|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Leslie Johnston |
![]()
AbstractIn fall 2004, the University of Virginia Library launched its Digital Library Repository for its first experimental year. The Repository was built using Fedora, a digital library management architecture jointly developed by the University of Virginia and Cornell University. The interface was designed to accommodate discovery and delivery of objects within and across collections and formats – images, texts, finding aids – and provide access to tools that support use of the collections in research and instruction. This includes an Image Viewer for on-the-fly manipulation of images, and a Digital Object Collector Tool for the creation of personal collection portfolios, slide shows, and image reserve Web sites. The development of the interface and tools required an extensive internal design review, classroom testing, and usability testing with library staff and faculty. In this article, development steps, testing procedures, and examples of test results and impact are discussed. IntroductionIn 1999 the UVa Library Digital Library Research and Development department began working with the Cornell University Digital Library Research Group, after discovering an article [1] by Carl Lagoze and Sandy Payette that described Fedora™ [2], the Flexible and Extensible Digital Object Repository Architecture. After UVa completed a reference implementation [3], they joined with Cornell to secure grants from the Andrew W. Mellon Foundation in 2001 and again in 2004 to develop Fedora into an advanced open source digital library architecture that can serve as the underlying infrastructure for many types of digital libraries. The Fedora project is a research effort to develop a generalized digital asset management (DAM) architecture, upon which many types of digital library systems might be built. Fedora is the underlying architecture for a digital repository, not a complete management, indexing, discovery, and delivery application. Fedora includes the software tools to ingest, manage, and provide basic delivery of objects with little or no customization, but Fedora's real flexibility and potential lies in that customization. Alongside the UVa Library's work on the development of Fedora, the Library began a large-scale effort in 2002 to define local architectural and service overlays specific to its collection development strategies and functional requirements for a repository. PrioritiesThe prioritization for collection development for the UVa Digital Library Repository was based on selector priorities, user needs, and the status of local legacy digital collections. Subject selector input was vital because the UVa Repository is a curated repository; subject librarians select all content, following much the same process as for physical materials, with the addition of a technical assessment. Production and content migration were prioritized by format type: digital images, electronic texts, and EAD finding aids were designated the priority for the first production Repository. Art and Architecture images were a particular priority because UVa had not previously delivered an online image catalog at all, and faculty were demanding such a service. Electronic texts were prioritized because of the scale of the legacy local collections and the need to provide search capabilities across the entire text collection, something requested by users but previously unavailable. The EAD finding aids were prioritized because UVa was preparing to migrate to EAD 2002, so the delivery mechanisms for the collection were already scheduled for redevelopment. Digital Collections AnalysisThe digital collections required analysis to determine the level of homogeneity of their file formats and the amount and type of metadata available. Why are such detailed analyses necessary to develop an end-user interface for Fedora? Object management and delivery in Fedora is based on content models that represent classes of data objects, which can be single units of content, complex data objects, or even aggregations of data objects. The objects contain linkages between datastreams (internally managed or external media files), metadata (inline or external), system metadata (including a PID – a persistent identifier – that is unique to the Repository), and disseminators that bind the data objects to behavior objects managed by Fedora that provide software processes (behaviors) that can be used with the datastreams. Behaviors encode the varying functionality that an end-user or another system would require or encounter in its use of an object in a Fedora repository. The disseminators include the varying programmatic mechanisms needed to execute those behaviors for the varying types of objects. The key to developing an end-user interface on top of Fedora is the development of these content models. Content Models and Production StandardsThe definition of the UVa Library content models required four steps: the abovementioned detailed analysis of the formats and configuration of media files and available metadata for the legacy object collections; development of new holistic production standards for media files and metadata; comparison of the collection analysis to the new production standards to confirm that the files met or could be processed to meet those standards; and the development of functional requirements for an end-user interface. While developing the Fedora reference implementation in 2000 and 2001, the UVa Library had already created its DTDs for the encoding of descriptive, administrative, and technical metadata – GDMS, UVaDescMeta, and UVaAdminMeta [4]. In 2003, when local Fedora development began in earnest, a Metadata Steering Group was formed to provide mappings and document use guidelines for UVaDescMeta and UVaAdminMeta, which serve as the crosswalk for all objects and metadata types in the Fedora Repository. New specifications were set for the production of new digital images of varying types (art and architecture or documentary