D-Lib Magazine
May/June 2015
Volume 21, Number 5/6
Table of Contents
Metamorph: A Transformation Language for Semi-structured Data
Markus Michael Geipel, Christoph Böhme, and Jan Hannemann
German National Library
Corresponding Author: Christoph Böhme, c.boehme@dnb.de
DOI: 10.1045/may2015-boehme
Printer-friendly Version
Abstract
In this paper we present Metamorph, a data flow-oriented language for transforming semi-structured data. Its declarative style facilitates communication between programmers and domain experts. Metamorph is embedded in a pipes and filters framework implemented as a Java library. It is both format-agnostic and extendable. Metamorph has become an integral part of the IT-infrastructure of the German National Library, where it is used in several applications and services. Due to its publication as Open Source Software Metamorph has acquired a user community which actively supports further development.
1 Introduction
The Metamorph language springs from the need to process and transform metadata, a central ingredient of any information storage and retrieval system. Being defined as "data on data", metadata provides descriptive information on the items stored in a library, an archive, or a web search engine.
The variety of possibly stored items is reflected in the plethora of existing metadata formats, which emerged in different communities: libraries, museums, booksellers, etc. In order to maintain interoperability in the face of such diversity and constant change, metadata transformation is essential. Transformations are not only performed to exchange data between institutions and domains: they are also an integral part of cross-collection searches, indexing, presentation in user-interfaces, and preprocessing for statistical analyses.
In technical terms, metadata is semi-structured data. Two major characteristics make metadata processing challenging. Firstly, loose typing: information is often specified as free text. For instance, one might think that the publication year of a book would be a date or an integer. However, values such as "ca. 1610", "150?" or "1710—" are quite common in library catalogs (based on our own analysis of German catalog data). This means that complex normalization is required for meaningful data processing. When general purpose programming languages are used, code tends to be convoluted due to the abundance of conditional branching. Secondly, metadata is characterized by loose adherence to data schemas which themselves may change frequently. An example for this is the cataloging practice in German libraries: how bibliographic records are filled is defined by a set of rules called RAK [35]. These rules are interpreted by catalogers, and due to this room for interpretation automatic validation is hardly feasible. Again, this flexibility leads to complex data processing code, which is hard to test and maintain.
Overall, the characteristics of metadata match the definitions of semi-structured data [3, 15, 42]. This paper presents a declarative, flow-oriented language for semi-structured data transformation.
A useful data transformation language should address three challenges: universality, transparency and efficiency.
Universality: Several formats of semi-structured data exist, such as the Object Exchange Model (OEM) [42], the Extensible Markup Language (XML) [11, 12], the Resource Description Framework (RDF) [1, 38], the Javascript Object Notation (JSON) [22], and the YAML Ain't Markup Language (YAML) [6]. Additionally, there are many domain-specific formats, e.g. MARC21, PICA and MAB (See [33, pp 195]) in the library domain. Ideally, a transformation language is independent of these particular input and output formats, and allows the user to define transformations on a more abstract level. That way transformations defined in such a language can be applied to data coming from a bibliographic record in MARC21 the same way it could be applied to data in XML, comma separated values or data coming from a database. In addition to handling semi-structured data from various domains, such an approach also allows for conversion between different data formats.
Transparency: Metadata transformation is typically a complex and sometimes tedious process requiring both domain knowledge and programming skill. The standard procedure is that a programmer implements a conceptual mapping created by a domain expert. This means that in practice, information tends to flow one-way from expert to programmer. What the programmer really implements is difficult to be double-checked by the domain expert as he or she in turn often lacks the fluency in the respective programming language the transformation is realized in. The challenge is thus to facilitate the exchange between programmer and domain expert, by defining transformations in a transparent way, stripped of implementation details. This is the classical use case for a domain specific language (DSL) [39]. Ideally, end user development [25, 46] is possible, i.e., the domain expert would be able to code transformations without the help of a programmer.
Efficiency: Efficiency is paramount when dealing with large data sets. The larger the data set the less feasible approaches become that build models of the entire data set, such as XSLT tends to do. Event-based processing models tend to scale much better.
Metamorph, the transformation language we present in this paper, addresses these challenges. Furthermore, Metamorph is part of the Open Source Metafacture project and supported by an active community. The source is hosted at github. The official user guide can be found here. Metamorph is also available via Maven Central: to use Metamorph in your Java Maven projects just include the XML snipped in Listing 1 in the dependencies section of the pom.xml.

Listing 1: Adding Metamorph to a Java Maven project.
The remainder of this paper is organized as follows. In Section 2 we provide a review of related work and discuss how Metamorph differs from existing approaches. In Section 3 the framework of Metamorph is presented, including a discussion of the data model and the data processing paradigm which provide the conceptual basis for the transformation language. Section 4, describing the actual transformation language, forms the central piece of this publication. It is followed by a brief presentation of applications using Metamorph in Section 5. Section 6.4 concludes the paper with a discussion of the scope and limitations of Metamorph, as well as future prospects.
