhanced Information Retrieval co-located with 36th European Conference on Information Retrieval (ECIR 2014), pages 5-12, Amsterdam, The Netherlands, 13 April 2014. |
| [2] |
M. Bertin, I. Atanassova, V. Larivière, and Y. Gingras. The distribution of references in scientific articles: an analysis of the IMRaD structure. In Proceedings of ISSI 2013 Vienna: 14th International Society of Scientometrics and Informatics Conference, Vienna, Austria, 15-19th July 2013. International Society for Scientometrics and Infometrics. |
| [3] |
M. Bertin, I. Atanassova, V. Larivière, and Y. Gingras. The invariant distribution of references in scientific papers. Journal of the Association for Information Science and Technology, 67(1):164-177, January 2016. http://doi.org/10.1108/eb026703 |
| [4] |
B. Cronin. The need for a theory of citing. Journal of Documentation, 37(1):16-24, 1981. http://doi.org/10.1108/eb026703 |
| [5] |
Y. Ding, X. Liu, C. Guo, and B. Cronin. The distribution of references across texts: Some implications for citation analysis. Journal of Informetrics, 7(3):583-592, 2013. http://doi.org/10.1016/j.joi.2013.03.003 |
| [6] |
L. Egghe and R. Rousseau. Co-citation, bibliographic coupling and a characterization of lattice citation networks. Scientometrics, 55(3):349-361, 2002. http://doi.org/10.1023/A:1020458612014 |
| [7] |
Z. Hu, C. Chen, and Z. Liu. The recurrence of citations within a scientific article. In A. Salah,
A. Tonta, C. Akdag Salah, and U. A. Sugimoto, editors, Proceedings of ISSI 2015 Istanbul: 15th International Society of Scientometrics and Informetrics Conference, Bogazici University Printhouse, Istanbul, Turkey, 29 June to 3 July 2015. International Society for Scientometrics and Infometrics. |
| [8] |
M. Krzywinski, J. Schein, I. Birol, J. Connors, R. Gascoyne, D. Horsman, S. J. Jones, and M. A.
Marra. Circos: an information aesthetic for comparative genomics. Genome Research, 19(9):1639-1645, 2009. http://doi.org/10.1101/gr.092759.109 |
| [9] |
H.-F. Moed. Citation Analysis in Research Evaluation. Information Science and Knowledge Management. Springer Netherlands, 2006. http://doi.org/10.1007/1-4020-3714-7 |
| [10] |
G. Pinski and F. Narin. Citation influence for journal aggregates of scientific publications: Theory, with application to the literature of physics. Information Processing & Management, 12(5):297-312, 1976. http://doi.org/10.1016/0306-4573(76)90048-0 |
| [11] |
H. Small. Co-citation in the scientific literature: A new measure of the relationship between two
documents. Journal of the American Society for Information Science, 24(4):265-269, 1973. http://doi.org/10.1002/asi.4630240406 |
| [12] |
D. Zhao and A. Strotmann. Re-citation analysis: Promising for research evaluation, knowledge network analysis, knowledge representation and information retrieval? In 15th International Society of Scientometrics and Informatics Conference, pages 1061-1065, Bogazici University Printhouse, Istanbul, Turkey, June 29 to July 3 2015. International Society for Scientometrics and Infometrics. |
| [13] |
G. K. Zipf. Human behavior and the principle of least effort. Cambridge, (Mass.): Addison-Wesley, 1949, pp. 573. http://dx.doi.org/10.1002/1097-4679(195007)6:3<306::AID-JCLP2270060331>3.0.CO;2-7
|
About the Authors
Iana Atanassova is associate professor at the Research Centre Lucien Tesnière for Linguistics and Natural Language Processing at the Université de Bourgogne Franche-Comté in France. In 2015 she completed her Habilitation to Direct Research (Habilitation à Diriger des Recherches) in Natural Language Processing at the Université de Franche-Comté titled "Analysis of Scientific Discourse: Applications in Information Retrieval, Information Extraction and Semantic Web". She completed her PhD thesis with honors in the field of Semantic Information Retrieval at Paris-Sorbonne University. She has worked in industry as R&D project manager with the mission of developing a large-scale semantic search engine for open access scientific publications. Her research interests are in the fields of information extraction and semantic information retrieval, semantic annotation using knowledge-based methods and machine-learning, multi-lingual automatic text processing.
Marc Bertin is currently assistant professor at University of Toulouse, France, and associate researcher at the Université du Québec à Montréal, Canada. He obtained his PhD with the highest level of distinction in Mathematics, Computer Science and Applications in Social Sciences at Paris-Sorbonne University. Prior to this, he worked on IT solutions for the Japanese pharmaceutical industry and the National Center for Scientific Research in France. He teaches artificial intelligence, computer sciences, information science and linguistics. His research interests include semantic annotation, artificial intelligence and knowledge extraction applied to information retrieval and digital libraries.