|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
David Bearman and Jennifer Trant With Susan Chun, Michael Jenkins, and Koven Smith (The Metropolitan Museum of Art), Rich Cherry, Tom Leonhardt, and Danielle Uchitelle (Guggenheim Museum), Doug Hiwiller (The Cleveland Museum of Art), Willy Lee (The Minneapolis Institute of Arts), Bruce Wyman (Denver Art Museum), Ray Shah (Think Design), Bryan Gawronski (Albright Knox Art Gallery), and Matt Morgan (Brooklyn Museum) |
![]()
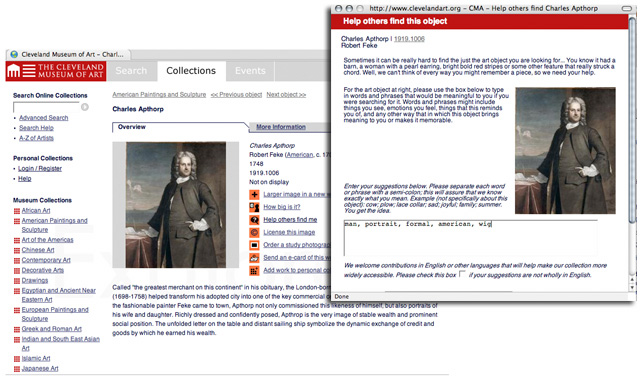
Collaborative Annotations: Tagging Art?BackgroundFrom their earliest encounters with the Web, museums have seen an opportunity to move beyond uni-directional communication into an environment that engages their users and reflects a multiplicity of perspectives. Shedding the "Unassailable Voice" (Walsh 1997) in favor of many "Points of View" (Sledge 1995) has challenged traditional museum approaches to the creation and delivery of content. Novel approaches are required in order to develop and sustain user engagement (Durbin 2004). New models of exhibit creation that democratize the curatorial functions of object selection and interpretation offer one way of opening up the museum (Coldicutt and Streten 2005). Another is to use the museum as a forum and focus for community story-telling (Howard, Pratty et al. 2005). Unfortunately, museum collections remain relatively inaccessible even when 'made available' through searchable on-line databases. Museum documentation seldom satisfies the on-line access needs of the broad public, both because it is written using professional terminology and because it may not address what is important to – or remembered by – the museum visitor. For example, an exhibition now on-line at The Metropolitan Museum of Art acknowledges "Coco" Chanel only in the brief, textual introduction (The Metropolitan Museum of Art 2005a). All of the images of her delightful fashion designs are attributed to "Gabrielle Chanel" (The Metropolitan Museum of Art 2005a). Interfaces that organize collections along axes of time or place – such of that of the Timeline of Art History (The Metropolitan Museum of Art 2005e) – often fail to match users' world-views, despite the care that went into their structuring or their significant pedagogical utility. Critically, as professionals working with art museums we realize that when cataloguers and curators describe works of art, they usually do not include the "subject" of the image itself. Simply put, we rarely answer the question "What is it a picture of?" [1] Unfortunately, visitors will often remember a work based on its visual characteristics, only to find that Web-based searches for any of the things they recall do not produce results. ObjectivesWe recognize that we may be alienating a user community, by not speaking their language or meeting their needs. But adding subject indexing to images in museum documentation cannot be a project of museum staff alone. The costs of retrospectively indexing huge collections is a barrier [2], but more fundamentally, professionals cannot easily shed their experience as museum staff to adopt a vernacular view of objects. Nor can any individual indexer generate the profusion of words that might come to mind for the collective publics, or begin to employ the multiplicity of languages for which it would be desirable to provide "keyword" access. Museum staff may also require help from remote experts to identify, contextualize, or locate the subject – a common need for photographs in archives (Greenhorn 2005), artifacts in cultural history museums (Vulpe and Sledge 2005) or specimens in natural history collections (Consortium for the Barcode of Life 2005). Collaborative Web tools may be valuable both to create distributed knowledge and to build virtual communities, two objectives that are becoming increasingly important to museums as they seek to engage an on-line community (Hammond, Hannay et al. 2005, Lund, Hammond et al. 2005). Although each is used in a different way, "social tagging" applications such as the ESP game (http://www.espgame.org/), Flickr (http://www.flickr.com/) and del.icio.us (http://del.icio.us/), and aggregating environments like technorati (http://www.technorati.com/), suggest ways to entice the broad