|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Herbert Van de Sompel Sandy Payette John Erickson Carl Lagoze Simeon Warner |
![]()
(This Opinion piece presents the opinions of the author. It does not necessarily reflect the views of D-Lib Magazine, its publisher, the Corporation for National Research Initiatives, or its sponsor.) IntroductionThere is growing dissatisfaction with the established scholarly communication system. This dissatisfaction is the result of a variety of factors including rapidly rising subscription prices, concerns about copyright, latency between results and their actual publication, and restrictions on what can be published and how it can be disseminated. The result is a global debate on how to remedy the system's deficiencies, and that debate has inspired concrete initiatives aimed at reforming the process. These are concerned mainly with access issues and seek to alleviate two longstanding problems. The first, known as the "serials crisis," addresses the often prohibitive prices of journal publications that impede access to scholarly materials. The second, known as the "permissions crisis," addresses the restrictions on use of publications once access has been obtained. The "Open Access" movement focuses primarily on these two problems with two different strategies. The self-archiving school strives for a scholar's right to make traditional journal publications freely available in an open repository. The journal-reform school promotes the emergence of new types of journals that are free at the point of use. While the open availability of the results of scholarly endeavors is indeed of fundamental importance to the future of scholarship, it is only one dimension of how the scholarly communication process can be transformed. As Geneva Henry [Henry 2003] has observed, opportunities abound in the world of 21st century publishing and the discussion on transforming scholarly communication must move beyond the debate of subscription-based vs. open access publication. In this article we consider the changing nature of scholarly research, the demands these changes place on the scholarly communication system, and our technical proposals to meet these demands. The changing nature of scholarly researchThe manner in which scholarly research is conducted is changing rapidly. This is most evident in Science and Engineering [Atkins et al. 2003], but similar revolutionary trends are becoming apparent across disciplines [Waters 2003] [note 1]. Improvements in computing and network technologies, digital data capture techniques, and powerful data mining techniques enable research practices that are highly collaborative, network-based, and data-intensive. These dramatic changes in the nature of scholarly research require corresponding fundamental changes in scholarly communication. Scholars deserve an innately digital scholarly communication system that is able to capture the digital scholarly record, make it accessible, and preserve it over time. The established scholarly communication system has not kept pace with these revolutionary changes in research practice. Changes thus far have mainly been small technological improvements. For example, a system that offers interoperability across publishing venues has yet to be realized. Admittedly, there is some level of interoperability, but it is relatively modest. Most publishers support PDF [note 2] as a standard interchange format, achieving a level of interoperability comparable to agreeing to print on paper in the pre-digital era. Some publishers have bought into the idea of assigning unique persistent identifiers to publications, and some have jointly chosen to use the DOI [note 3] for that purpose. Some publishers support the OpenURL [note 4] to allow users to more easily navigate across publishing venues, and a few publishers use the OAI-PMH [note 5] to support metadata sharing. While these efforts represent progress, their limited scope demonstrates that the scholarly communication system is still in an early phase of absorbing the digital technologies that have disrupted the paper-based status quo. Interoperability is one dimension of a larger technical challenge involved in designing a natively digital scholarly communication system. Other challenges include issues of workflow, service sharing, and information modeling. We propose a more fundamental re-engineering to a network-based system that addresses these challenges and provides interoperability across participating nodes. Our vision is based on our belief that the future scholarly communication system should closely resemble—and be intertwined with—the scholarly endeavor itself, rather than being its after-thought or annex. We consider in this article the aspects of the established system that constrain the scholarly endeavor. Based on those considerations, we describe the desired technological characteristics of a future system of scholarly communication. We argue for a scholarly communication system composed of an interoperability substrate allowing flexible composition of the value-adding services that up to now have been vertically locked in the journal