2 Related Work
In recent years semi-structured data has received increased attention from practitioners and a variety of solutions for storage and retrieval of semi-structured data have emerged. They are commonly referred to as NoSQL databases, emphasizing the opposition to the strict schema used in SQL databases. Examples are MongoDB or CouchDB. Relaxing the schema and normalization requirements may also give a boost to the performance as Bigtable [19] or HBase [30] demonstrate. Furthermore, new formats for encoding semi-structured data have been introduced, e.g., JSON [22].
While there have been considerable advances in the field of storing and retrieving semistructured data, transformations of semi-structured data still tend to be solutions written from scratch for each individual use case, with scarce tool support and little (code) reuse, despite being such a ubiquitous task. Except for the XML-centered XSLT [21] there is currently no dominant solution.
In the following we give an overview of existing languages for querying semi-structured data as approaches for transformation. As Metamorph is a flow-oriented language, similarities and differences to the aims and scope of other flow-oriented languages are discussed in Section 2.2.
2.1 Query and Transformation Languages
The rise of semi-structured data and XML in particular triggered the development of a number of languages for querying and transforming such data (see [4, 13] for overviews). The difference between query and transformation languages is often not clear-cut since transformation usually involves selecting (i.e. querying) those elements of the input data which should be transformed and included in the output data. Hence, transformation languages often include elements which allow querying a semi-structured data source. Well-known query and transformation languages for semi-structured data include XQuery [10] and XSLT [21]. Both rely on XPath [8] for addressing XML elements.
In his overview paper [4] Bailey distinguishes two main types of languages for element selection in semi-structured data: navigational languages and positional languages. In navigational languages elements are selected by describing a path through the semistructured data object (e.g. an XML document) leading from a start element (or context element) to the element that is to be selected. Positional languages in contrast select elements by describing patterns matching the elements that should be selected. XPath and consequently XQuery and XSLT use a navigatorial approach to locate elements in the XML data. Since this approach can lead to complex selection specifications [7], other query languages were developed that use a positional approach. A recent example of such languages is the XML query language Xcerpt [7]. In addition to using a positional approach for selecting data, Xcerpt has the ability to create graphical representations of Xcerpt scripts, a feature similar to Metamorph's visualization. See Section 4.7.2.
Allowing the selection of arbitrary elements in an input document can severely restrict the ability of a transformation processor to process a stream of semi-structured data. A point in case is XSLT which allows to refer to any element in the document using XPath expressions. In order to mitigate the effects this can have on the ability of XSLT processors to work on data streams (such as those created by SAX), Becker developed the Streaming Transformations for XML (STX) [5, 20]. The core feature of this language is a selection language based on XPath 2.0, which only allows backward selection of elements.
Metamorph differs from the transformation languages described above in a number of ways. First, Metamorph is not bound to any specific data format such as XML but operates on an abstract data model instead (see Section 3.2). This data model is well-suited to represent the heavily structured data consisting of numerous small data fields that is often found in metadata. By excluding complex features such as namespaces or attributes the data model of the transformation language is kept concise. However, it is still possible to map XML onto this simpler data model. Second, in contrast to most other transformation languages, which follow the idea of transformation by querying, Metamorph is built from ground up on the concept of transforming a stream of events. Third, Metamorph differs from XSLT by relying on the positional approach for data addressing as opposed to the navigational approach.
Apart from query and transformation languages focusing on semi-structured data in XML format the emergence of NoSQL and distributed data processing frameworks such as Apache Hadoop gave rise to new paradigms for distributed data processing such as map-reduce [24]. Building on this paradigm new languages have been developed to facilitate distributed processing of semi-structured data. Two examples are JAQL [9] and PIG [41]. Both combine declarative features with a classical iterative programming model. In contrast, Metamorph follows a purely declarative, flow-oriented programming model, and does not have built-in support for map-reduce at the language level. It has, however, been successfully used in combination with map-reduce (see also Section 5.1).
2.2 Flow Languages
Metamorph is a flow language, defining the transformation process in a declarative fashion. It shares the critique of control-flow orientation put forth by flow language advocates. Morrison, who refers to the flow concept as Data Stream Linkage Mechanism argues as follows: "[The Data Stream Linkage Mechanism] can increase the productivity of programmers and can result in programs that are easier to understand and maintain" [40]. In the context of Metamorph this means that domain experts can concentrate on declaratively defining how output is assembled from input without having to worry about control-flow aspects such as if-statements or loops. We argue that in the domain of metadata transformation this shift of focus is beneficial and facilitates the integration of domain experts in the development process.
Flow language advocates put forth another argument: Johnston points out in a survey article, that "[t]he original motivation for research into data flow was the exploitation of massive parallelism." [37]. The same point of view is also taken in [29, 44]. The parallelism aspect of flow languages is not shared by Metamorph. Furthermore, Metamorph operates on rather small, self-contained data records (see also Section 3.2). For these reasons, there is no necessity to execute elements of the flow in parallel as parallelism may easily be achieved by splitting the input data along record boundaries and running several Metamoprh instances in parallel.
In summary, Metamorph uses the flow paradigm to enable declarative definition of transformations. It does not use the flow paradigm to enable parallelism.