public to engage with museum content. TREC (Text REtrieval Conference) has shown that recall in searching is strongly correlated with the number of terms assigned to a record (Voorhees and Harman 1999), and that precision and utility are strongly correlated with the similarity of the user's language to that of the indexer (Jörgensen 1999). So we hope to encourage the general public to annotate our collections, supplying keywords or 'tags' in their own words. There is reason to believe this kind of engagement is possible: early work with The Thinker at the Fine Arts Museums of San Francisco did just this, successfully (Futernick 2005). Collaborative on-line involvement with museums has a history going back to the 1996 monarch butterfly tracking project (Monarch Watch 2005) and the teaching activities surrounding it (Elliott 1996). Art and cultural museums learned to encourage widespread public contributions of object information through initiatives like Save Outdoor Sculpture (Smithsonian American Art Museum and Heritage Preservation 2005); and wikis, such as the Wikipedia ([Collective] 2001-), show strong communities of practice can emerge in collaborative Web spaces. We'd like to see if we can harness some of that same energy, encouraging public engagement with art collections. Progress to DateFor over two years, a growing group has conducted preliminary experiments, and discussed this concept within the museum community. In April, a "Cataloguing by Crowd" professional forum at Museums and the Web 2005 (Chun and Jenkins 2005) drew over a hundred colleagues, who debated the potential for 'social tagging' in a lively floor discussion. The enthusiastic reception of the concept led to follow-up activities at The Metropolitan Museum of Art, the Guggenheim Museum, and The Cleveland Museum of Art. The Metropolitan Museum of Art (MMA) conducted a series of tests that compared the terminology assigned to works of art by professional librarians and library assistants, and began to examine whether professionals provide more and better subject terms for works of art (so far they do not) and whether prompting for a term "category" or suggesting a "category" helps elicit more terms (so far it does, but determining the best way to do it requires interface testing) (The Metropolitan Museum of Art 2005c and d). At the Cleveland Museum of Art, a prototype entry form was integrated into the existing CMA Collections Web interface (Figure 1). A simple "Help others find this object" link on the main page describing a work from the collection opens a pop-up window with a description of the problem and a request for assistance in describing the work to improve its retrieval. The user enters terms into a large text box. The experience, focused on one pre-selected work of art, seems analytical and directed.
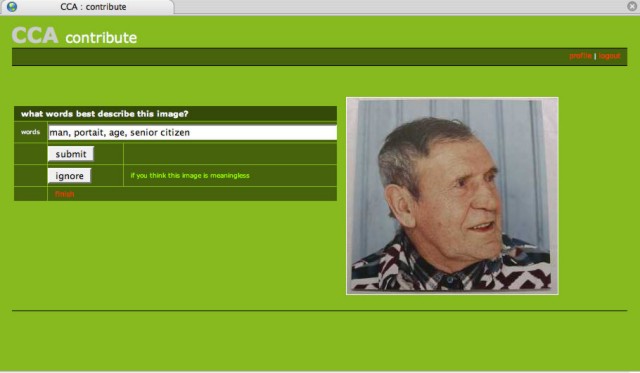
Early results are telling: the content collected from an interface with a large text entry box with a button that says "Send Suggestions" was mixed, ranging from responses clearly showing desirable, delimited, single-term data, to some that were non-compliant with the instructions, consisting of wordy commentary on the image that was based on personal opinion or experience. About two-thirds of respondents entered personal information (name and e-mail address), indicating a general willingness to provide identifying information and encouraging the possibility that communities of volunteer indexers could be nurtured. This experiment hints at the potential for collecting descriptions from the general public, and at the questions to be resolved in the creation of a robust application (Cleveland Museum of Art and Hiwiller 2005). The Guggenheim Museum created a beta prototype tool to explore the issues identified at the Museums and the Web 2005 session and to gather terms from controlled test groups. Their "Community Cataloging Application Prototype 1.0" provides a basic Web interface to support annotation of a collection of images (Figure 2). Images from a pre-defined set are presented to the user at random, without any links to collections data and users provide terms. The user experience is much more like the ESP Game (Ahn and Dabbish 2004); speed and entering large numbers of terms become goals.
