|
||
D-Lib Magazine |
|||||||||||
|
|
![]()
IntroductionThere has been an explosive growth in the number of scholarly journals available in electronic form over the Internet. As e-journal systems move past the pains of initial implementation, designers have begun to explore the power of the new environment and to add functionality impossible in the world of paper-based journals. Probably the single most important such development has been reference linking, the ability to link automatically from the references in one paper to the referred-to articles. Over the past several years, substantial effort has gone into building an environment to support linking between the rapidly growing number of journal articles available on the web. As this environment developed, it became clear that the initial linking model required refinement to reflect the full range of service arrangements found across the information landscape today. In particular, the model worked well for articles served exclusively through a single delivery system, but not for those replicated in multiple service environments. The complexity inherent in having multiple online copies has become known as the "appropriate copy problem"; this paper describes a project demonstrating one solution to this problem. DOI, CrossRef, and the General Linking ModelEarly linking facilities between independent systems were largely built on bi-lateral agreements, and the link syntaxes they used were based on disparate specific local system configurations. By the late 1990s, however, it became clear that having to individually negotiate with and construct different links for each source did not scale, and that a generalized infrastructure was needed. Three relatively recent developments have helped to enable the emergence of this infrastructure: a series of workshops defined a general model for linking, the DOI system was implemented, and the CrossRef system was implemented. Workshops. A widely-felt concern that the developing architecture of linking systems be as robust, as generalized, and as open as possible led to a series of meetings co-sponsored by the National Information Standards Organization (NISO), the Digital Library Federation (DLF), the National Federation of Abstracting and Indexing Services (NFAIS), and the Society for Scholarly Publishing (SSP). Following the model of an earlier series of workshops focusing on the Digital Object Identifier, these meetings brought together primary publishers, secondary publishers, librarians and researchers in an attempt to understand the functional requirements of linking systems and to begin to model linking systems that satisfied these requirements. Two workshops and a smaller working meeting were held under these auspices between February and June of 1999. A summary of the conclusions of the participants was published in D-Lib Magazine [Caplan and Arms]. Essentially, by the summer of 1999, the basic parameters of a linking architecture were established. The accepted model posited that publishers would contribute bibliographic metadata associated with identifiers to a reference database, and that identifiers would be associated with locations (URLs) in a location database. Citations would be searched in the reference database to obtain identifiers, which would in turn be searched in the location database to return one or more locations in a process known as resolution. The preferred location would then be used to obtain the desired content. Although the model is simple, several of the underlying assumptions were not apparent at the time. There was much discussion over what identifiers should pertain to, particularly over whether they should identify works or manifestations of works. The need for identifiers (also called names) was another subject of debate, as algorithmically calculated linking keys were also popular. The workshop series established the consensus that a linking key must meet at least three functional requirements: it must be persistent, unique within a defined namespace, and capable of supporting resolution to multiple items. The last requirement came from an understanding that multiple copies of a work may exist, and that it must be possible to get to all copies or the subset of copies most appropriate for the user. DOI (Digital Object Identifier). The DOI was initially developed by the Association of American Publishers (AAP), but rapidly turned into an international effort resulting in the formation of the International DOI Foundation (IDF) in 1997 (see <http://www.doi.org>). The aim of the DOI effort was to create an identifier and associated resolution system to aid in the management of intellectual property on the Internet. The DOI may be considered a form of URN (Uniform Resource Name). It provides two critical functions: 1) it is a unique identifier of an object, and 2) it provides a mechanism for locating a copy of the named object on the Internet. The DOI syntax is ANSI/NISO standard Z39.84 [Z39.84]. It is an essentially opaque identifier, meaning that one cannot reliably tell from the string itself the location or bibliographic identity of the object it is identifying. The resolution system for the DOI is the Handle System, developed at the Corporation for National Research Initiatives (CNRI) (see <http://www.handle.net>). The Handle System is a comprehensive system for assigning, managing and resolving persistent identifiers, such as the DOI, for digital objects and other resources on the Internet. In its most commonly used form, the DOI is embedded in a URL, where the server name given in the URL is that of a service (in this case a Handle System resolver) that looks up the DOI in a database and returns information on the object, including one or more addresses. Thus, as long as the database is kept current, objects identified by a DOI can be moved from system to system, and from owner to owner, without the DOI ever "breaking". CrossRef. CrossRef has its origins in the DOI-X project, a collaborative effort among journal publishers to use the DOI for reference linking [Atkins et al.]