images, 24-bit full-color pages images, and bitonal page images) [5]. Revised encoding guidelines were developed for the new markup of TEI (Text Encoding Initiative) electronic texts [6], including the placement of <pb> tags, rules for encoding seriality (monographic series and newspapers), and naming strategies to identify an object as part of a defined set for the Repository and for OAI. Mappings and encoding guidelines were developed for the transition to EAD 2002 [7]. When the legacy collections were compared to the new production standards, even with the natural variation in production over the preceding years, it was determined that the differing media files could be migrated to meet a relatively small number of file configurations with acceptable variations of the production and metadata standards. Those variations in configurations, combined with variations in end-user delivery functionality, are the core for the definition of the UVa content models. For images, it was agreed that delivery functionality required preview, screen, and max size deliverables, as well as the ability to display an image in the context of its metadata and any objects with which it has a relationship. Three image content models and production variations were agreed upon:
One content model and production standard was set for image metadata in the local GDMS (General Descriptive Modeling Scheme) format. For TEI files, production standards and content models exist somewhat independently. The encoding standards UVa has developed can best be viewed as concentric circles. At the center is a core subset of elements with the most proscribed encoding options, and the "loosest" is the full set of elements and all acceptable encoding options. This provides clearly defined and interoperable markup in common, but allows practice at the outer "circles" that help deal with increasing variability and provide additional functionality beyond the basic level provided by the core. Each circle is clearly defined, and not just allowed to be "looser" than its inner neighbor. All the local encoding practices parse against the same UVa extension of the TEI DTD (Document Type Definition). In an interface to the TEI files, a table of contents must be available, if it exists, for each volume. Each text section (e.g., a chapter or article or poem) must be independently navigable and viewable, and the option for viewing the entire text on one page must be available. Searching was specified where hits in context – showing a byte-offset of characters/words surrounding the search term – help the user locate specific passages. If page images are available for the book, the user must be able to "turn" the pages and navigate between the page turner and the transcription. It must also be possible to browse the page images in sets. Three TEI content models were developed:
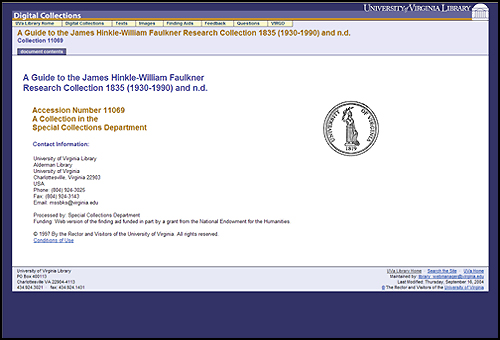
Any of the levels of local TEI encoding practice can be applied to books that fall into any of the three content models, depending upon the level of functionality required for the text. The page images for a TEI-encoded book must adhere to one of the three image content models described above. In an interface to the EAD files, each section of the finding aid – title page, descriptive summary, scope and content information, contents list, etc. – must be independently navigable and viewable. It must be possible to browse the entire Finding Aid collection as well as to be able to search it via full text. When viewing a single finding aid, users must be able to search only within that finding aid. Only one content model and production standard was set for EAD finding aids. The key to the development of uvaEAD was a mapping of existing local EAD encoding practice to best practices for the use of EAD2002, overlaid by the mechanisms needed for the above functionality. In addition, the linked TEI or GDMS files representing any special collection objects must adhere to one of the TEI content models, and any images, whether directly linked or part of a TEI object, must adhere to one of the image content models. The functional requirements were translated into content model behaviors that objects should be able to present, such as delivering subsets of their content or metadata, delivery of static files or on-the-fly transformations (such as raw XML delivery versus delivery of XHTML generated from the same XML file), or supporting the download of image files. Great care was needed to confirm that the desired functionality for the search and delivery in the public interface matched behaviors in the content models, and that the correct number and types of media file and metadata datastreams were present to support those behaviors. Disseminators were designed to encompass every behavior that would be manifested in the user environment. Additionally, the specifications for the interface look and feel and functionality were documented for each collection type in a detailed screen-by-screen description. Phase 1 Prototype Repository AssessmentIn summer 2003, a "Phase 1" prototype was developed for review by Library staff. The prototype did not operate on top of Fedora, but was a functional proof-of-concept meant to elicit feedback that would guide the development of the production Fedora Repository and its end-user interface. The prototype included texts from the Library's Special Collections and images of art and architecture. Over 130 comments were collated from Library staff on the design, functionality, and usability of the prototype into 23 recommendations in four categories: User Interface, General User Functionality, Image-Specific Functionality, and Text-Specific Functionality. Library staff from the Administrative Council, Imaging Group, Production and Technology Services area, User Services, and the Usability team ranked the list to help determine the development priorities. The rankings were assigned numeric values, and thresholds were established to group the recommendations into developmental phases as shown in Table 1.