A Shared Research Tool: SteveBasic FunctionalityIn July 2005, we constituted ourselves as a working party for an intensive week of planning and programming on Grindstone Island. We defined the functional requirements for a tool – "Steve" – that is a social tagging system with a great deal of variability in its interface. This flexibility is essential to test a suite of features related to user involvement, term utility, and museum community acceptance. Minimally, the prototype should:
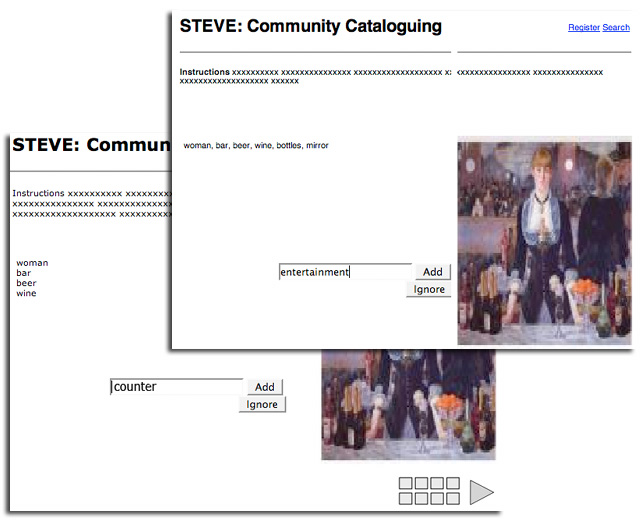
Our beta application has most of these functions. As we tested and discussed it, we realized the need for a comprehensive research project to test the impact of various design decisions intended to motivate users, guide them in their use, and reward them for participation. We need to identify what interface features and forms of engagement correlate with efficient and effective term contribution by both the general public and those special groups we would like to cultivate (Cataloguing by Crowd Working Group 2005a and b). FeaturesMotivateMotivation to participate is likely to come from a user's personal connection with the museum or the content: we might engage existing groups, such as docents, members or donors. If we could obtain much of our input from a community of cyber-cataloging volunteers, we could develop trusted contribution roles and support the strengths of different individuals. An ongoing relationship with the museum might prove more satisfying than an occasional one. But while we want to cultivate community, we do not want to dissuade people who might wish to remain anonymous. We need to understand what impact anonymity has on contribution, and on our ability to analyze the resulting data. Initial reactions to the random presentation of images within the prototype were mixed, and seemed to impede fostering a personal connection with the content; many testers found the disjunction between unrelated images jarred their concentration and slowed them down. Since we do not know if pre-selected sets (or user-defined sets) will generate better responses than purely random sets, we've posited "environments" in the prototype in which users are given a choice between random images, museum-defined (thematically related) sub-pools, and a metadata-based search to create their own "pool". Could this more personalized approach strengthen ties with the institution? Could it be used to take advantage of specialized expertise or demonstrated ability to index specific types of images? GuideWe are unsure how elements of the user interface will influence user behavior. The boundaries between terms must be clear, so a means of separating terms – especially multi-word bound-terms – is needed. What visual clues will encourage the contribution of keywords? Users will enter terms describing what they see in a limited-length term-entry box. Even a simple user scenario raises questions about the influence of particular variables on user behavior and the resultant "tag quality". To avoid the 'long narrative' problem encountered in the Cleveland prototype (where a large input box prompted a discursive response), the prototype has terms entered in a short input box, and then echoed to a list display. Should that list be a vertical list of terms, or a horizontal 'paragraph' of comma delimited entries? We've mocked up variations for testing (Figure 3).