. The success of that effort led to the creation of PILA, the Publishers International Linking Association, and its CrossRef initiative early in 2000 (see <http://www.crossref.org>). The CrossRef system is intended to enable the automated large-scale assignment of DOI links to references [Pentz]. When a publisher assigns a DOI to a journal article, a standardized metadata record for that article is associated with that DOI and deposited in the CrossRef database. Then, when subsequent articles are being prepared for electronic publication, the references in those articles can be used to search the metadata in the CrossRef database, and the matching DOI retrieved and included as a link in the article. While the name (clickable anchor text) for such links varies from one online system to another, most services simply label the link "CrossRef", and these links will be called "CrossRef links" in the remainder of this paper. Appropriate Copy ProblemThe workshop model called for a reference database for obtaining identifiers and a location database for resolving identifiers to locations. The CrossRef system provides the former, while the DOI and its Handle System resolution service provides the latter. In this way the DOI/CrossRef infrastructure provides a very powerful and generalized mechanism for linking to electronic journal articles across a large number of independent and heterogeneous publisher systems. However, in the current technical environment this architecture suffers a significant limitation. When a DOI link is "clicked", the DOI is sent to the resolver, and the URL found in that database is returned to the browser as an HTTP redirect. The mechanism in its general form is therefore limited to supporting a one-to-one relationship between DOIs and URLs. This would be fine if there existed only a single copy of each e-journal article. For a number of reasons, however, there are many instances when more than one legitimate copy of an article is available:
In each of these cases, the address to which the DOI should appropriately resolve depends on the location or affiliation of the user who is making the resolution request. This issue of which of multiple possible copies should be addressed in response to a resolution request is commonly referred to as the "appropriate copy problem" [Caplan and Flecker]. The limitation of one-URL-per-DOI was recognized as a significant issue from the beginning of the DOI implementation, and in fact the Handle System technology does allow multiple URLs to be associated with each DOI. However, even if multiple addresses were registered for a DOI, there is nothing in the current architecture of linking that could select among these multiple addresses to provide the appropriate one for a given user. As was recognized quickly in the various workshops on linking, selecting the appropriate copy when multiples exist is essentially a "localization" process, and is best carried out at the institutional (library or consortial) level. The local institution is best placed to keep a record of holdings and licensed services and determine the services users should be offered. The "appropriate copy" problem, then, is essentially the issue of where and how to insert localization into the linking process. OpenURL FrameworkAt the same time the discussions of appropriate copy resolution were taking place, Van de Sompel was defining the OpenURL framework, based on his work on SFX [Van de Sompel and Hochstenbach 1999a, Van de Sompel and Hochstenbach 1999b, and Van de Sompel and Hochstenbach 1999c]. SFX, now marketed by Ex Libris, pioneered the ability to provide an appropriate set of extended services based on the context of a user and his request (see <http://www.sfxit.com>). Such services might include choices such as linking to an abstract rather than the full text, performing a citation search on the author or title, finding additional information about the author, or linking to related publications. The OpenURL framework is an architecture that allows for the building of localized, context-sensitive links based on metadata and identifiers for referenced works [Van de Sompel and Beit-Arie 2001a, Van de Sompel and Beit-Arie 2001b]. It defines a model for Open Linking, separating the identity of referenced items from specific linking addresses. In the OpenURL framework, a source system links to a local service component such as SFX rather than linking directly to the referenced work, and passes information identifying the bibliographic item. The OpenURL itself is an HTTP request (GET or POST) that delivers metadata and/or identifiers of the referenced work to a local service component when clicked by the user. The OpenURL draft specification was submitted to NISO in December 2000 and was accepted as a work item towards development as an American National Standard (see <http://www.niso.org/commitax.html>). A fundamental notion in the OpenURL architecture is that a referenced work can be identified by either an explicit set of metadata elements (e.g., ISSN, title, year, volume) or by one or more unique identifiers (e.g., DOI). The latter can be considered pointers to metadata since in many cases the service component will be able to use these identifiers to fetch additional metadata about the referenced work from resources that can accept identifiers as keys to metadata. Demonstration ProjectPrototype. A small group of interested parties agreed