publication milieu. In this loosely coupled system, the units of scholarly communication (i.e., data, simulations, informal results, preprints, etc.) could follow a variety of scholarly value chains in which each hub provides a service such as registering results, certifying their validity, alerting scholars to new claims and findings, preserving the scholarly record, and ultimately rewarding scholars for their work.New units of scholarly communicationIn the established scholarly communication system, the concept of a journal publication dominates our definition of a unit of communication. Such publications come with well-known characteristics, some of which are unattractive in light of the changing nature of research. For example, publications are unable to adequately deal with non-textual materials, which are generally regarded to be add-ons rather than essential parts of the publication [Lynch 2003], let alone be publications in their own right. Furthermore, significant communication delays are introduced as the result of the integration of peer-review in the publication process. These problems suggest a revised perspective on what constitutes a unit of communication in a future scholarly communication system:
Hence, our proposal is to revise the notion of a unit of communication in both a technological and a systems sense. In a technological sense, a future unit of communication should not discriminate between media types and should recognize the compound nature of what is being communicated. Such revision would allow for conveying multiple heterogeneous data streams as a single communication unit, as well as to recognize references to previously communicated units as formal components of a new unit. From a systems perspective, the concept of registering a communication unit in the scholarly communication process remains in place. However, we propose that a new system allow for more flexibility regarding the moment at which a unit can enter the communication process. We anticipate that such flexibility would empower individual scholarly communities to decide which actions constitute registering a unit of communication, as well as what the community deems acceptable with respect to the timing of registration and how that relates to the quality of what is to be registered. Apart from facilitating an increased speed of discovery, we feel a more flexible environment would allow scholars to officially incorporate materials in the system of communication that are currently largely living in a grey literature area. New ways to combine the functions of scholarly communicationBased on an analysis of formal scholarly communication since its emergence in the 18th century, Roosendaal and Geurts distinguish the following functions that must be fulfilled by every system of scholarly communication regardless of its actual implementation [Roosendaal and Geurts 1997]:
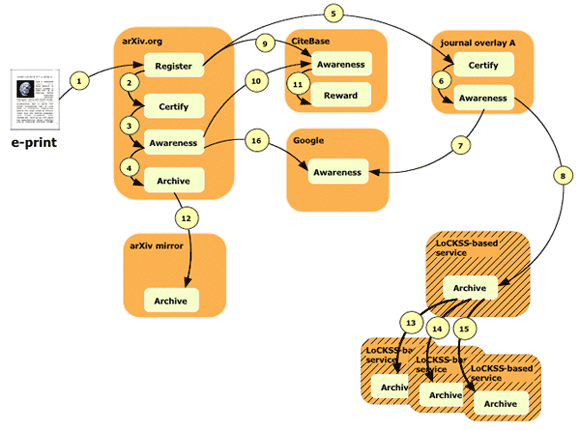
By linking these functions together we adopt a value chain perspective of the scholarly communication system. In the established system, this value chain has largely been implemented in a vertically-integrated manner through the traditional publication process, in particular through journal publication. The registration date is recorded by a journal publisher as the date the manuscript was received. The peer-review process, conducted under the auspices of the journal publisher certifies the claims made in the manuscript. The eventual published journal article, supported by the availability of secondary finding aids, fulfills the awareness function. Rewarding is based on the mere fact of publishing in a certain class of journals and on being referenced in articles by other scholars, both metrics directly derived from the scholarly communication system itself. In the paper-based era the published article itself, bundled into a journal issue, was archived in an ad hoc fashion as it was shelved by libraries across the world. It is noteworthy to point out that archiving is the only function of scholarly communication that, in the paper-based system, is implemented by many parties at the same time. With this exception, the paper-based nature of scholarly communication does not provide the flexibility for the functions of scholarly communication to be fulfilled by separate parties, nor for the same function of scholarly communication to be implemented in different ways by different parties for the same unit of communication. The digital, networked environment has fewer restrictions. As an illustration of this argument, let us examine the scholarly ecology that has already emerged around arXiv [note 6] since its inception in 1991, and let us speculate about things we may expect to emerge in due course. Figure 1 depicts the information flow of a unit of communication—an electronic manuscript—as it enters the arXiv and proceeds through multiple services hubs that fulfill functions of the scholarly communication process. Each step in the information flow is shown as a numbered arrow. The directionality of the arrows depicts the evolution of the communication unit through one or more pathways in the system.
