|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Ralph R. LeVan Thomas B. Hickey Jenny Toves |
![]()
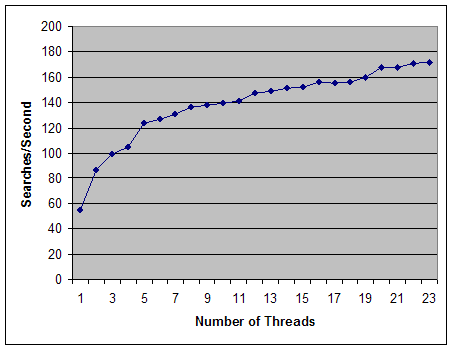
IntroductionWhile the news is full of reports of the success of the Internet search engines at searching billions of web pages at prices so low that they can afford to give the searching away for free, such affordable searching is not common in the rest of the world. What searching is available in the rest of the world is not scalable, not cheap or not fast. Often it suffers from a combination of those flaws. This article describes our experience building a scalable, relatively inexpensive, and fast searching framework that demonstrated 172 searches per second on a database of 50 million records. The article should be of interest to anyone seeking an inexpensive, open source, text-searching framework that scales to extremely large databases. The technology described uses the SRW (Search/Retrieve Web) service in a manner nearly identical to federated searching in the metasearch community and should be of interest to anyone doing federated searching. What problem were we trying to solve?OCLC [1] maintains a database (WorldCat [2]) of 50 million bibliographic records that grows at a rate of 3 million records per year. OCLC provides a search service (FirstSearch [3]) that makes available both browser and Z39.50 [4] access to the WorldCat database. Typical search loads average 5 searches per second with peak loads at 16 searches per second. This service currently runs on IBM WinterHawk computers using Oracle Text [5] for searching. We wanted to know if it was technically feasible to run such a service on cheaper hardware using open source software. The goal was to demonstrate 100 searches per second on this framework. We chose to partition our large database into a number of smaller databases and use federated searching techniques to search across the databases with a Beowulf cluster [6] as our hardware platform. A Beowulf cluster is a collection of commodity CPU's connected by a high-speed network switch running an open source operating system. (We were interested in Beowulf cluster technology for a range of experiments within OCLC Research, not just for this one experiment.) Our cluster consists of 24 nodes with 2 Intel Xeon 2.8 GHz CPU's per node with 4GB of memory. The root node has 130GB of disk shared via NFS [7]. The 23 application nodes have 80GB of disk per node. The network switch was a 48-port Cisco Catalyst 4850 switch with all internal ports at gigabit speed. Each node has 2 gigabit Ethernet connections. The cluster runs the Linux [8] operating system and the Rocks [9] cluster management software. Clusters like this now cost less than $100,000. The partitioning schemeThe cluster configuration (1 root node and 23 application nodes) led to our partitioning scheme. Since each application node had 2 processors and the processors were running hyperthreading (theoretically supporting 2 processes per CPU), we concluded that we could run 4 processes on each application node. We wanted to reserve one process for hypothetical redundancy planning, so that left 3 processes per node or 69 processes for the entire cluster. Since each partition was to get its own searching process, the database was divided into 69 partitions. When we return results from a search, we order the results by the popularity of the items described by the bibliographic records in the database. We are able to assign a popularity score to the items because we know which of our member libraries hold those items. (We call the score the "holdings count".) We did not want to have to sort the search results across the 69 partitions, so we chose to partition the database by the popularity of the items, putting the most popular items into the first partitions, and so on. With that scheme, we only need to sort the item records within the partition and can have the sorting done on the application nodes, instead of having to collect all the results on the root node and doing the sorting there. 50M records divided across 69 partitions leads to a partition size of approximately 725K records. The most popular 725K items are held by 264 or more libraries. (The most popular item, Time Magazine, is held by 6,349 libraries.) The next partition consists of records for items held by 140-263 libraries. The partitioning continues in this manner until we get to the 1.2M items held by seven libraries. This number is much larger than the 725K records we had planned for each partition. When we get to items held by a single library, we find nearly 21M records. The large partitions are further subpartitioned in pieces of equal size near the 725K record goal. The subpartitioning scheme is arbitrary, based on internal record number. The 69 partitions are sequentially assigned to the application nodes, three partitions per node. Problems with disk architecture and partitioningIn the best of all worlds, we would have moved the complete 41GB of MARC-21 data and 4GB of associated holdings information onto the Beowulf cluster and would have done the partitioning there. Unfortunately, there are problems with trying to move that much data in one transaction. Expecting the applications responsible for moving the data to perform flawlessly over the necessary hours is unreasonable; something – either hardware or software – is likely to fail. Using zip technology to compress the data reduces the transmission time, but zip has problems with files that large. Since the files needed to be broken down in chunks smaller than 2GB for zip, we decided to do the partitioning on the data's host computer and then zip the partitions. Once the data was on our Beowulf cluster, we could begin experimenting with the multi-processing features of the system. Would it be better to have the root node unzip the 69 files, or have the application nodes each unzip their three files? It took the root node 29 minutes to unzip the 69 files. Next, we had the application nodes unzip the files where they resided on the root node. After 2 hours, we cancelled the jobs. Finally, we copied the zipped files to the disks attached to the application nodes and had the