Categories might also guide term submission. Would 'prompting' for different categories of terminology aid the users? Or would asking users to categorize terms after they have been submitted be more effective? Work at the Metropolitan Museum is exploring this question (The Metropolitan Museum of Art 2005c; The Metropolitan Museum of Art 2005d; The Metropolitan Museum of Art and Smith 2005). Museum collections represent all cultures of the world, and we hope users will supply terms in many native languages; a way to determine the language of the terms is therefore needed. We have hypothesized we might be able to determine language (from a number of terms) if we have dictionaries of many languages available to the system. But how many terms are required and how efficient is this approach? Would it be preferable, or even viable, to explicitly ask for language as part of the term-collection dialog? Can we assume that those assigning tags will not switch languages within a session (since we need to associate language with every term)? RewardIf a folksonomic tool is to become a part of a museum's programs, we need to understand how to encourage users to continue to supply terminology. We hypothesized that users with whom on-going relations were developed would want to be able to "continue" work from one session to the next; thus the user experience needs to be "restorable". To cement relationships it might be nice to enable users to view their "stats": a history of past works tagged, lists of terms, or "tag clouds" of terms (that they've assigned or that all users have assigned) [3]. We wondered if game-like environments, or competitions with prizes would be rewarding for users, and recognised that rewards could be external to the system (and include such things as discounts at a museum store). Since we also know that people want to tell us stories or ask questions, how can this narrative dialogue be enabled without interfering with the term-contribution process. Could a blog-like environment meet this need? How would these two input paradigms co-exist? Regular communication might also be rewarding for participants in a social tagging environment. Perhaps a tag-feed accompanied by representative images could be used to remind users of the system and encourage them to participate. Technical Characteristics of a System to Support ResearchDevelopment StrategyWe are now developing our prototype – online and available for use at <http://www.steve.museum> – to help us gather the data required to answer these (and other) questions (Cataloguing by Crowd Working Group and Trant 2005b). The environment (MySQL/php) uses a general SQL handling layer that can support a range of relational databases (portability has been identified as an issue in deployment). Sessions to this system are a relationship between a user, a system time and a mode of use (not the duration from the first log-in to the final log-off unless that entire time was spent in one "mode"). If these are recorded along with the user, a time and the environment settings that were in place, then the "modes" (or features) that are activated throughout a functional session will be available for analysis. Thus the user may (effectively) "resume" sessions, although the system might log a new session, passing the environment settings, including search criteria forward (Cataloguing by Crowd Working Group and Hiwiller 2005, Cataloguing by Crowd Working Group and Jenkins 2005) Structured object metadata can enable user selection of images to tag (searching), grouping of related images in sets to describe. It could also be displayed (or not) in order to test the impact of the presence of cataloguing information on the task at hand. Documentation of the relational data structure, including an entity-relationship diagram and data dictionary are available on the project Web Site. In defining our development strategy, we've specified a "back-end" that will support all the variables identified in our research questions (Cataloging by Crowd Working Group and Leonhardt July 2005). Initial implementations will not, however, have all possible environment variables present in the user interface (Cataloguing by Crowd Working Group and Bearman 2005). Institutions participating in the project are coming forward to create other "environments": for example, categorization of terms has been tested in a preliminary way by The Metropolitan Museum of Art (The Metropolitan Museum of Art and Smith 2005) and interface alternatives that explore this issue are of interest to the MMA. Continuing Research AgendaOur goal is to stimulate a long-term, distributed, research programme in the museum community on the use of folksonomic methods to augment museum documentation and generate a sense of involvement with cultural collections. We need to deploy our front-end tool with a highly flexible interface and good logging functions in order to examine empirically what users will do when faced with different interface elements and