to prototype a solution to the appropriate copy problem based on the OpenURL framework. Participants consisted of representatives from CrossRef, Ghent University, Ex Libris, and CNRI. In this prototype, a HTTP-to-Handle proxy server in front of the DOI resolver rerouted certain resolution requests to an alternate resolver, in this case an SFX implementation. The location of the alternate resolver was communicated to the proxy server via cookies stored on the user's browser using the SFX "CookiePusher" program (see <http://www.sfxit.com/openurl/cookiepusher.html>). The experiment provided practical answers to several of the issues raised earlier: where to insert localization (at a central spot in front of the default resolver), how to insert localization (information passed in cookies), and how to identify the appropriate location (using profile tables in the local server to associate subscription information with services). The prototype was presented at a third linking workshop sponsored by NISO, the DLF, and CrossRef in July 2000 [NISO, Van de Sompel]. This meeting resulted in consensus on a new general model for linking based on the OpenURL framework. An actionable identifier found in any information service, when clicked, would go to a redirector at a central site for the identifier type. The redirector would check whether there was a cookie indicating an alternate service component, and if not, forward the identifier for resolution at the default resolver. If a cookie were found, the resolution request would be reformatted as an OpenURL addressing the alternate service component. The alternate service component might be an institutional or consortial resolver or some third-party service. Institutional access to articles is generally by subscription to a journal title for some period of time. DOI identifiers, however, point to articles, not journals, and do not reliably contain information identifying the journal title, issue or date. Another important outcome of the workshop was the realization that the CrossRef database, originally intended to enable looking up a DOI from metadata in hand, could, with a small amount of programming, also be used to enable lookup of metadata from a DOI in hand. This "reverse lookup" facility in CrossRef would provide the additional metadata needed to determine the appropriate copy and/or deliver extended linking services to the user. Project structure. Following this consensus on a general model for "localizing" reference links, a number of institutions agreed to conduct a larger demonstration of the proposed architecture. The project involved providing "appropriate copy" resolution of DOI links for three institutions, each of which has access to collections of locally loaded e-journal articles:
Other participants in the project included:
In addition, a number of other institutions served as observers and participated in the planning of the project:
Architecture. The project architecture followed closely on the July prototype. Key components of the architecture were:
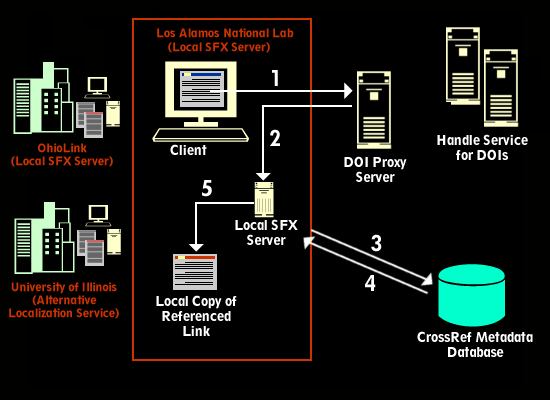
This architecture is illustrated in Figure 1.
1. A user reading an e-journal article "clicks" a DOI link in a reference. The DOI and the user's cookie (previously set through the "CookiePusher" mechanism) are sent to the DOI HTTP-to-Handle proxy server.
In addition to resolving an address for the item identified by a DOI, local resolution servers can also provide "extended services" based on the metadata derived from CrossRef. In the LANL implementation, clicking on a CrossRef link in a cited reference on a publisher's website would take the user to a complete SFX services screen, which included not only a link to the full text of the appropriate copy, but also links to extended services such as cited author searches and document delivery options. Illinois also experimented with extended services, providing a menu of links to targets including Compendex, INSPEC, and the local OPAC. Ohio State users were offered links to local holdings of the printed version of the journal as reflected in the OhioLINK union catalog, MyEmail (for authors' addresses), and Google (for searching keywords from the article title). Participant Experience. Overall, all three implementations of local resolution were successful, and the proof-of-concept was amply demonstrated. No significant barriers were encountered during the project. Usage of the test systems was unfortunately quite limited, for a number of reasons:
The amount of feedback received from actual users was low, not only because usage was low, but because the resolution process was transparent to users. Participating staff noticed two minor problems: First, as noted above, most services displaying reference links to users use something generic, such as a highlighted title, or the anchor text "CrossRef" to indicate the clickable link. At least one online service, however, attempted to determine the target of the CrossRef link, and displayed the name of the target service to the user, e.g., "Access full text of this article from XYZ site". Redirecting the link from XYZ to the local e-journal collection was a source of potential user confusion. All project participants felt that explicitly identifying the target of a link was bad practice and should be discouraged. Second, LANL and Illinois found that the metadata returned from CrossRef varied. For example, a reference with several authors might return only the first author with the metadata, limiting the extended services that could be made available. (Since CrossRef collects only the basic metadata necessary for matching references to article DOIs, submitting more than the first author for an article is optional.) Outstanding IssuesCookies. The use of