The arXiv itself provides an implementation for most of the functions of the scholarly communication process, as can be seen from the pathway through arXiv which covers registration, certification, awareness, and archiving:
Some scholarly functions are implemented in other ways by other service hubs, resulting in alternative or parallel pathways, as highlighted in the discussion below.
This example demonstrates how the basic functions of scholarly communication can potentially be implemented by multiple parties in different ways, and then offered together as alternative or companion services. As illustrated by means of arXiv, existing hubs are already devising loose, informal connections among services within the constraints of the existing scholarly communication system. Other recent developments are changing the technical and social landscape of the scholarly communication process, and at least suggest a trend that parallels arXiv. The "institutional repository" movement [Lynch 2003, Van de Sompel 1999] is leading to the creation of many new hubs for scholarly content. Universities, libraries, research institutions, and scholarly societies are employing systems such as DSpace [Smith et al. 2003] [note 10], EPrints.org [note 11], Fedora [Payette and Staples 2002, Staples et al. 2003] [note 12], and others to register, disseminate, and preserve documents, datasets, and other media as valuable scholarly assets. At the same time, Grid technologies are being developed to provide network-based services for data sharing and information integration [Frey et al. 2002, Williams et al. 2003]. As materials in those heterogeneous repositories become openly accessible, the emergence of a variety of value chains with those materials at their starting point is quite predictable. Indeed, in the Grid environment, units of communication of a very different nature—say datasets—already proceed through value chains in which hubs fulfill functions such as quality control (certification), discovery (awareness), and archiving. Therefore, we can imagine a future scholarly communication system in which many distributed hubs exist, and where each hub is a service that performs a specific scholarly communication function in a particular way. These hubs may then be composed in multiple combinations to form different pathways through which a unit of scholarly communication may proceed. Each pathway consists of a sequence of distributed service hubs implementing the required functions of scholarly communication in a different way. In such an environment, a single unit of scholarly communication may proceed simultaneously through different value chains implemented across the network. We argue that in order for a distributed service approach to be worthy of the name scholarly communication "system" (rather than scholarly "chaos"), the service hubs need to be interconnected, as if they were part of a global scholarly communication workflow system. Such a workflow system would allow the construction of macro-level workflows for streamlining and concatenating the fulfillment of the various implementations of the functions of scholarly communication. That is, it would allow the chaining of specific implementations of the registration, certification, etc. functions into a pathway that could be followed by a unit of communication. This workflow system could also be implemented at the micro level for streamlining and concatenating the different steps involved in the fulfillment of a given function of scholarly communication by a specific hub. For example, a micro-level workflow could chain a set of migration tasks to fulfill the digital preservation requirements of the archiving function. Or a micro-level workflow could chain tasks involved in an open peer-review implementation of the certification function: make a unit of communication available for review, interactively discuss the paper, propose resolution by the editor, etc. [Pöschl 2004] We believe that a next-generation network-based communication system designed to accommodate these flexible combinations of the functions of scholarly communication will provide the following benefits:
Recording the dynamics of scholarshipThe established scholarly communication system does not record an unambiguous and visible trace of the evolution of a unit of communication through the system, nor of the nature of that evolution. Consider the following simple example: At a certain point, a scholarly manuscript makes its public appearance in the system as an electronic preprint. Next, it is peer-reviewed and published in a journal. Then some secondary publishers create and publish a metadata record describing the paper. Some scholars discover and read the paper, build on it and hence cite it. Later, services need to go through enormous pains to computationally derive the relationships between the preprint, the journal publication, the metadata records, and the citations. The problem addressed in the above example can be misread to be one of computing power, algorithms and access rights. In actuality, the problem is one of relationships among units of scholarly communication. Many important relationships are known at the moment a communication unit goes through a step in a value chain, but these relationships are not recorded in the existing scholarly communication system. The result is that the very dynamics of scholarship—the interaction and connection between communication units, authors, readers, quality assessments about communication units, scholarly research areas, etc.—are lost and are extremely hard or impossible to recover after the fact. We feel this loss needs to be remedied in a future scholarly communication system by natively embedding the capability to record and expose such dynamics, relationships, and interactions in the scholarly communication infrastructure. Recording this body of information is synonymous to recording the evolution of scholarship at a fine granularity. This will allow tracing the origins of specific ideas to their roots, analyzing trends at a specific moment in time, and forecasting future research directions. It will also provide the means to start defining and extracting new metrics to assess the quality of scholarly assets and for the evaluation of the performance of actors in the scholarly system. Such metrics are crucial to avoid information overload and to pave the way toward acceptance of a new scholarly communication system at the socio-political level. ConclusionBy considering the changing nature of research, exploring characteristics of the established scholarly communication system, and observing emerging trends, we have tried to distill some core characteristics of a future scholarly communication system. We have argued for a revised notion of the unit of communication so that in a new scholarly communication system the unit more accurately reflects the changing nature of the information assets produced and consumed in scholarly endeavors. We have argued that the system should allow for—though not mandate—the early registration of scholarly assets in the system to support collaborative and networked-based endeavors, and to increase the speed of discovery. We have argued for technology that allows units to follow a variety of pathways through the system, with distributed nodes fulfilling the different functions of the value chain. We have also argued for technology that records the flow of units through the system. In a spirit similar to the one that led to the creation of the Open Archives Initiative [note 13], our proposals are mainly technical and architectural, but with wide ranging social and organizational implications. Like any technology, success will depend not only on technical soundness but on the willingness of the participants in the system—publishers, scholars, academic institutions, funding institutions, and others—to adopt new tools and develop new organizational models on top of them. Although the proposals described here indeed challenge existing models, we believe that they also provide novel opportunities for all participants in the system. The changes we propose will permit experimentation with novel ways to implement the functions of scholarly communication, for the system to evolve as the scholarly process itself evolves, and for the emergence of competition in a largely monopolized market. The changes will also create a body of information that can be reused, mined, and analyzed, forming a foundation from which new knowledge can be generated. The task of implementing a new scholarly communication system holds many complex technical and organizational challenges. While many new systems are emerging, they tend to offer little or no interoperability among them at this time. There exists no generally accepted information model for the domain of scholarly publishing. In terms of the vision of distributed services that can act as hubs in a future system, there is no common workflow model to build upon. A necessary technical step is the development of information models, process models, and related protocols to enable interoperability among existing repositories, information stores, and services. The NSF has recently recommended funding the authors of this paper to investigate these problems, building on our collective research and development. In a future article we will discuss our current work in moving toward a network overlay that promotes interoperability among heterogeneous data models and system implementations. We will describe our architectural vision for addressing the fundamental technical requirements of a next generation system for scholarly communication. ReferencesAtkins, D. et al.. 2003. National Science Foundation Blue-Ribbon Advisory Panel on Cyberinfrastructure, Revolutionizing Science and Engineering through Cyber-infrastructure, <http://www.communitytechnology.org/nsf_ci_report/>. Brody, T., Kampa, S., Harnad, S., Carr, L. and Hitchcock, S. 2003. Digitometric Services for Open Archives Environments. In Proceedings of European Conference on Digital Libraries 2003, pages pp. 207-220, Trondheim, Norway. <http://eprints.ecs.soton.ac.uk/archive/00007503/>. Frey, J., De Roure, D. and Carr, L. 2002. Publication at Source: Scientific Communication from a Publication Web to a Data Grid. <http://eprints.ecs.soton.ac.uk/archive/00007852/>. Henry, G. 2003. On-line publishing in the 21-st Century: Challenges and Opportunities. D-Lib Magazine, Volume 9, Issue 10. <doi:10.1045/october2003-henry>. Lynch, C. 2003. Institutional Repositories: Essential Infrastructure for Scholarship in the Digital Age. ARL Bimonthly Report 226. February 2003, <http://www.arl.org/newsltr/226/ir.html>. Payette, S., and Staples, T. 2002. The Mellon Fedora Project: Digital Library Architecture Meets XML and Web Services. European Conference on Research and Advanced Technology for Digital Libraries, Rome, Italy, September 2002. <http://www.fedora.info/documents/ecdl2002final.pdf>. Pöschl, U. 2004. Interactive Journal Concept for Improved Scientific Publishing and Quality Assurance. Learned Information, Volume 17, Number 2, pp 105-113. <doi:10.1087/095315104322958481>. Reich, V. and Rosenthal, D. 2001. LOCKSS: A Permanent Web Publishing and Access System. D-Lib Magazine, Volume 7, Issue 6. <doi:10.1045/june2001-reich>. Roosendaal, H., and Geurts, P. 1997. Forces and functions in scientific communication: an analysis of their interplay. Cooperative Research Information Systems in Physics, August 31—September 4 1997, Oldenburg, Germany. <http://www.physik.uni-oldenburg.de/conferences/crisp97/roosendaal.html>. Smith, M., Bass, M., McClellan, G., Tansley, R., Barton, M., Branschofsky, M., Stuve, D., and Walker, J., 2003. DSpace: An Open Source Dynamic Digital Repository. D-Lib Magazine, Volume 9, Issue 1. <doi:10.1045/january2003-smith>. Staples, T., Wayland, R., and Payette, S. 2003. The Fedora Project. D-Lib Magazine, Volume 9 Issue 4 <doi:10.1045/april2003-staples>. Van de Sompel, Herbert. 1999. Repositioning Libraries in the Digital Age. Preservation & Access International Newsletter. June 1999, Number 6. <http://www.clir.org/pubs/pain/pain06.html#repositioning>. Waters, D. 2003. Cyberinfrastructure and the Humanities. Fall Task Force Meeting of the Coalition for Networked Information. <http://www.cni.org/tfms/2003b.fall/handouts/Fall2003Handouts/H-Watersplenary.doc>. Williams, R., Moore, R., and Hanisch, R. A Virtual Observatory Vision based on Publishing and Virtual Data, 2003, <http://bill.cacr.caltech.edu/usvo-pubs/files/VO-vision.pdf>. Notes[1] Commission on Cyberinfrastructure for the Humanities & Social Sciences. <http://www.acls.org/cyberinfrastructure/cyber.htm>. [2] PDF: Adobe Portable Document Format <http://www.adobe.com/products/acrobat/adobepdf.html>. [3] DOI: Digital Object Identifier <http://www.doi.org/>. [4] OAI-PMH: Open Archives Protocol for Metadata Harvesting <http://www.openarchives.org/OAI/openarchivesprotocol.html>. [5] OpenURL: Specification that defines an interoperable approach for requesting context-sensitive services pertaining to referenced resources. The initial specification focused on scholarly publications and is available at <http://www.exlibrisgroup.com/sfx_openurl_syntax.htm>. The generalized framework will be published as a NISO Standard. The current version is at <http://library.caltech.edu/openurl/Standard.htm>. [6] arXiv, <http://arXiv.org>. [7] arXiv policy, <http://arXiv.org/help/endorsement>. [8] Lots of Copies Keep Stuff Safe, <http://lockss.stanford.edu/>. [9] CiteBase, <http://citebase.eprints.org/cgi-bin/search>. [10] DSpace: Durable Digital Depository, 2003, <http://dspace.org>. [11] EPrints.org, <http://www.eprints.org>. [12] The Fedora™ Project: An Open-Source Digital Repository Management System, 2003, <http://www.fedora.info>. [13] Open Archives Initiative: The initiative that facilitated the creation of the OAI-PMH. <http://www.openarchives.org>. Copyright © 2004 Herbert Van de Sompel, Sandy Payette, John Erickson, Carl Lagoze, and Simeon Warner |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2004-vandesompel
|