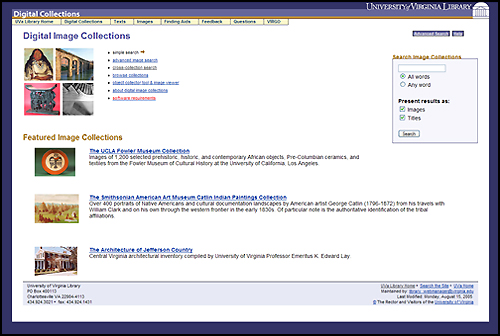
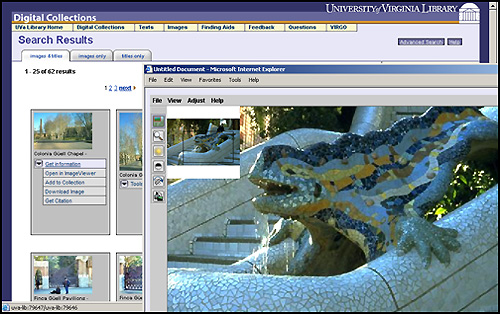
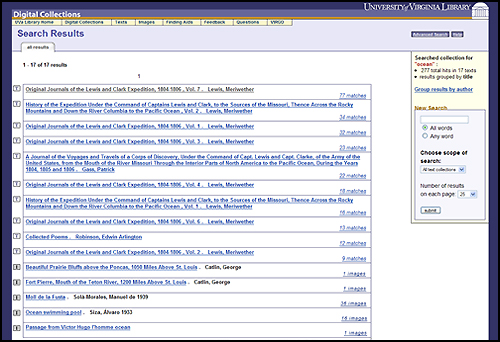
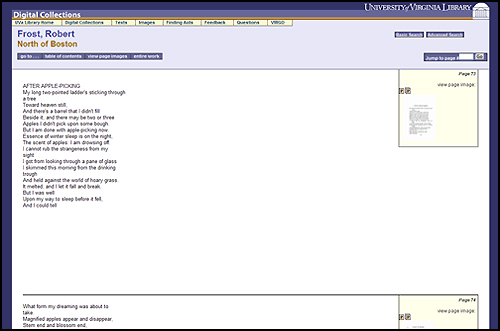
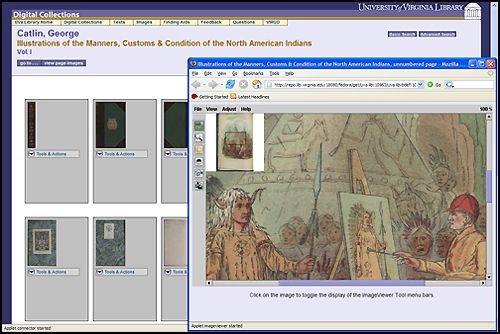
Survey Respondents assigned High, Medium, and Low rankings to items. The analysis of the comments led to modifications of the functional specifications for the interfaces, such as the ability to move between text transcriptions and page images and retain the reader's position in both datastreams, which required the addition of behaviors to some of the content models to meet the new specifications. Additional specifications were also developed for an end-user image tool called the "Digital Object Collector Tool" to be integrated into the "Phase 2" Repository. Phase 2 RepositoryThe implementation for the Phase 2 Repository took two years and involved staff from nine different units whose responsibilities ranged from setting metadata requirements to content production to graphic design to programming. The programming time required was not extensive, instead requiring small slices of time from a number of programmers as resources became available. Implementation required scripts to convert legacy images, electronic texts, and finding aids to current standards and to ingest each type of content model for images, electronic texts, and finding aids. All disseminator programs to display or download objects in the manner defined by the behaviors in the UVa Library content models were developed. Apache Cocoon was implemented as the XML pipeline middleware to translate between the user interface and the Repository. A unified interface and graphic design was applied across all discovery and delivery functionality for the Repository collections using CSS and XSLT. A combined metadata-only discovery search for images, electronic texts, and finding aids was implemented using XPAT. Full-text searches for the electronic texts and the finding aids were also implemented using XPAT. The Phase 2 Repository was launched for its first experimental use by the UVa community in October 2004. Images can be discovered through their metadata and displayed in the context of their parent object and sibling images with full metadata. They can also be opened in an ImageViewer Java Applet that supports zooming and panning, or the images can be downloaded. Full-text searching is available for the electronic texts. The texts can be read online if a transcription is available; if only page images are present, a Page Turner navigates through the text. EAD Finding Aids are now included in the Repository. Full-text searching is available, and the Finding Aids can be viewed in their entirety or in sections. A simple, keyword cross-collection metadata search (image metadata and TEI and EAD headers) is also available. Individual image collections can be browsed; implementation of browsing for the texts and finding aids is due in fall 2005. Figures 1 - 6 provide screen shots of various Repository web pages.
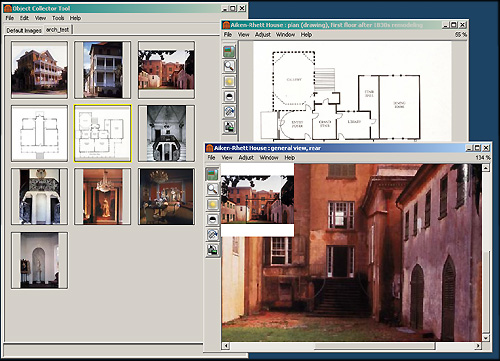
The Phase 2 Repository includes the first release of the Digital Object Collector Tool (see Figure 7) that allows users to create personal portfolios of objects. The Collector Tool is a client Java application that is automatically installed, downloaded, and updated via Java WebStart. All images discovered through a Repository search are "collectable" through the imbedding of a small chunk of JavaScript in the results page. All images, including page images, are accompanied by a "Tools & Actions" menu through which users can view additional metadata, invoke an improved ImageViewer (zooming, panning, rotating and on-the-fly image manipulation), or collect the image. The Collector Tool supports the organization of personal portfolios for which users can generate slide shows or electronic reserve websites that include pointers to the images and metadata in the Repository. The slides shows and electronic reserve web pages deliver the images wrapped in the same ImageViewer application that is available for search results in the Repository. The electronic reserve web pages that are generated by the Collector Tool contain the same chunk of JavaScript as the repository search results, allowing any images on the pages to be themselves collectable by any other user with the Tool. Later releases will be generalized to support the collection of other object types, a sort of combination shopping cart and authoring tool for the entire Repository.