cookies in this project tried to address a problem that is not specific to the proposed architecture, but rather is a universal problem related to checking user credentials in a distributed networked environment. Throughout, the use of cookies was problematic, and clearly only a short-term solution. One problem with the cookie mechanism was finding a method for setting cookies on every user's machine, and then resetting them regularly as they expired. The general approach to this was to utilize a web page that library users could be expected to visit regularly to activate the cookie-pushing process. Such mechanisms are necessarily somewhat scattershot, and some users may not have the cookie set at the point at which they encounter a DOI. Another issue with cookies is setting them inappropriately. Generally, the web pages used for initiating the cookie setting are available to outside as well as institutional users. Therefore, it is important that either the cookie-setting process be filtered to eliminate non-local users, or that the localization process check for non-local users and implement cookie "unsetting" when outside users are encountered. The JavaScript that LANL used to push the cookie did check to ensure it was set only for users within correct IP ranges. A third issue concerned users with multiple affiliations (for example, university department and government research laboratory). Using the cookie mechanism, such users would have different access rights depending on the context of a particular server connection. The only alternative to the use of cookies considered during the project was having the DOI HTTP-to-Handle proxy filter users directly based on IP address. All users from a given range of IP addresses would be routed to the local resolver for the associated institution. This is, of course, the mechanism used to control access for most commercial services to which libraries subscribe today. However, this option was rejected as administratively too difficult in the short term, as the DOI service does not currently have a business relationship to the institutions requiring localization. In the long-term, better solutions than cookies will be needed to support localization. Many hope that digital certificates will help here, as they may in the general problem of authenticating users to remote information services. When better solutions become available, they can be easily substituted for local resolution without damage to the overall architecture. Publisher "opt-out". From the earliest linking meetings there was discussion of a mechanism for publishers to "opt-out" of localization; that is, DOIs for a particular publisher would not be redirected to a local server. Some publishers, in particular society publishers that do not allow "local loading" or other arrangements resulting in institutions having alternative copies (except, of course, for print), may want their identifiers to resolve only to the location registered by the publisher. For some journals there may be no options for extended access that could even be offered by a localization server. Localization also introduces the possibility that links could be redirected to illegal copies of an article (perhaps as a result of honest configuration errors, or lack of awareness of license terms) or to document delivery suppliers that don't pay the copyright fee to publishers. The most effective way to implement the opt-out option would be for a "no redirection" flag to be recorded for each of a publisher's DOIs in the central DOI directory. It was decided that, while possible, it was not practical to do this during the project. It is not clear whether any publishers would actually choose to opt-out, based on the value localization brings to end users and librarians, but it may be important to have this alternative for localization to be fully accepted. Terms and Conditions for Use of Metadata. Publishers who deposit metadata in the CrossRef system are naturally concerned about who uses that data, and for what purposes. Publishers have a legitimate interest in how links to content they publish are presented to users. The terms and conditions for the delivery and use of metadata for localization still need to be finalized, but it is likely that publishers will want CrossRef Library Affiliates to sign agreements that:
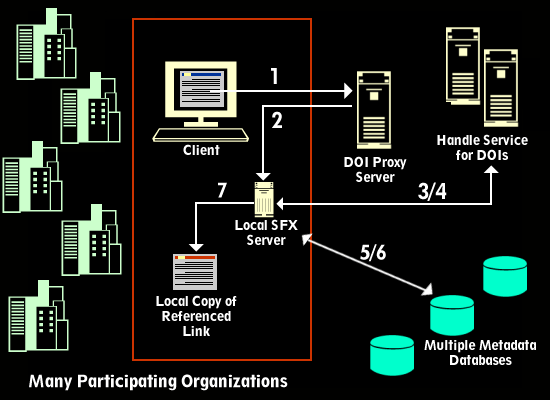
Content Licensing. Practically all publishers offering electronic access today require subscribing institutions to sign license agreements governing the terms of access and use. There was disagreement among the participants as to whether changing the ultimate destination of a DOI link provided in a publication could be interpreted as changing the publication itself in which the link was found. Some user licenses prohibit such changes. Scalability/Performance. The performance effects of redirecting links at the DOI Proxy, and of reverse lookup in the CrossRef reference database must be assessed. Also, publisher opt-out or other options that might require changes to the Handle System service may have an effect on the performance of the central DOI directory. Locating metadata. During the project, local resolvers simply assumed that metadata for all DOIs could be retrieved from the CrossRef database. That is a valid assumption today, as all current DOIs are for material for which CrossRef is the DOI registration agency. However, other registration agencies have already been established, and the metadata look-up process will need to be made more flexible. A logical elaboration on the general architecture of the project is to add to the DOI database information about what registration agency holds the metadata for a given DOI. This architecture is illustrated in Figure 2.