3 Framework
Before defining the data transformation language itself, the framework within which it operates needs to be defined: firstly, Metamorph employs a Pipes and Filters processing architecture to organize the data flow (Section 3.1). Secondly, the data representation in Metamorph is based on a simple, generic model, which is presented in Section 3.2.
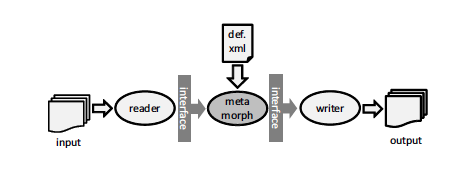
Figure 1: A processing pipeline including a reader, a transformation, and a writer. The transformation is performed by a Metamorph object, configured via a transformation definition.
3.1 Pipes and Filters Pattern
As pointed out in Section 1, a transformation tool should not commit to a specific input or output format (universality). Consider the task of indexing a book catalog: we would need to read the book metadata, select the pieces of information to be indexed (title, author, subject etc.), and finally, pass this information to the indexer. Data may come from a variety of different sources: databases, network connections, local files etc. The indexer might be exchanged for a different one or even replaced with a viewer for debugging purposes. On an abstract level the following characteristics can be identified:
- Non-adjacent processing steps do not share information
- Different sources of input exist
- Final results may be stored in different ways
Given this situation, the software pattern literature suggests a Pipes and Filters pattern to be most expedient [16, p. 54]. Buschmann et al. define this architecture as follows:
"The Pipes and Filters architectural pattern divides the task of a system into several sequential processing steps. These steps are connected by the data flow through the system — the output data of a step is the input to the subsequent step. Each processing step is implemented by a filter component". [16, p. 55]
Figure 1 shows how the transformation language Metamorph employs the Pipes and Filters pattern. Input data is read and converted to events defined by an abstract data model, which acts as an interface between the different processing stages (filters). The data model will be described in the next section. A Metamorph filter receives the events, transforms them, and outputs the result as a new stream of events. The transformation itself is encoded in an XML file, which we refer to as the Metamorph definition. Listing 1 shows the respective Java code, implementing the Pipes and Filters chain depicted in Figure 1. First, the Pipes and Filters objects are created. Second, they are connected to form a processing pipeline. Finally, the pipeline is started by reading the input data. The implementation thus corresponds to passive push filters in the Pipes and Filters taxonomy.
Passive filters are simpler than active ones as they do not need separate threads or processes and neither require buffering. If multi-threading became an issue in the future, it would be possible to equip individual filters with their own thread, making them active.

Listing 2: Constructing a processing pipeline according to the pattern depicted in Figure 1.
3.2 Data Model and Event Interface
To separate the different filters in a pipe from each other, an abstract data model needs to be established. It defines the interface by which filters connect and pass information to the next stage. To find a common denominator, we made the following assumptions:
- The semi-structured data intended for processing can be divided in self-contained units, which we will refer to as records.
- The atomic unit of information is a literal that consists of a name and a value. In the current implementation both are of type String. The rationale is to keep the implementation simple at the current state of development and to follow best practice of metadata formats in the cultural heritage domain, where the string data type is used almost exclusively.
- Literals may be grouped in entities. An entity may be contained within another entity. Entities have a name of type String.
The resulting data structure is depicted in Figure 2.
This data structure is never explicitly instantiated in the processing pipeline for reasons of efficiency, as described in Section 1. This means that there are no such classes as Record or Entity. Instead, the information contained in one record is passed from one filter to the next by means of events. This model of semi-structured data as a stream of events is similar to the Streaming API for XML (SAX) [14]. The events used by Metamorph are defined as Java interface shown in Listing 3. In contrast to SAX, Metamorph uses a smaller set of events and restricts the parameters of all events to simple strings so that no complex data structures (such as lists of attributes) have to be constructed.
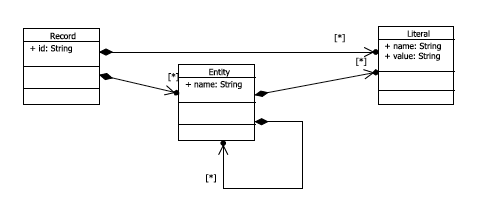
Figure 2: The generic data structure used to model semi-structured data.

Listing 3: The event interface implemented by the filters.
The rationale for this design decision is twofold: firstly, the event-based processing reduces object creation. It avoids having to explicitly create a Record object and all the Entity, Literal and supporting List objects. As object creation is costly [45], this results in faster code and addresses the efficiency challenge discussed in Section 1. Secondly, we avoid having to commit to a specific implementation of the data structure in Figure 2. Implementation decisions would always be application specific. For instance, using hash tables instead of arrays of linked lists to hold entities or literals would favor application scenarios which need random access, deciding otherwise would again mean optimizing for scenarios, in which ordered processing is important. The event-driven model is eclectic in that sense.
Listing 4 gives an example of a semi-structured piece of data. According to the StreamReceiver interface the serializer or reader would invoke the following methods on the next filter in the pipe: startRecord("118559796"); startEntity("prefName"); literal("forename", "Immanuel"); and so forth, ("prefName" is the preferred name of the person). The generic nature of the data model addresses the universality challenge pointed out in Section 1.

