 |
T A B L E O F C O N T E N T S
N O V E M B E R / D E C E M B E R 2 0 1 5
Volume 21, Number 11/12
DOI: 10.1045/november2015-contents
ISSN: 1082-9873
E D I T O R I A L
Holiday Reading
Editorial by Laurence Lannom, Corporation for National Research Initiatives
O P I N I O N
Reminiscing About 15 Years of Interoperability Efforts
Opinion by Herbert Van de Sompel, Los Alamos National Laboratory and Michael L. Nelson, Old Dominion University
Abstract: Over the past fifteen years, our perspective on tackling information interoperability problems for web-based scholarship has evolved significantly. In this opinion piece, we look back at three efforts that we have been involved in that aptly illustrate this evolution: OAI-PMH, OAI-ORE, and Memento. Understanding that no interoperability specification is neutral, we attempt to characterize the perspectives and technical toolkits that provided the basis for these endeavors. With that regard, we consider repository-centric and web-centric interoperability perspectives, and the use of a Linked Data or a REST/HATEAOS technology stack, respectively. We also lament the lack of interoperability across nodes that play a role in web-based scholarship, but end on a constructive note with some ideas regarding a possible path forward.
A R T I C L E S
Developing Best Practices in Digital Library Assessment: Year One Update
Article by Joyce Chapman, Duke University Libraries, Jody DeRidder, University of Alabama Libraries and Santi Thompson, University of Houston Libraries
Abstract: The purpose of this scoping study is to answer the research question: What does the literature tell us about online sociability that could inform how participation in collaborative construction of digital cultural heritage (DCH) can be supported, motivated and sustained? A scoping review was conducted with the aim of building on the recent advances in research on online sociability and participatory culture. An extensive literature survey was undertaken across various disciplinary fields to gain a broad snapshot of the factors that have been found and suggested as having an influence on online sociability in collaborative projects. Relevant literature were analysed and weaved together to map a pathway with motifs that could be useful as a guide for projects working towards collaborative construction of DCH.
The OpenAIRE Literature Broker Service for Institutional Repositories
Article by Michele Artini, Claudio Atzori, Alessia Bardi, Sandro La Bruzzo, Paolo Manghi and Andrea Mannocci, Istituto di Scienza e Tecnologie dell'Informazione "A. Faedo" — CNR, Pisa, Italy
Abstract: OpenAIRE is the European infrastructure for Open Access scholarly communication. It populates and provides access to a graph of objects relative to publications, datasets, people, organizations, projects, and funders aggregated from a variety of data sources, such as institutional repositories, data archives, journals, and CRIS systems. Thanks to infrastructure services, objects in the graph are harmonized to achieve semantic homogeneity, de-duplicated to avoid ambiguities, and enriched with missing properties and/or relationships. OpenAIRE data sources interested in enhancing or incrementing their content may benefit in a number of ways from this graph. This paper presents the high-level architecture behind the realization of an institutional repository Literature Broker Service for OpenAIRE. The Service implements a subscription and notification paradigm supporting institutional repositories willing to: (i) learn about publication objects in OpenAIRE that do not appear in their collection but may be pertinent to it, and (ii) learn about extra properties or relationships relative to publication objects in their collection.
Using Scenarios in Introductory Research Data Management Workshops for Library Staff
Article by Sam Searle, Griffith University, Brisbane, Australia
Abstract: This case study describes the inclusion of a scenario-based group learning activity in introductory research data management workshops for librarians at two Australian universities in 2012-2013. The positive response from attendees at these workshops, and the successful re-use of the scenarios at several other Australian universities in 2014-2015, prompted further investigation into scenario-based learning (SBL) and reflection on how this approach could be better applied in future as part of in-house professional development programs for librarians.
Collaborative Construction of Digital Cultural Heritage: A Synthesis of Research on Online Sociability Determinants
Article by Chern Li Liew, Victoria University of Wellington, New Zealand
Abstract: The purpose of this scoping study is to answer the research question: What does the literature tell us about online sociability that could inform how participation in collaborative construction of digital cultural heritage (DCH) can be supported, motivated and sustained? A scoping review was conducted with the aim of building on the recent advances in research on online sociability and participatory culture. An extensive literature survey was undertaken across various disciplinary fields to gain a broad snapshot of the factors that have been found and suggested as having an influence on online sociability in collaborative projects. Relevant literature were analysed and weaved together to map a pathway with motifs that could be useful as a guide for projects working towards collaborative construction of DCH.
Efficient Table Annotation for Digital Articles
Article by Matthias Frey, Graz University of Technology, Austria and Roman Kern, Know-Center GmbH, Austria
Abstract: Table recognition and table extraction are important tasks in information extraction, especially in the domain of scholarly communication. In this domain tables are commonplace and contain valuable information. Many different automatic approaches for table recognition and extraction exist. Common to many of these approaches is the need for ground truth datasets, to train algorithms or to evaluate the results. In this paper we present the PDF Table Annotator, a web based tool for annotating elements and regions in PDF documents, in particular tables. The annotated data is intended to serve as a ground truth useful to machine learning algorithms for detecting table regions and table structure. To make the task of manual table annotation as convenient as possible, the tool is designed to allow an efficient annotation process that may spawn multiple session by multiple users. An evaluation is conducted where we compare our tool to three alternative ways of creating ground truth of tables in documents. Here we found that our tool overall provides an efficient and convenient way to annotate tables. In addition, our tool is particularly suitable for complex table structures, where it provided the lowest annotation time and the highest accuracy. Furthermore, our tool allows annotating tables following a logical or a functional model. Given that using our tool, ground truth datasets for table recognition and extraction are easier to produce, the quality of automatic tables extraction should greatly benefit.
Structured Affiliations Extraction from Scientific Literature
Article by Dominika Tkaczyk, Bartosz Tarnawski and Łukasz Bolikowski, Interdisciplinary Centre for Mathematical and Computational Modelling, University of Warsaw, Poland
Abstract: CERMINE is a comprehensive open source system for extracting structured metadata from scientific articles in a born-digital form. Among other information, CERMINE is able to extract authors and affiliations of a given publication, establish relations between them and present extracted metadata in a structured, machine-readable form. Affiliations extraction is based on a modular workflow and utilizes supervised machine learning as well as heuristic-based techniques. According to the evaluation we performed, the algorithm achieved good results both in affiliations extraction (84.3% F1) and affiliations parsing (92.1% accuracy) tasks. In this paper we outline the overall affiliations extraction work flow and provide details about individual steps' implementations. We also compare our approach to similar solutions, thoroughly describe the evaluation methodology and report its results. The CERMINE system, including the entire affiliations extraction and parsing functionality, is available under an open-source licence.
NLP4NLP: The Cobbler's Children Won't Go Unshod
Article by Gil Francopoulo, IMMI-CNRS + TAGMATICA, France; Joseph Mariani, IMMI-CNRS + LIMSI-CNRS, France; Patrick Paroubek, LIMSI-CNRS, France
Abstract: For any domain, understanding current trends is a challenging and attractive text mining task, especially when suitable tools are recursively applied to publications from the very domain they come from. Our research began by gathering a large corpus of Natural Language Processing (NLP) conferences and journals for both text and speech, covering documents produced from the 60's up to 2015. Our intent is to defy the old adage: "The cobbler's children go unshod", so we developed a set of tools based on natural language technology to mine our scientific publication database and provide various interpretations according to a wide range of perspectives, including sub-domains, communities, chronology, terminology, conceptual evolution, re-use, trend prediction, and novelty detection.
MapAffil: A Bibliographic Tool for Mapping Author Affiliation Strings to Cities and Their Geocodes Worldwide
Article by Vetle I. Torvik, University of Illinois at Urbana-Champaign
Abstract: Bibliographic records often contain author affiliations as free-form text strings. Ideally one would be able to automatically identify all affiliations referring to any particular country or city such as Saint Petersburg, Russia. That introduces several major linguistic challenges. For example, Saint Petersburg is ambiguous (it refers to multiple cities worldwide and can be part of a street address) and it has spelling variants (e.g., St. Petersburg, Sankt-Peterburg, and Leningrad, USSR). We have designed an algorithm that attempts to solve these types of problems. Key components of the algorithm include a set of 24,000 extracted city, state, and country names (and their variants plus geocodes) for candidate look-up, and a set of 1.1 million extracted word n-grams, each pointing to a unique country (or a US state) for disambiguation. When applied to a collection of 12.7 million affiliation strings listed in PubMed, ambiguity remained unresolved for only 0.1%. For the 4.2 million mappings to the USA, 97.7% were complete (included a city), 1.8% included a state but not a city, and 0.4% did not include a state. A random sample of 300 manually inspected cases yielded six incompletes, none incorrect, and one unresolved ambiguity. The remaining 293 (97.7%) cases were unambiguously mapped to the correct cities, better than all of the existing tools tested: GoPubMed got 279 (93.0%) and GeoMaker got 274 (91.3%) while MediaMeter CLIFF and Google Maps did worse. In summary, we find that incorrect assignments and unresolved ambiguities are rare (< 1%). The incompleteness rate is about 2%, mostly due to a lack of information, e.g. the affiliation simply says "University of Illinois" which can refer to one of five different campuses. A search interface called MapAffil has been developed at the University of Illinois in which the longitude and latitude of the geographical city-center is displayed when a city is identified. This not only helps improve geographic information retrieval but also enables global bibliometric studies of proximity, mobility, and other geo-linked data.
PubIndia: A Framework for Analyzing Indian Research Publications in Computer Science
Article by Mayank Singh, Soumajit Pramanik and Tanmoy Chakraborty, Indian Institute of Technology, Kharagpur, India
Abstract: This paper describes PubIndia, a framework for analyzing the growth and impact of research activities performed in India in the computer science domain, based on the evidence of scientific publications. We gathered and analyzed a massive publication dataset of more than 2.5 million papers in the computer science domain with rich metadata information associated with each paper. Specifically, we attempted to analyze the temporal evolution of the collaboration pattern and the shift in research work among different topics, and made a thorough comparison between Indian and Chinese research activities. A preliminary analysis on a subset of papers on Natural Language Processing extracted from the large dataset revealed that Indian researchers tend to collaborate with researchers outside of India quite often; however Chinese researchers tend to work among themselves. We also show the evolutionary landscape of different keywords that indicate how the importance of individual keywords varies over the years.
Semantometrics in Coauthorship Networks: Fulltext-based Approach for Analysing Patterns of Research Collaboration
Article by Drahomira Herrmannova, KMi, The Open University and Petr Knoth, Mendeley Ltd.
Abstract: To date, many studies of scientific citation, collaboration and coauthorship networks have focused on the concept of cross-community ties. In this article we explore how Semantometrics can help to characterise the types of research collaboration in scholarly publication networks and the nature of the cross-community ties, and how this information can be utilised in aiding research evaluation. In contrast to the existing research evaluation metrics such as Bibliometrics, Altmetrics or Webometrics, which are based on measuring the number of interactions in the scholarly network, Semantometrics build on the premise that fulltext is needed to understand the value of publications. Using the CORE dataset as a case study, this paper looks at the relation between the semantic distance of authors and their research endogamy value. We identify four potential types of collaboration in a coauthorship network. The results suggest similar measures can be used to provide meaningful information about the nature of collaboration in scholarly publication networks.
N E W S & E V E N T S
In Brief: Short Items of Current Awareness
In the News: Recent Press Releases and Announcements
Clips & Pointers: Documents, Deadlines, Calls for Participation
Meetings, Conferences, Workshops: Calendar of Activities Associated with Digital Libraries Research and Technologies
|
|
F E A T U R E D D I G I T A L
C O L L E C T I O N

Image of Mantis Shrimp. Author: Roy Caldwell.
[Copyright 1994-2015 by the Regents of the University of California. Used with permission.]

Tribrachidium heraldicum.
[Copyright 1994-2015 by the Regents of the University of California. Used with permission.]
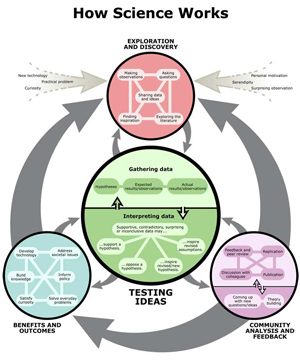
How Science Works
[Copyright 2008 by the University of California Museum of Paleontology and the Regents of the University of California. Used with permission. ]
The history of the University of California Museum of Paleontology is a long and interesting one. At present, The University of California Museum of Paleontology (UCMP) has the largest paleontological collection of any university museum in the world.
UCMP's mission is "to investigate and promote the understanding of the history of life and the diversity of the Earth's biota through research and education." UCMP's collections are well-curated and the computerized collections include fossil and modern organisms representing prokaryotes to vertebrates collected from all continents. The collections are used by paleontologists, biologists and geologists throughout the world.
The Museum serves the University community in various research projects and provides support for instruction at the undergraduate and graduate levels at Berkeley and other UC campuses. In addition, the UCMP provides educational support for K-12 teachers and their students through online resources and professional development, such as short courses and a summer institute for science educators. Programs for the public are also offered at various times throughout the year. These programs change from year to year and might include tours, lectures, hands-on activities and displays.
UCMP has developed several other outreach websites to promote science and science education, including Understanding Science and Understanding Evolution.
Contributed by Trish Roque
University of California, Berkeley
troque@berkeley.edu.
D - L I B E D I T O R I A L S T A F F
Laurence Lannom, Editor-in-Chief
Allison Powell, Associate Editor
Catherine Rey, Managing Editor
Bonita Wilson, Contributing Editor
|