1. A user reading an e-journal article "clicks" a DOI link in a reference. The DOI and the user's cookie (previously set through the "CookiePusher" mechanism) are sent to the DOI HTTP-to-Handle proxy server.
Large-scale test. As discussed above, there was very little actual use during the project. More links and increased use of the resources containing them will be required to assess the validity and utility of the architecture. Next StepsThe participants and observers in this project are convinced that:
It is currently the intention of the participants in this prototype to continue working together on the issues raised in this paper. While the business terms and policies are being discussed and resolved, the current implementation can be kept running and even extended, with the agreement of the current participants. It would be useful to test the system with greater usage and heavier loads and investigate solutions to issues that have been identified. Further user feedback, when many more CrossRef links are in place, will also be valuable. In the online world collaboration, network effects and standards are all critical factors. Under network effects, the more computers that join a network, the more valuable it becomes. Similarly, the more that the various parties in the online scholarly information chain collaborate, the more valuable the whole system becomes for everyone. Network effects are not possible without standards at all levels, from HTTP to metadata encoded in XML. It is unusual but necessary to have trade associations like CrossRef and the DLF, publishers, standards organizations, libraries and library systems vendors all working together on a common solution to a problem. The end result of this collaboration will be to make robust, open reference linking possible across all legal copies of articles, which will serve the best interests of scholars, libraries and publishers. AcknowledgementsThe authors wish to acknowledge the following individuals who participated in the localization prototype project, reviewed drafts of this paper, provided illustrations, or otherwise contributed to this article: Thomas Dowling, OhioLINK Notes[1] ScienceServer is a software product for loading and searching local journal collections, marketed by ScienceServer LLC. [2] In addition to SFX, resolution systems are under development by OCLC Open Name Services <http://www.oclc.org/strategy/preservation/opennames> and Endeavor Information Systems <http://www.endinfosys.com/prods/linkfinderplus.htm>. References[Atkins et. al.] "Reference Linking with DOIs: A Case Study." D-Lib Magazine, February 2000. <http://www.dlib.org/dlib/february00/02risher.html> [Caplan and Arms] "Reference Linking for Journal Articles." D-Lib Magazine, July/August 1999. <http://www.dlib.org/dlib/july99/caplan/07caplan.html> [Caplan and Flecker] Choosing the Appropriate Copy: Report of a discussion of options for selecting among multiple copies of an electronic journal article. <http://www.niso.org/DLFarch.html> [NISO] NISO/DLF/CrossRef Workshop on Localization in Reference Linking: Meeting Report. <http://www.niso.org/CNRI-mtg.html> [Pentz] "CrossRef: the missing link." College and Research Libraries News, Volume 62, Number 2, February 2001. [Van de Sompel] CrossRef--DOI--OpenURL--SFX demo using IDEAL metadatabase & enhanced DOI proxy. July 2000. <http://www.sfxit.com/crossref/prototype1.html> . [Van de Sompel and Beit-Arie 2001a] "Open Linking in the Scholarly Information Environment Using the OpenURL Framework." D-Lib Magazine, March 2001. <http://www.dlib.org/dlib/march01/vandesompel/03vandesompel.html> [Van de Sompel and Beit-Arie 2001b] "Generalizing the OpenURL Framework beyond References to Scholarly Works: The Bison-Futé Model." D-Lib Magazine, July/August 2001. <http://www.dlib.org/dlib/july01/vandesompel/07vandesompel.html> [Van de Sompel and Hochstenbach 1999a] "Reference Linking in a Hybrid Library Environment, Part 1: Frameworks for Linking." D-Lib Magazine, April 1999. <http://www.dlib.org/dlib/april99/van_de_sompel/04van_de_sompel-pt1.html> [Van de Sompel and Hochstenbach 1999b] "Reference Linking in a Hybrid Library Environment, Part 2: SFX, a Generic Linking Solution." D-Lib Magazine, April 1999. <http://www.dlib.org/dlib/april99/van_de_sompel/04van_de_sompel-pt2.html> [Van de Sompel and Hochstenbach 1999c] "Reference Linking in a Hybrid Library Environment, Part 3: Generalizing the SFX solution in the "SFX@Ghent & SFX@LANL" experiment." D-Lib Magazine, October 1999. <http://www.dlib.org/dlib/october99/van_de_sompel/10van_de_sompel.html> [Z39.84] Syntax for the Digital Object Identifier, Z39.84-2000. <http://www.techstreet.com/cgi-bin/pdf/free/247384/z39-84.pdf> Copyright 2001 Oren Beit-Arie, Miriam Blake, Priscilla Caplan, Dale Flecker, Tim Ingoldsby, |
|
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/september2001-caplan
|