Listing 4: An example of a semi-structured piece of data, in a JSON-like syntax (repeated keys are not allowed in JSON, however common in semi-structured data).
4 Transformation Language
From an implementation point of view, Metamorph corresponds to a filter in the pipes and filters architecture described in the previous section. A concrete instance is created according to an XML file which declares the transformations to be applied to the data flow. The flow comprises elements that select literals from the input data, as well as elements for processing and combining data. Figure 3 shows an example of a visual representation of such a data flow. The corresponding Metamorph definition is shown in Listing 5.
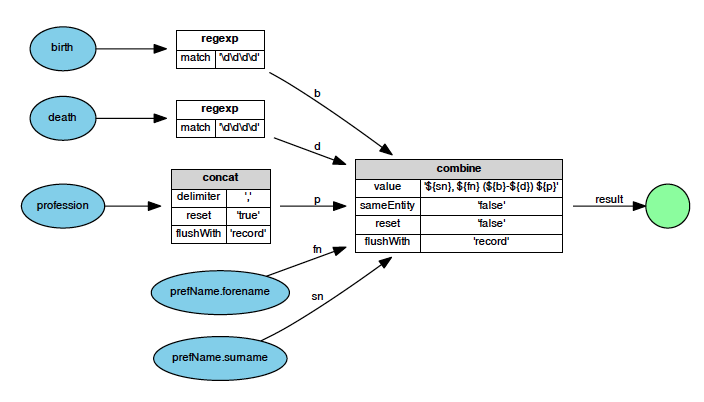
Figure 3: Flowchart of a data transformation. Oval shapes depict inputs. Squares symbolize processing and combination steps, and circles output. The names of the generated literals are shown as arrow labels.

Listing 5: A simple Metamorph definition to construct a short description of a person.
Imagine we want to build a service in which a short description of a person is needed. For instance: "Kant, Immanuel (1724—1804) philosopher, professor, librarian". The data base provides semi-structured data similar to Listing 4. The data is actually a simplified version of the data provided by the Linked Open Data service of the DNB. Several steps are needed to assemble the output: the year of birth and death are extracted from a free text field via a regular expression matching four digit numbers. Professions are concatenated. Finally all parts are combined to form a single name value. Both using XML and making the language declarative lowers the entry barrier for domain experts, and thus adds to transparency (see discussion in Section 1). The example is simplistic of course: there is only one output. The output is itself not structured, just a string. In the following we present a broader selection of Metamorph's features.
4.1 Selection
To start transforming a record of semi-structured data, the pieces of data serving as inputs (see also Figure 3) need to be selected. In the simplest way this is done by providing a path expression. For instance prefName.forename would address the String "Immanuel" in the sample data shown in Listing 4.
Listing 6 shows an example in Metamorph.
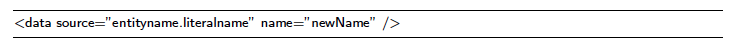
Listing 6: Receiving values from literals.
The dot character is used as delimiter to separate entities and literal names. Metamorph also supports path expressions containing wildcards. For instance, the star-wildcard "person*" matches all literals with names starting with "person", such as "person name", "person age", etc. Apart from the star-wildcard, the question mark wildcard ("?") is supported. It matches exactly one arbitrary character. To match only specific characters Metamorph supports character sets in path expressions. The set "[abc]", for instance, matches one character "a", "b" or "c".
Additionally, sources can be concatenated using the pipe-character to express a logical or relationship: "creator|contributor" would match both 'creator' and 'contributor'. The pipe connects complete source names. It does not apply to parts or characters. More elaborate path matching schemes are conceivable.
The current implementation of Metamorph uses a Trie [27] to efficiently match and dispatch incoming literals. The Trie has been extended to support basic regular expression matching. Its implementation follows the principles outlined in [32].
4.2 Processing
Elements for processing take one literal at a time (name-value pair) and perform a given operation on it. The result may be 0 to n output literals. An example is shown in Listing 7: a regular expression match is applied to the value of the birth literal. If a four digit number is found, it is returned as result; if not the result is void and processing is stopped. Processing elements can be chained and they may maintain state. This makes it possible to filter by occurrence, filter by uniqueness or to delay processing.

Listing 7: Processing data within the data tag.
4.3 Collection
Collection elements are used to build one output literal from a combination of input literals. The example in Listing 8 for instance collects the sur- and forename, both of which are stored in separate literals, to combine them according to the pattern 'surname, forename'.
By default combine waits until at least one value from each data tag is received. If the collection is not complete on record end, no output is generated. After each output the state of combine can be reset. If one data tag receives literals repeatedly before the collection is complete only the last value will be retained.

Listing 8: Combining data from two different data sources.
The standard behavior of combine can be modified with several arguments: flushWith="entityname" generates output on the end of each entity with name entityname. Variables in the output pattern which are not yet bound to a value, are replaced with the empty string. Use flushWith="record" to set the record end as output trigger. reset="true" enables the reset after output: already collected values are discarded. sameEntity="true" will reset the combine after each entity end and thus emit combinations stemming from the same entities only.
Further collection elements include functionality for concatenation, building tuples or making a choice based on priorities.
4.4 Entity Construction
With the elements discussed so far, only the output of named values is possible. Many applications require the output of structured data, though. Structured output is achieved with the entity tag. Listing 9 shows how information about a creator of a media unit (its name stored in fields "100? .a" and role stored in "100? .4") is extracted from a MARC21 record and bundled within a "creator" entity. Entity tags may be nested to create more complex structures.

Listing 9: Combining named values in an entity.
4.5 Recursion
Pieces of data processed with Metamorph are by default sent to the next filter in the pipe. However, there is also the possibility to send them into a feedback loop. In this case the data reenters Metamorph just as if it came from the upstream filter in the pipe. This recursion is accomplished by prepending an '@' to the name of the data. Listing 10 shows an example. While recursive loops are possible with this technique, the main application is literal reuse: imagine two desired outputs partially sharing the same data and processing. The shared partial result can be distributed via the recursion mechanism. Listing 10 shows such a case where two versions of the format literal are generated.

Listing 10: Prepending '@' to the literal name to enable recursive processing.
4.6 Language Implementation
This section discusses specific implementation aspects of Metamorph. Firstly, why we chose XML as format for the definition files. And secondly, how Metamorph filters are instantiated based on such XML descriptions.
4.6.1 Metamorph Definitions in XML
The transformation performed by the Metamorph object is declared in XML. The choice in favor of XML is motivated by three arguments:
- The document object model behind XML is a tree with homogeneous nodes. The mapping of dataflow diagrams such as the one depicted in Figure 3 to an XML-structure (and vice versa) is straight-forward. The definitions are clear and homogeneous enough to keep the XML simple.
- XML parsers for Java are available and mature. They provide syntax checking and build a document object model (DOM) from the XML code. The DOM may serve as an homogeneous abstract syntax tree (AST). Homogeneous ASTs are a fitting choice for non object-oriented languages (see [43, p. 94]).
- Schema-aware XML-editors are wide spread. They offer syntax checking, auto-completion and syntax highlighting based on a schema referenced in the XML and are thus a viable substitute for a full-edged IDE, at least for domain specific languages.
4.6.2 Integration in Java
The mapping of XML tags to the Java objects implementing the flow is straight forward: each tag has a one-to-one correspondence to a Java class implementing it. The name of the tag is connected to the class name via a lookup table, manifested in a Java properties file. The attributes of the tag are mapped to setter-methods of the respective class and invoked via the Java Reflection API [31]. From a software engineering point of view this corresponds to the technique of Dependency Injection as outlined by Fowler [26]. In that sense the Metamorph XML file plays a similar role as the application context XML file in the Dependency Injection framework Spring [36].
4.7 Further Features
Metamorph offers a number of further features. Their detailed description would be beyond the scope of this paper, though. We therefore only briefly point out the most salient ones and refer the reader to the Metamorph User Guide [2] for more information.
4.7.1 Test Framework
As any piece of software, data transformations need to be tested. Doing this in Java can be very tedious, involving large amounts of so called "boilerplate code", i.e. sections of code that have to be included in many different places with little or no alteration. The Metamorph Java library therefore includes a test harness for transformations: test cases are defined as XML files comprising three parts. Firstly, an XML representation of the input data as an event stream or a reference to a data file and the corresponding reader. Secondly, the Metamorph definition to be tested or a reference to a Metamorph definition file. Thirdly and finally, the expected result. Modifiers can be used to indicate to the test framework whether the order of the data is supposed to matter. The test cases integrate into the JUnit framework [28] and therefore show in JUnit IDE plug-ins just as any other JUnit test case.
4.7.2 Visualization
As Metamorph definitions describe flows, they can easily be visualized. Metamorph contains a command line tool, which automatically translates the Metamorph XML to the graph description language used by GraphViz. Based on the resulting gv-file a flow diagram can be generated by applying Graphviz's dot layouter. Figure 3 is an example of such a visualization. Its source code is depicted in Listing 5. Such visualizations further increase transparency (see challenges outlined in Section 1).
4.7.3 Maps and external Data Sources
Table lookup is a pervasive task in metadata transformation. Consider for example replacing ISO country codes with full names or expanding abbreviations (ed becomes editor, prf becomes performer, etc.). To address this, maps can be defined in the Metamorph definition. They constitute additional input to processing elements such as lookup, whitelist, blacklist or setreplace. Sometimes these tables or maps are held in databases or accessed by other means. Any Java object implementing the Map interface can be registered with the Metamorph instance to act as map. The registration can be performed any time prior to processing.
4.7.4 Macros and XInclude
Metamorph offers a basic macro support to avoid repetition on the code level. Macros are expanded before visualization. Furthermore, XInclude is supported to foster code reuse. Both features are still subject to change and will be further developed in future releases.
Applications
Metamorph is an integral part of several services provided by the German National Library, two of which are presented in this section. A third example discusses a project in which a project-specific data mapping technology is currently being replaced by Metamorph.
5.1 Culturegraph
As more and more cultural heritage data become openly available, the opportunities to combine data sets to build new services and applications multiply. To do so, however, relations between as yet unconnected data sets need to be created. Culturegraph is an open platform for connecting and processing metadata primarily from the library domain, developed by the German National Library and partner institutions. The data is processed on a Hadoop Cluster. All data transformations in the Culturegraph platform are realized with Metamorph. This includes:
- Transformation of input data in the MARC21 format to the internal data format of Culturegraph.
- Matching bibliographic records with each other, unique properties identifying the records are calculated based on their metadata content.
- Transformation of records to Lucene documents for indexing.
- Transformation of records for presentation in HTML (full view or search result preview) and RDF.
The Culturegraph platform, online since 2011, currently stores, matches and indexes over 120 million bibliographic records from Germany
and Austria.
5.2 DNB Linked Open Data
In 2009, the German National Library started to publish its extensive metadata collections as linked open data [34], aiming to provide library metadata in an easily accessible format. Currently, RDF is offered. This data can be accessed via data dumps, through the web portal of the German National Library, or via SRU and OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) interfaces.
As of now, the services offer the following datasets that are transformed from the internal library format (Pica+) into RDF using Metamorph. Currently the data comprises 10.3m bibliographical records, 7.2m records on persons, 1.2m records on organizations, 1.1m records of controlled vocabulary for geographic locations, congresses, etc., and 0.2m records on subject headings. The transformations are performed both on-demand (web portal, SRU, OAI-PMH) and offline (data dump).
Further information on the linked data service of the German National Library is available.
5.3 DNB Portal Search
The German National Library provides a web-based portal for searching the library catalog. The search engine behind this portal relies on Apache Solr. For the indexing process, the bibliographic records in Pica+ format need to be transformed into Solr documents. This does not only involve the conversion of individual records but also requires the expansion of record references. Currently, transformations are specified in a custom XML-based configuration language that became quite complex and powerful over time. However, despite this power, the language is highly geared towards the task of resolving references and converting Pica+ records into Solr documents and cannot be used for other conversion tasks.
Metamorph offers the opportunity to replace this highly task specific language with a more general one, allowing the German National Library to consolidate the software technology stack and to focus development efforts on a single transformation language.
In a pilot study, the task specific XML configuration was translated into Metamorph. Large parts of the translation were performed automatically with a Perl script. The remaining parts were translated manually. All in all, it took one programmer half a day to convert the XML-based configuration to Metamorph. No major problems were encountered. The programmer emphasized in particular the usefulness of the pipes and filters architecture as it allowed her to easily test the transformation on individual records and to verify the correctness of the transformations with unit tests.
6 Discussion
6.1 Scope of Metamorph
In Sections 3.1 and 3.2 we explained how Metamorph combines a Pipes and Filters architecture with an event-based processing paradigm for data structures. The motivation was to implement a format-agnostic transformation language with high processing efficiency. This optimization comes at a cost: the data and the processing task must fit into this framework. In other words, Metamorph can only implement a processing task which can be accomplished in one start-to-end pass through the data record. In particular, it is not possible to follow references in a data structure, a feature for instance exhibited by the METS format: "Within a METS document it is often desirable to associate information in one section of the document with information in a different section. This internal linking is accomplished by means of XML ID/IDREF attributes." [23].
Having said that, a large number of processing tasks do not require the resolution of references and fit well into the class of tasks solvable within the event-based processing paradigm. (See also the applications presented in Section 5.)
6.2 Usability
An aim of Metamorph is to enable domain experts to perform metadata conversions themselves. Over the last years we were able to gather feedback concerning the usability of Metamorph from users with backgrounds as library metadata experts, information scientists or software developers in libraries. The main source of feedback was a series of hands-on workshops on the analysis of library metadata [17, 18]. Participants in the workshops who had a solid technical background quickly grasped the fundamentals of Metamorph and were able to write simple scripts. Users who were not familiar with XML and working with integrated development environments or XML editors found it hard to follow the workshops, though. Interestingly, domain experts quickly understood and accepted the declarative nature and data-driven execution of Metamorph, while users with prior programming experience often unconsciously assumed that Metamorph scripts were executed from top to bottom like a program in a typical imperative programming language.
In the workshops we observed that many challenges the workshop participants encountered were not rooted in the usage of Metamorph but in the fact that library metadata itself is quite complex. This complexity requires users to consider various special cases in their data conversions which might not be immediately obvious. A case in point is the processing of dates of birth and death, which was one of the exercises in the workshop. Intuitively one assumes that persons only have a single date of birth and a single date of death. However, in the integrated authority file (Gemeinsame Normdatei (GND)), which provided the database for the workshop, this is not always given. The integrated authority file allows recording multiple dates for a person to cover cases in which competing dates exist. The feature is also facilitated for storing different formats of dates (such as dates consisting only of the year and those also including day and month). In the workshops, participants (including most domain experts) were surprised when the number of dates found in the authority file was larger than the number of persons. After having learned that there might be multiple dates of birth and death for a person, the main question was usually how these additional date values should be interpreted within the domain. Once the participants had decided on an interpretation of the data, they implemented the Metamorph solution in a straightforward manner.
In summary, we observed that Metamorph makes metadata conversion accessible for domain experts. The workshops showed, though, that users need to have the ability to develop a structured mental picture of their conversions and to identify corner cases in the conversions which they want to describe. Additionally, learning Metamorph was much easier for those users who were versed in computing and already familiar with technologies such as XML and XML editors.
6.3 Future Work
While Metamorph has proven its value in the library metadata domain where it is already part of the production environment, it is still a work in progress. To become an entirely domain-independent tool, several issues need to be addressed and will be the main focus of future work.
6.3.1 Type System
As pointed out in Section 3.2, Metamorph uses only Strings. In the field of library metadata this is a viable and necessary assumption: all data are Strings. Numerical computations do not exist. To reach beyond library metadata, a type system is indispensable.
6.3.2 Function Libraries
Metamorph currently contains a number of built-in functions and collectors that cover metadata processing in the library domain. New functions can be added as pointed out in Section 4.7 and macros can be shared by means of the XInclude mechanism. In domains with entirely different processing needs, however, the currently used mechanisms might be cumbersome. It would be preferable to build libraries of functions and macros for different domains that can be included as needed.
6.3.3 Syntax and Parsing
In the current version of Metamorph, XML forms the basis for Metamorph definitions, as pointed out in Section 4.6.1. The just discussed venues of future work will likely go beyond the expressiveness of XML. Especially, a type system requires a level of expressiveness which can hardly be achieved with XML; not to mention elegance and ease of writing.
6.4 Conclusion
In this paper we presented a new language — Metamorph — for semi-structured data transformation. It is declarative, data flow-oriented, integrated in Java and expressed in XML. Metamorph has a narrower scope than XSLT. Its event-based processing model is, however, more efficient with respect to the DOM centered processing model of XSLT. Furthermore, Metamorph can easily be visualized and facilitates communication with domain experts. While Metamorph is still subject to changes and modifications as we discussed in Section 6.3, it is already a part of the production environment of the German National Library (see Section 5), and as pointed out in the Introduction, Metamorph is available Open Source.
References
[1] RDF/XML Syntax Specification (Revised), February 2004.
[2] Metafacture wiki, 2013.
[3] S. Abiteboul. Querying semi-structured data. In Database Theory — ICDT '97, pages 1—18. ACM, 1997.
[4] J. Bailey, F. Bry, T. Furche, and S. Schaffert. Web and semantic web query languages: A survey. In Reasoning Web, pages 35—133, 2005. http://doi.org/10.1007/11526988_3
[5] O. Becker. Serielle Transformationen von XML Probleme, Methoden, Lösungen.
PhD thesis, Humboldt Universität zu Berlin, Berlin, Germany, 2004.
[6] O. Ben-Kiki, C. Evans, and I. döt Net. YAML Ain't Markup Language (YAML) Version 1.2, October 2009.
[7] S. Berger, F. Bry, S. Schaffert, and C. Wieser. Xcerpt and visxcerpt: From pattern-based to visual querying of xml and semistructured data. In Proc. Intl. Conference on Very Large Databases (VLDB03), Demonstrations Track, Berlin, Germany, 2003.
[8] A. Berglund, S. Boag, D. Chamberlin, M.F. Fernandez, M. Kay, J. Robie, and J. Siméon. XML path language (XPath) 2.0. W3C, January 2007.
[9] K. S. Beyer, V. Ercegovac, R. Gemulla, A. Balmin, M. Eltabakh, C. Kanna, F. Ozcan, and E. J. Shekita. Jaql: A scripting language for large scale semistructured data analysis. In Proceedings of the VLDB Endowment, volume 4, Seattle, Washington, 2011.
[10] S. Boag, D. Chamberlin, M. F. Fernández, D. Florescu, J. Robie, and J. Siméon. XQuery 1.0: An XML Query Language Second Edition, December 2010.
[11] T. Bray, J. Paoli, and C.M. Sperberg-McQeen. Extensible Markup Language (XML) 1.0, February 1998.
[12] T. Bray, J. Paoli, C.M. Sperberg-McQeen, E. Maler, and F. Yergeau. Extensible Markup Language (XML) 1.0 (Fifth Edition), November 2008.
[13] J. Broekstra, C. Fluit, and F. van Marelen. The state of the art on representation and query languages for semistructured data. Technical report, AIdministrator Nederland BV, 2000. Deliverable 8 of the EU-IST On-To-Knowledge (IST-1999-10132) project.
[14] D. Brownell. Sax2. O'Reilly Media, Incorporated, 2002.
[15] P. Buneman. Semistructured data. In Proceedings of the sixteenth ACM SIGACTSIGMOD-SIGART symposium on Principles of database systems, pages 117—121. ACM, 1997. http://doi.org/10.1145/263661.263675
[16] F. Buschmann, R. Meunier, H. Rohnert, P. Sommerlad, and M. Stal. A system of patterns: Pattern-oriented software architecture. Wiley, 1996.
[17] C. Böhme. Analysis of library metadata with metafacture. Workshop at Semantic Web in Libraries Conference (SWIB '13), November 2013.
[18] C. Böhme. Analysis of library metadata with metafacture. Workshop at Semantic Web in Libraries Conference (SWIB '14), December 2014.
[19] F. Chang, J. Dean, S. Ghemawat, W.C. Hsieh, D.A.Wallach, M. Burrows, T. Chandra, A. Fikes, and R.E. Gruber. Bigtable: A distributed storage system for structured data. ACM Transactions on Computer Systems (TOCS), 26(2):4, 2008. http://doi.org/10.1145/1365815.1365816
[20] P. Cimprich, O. Becker, C. Nentwich, H. Jiroušek, M. Batsis, P. Brown, and M. Kay. Streaming Transformations for XML (STX), April 2007.
[21] J. Clark. XSL Transformations (XSLT). W3C, November 1999.
[22] D. Crockford. The application/json Media Type for JavaScript Object Notation (JSON). Network Working Group, July 2006. RFC 4627.
[23] M.V. Cundiff. An introduction to the metadata encoding and transmission standard (mets). Library Hi Tech, 22(1):52—64, 2004. http://doi.org/10.1108/07378830410524495
[24] J. Dean and S. Ghemawat. Mapreduce: simplified data processing on large clusters. Communications of the ACM, 51:107—113, 2008. http://doi.org/10.1145/1327452.1327492
[25] G. Fischer, E. Giaccardi, Y. Ye, A.G. Sutcliffe, and N. Mehandjiev. Meta-design: a manifesto for end-user development. Communications of the ACM, 47(9):33—37, 2004. http://doi.org/10.1145/1015864.1015884
[26] M. Fowler. Inversion of control containers and the dependency injection pattern, 2004.
[27] E. Fredkin. Trie memory. Commun. ACM, 3(9):490—499, September 1960. http://doi.org/10.1145/367390.367400
[28] E. Gamma and K. Beck. Junit: A cook's tour. Java Report, 4(5):27—38, 1999.
[29] D. Gelernter and N. Carriero. Coordination languages and their significance. Commun. ACM, 35(2):97—107, February 1992. http://doi.org/10.1145/129630.129635
[30] L. George. HBase: The Definitive Guide. O'Reilly Media, 2011.
[31] J. Gosling. The Java language specification. Prentice Hall, 2000.
[32] D. Gusfield. Algorithms on strings, trees and sequences: computer science and computational biology. Cambridge University Press, 1997.
[33] R. Hacker. Bibliothekarisches grundwissen. 2008.
[34] J. Hannemann and J. Kett. Linked data for libraries. World Library and Information Congress: 76th IFLA General Conference and Assembly, August 2010.
[35] G. Henze, Editor. Regeln für die alphabetische Katalogisierung in wissenschaftlichen Bibliotheken: RAK-WB. Deutsche Nationalbibliothek, 2007.
[36] R. Johnson. Expert one-on-one J2EE design and development. Wrox, 2002.
[37] W.M. Johnston, JR Hanna, and R.J. Millar. Advances in data flow programming languages. ACM Computing Surveys (CSUR), 36(1):1—34, 2004. http://doi.org/10.1145/1013208.1013209
[38] O. Lassila and R. R. Swick. Resource Description Framework (RDF) Model and Syntax Specification, February 1999.
[39] M. Mernik, J. Heering, and A.M. Sloane. When and how to develop domain-specific languages. ACM computing surveys (CSUR), 37(4):316—344, 2005.
[40] J. P. Morrison. Data stream linkage mechanism. IBM Syst. J., 17(4):383—408, December 1978. http://doi.org/10.1147/sj.174.0383
[41] C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. Pig latin: a not-so-foreign language for data processing. In Proceedings of the 2008 ACM SIGMOD
international conference on Management of data, pages 1099—1110. ACM, 2008. http://doi.org/10.1145/1376616.1376726
[42] Y. Papakonstantinou, H. Garcia-Molina, and J. Widom. Object exchange across heterogeneous information sources. In Data Engineering, 1995. Proceedings of the Eleventh International Conference on, pages 251—260. IEEE, 1995. http://doi.org/10.1109/ICDE.1995.380386
[43] T. Parr. Language implementation patterns: create your own domain-specific and general programming languages. Pragmatic Bookshelf, 2009.
[44] M. L. Scott. Programming Language Pragmatics. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 3rd edition, 2009.
[45] J. Shirazi. Java performance tuning. O'Reilly Media, Incorporated, 2003.
[46] A. Sutcliffe, N. Mehandjiev, et al. End-user development. Communications of the ACM, 47(9):31—32, 2004. http://doi.org/10.1145/1015864.1015883
About the Authors
 |
Markus Michael Geipel graduated with distinction from Technische Universität München in Computer Science and earned a doctorate from the Swiss Federal Institute of Technology, Zurich. In 2011 he joined the German National Library where he worked on the German Digital Library (DDB) and created the software architecture of culturegraph.org. Together with Christoph Böhme, he founded the Open Source Project Metafacture/Metamorph to facilitate the processing of bibliographic metadata. