D-Lib Magazine
May/June 2017
Volume 23, Number 5/6
Table of Contents
SHARE: Community-focused Infrastructure and a Public Goods, Scholarly Database to Advance Access to Research
Cynthia R. Hudson-Vitale, Washington University in St. Louis
chudson [at] wustl.edu
Richard P. Johnson, University of Notre Dame
rick.johnson [at] nd.edu
Judy Ruttenberg, Association of Research Libraries
judy [at] arl.org
Jeffrey R. Spies, Center for Open Science, University of Virginia
jeff [at] cos.io
https://doi.org/10.1045/may2017-vitale
Abstract
SHARE has a schema-agnostic approach to aggregate diverse and distributed scholarly metadata in order to build a broadly inclusive open data set about scholarship to power innovation and discovery. In an environment where metadata standards vary widely by discipline or domain, distributed digital assets — while intellectually linked to other objects in the ecosystem — may lack the necessary information to intuit these relationships directly, including strong identifiers for people, institutions, or sources of funding. Aggregating metadata across diverse data sources and repositories is essential for making related content discoverable — especially content that may not currently have first-class status in scholarship. Related contextual objects, beyond publications, support replicability, reproducibility, and reuse. It is impractical to ask each of these diverse data sources to adopt and implement a common metadata format when the incentives for doing so are low. Instead, SHARE is harvesting, normalizing, and linking dispersed assets into an aggregated, open data set of research outputs. This is producing tangible demonstrations of the power of a public goods database to provide notifications or reports of research activity and promote discovery. These demonstrations will entice institutions to enhance their metadata in SHARE or use SHARE to clean and augment metadata in their repositories.
Keywords: SHARE, Scholarly Metadata, Institutional Repositories, Metadata Schemas
1 Introduction
"One researcher's metadata is another researcher's data"
Aggregated, diverse object-type metadata facilitates discovery, gives more exposure and credence to previously overlooked digital assets (e.g., data, code, software, patents), and contributes significantly to research involving meta-analyses and meta-scholarship. Given the dispersed and specialized nature of much scholarship and research, an aggregated (meta)data set is necessary to determine links and relationships among research assets. This information is especially important to scholars, institutions, and funders, all of whom are engaged in tracking research activity for various purposes. SHARE emerged within North American higher education in 2013 to address the gap in digital infrastructure by connecting research activity across disciplinary, agency, and institutional repositories in a timely and structured manner (ARL, 2014, Walters and Ruttenberg, 2014).
There are and were, within research or other academic communities, a variety of schemas and extensions that developed to facilitate the aggregation of metadata from multiple repositories (Riley, 2009). The growth over the past few decades of discipline-specific metadata elements and controlled vocabularies has allowed researchers in particular academic domains the ability to share data and exchange information about research in a structured, interoperable format. Further, this development and adoption has facilitated data reuse among research domain communities by providing important technical, descriptive, and contextual information (Yarmey & Baker, 2013, Qin & Li, 2013).
But the proliferation of many metadata schemas and controlled vocabularies is not without its challenges. While the use of a specific metadata schema encourages sharing among researchers within a given subject domain or object type, the disciplinary focus often limits the extensibility of the metadata schema to other domains or types of objects, which limits the discoverability of the research to only those who are most familiar (Willis, et.al., 2012). A recent presentation by Cox (2016) further highlighted the challenges in the use of controlled vocabularies, when he found eleven different definitions of the word "soil," some from the same taxonomic organization.
Historically, the need to harmonize different metadata schemas has been addressed through cross-walking and reconciliation efforts, which are hard to scale and are labor intensive for the participating data sources/repositories. For institutional repositories, challenges to creating robust metadata include lack of sufficient human resources, inconsistent access to administrative changes within repository platform software, and variable sourcing of metadata, including from third-party services or by author deposit.
In recent years a number of initiatives have developed in an attempt to catalog and enumerate the variety of metadata schemas available for a scholar, institution, or organization to use to describe their research. In 2013, the Digital Curation Centre (DCC) launched a metadata standards directory that breaks down a variety of metadata schemas by discipline and provides a short description of each schema's use (DCC Metadata Standards Directory, 2013). Around this same time, the Research Data Alliance (RDA), in collaboration with the DCC, developed a community-supported version of the metadata standards directory (Ball, 2014). While containing many of the same standards, the RDA directory is more highly structured in what information it is reporting, including use cases, metadata extensions, and tools. While both the DCC and RDA directories are extremely useful for discovering and comparing different metadata schemas, neither is exhaustive in its listing.
To address the need for an aggregated (meta)data set of research and scholarship, appropriately account for the variety of metadata standards, and lower the barrier to participation among repositories, the SHARE initiative adopted a schema-agnostic approach to harvesting scholarly and research metadata. SHARE, a partnership of the Association of Research Libraries (ARL) and the Center for Open Science (COS), employs multiple strategies to harvest, ingest, map, and normalize metadata. These strategies include harvesting from OAI-PMH, and non-standard application programming interfaces (APIs); having sources push records to SHARE; and in some cases web scraping. In this way, SHARE has moved beyond any one protocol or any one type of repository as the exclusive target for harvesting and towards an ecosystem of evolving information resources.
SHARE is a community-based project and came to its inclusive strategy through community consultation, including working and task groups of experts in metadata, digital libraries, and publishing. SHARE is centered around the driving goal to make a more comprehensive picture of research accessible and open. SHARE assumes that the digital research environment is both complex and distributed. And SHARE embraces a system-wide mission and remit — to provide exposure to research outputs and a mechanism to aggregate and connect those outputs from multiple sources while supplying an open data store for metadata enhancement and maintenance and to feed existing and new services.
2 SHARE metadata harvesting and normalizing pipeline
Each potential metadata provider for SHARE goes through a simple registration process where both the appropriate harvesting mechanism and proper set of records to be harvested are determined. Commonly, API endpoints like OAI-PMH are utilized by SHARE for a given data provider. As the usage of metadata elements and schemas vary across each organization, the SHARE development team customizes the harvesting process for each provider. By not requiring any specific metadata elements to be harvested and by the SHARE team writing necessary harvesters, the efforts placed on repository staff or library IT staff have thus far been minimal. Upon ingest, records are fed to a data processing and normalization pipeline (see Figure 1). From the original request and response, the metadata is processed and normalized by mapping its schema that varies across data providers to the SHARE schema. By performing this process at the time of ingest, SHARE does not require all data providers to conform to one metadata format for interoperability. Data is also archived at each incremental stage of the process for reference or use later, and the final set of normalized data is stored and indexed for discovery.
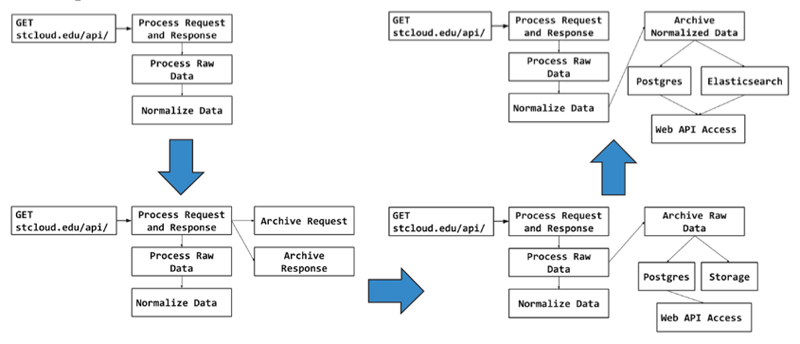
Figure 1: Data Pipeline
Typically, a set of metadata records about research activity (e.g., publications, data sets) is supplied to SHARE. Upon receipt, these metadata elements are then normalized and mapped within SHARE's schema. Associated institutions, co-authors, collaborators, and related works are then derived from common metadata elements across activity records supplied (see Figure 2). Alternatively, data providers may also push records directly to SHARE via its API. When possible, this use of the SHARE API can streamline the normalization and linking of people, institutions, and works within SHARE as mapping can occur at the source.
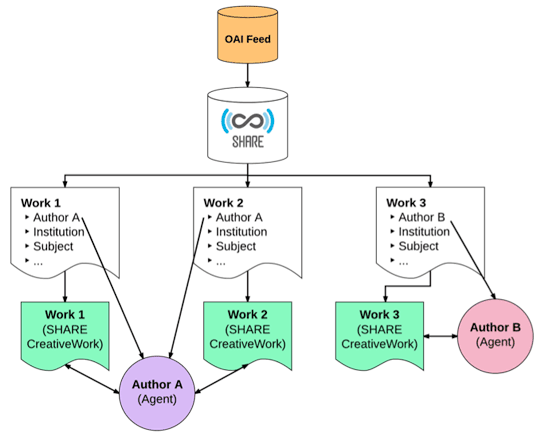
Figure 2: SHARE Object and Relationship Mapping
Within the SHARE project, guidelines are under development to formalize best practices, especially around structure of the metadata values themselves. For example, the use of unique identifiers, authority records, or controlled vocabulary terms greatly accelerates the linking and deduplication of metadata records. Furthermore, identifying which authority and controlled vocabulary schemes are being used (e.g., TGN, DCMI, LCSH) increases precision within the metadata and the confidence with which SHARE asserts relationships between records.
3 SHARE API
Metadata harvested, normalized, and enhanced are then made widely available through the SHARE discovery application programming interface (API), which queries SHARE's Elasticsearch index. Individuals can search across the normalized metadata to discover and make connections among the varying research outputs. For institutions and researchers, the SHARE data set may be used to:
- discover research and data for reuse or to assess the rigor of a research study
- populate researcher profiling systems
- visualize collaborative networks
- support institutional open access policies
- conduct meta-analyses
With the flexibility of the SHARE API, specific providers, work types, subjects, and funders can be discovered using the controlled, discipline-specific vocabulary, or the normalized terms. In aggregating the dispersed sources, and making the metadata available through a common API, duplication of efforts and redundancies across institutions can also be reduced. Rather than searching each individual provider independently for related materials or using different search syntaxes and controlled vocabularies, a user can access the SHARE API and search across all at once. As a developer, this also decreases the need for any one-on-one connections for application development or feeds from a source to a local repository. The SHARE Institutional Dashboard being developed collaboratively between UC San Diego and the Center for Open Science (described in the "Applications and Tools" section below) is one such solution that allows an institution to search at once across many distributed sources.
Several institutions use SHARE's push API to add metadata records to SHARE. In some cases, this is an alternative to providing records to SHARE via OAI-PMH from their repository or database. As is the case with UC San Diego and its institutional dashboard, the push API is also being used to supply additional records aggregated or created that are related to people or work originating from their institution and directly assert relationships between those records.
4 Applications and Tools
One of SHARE's greatest strengths is the platform it provides to develop tools and services for collecting, using, exchanging, and analyzing research assets. Through the SHARE API, new tools for research discovery and aggregation are being built that further facilitate the discovery of research outputs and display them in a manner that is reflective of community needs, while leveraging a public good.
4.1 OSF Preprints and Registries
In the last year the scholarly community has seen an explosion of pre-publication paper (pre-print) services and discussions around their potential role in a changing scholarly communication environment. For those disciplines that have a robust history of pre-publication sharing, such as math, physics, and economics, different sets of metadata elements and taxonomies are in use to gather the necessary domain terms to describe the pre-prints adequately. Additionally, many of the existing pre-print services are dispersed across institutions, organizations, and technologies, which are also often limited to a specific discipline and community.
The Center for Open Science saw a need to develop infrastructure to facilitate the discovery and the aggregation of these dispersed pre-print records. By harnessing the existing infrastructure of the SHARE data set and the Open Science Framework (OSF), COS launched a multidisciplinary preprint server and aggregated discovery service, OSF Preprints. Powered by SHARE, OSF Preprints allows an individual to search across many dispersed pre-print servers and records at once. OSF Preprints and its discovery layer can also be branded for particular organizations or disciplinary outreach groups; branded services exist for sociology (SocArXiv), psychology (PsyArXiv), engineering (engrXiv), agriculture (AgrXiv), and the Berkeley Initiative for Transparency in the Social Sciences (BITTS).
By aggregating and normalizing dispersed metadata from many sources SHARE has similarly enabled the development of a tool that aids in the discovery of research registrations, a concept common in, for example, clinical trials. Registrations are time-stamped, (ideally) immutable versions of a research project meant to increase transparency and accessibility to work; they often include documentation or metadata about the state of the project at a given point in time. A pre-registration is a registration created before data collection begins that captures hypotheses and documents what will be tested in a confirmatory analysis. This allows these analyses to retain validity of their statistical inferences and assists readers in separating confirmatory analyses from exploratory analyses that may lead to future confirmatory work. OSF Registries includes registrations from a variety of domains, including the medical sciences, government, and politics. With SHARE, OSF Registries makes possible the searching of multiple registries through one interface.
4.2 SHARE Institutional Dashboard
Research and higher education institutions have a strong interest in understanding the research-related outputs of their faculty and staff. Aggregating and discovering this information is time-consuming and expensive given the variety of research assets dispersed across applications (e.g., data sets, pre-prints, award information, patents, publications), inconsistent adoption of strong identifiers for people and institutions despite the maturity of community standards (e.g., ORCID, OpenISNI), and highly variable metadata.
In collaboration with the UC San Diego Libraries (UCSD), an institutional dashboard of research assets is currently in development as an application layer on top of the SHARE API. The dashboard provides faceted views and visualizations of institutionally affiliated metadata found in the SHARE data set. Built as flexible JavaScript widgets, the open source dashboard allows institutions to pick and choose the facets, charts, and information they are most interested in displaying on their custom institutional dashboard.
Developing the dashboard application requires metadata that is curated to include institutional affiliations for each record. Unfortunately, the use of affiliation identifiers is not widespread in many metadata records. By adopting affiliation identifiers in organizational metadata, such as OpenISNI or GRID (Wheeler, 2015), a number of institutional disambiguation issues can be reduced.
For the UCSD pilot project, affiliations are made using a combination of programmatic and human-mediated efforts. As records are coming from many disparate sources, a useful technique has been to apply a controlled list of aliases to query for affiliation (e.g., UCSD, UC San Diego, UC San Diego Library).
5 Community
The creation of high-quality metadata using any general, domain, or discipline schema requires an investment of individual time and resources. While SHARE continues working on automatic techniques to enhance metadata records, these approaches are not infallible for all types of missing metadata values (Liu, 2016). Thus metadata practitioners, curators, and repository staff within the SHARE community are an integral component to the curation and metadata ingest workflow. Through this community, institutions and organizations can begin to collectively address many of our shared challenges and successes associated with quality metadata, curation treatments, institutional analytics, and more.
Through programs that build community and technical capacity, such as the SHARE Curation Associates pilot program, participants learn and exchange treatments and techniques to enhance their own local, institutional metadata. As SHARE providers, any enhancements the Associates make locally on a repository or in metadata records are also fed into the SHARE data set, which is then widely shared. Similarly, data enhanced by SHARE can be used locally. This results in a sustainable, round-trip enhancement of metadata that has both local and national impact.
6 Conclusion
One of SHARE's core values is openness. By creating and aggregating open, research-related metadata, software, assets, and tools, SHARE is contributing to a larger movement towards open science and open scholarship. Through these movements, scientific innovation is catalyzed and efficiencies in research funding and studies can be improved. Just as the larger movement requires involvement of researchers and faculty to further move ahead, SHARE needs the continued involvement of the community to use the data set, build applications on top of the API, and curate or enhance the metadata.
In 2017 SHARE will be transitioning to a new governance structure comprised of SHARE's most active contributors and stakeholders. Local and community needs surfaced through this group and other partners will be a driving force behind the development of new tools and services leveraging SHARE. While the community continues to use many metadata schemas and standards — a reality that cannot be avoided — the SHARE approach cannot be addressed fully by any one organization. SHARE is focusing efforts on growing its community of collaborators in order to distribute curation, support, development, and maintenance. Direct collaboration also enables community members to shape solutions like the SHARE data set to best realize their own objectives now and in the future.
References
| [1] |
Association of Research Libraries. SHARE Notification System Project Plan. Washington, D.C: Association of Research Libraries, 2014. |
| [2] |
Ball, Alexander, et al. Building a Disciplinary Metadata Standards Directory. International Journal of Digital Curation 9.1 (2014): 142-151. https://doi.org/10.2218/ijdc.v9i1.308 |
| [3] |
Cox, Simon. 'What Does That Symbol Mean? — Controlled Vocabularies and Vocabulary Services'. SciDataCon 2016. Denver, Colorado. 2016. |
| [4] |
Digital Curation Centre. Disciplinary Metadata | Digital Curation Centre., n.p., n.d. |
| [5] |
Liu, Jiankun. Classifying Research Activity in SHARE with Natural Language Processing. SHARE. n.p., 18 May 2016. |
| [6] |
Qin, Jian, and Kai Li. How Portable Are the Metadata Standards for Scientific Data? A Proposal for a Metadata Infrastructure. International Conference on Dublin Core and Metadata Applications (2013): 25-34. |
| [7] |
Riley, Jenn. Seeing Standards: A Visualization of the Metadata Universe. 2009-2010. |
| [8] |
Walters, Tyler, and Judy Ruttenberg. Shared Access Research Ecosystem. Educause Review 24 March 2014. |
| [9] |
Wheeler, Laura. Digital Science Launches GRID, a New, Global, Open Database Offering Unique Information on Research Organisations. Digital Science. n.p., 12 Oct. 2015. |
| [10] |
Willis, Craig, Jane Greenberg, and Hollie White. Analysis and Synthesis of Metadata Goals for Scientific Data. Journal of American Society for Information Science and Technology (2012): 1505-1520. Print. |
| [11] |
Yarmey, Lynn, and Karen S. Baker. Towards Standardization: A Participatory Framework for Scientific Standard-Making. International Journal of Digital Curation 8.1 (2013): 157-172. https://doi.org/10.2218/ijdc.v8i1.252 |
About the Authors
Cynthia R. Hudson-Vitale is the Data Services Coordinator in Data & GIS Services at Washington University in St. Louis Libraries. In this position, Cynthia leads research data services and curation efforts for the Libraries. Since coming into this role in 2012, she has worked on faculty projects to facilitate data sharing and interoperability while meeting faculty research data needs throughout the research lifecycle. She has also worked across the University to improve research reproducibility, addressing both technical and cultural barriers. She currently serves as the Visiting Program Officer for SHARE with the Association of Research Libraries.
Judy Ruttenberg is the Program Director for Strategic Initiatives with the Association of Research Libraries. She is primarily responsible for managing the SHARE initiative. While at ARL, Judy has also directed the Transforming Research Libraries initiative, which included responsibility for e-research and special collections working groups. Judy works closely with her colleagues in public policy and diversity and inclusion in advancing the agenda of accessibility and universal design within ARL. Prior to joining ARL in 2011, Judy was a program officer at the Triangle Research Libraries Network (TRLN) where she coordinated the work of TRLN's collections groups, focusing on issues such as collections analysis, shared collections, and large-scale digitization.
Richard P. Johnson is the Co-Program Director, Digital Initiatives and Scholarship and Head, Data Curation and Digital Library Solutions at the University of Notre Dame, Hesburgh Libraries. He directs the design and development of the Libraries' data curation and digital library solutions for research, teaching, and learning. These include CurateND, the library's service to curate, preserve, and spotlight collections and research at Notre Dame. Rick also provides oversight of data management planning services within the libraries, and supports activities in the Center for Digital Scholarship. He currently serves as the Visiting Program Officer for SHARE with the Association of Research Libraries.
Jeffrey R. Spies is the co-founder and Chief Technology Officer of the Center for Open Science (COS), a non-profit technology company missioned to increase openness, integrity, and reproducibility of scholarly research. Jeff is also the co-director of SHARE. Jeff has a Ph.D. in Quantitative Psychology from the University of Virginia where he now holds a visiting assistant professor position in the Department of Engineering and Society. His dissertation included the development of the Open Science Framework, a free, open source scholarly commons that is now the flagship product of COS.