Repository AssessmentThe assessment of the Repository has taken four forms. First, there has been a review of all the collection interfaces by the Library staff. This review primarily resulted in the reporting of bugs and heuristic issues with the interface. The Finding Aid view was not fully completed at the time of the staff review. Four members of the faculty were invited to test the Image Collection in classroom use. One made sets of images available as a study set for a course, two built collections and used the Collector Tool to teach in class, and one used both the Tool in the classroom and asked students to build their own image collections for use in class projects. Two focus groups were held with mixed Architectural History, Architecture, and Art History faculty. They were presented with a demonstration of the Image and text interfaces, and asked to provide feedback. Usability tests were held with teaching faculty and Library staff from varying areas as testers. The testing was limited to the Image interface – the only fully complete interface at the time of the testing. Please see Appendix A for the questions used in the Usability Test, and Appendix B for the collected feedback from all four assessment instruments. All bugs, feedback, and requests from the assessment processes are logged into a database for review and prioritization by the implementation team. As bugs were discovered, they were fixed. Easier to fix issues, such as standardizing menu labeling, reorganizing menus, truncating titles in the image results display, updating the display when a search produced no results, identifying file type in the download window, and ensuring that navigation was present, were addressed during the test period. Requests from the classroom testing faculty were addressed as promptly as possible during the testing period. These included adding the ability to duplicate images in collections and adding blank screens into presentations. Some of their requests were submitted during follow-up assessment meetings after the end of the term. These requests were prioritized for implementation before or during the fall 2005 term (see Table 2):
Future WorkThere is still work to be done on the core implementation. The infrastructure and interface do not yet support the ingest and navigation of objects that represent entire collections or aggregations. Services to support the ingest and delivery of digital video, datasets, and audio are in the planning stages. The implementation team is also considering additional and alternative interfaces to the Repository collections, including a separate dedicated interface to UVa history-related collections across all formats, an experiment using Thinkmap [8] to provide visualization of content relationships, and investigation of a thesaurus-based query system that could be modeled on the work done with MyLibrary@Ockham at Notre Dame [9]. Lessons LearnedThe development process encompassed the creation and documentation of entirely new holistic standards for production, functional requirements for discovery and delivery, unified interface design across collections, and the implementation of new software tools and scripts for all aspects of production and delivery. The principle lesson learned in the development of the end-user interface is that the process required four initial tasks:
Great care was needed to be certain that the desired functionality for the search and delivery in the public interface were matched to behaviors in the underlying content models and that the correct number and types of media files and metadata datastreams were present to support those behaviors. It was not until those details were in place that the task of actually coding disseminators could begin – creating behavior objects, ingesting content objects, generating search indexes, and integrating all of the above with the look-and-feel for the public interface. The development process had to be accompanied by multiple types of assessment involving many categories of users. While there was some feedback in common – changing the type of results returned for image search results or wanting to limit advanced searches to sub-collections – each new assessment provided additional data that helped us better define the functionality desired by our users. The assessment was vital for our implementation. While this implementation is under way, a process is also underway to design a new information architecture for the Library's overall web presence, and determine how to technically and visually integrate all the currently disparate tools and pages that provide access to the collections and services supporting use of the collections, regardless of format. The overarching goal is the development of an integrated interface that provides access to and delivery of content from the Library's distributed resources. The assessment used in this process will prove vital in modeling assessment strategies for the Library's larger undertaking. Appendix A: Usability Questions Used in the Image Interface Assessment
Appendix B - Collated Feedback from All Repository Interface Assessments Notes and References1. S. Payette and C. Lagoze, "Flexible and Extensible Digital Object and Repository Architecture (FEDORA)," presented at Second European Conference on Research and Advanced Technology for Digital Libraries, Heraklion, Crete, 1998. <http://www2.cs.cornell.edu/payette/papers/ECDL98/FEDORA.html>. 2. Fedora software releases and documentation are available at: <http://www.fedora.info/>. 3. Staples, Thornton, and Ross Wayland. "Virginia Dons Fedora: A Prototype for a Digital Object Repository." D-Lib Magazine, July/August 2000. <doi:10.1045/july2000-staples>. 4. Information about the UVa Library's metadata standards is available at: <http://www.lib.virginia.edu/digital/metadata/>. 5. Information on the UVa Library's production standards are available at: <http://www.lib.virginia.edu/digital/reports/uvalib_production_standards.htm>. 6. Information about the UVa Library's TEI encoding practices is available at: <http://text.lib.virginia.edu/bin/cgi-dl/dlps/doco/text/practices/dlpsPractices_postkb.html>. 7. Information about the UVa Library's EAD best practices as a part of the Virginia Heritage Project is available as a PDF at: <http://www.lib.virginia.edu/small/vhp/download/VHBPG2004.pdf>. 8. Thinkmap is a commercial product from Thinkmap, Inc, at: <http://www.thinkmap.com/>. 9. The MyLibrary@Ockham project has done interesting work in analyzing indexes and enhancing search with ASPELL, WordNet, and statistical analysis to create their "Find More Like This One" service. More information on the work is available at: <http://mylibrary.ockham.org/>. Copyright © 2005 Leslie Johnston |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/october2005-johnston
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||