application nodes unzip them there. It took 14 minutes to copy the files sequentially and 9 minutes to unzip them in parallel. We tried having the application nodes copy the files in parallel; this took 55 minutes. Clearly, disk contention is a problem on the NFS-mounted disks on the root node for this type of operation. The database technologyOCLC Research has developed open source database software that consists of two modules: the search engine (Gwen [10]) and the database building software (Pears [11]). Gwen and Pears have been used by OCLC Research for several years, and they are also used in some of OCLC's commercial products. Pears, running under a different search engine, is also used by the Open Source SiteSearch [12] community. This software has been used to support monolithic versions of the WorldCat database and should be more than adequate for searching a database one sixty-ninth that size. The question remained as to what federating technology to use. OCLC Research has considerable experience with Z39.50, which has been in use for nearly a decade to support federated searching in the Library community. But, a Web-Service-based alternative to Z39.50 has recently been developed: SRW [13] (Search and Retrieve on the Web). Our experience with both protocols leads us to believe that SRW is much easier to understand and implement than Z39.50, but retains all the functionality necessary to support federated searching. Our open source implementation of an SRW server [14] includes an abstract database interface with implementations for both Pears and Gwen, and for Jakarta Lucene [15] as used by the open source digital archive, DSpace [16]. Our SRW server is built using the Apache Axis [17] Web Service toolkit, and we run it under the Apache Tomcat [18] servlet engine. Pears, Gwen and the SRW server are all 100% Java. The searching architectureThe partitions are made searchable via the SRW and SRU (Search and Retrieve URL) search protocols. SRW is a Web Service based on SOAP [19] with functionality closely based on that provided by the Search and Present services of Z39.50. SRU provides the same functionality as SRW, but with a REST [20] model instead of SOAP. With SRU, all the request parameters, including the query, are embedded in the URL. Our SRW/U service is implemented using the Apache Axis toolkit and runs under Apache Tomcat. To provide the service, there is a single copy of Tomcat running on each application node. The SRW/U service is configured to know about the three partitions on each node. Each partition is searchable at a different base URL (e.g., the first partition on application node 0-0 had a base URL of http://app-0-0:8080/SRW/Search/Partition1.) We considered running a separate Tomcat server for each partition, but decided that Tomcat would run each search of each partition on a separate thread and that Linux would see to it that the threads got spread across the available CPU's. We used two sets of searches for our testing. The full set of searches was extracted from our logs from one day's searching of our WorldCat database in our FirstSearch service. The logs were filtered to remove date range and truncated searches. (The filtering was done to support other searching experiments, and we didn't think it would affect our results with the experiment described in this article.) The second set of searches consisted of 1,000 searches randomly selected from the 37,000 searches in the full set. We wrote a client to read the searches from a file and send the queries to the partitions. The actual sending and receiving of messages to a particular partition happened on separate threads. We would extract the document counts from the responses from each partition. Those counts would be summed and reported in the client's log. A sampling of those counts was manually checked for accuracy, and the results of subsequent runs of the client were compared with the validated results. An SRW clientThe first client architecture was quite trivial. A search was read from an input file and passed to each of 69 threads that would process the search for one of the 69 partitions. Each thread would generate an SRW request using code generated by the Apache Axis SOAP toolkit from the SRW WSDL (Web Services Description Language). The threads then extracted the document count from the response. The counts from the threads were summed and the total count was reported. Average response time for the 1,000-search test was 437ms, or slightly more than 2 searches per second. This was far from our 100 searches per second goal. We used two tools during our testing. The first tool was the client software itself, which reported each query, search results, and the response time for the search. In addition, the client software reported the average response time for the entire run, and the fastest and slowest searches. The second tool was the Ganglia Cluster Toolkit [21]. This toolkit generates a dynamic web page that allows the user to monitor the activity of the cluster. While it can produce detailed information on the memory, disk, network and CPU activity of each node, and for the cluster as a whole, we primarily used their cluster summary page. On that page, a graph of overall activity over the last hour for each node was provided. The background color for the graph also indicated the immediate activity for the node, with colors ranging from blue (barely active) to red (very active). While running the SRW client test, we noticed that the root node for the cluster, where the client was running, was red on the Ganglia page, and all the search nodes were blue. This indicated to us that the client software might be the bottleneck preventing faster searches. We understood that the process of serializing Java objects into XML and back that the Apache Axis toolkit performed was not an inexpensive one. When we also considered that the client was doing this 69 times for each search, we weren't surprised that the SRW client had become a bottleneck. An SRU clientWe next modified the client to use SRU instead of SRW. This simply entailed appending a few SRU parameters to the same base URL that we had used for SRW and then appending the query. The response was still the same XML record that was returned by SRW, but instead of parsing it, we just scanned it for the string marking the postings count and extracted that count from the record. This work was still being done in 69 threads, one for each partition of the database. Response time dropped by a factor of 10, to 40ms per search, but, the Ganglia page still indicated that the client was a bottleneck. SRW revisitedWe then made a final attempt to use SRW. Instead of using the Apache Axis toolkit to encode and decode the SOAP messages, the messages were constructed by hand and sent to the server. The responses were scanned for the postings count as in the SRU client. Response time had dropped to 46ms per search – much better, but still not nearly as good as when we used the simpler SRU code. We made no further attempts to improve the SRW code. 23 databases are better than 69The Ganglia page seemed to indicate that the client itself was the reason faster searching wasn't possible. We decided to reduce the number of threads that the client needed from 69 to 23, which reduced the work of the client by two-thirds. To compensate for this change in the client, small database federators were created for the application nodes. A single SRW database was created that acted as a gateway to the three local databases and aggregated the results of the searches on those partitions. Using the new database architecture, SRU client searches dropped from 40ms to 14ms per search. The hand-built SRW client went from 46ms to 30ms per search. Finally, the original SRW client went from 445ms to 164ms per search. 14ms per search results in an overall throughput of 71 searches per second, which was not yet at our goal of 100 searches per second. In addition, while some of the search nodes were showing as yellow on the Ganglia page, the root node was still red, and most of the application nodes were only green. Clearly, the client continued to do too much of the work, and not enough was being done by the application nodes. Moving the aggregation to the application nodesTo address the problem of the client doing too much work, we created a new kind of SRW database. This database aggregated the results of searches sent to remote databases, unlike the previous aggregating database that searched local databases. This new database solved two problems: when run on the root node, it provided a single database for web browsers to use to search the entire WorldCat database with 15ms response time; when run on the application nodes, it provided 23 possible servers to which a client might send WorldCat searches. We then created a new client to take advantage of these new databases. The client still read searches from a file, but it gave those searches to an SRU client running on a thread that sent the search to a remote WorldCat database. The main client did not wait for the response from the SRU client. Instead, it read another search and waited for an available SRU client to give the search to. Overall searching throughput was measured by the main client by recording the start and end times for the run and dividing that into the number of searches performed, resulting in an overall number of searches per second. Experiments were performed with differing numbers of SRU clients. The complete results are displayed in Figure 1 below. The significant result was the achievement of an overall search throughput of 172 searches per second. During the tests that produced this final result, the Ganglia page showed all the nodes red.
Status of developmentAs of this writing, there are no plans to use this code in production at OCLC. As a result, there are a number of features left undeveloped in this framework. No provision was made for Fault Tolerance. Fault Tolerance can be achieved by duplicating the partitions on multiple nodes and configuring 23-way aggregators that use the different combinations of partitions. While record retrieval across the federated database is complete, sorting and ranking remains to be done. This work can be primarily done at the partition level and the aggregators can simply merge the results. While the system is incomplete, all the open source code described in this article, including the fully functional SRW server and databases, and the Pears/Gwen database, are available from OCLC Research [22]. ConclusionsThere is reason to be concerned about the efficiency of SRW and SOAP-based Web Services as opposed to SRU and REST-style services, at least in high-throughput multi-threaded clients. The goal of this project was to demonstrate 100 searches per second on a large database using relatively inexpensive hardware. In the end, we demonstrated 172 searches per second. The framework scales easily by adding more nodes to the system. References1. OCLC Online Computer Library Center, Inc. <http://www.oclc.org/>. 2. WorldCat, <http://www.oclc.org/worldcat/>. 3. FirstSearch, <http://www.oclc.org/firstsearch/>. 4. Z39.50, <http://www.loc.gov/z3950/agency/>. 5. Oracle Text, <http://www.oracle.com/technology/products/text/index.html>. 6. Beowulf cluster, <http://www.beowulf.org/overview/index.html>. 7. NFS, <http://www.webopedia.com/TERM/N/NFS.html>. 8. Linux, <http://www.linux.org/>. 9. Rocks, <http://www.rocksclusters.org/Rocks/>. 10. Gwen, <http://www.oclc.org/research/software/gwen/>. 11. Pears, <http://www.oclc.org/research/software/pears/>. 12. Open Source SiteSearch, <http://opensitesearch.sourceforge.net/>. 13. SRW, <http://www.loc.gov/z3950/agency/zing/srw/>. 14. SRW server, <http://www.oclc.org/research/software/srw/default.htm>. 15. Jakarta Lucene, <http://lucene.apache.org/java/docs/index.html>. 16. DSpace, <http://www.dspace.org/>. 17. Apache Axis, <http://ws.apache.org/axis/>. 18. Apache Tomcat, <http://jakarta.apache.org/tomcat/>. 19. SOAP, <http://www.webopedia.com/TERM/S/SOAP.html>. 20. REST, <http://www.webopedia.com/TERM/R/REST.html>. 21. Ganglia Cluster Toolkit, <http://ganglia.sourceforge.net/>. 22. Open Source from OCLC Research, <http://www.oclc.org/research/software/>. Copyright © 2005 OCLC Online Computer Library Center, Inc. |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2005-levan
|