feature options, and study how their choices will affect term collecting. With this research instrument, we will examine characteristics of front ends that motivate users to participate, guide them to contribute the maximum quantity and quality of terms per image, and reward them for doing so. Term UtilityBecause many of the museums participating maintain Web-searchable collections catalogs, we have a significant volume of data about the terms used by the general public to search our collections, including the terms they have used without success (null-hit terms). For example, The AMICO Library Thumbnail Catalog search logs, will be available – along with the rest of this collaboration's record – through the University of Toronto Archives. Initially, terms will be analyzed in light of this historical search data; ultimately we may specify and develop search environments that take advantage of what we have learned or explore ways to provide the vernacular enhancements to systems, such as Google images, that enable access to on-line museum images within heterogenous collections of images on the Web (Cataloguing by Crowd Working Group and Trant 2005a). We need to further our understanding of the utility of folksonomic tags for retrieval in the various settings in which museum content is made available on-line. How best do we incorporate this new documentation into our systems? Assuming the tools we develop are an effective means of acquiring multiple-language terminology associated with collection objects, how best do we make multi-lingual terms usable? We need to determine how to deploy this language in conjunction with curatorial cataloging in order to satisfy the concern that users have access to authoritative information. We are intrigued by, but at this stage uncertain about, the benefits and methods for sharing the lists of tags used. Only when we have significant volumes of terms from many institutions will we be able to determine if there is any sense in combining these in a "vocabulary". Structures, such as flickr's "clusters" might provide another approach to organizing user-submitted terminology (flickr and Butterfield 2005).Community DevelopmentOnce we have a functioning environment that enables the 'tagging' of museum collections, our research will turn to integrating its use into museum programs. We have pre-existing relations with docents, volunteers, friends of the museum, teachers and others whom we would want to further cultivate through engagement in this activity, and the missions of our institutions will encourage building sticky cyber-communities. We want to explore how best to engage people and keep them engaged, to learn about their interests and permit them to use their skills to best advantage. Could we enhance multicultural access, or access by members of small communities with shared heritages (including hobbyists and enthusiasts whose shared heritage and jargons), by encouraging participation by others who share their specialized knowledge? How might we employ volunteers to guide the work of others, to edit and massage term lists and to assess the effectiveness of the process itself? What features will build a sense of community in our cyber-volunteers who are working independently and remotely? What features reward cyber-volunteers and bind them to a long-term relationship with the museum and with this term gathering activity? Could tagging-related projects develop relationships between museums and their communities? How important is the real-time feedback of tools like del.icio.us? Do possible editorial processes surrounding the integration of terms affect the 'stickiness' of the application? Could a 'tag stream' about art encourage visits to the museum's Web site and the museum itself as well? Future CollaborationsWe are actively seeking others from the museum community and the broader digital library community to participate in the development of systems for community contribution of terminology in the cultural sphere; <http://www.steve.museum> is the focus for our open dialogue. We are committed to full and open publication of our findings and the software code (initially under Creative Commons / Share and Share Alike license) in hopes that reporting on our progress will enable us to build links with other researchers who are exploring folksonomic approaches to problems that are similar to our own and who are interested in engaging network communities with museum collections. ReferencesAhn, L. v. and L. Dabbish (2004). "Labeling Images with a Computer Game". CHI 2004, Vienna, Austria, ACM. Arms, W. Y., D. Hillmann, et al. (2002). "A Spectrum of Interoperability: The Site for Science Prototype for the NSDL." D-Lib Magazine, 8(1) January 2002. Available: <doi:10.1045/january2002-arms>. Cataloging by Crowd Working Group and T. Leonhardt (July 2005). Community Cataloguing Application, Description of V1.0 Prototype, Updated: July 2005. Available: <http://www.steve.museum/reference/CCA-PrototypeLeonhardt200507.pdf>. Consulted: August 24, 2005. Cataloguing by Crowd Working Group (2005a). Cyber-Cataloguer: Front End Functionality, Updated: July 2005. Available: <http://www.steve.museum/reference/CybercataloguerFR-2.pdf>. Consulted: August 25, 2005. Cataloguing by Crowd Working Group (2005b). "Front End" Working Group Report. Available: <http://www.steve.museum/reference/ComCatFrontEnd050720.pdf>. Cataloguing by Crowd Working Group and D. Bearman (2005). A Matrix of Environmental Variables to be Tested in a Museum-Based Folksonomic Tool, Updated: July 2005. Available: <http://www.steve.museum/reference/CCA-environmentMatrix20050.pdf>, Consulted: August 24, 2005. Cataloguing by Crowd Working Group and D. Hiwiller (2005). "Back End" Working Group Report 2, Updated: July 2005. Available: <http://www.steve.museum/reference/ComCatBackEnd050722.pdf>. Consulted: August 25, 2005. Cataloguing by Crowd Working Group and M. Jenkins (2005). "Back End" Working Group Report –1, Updated: July 2005. Available: <http://www.steve.museum/reference/ComCatBackEnd050720.pdf>. Consulted: August 25, 2005. Cataloguing by Crowd Working Group and J. Trant (2005a). Cataloguing By Crowd: Issues in Term Analysis, Updated: July 23, 2005. Available: <http://www.steve.museum/reference/comCatTermAnalysis050723..pdf> Consulted: August 25, 2005. Cataloguing by Crowd Working Group and J. Trant (2005b). Research Questions: A Summary of Issues Raised in Discussion, Updated: July 23, 2005. Available: <http://www.steve.museum/reference/ComCatResearchQ050723.pdf>. Consulted: August 25, 2005. Chen, C.C., H. D. Wactlar, et al. (2005). "Digital imagery for significant cultural and historical materials, an emerging research field bridging people, culture and technologies." International Journal of Digital Libraries 5: 275-286. Chun, S. and M. Jenkins (2005). Cataloguing by Crowd; a proposal for the development of a community cataloguing tool to capture subject information for images (A Professional Forum). Museums and the Web 2005. Vancouver, Archives & Museum Informatics, Updated: March 31, 2005. Available: <http://www.archimuse.com/mw2005/abstracts/prg_280000899.html>. Consulted: August 7, 2005. Cleveland Museum of Art and D. Hiwiller (2005). Cleveland Museum of Art Cataloging by Crowd Prototype Term Collection Tool, Updated: July 2005. Available: <http://www.steve.museum/reference/ClevelandPrototype-2005.pdf>. Consulted: August 25, 2005. Coldicutt, R. and K. Streten (2005). Democratize And Distribute: Achieving A Many-To-Many Content Model. Museums and the Web 2005: Proceedings. J. Trant and D. Bearman. Toronto, Archives & Museum Informatics, Updated: March 31, 2005. Available: <http://www.archimuse.com/mw2005/papers/coldicutt/coldicutt.html>. Consulted: August 7, 2005. [Collective] (2001-). Wikipedia, the free encyclopedia, Updated. Available: <http://en.wikipedia.org/wiki/Main_Page>. Consulted: Aug 24, 2005. Consortium for the Barcode of Life (2005). Consortium for the Barcode of Life (Web Site), Smithsonian Institution. Available: <http://barcoding.si.edu/index_detail.htm>. Consulted: August 6, 2005. Durbin, G. (2004). Learning from Amazon and eBay: User-generated Material for Museum Web Sites. Museums and the Web 2004: Proceedings. D. Bearman and J. Trant. Toronto, Archives & Museum Informatics, Updated: March 25, 2004. Available: <http://www.archimuse.com/mw2004/papers/durbin/durbin.html>. Consulted: August 7, 2005. Eakins, J. and M. Graham (1999). "Content-based Image Retrieval." JISC Technology Applications Programme Report 39. Available: <http://www.jisc.ac.uk/uploaded_documents/jtap-039.doc>. Elliott, E. (1996). Migrating Monarchs and Trekking Timber wolves on the Internet. Access Excellence @ the national health museum: Activities Exchange. Available: <http://www.accessexcellence.org/AE/AEC/AEF/1996/elliott_internet.html> Consulted: August 7, 2005. flickr and S. Butterfield (2005). The New New Things. flickr Blog. Updated: August 1, 2005. Available: <http://blog.flickr.com/flickrblog/2005/08/the_new_new_thi.html>. Futernick, B. (2005). keyword indexing the thinker. J. Trant: email message. Graham, M. E. (2001). "The cataloguing and indexing of images: time for a new paradigm." Art Libraries Journal 26(1): 22-27. Greenhorn, B. (2005). Project Naming: Always On Our Minds. Museums and the Web 2005; Proceedings. J. Trant and D. Bearman. Toronto, Archives & Museum Informatics, Updated: March 31, 2005. Available: <http://www.archimuse.com/mw2005/papers/greenhorn/greenhorn.html>. Consulted: August 7, 2005. Hammond, T., T. Hannay, et al. (2005). "Social Bookmarking Tools (I): A General Review." D-Lib Magazine 11(4). Available: <doi:10.1045/april2005-hammond>. Howard, G., J. Pratty, et al. (2005). Storymaker: User-generated Content - Worthy Or Worthwhile? Museums and the Web 2005: Proceedings. J. Trant and D. Bearman. Toronto, Archives & Museum Informatics, Updated: March 31, 2005. Available: <http://www.archimuse.com/mw2005/papers/howard/howard.html>. Consulted: August 7, 2005.
Jörgensen, C. (1999). "Image Indexing: An analysis of selected classification systems in relation to image attributes named by naïve users." Annual Review of OCLC Research 1999. Available: <http://digitalarchive.oclc.org/da/ViewObject.jsp;jsessionid= Lund, B., T. Hammond, et al. (2005). Social Bookmarking Tools (II): A Case Study - Connotea. D-Lib Magazine, 11(4). Available: <doi:10.1045/april2005-lund>. Monarch Watch (2005). Digital Monarch Watch. Available: <http://pathfinderscience.net/monarch/index.cfm>. Consulted: August 7, 2005. Parker, J. J. S. (2004). "Commercial digital image libraries, digital images and digital discontent." International Journal of Digital Libraries 4: 124-136. Shatford Lane, S. (1994). "Some Issues in the Indexing of Images." Journal of the American Society for Information Science 45(8): 583-588. Shatford, S. (1986). "Analysing the Subject of a picture: A theoretical approach." Cataloguing and Classification Quarterly 6: 39-62. Sledge, J. (1995). Points of View. Multimedia Computing and Museums, Selected papers from the Third International Conference on Hypermedia and Interactivity in Museums (ICHIM95/MCN95). D. Bearman. Pittsburgh, Archives & Museum Informatics: 335–346. Smithsonian American Art Museum and Heritage Preservation (2005). Save Outdoor Sculpture! Available: <http://americanart.si.edu/art_info/sos.cfm>. Star, S. L., G. C. Bowker, et al. (2003). Transparency beyond the Individual Level of Scale: Convergence between information artifacts and communities of practice. Digital Library Use: Social Practice in Design and Evaluation. A. P. Bishop, N. A. V. House and B. P. Buttenfield. Cambridge, Mass., MIT Press: 241-269.
The Metropolitan Museum of Art (2005a). Chanel (exhibition description). New York, Updated: 2005. Available: <http://www.metmuseum.org/special/se_event.asp? The Metropolitan Museum of Art (2005b). Image Cataloguing Script, Fall 2004, Updated: 2005. Available: <http://www.steve.museum/reference/MetImagesScriptTF_kjs2.pdf> Consulted: August 25, 2005. The Metropolitan Museum of Art (2005c). Image Cataloguing Test Results. Fall 2004, Updated: 2005. Available: <http://www.steve.museum/reference/MMAImageCatalogingTestFall2004.pdf>. Consulted: August 25, 2005. The Metropolitan Museum of Art (2005d). Image Cataloguing Test, December 7, 2004, Updated: 2005. Available: <http://www.steve.museum/reference/MMAImageCatalogingTest12-7-04.pdf>. Consulted: August 25, 2005. The Metropolitan Museum of Art (2005e). The Timeline of Art History. Available: <http://www.metmuseum.org/toah/splash.htm>. Consulted: August 7, 2005. The Metropolitan Museum of Art and K. J. Smith (2005). MMA Subject Cataloguing Trials. Updated: 2005. Available: <http://www.steve.museum/reference/MMASubjectCatTests0508.pdf>. Consulted: August 25, 2005. Trant, J. (2004). Image Retrieval Benchmark Database Service: A Needs Assessment and Preliminary Development Plan. CLIR Reports. Available: <http://www.clir.org/pubs/reports/trant04.html>. Consulted: August 24, 2005. Voorhees, E. M. and D. Harman (1999). Overview of the Eighth Text REtrieval Conference (TREC-8). Available: <http://trec.nist.gov/pubs/trec8/papers/overview_8.pdf>. Vulpe, M. and J. Sledge (2005). Expanding the Knowledge Base Managing Extended Knowledge at the National Museum of the American Indian. Museums and the Web 2005: Proceedings. J. Trant and D. Bearman. Toronto, Archives & Museum Informatics, Updated: March 31, 2005. Available: <http://www.archimuse.com/mw2005/papers/vulpe/vulpe.html>. Walsh, P. (1997). "The Web and the Unassailable Voice." Archives and Museum Informatics 11(2): 77-85. Available: also available at <http://www.archimuse.com/mw97/speak/walsh.htm>. Notes[1] The problem of access to visual materials is discussed in detail elsewhere:
[2] As Bill Arms et al. put it in their discussion of the much better funded NDSL in 2002 "The Site for Science metadata strategy is based on two principles. The first is that metadata is too expensive for the Core Integration team to create much of it. Hence, the NSDL has to rely on existing metadata or metadata that can be generated automatically. The second is to make use of as much of the metadata available from collections as possible, knowing that it varies greatly from none to extensive." Arms, W. Y., D. Hillmann, et al. (2002). A Spectrum of Interoperability: The Site for Science Prototype for the NSDL. D-Lib Magazine, 8(1) January 2002. Available: <doi:10.1045/january2002-arms>. [3] We have left to legal counsel the question of whether the system needs to comply with COP(P)A (Children's online privacy protection act) or other privacy legislation, but will incorporate necessary features if we find it does. (On November 11, 2005, the name of the Denver Art Museum was corrected in the list of contributors to this article.)
|
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2005-bearman
|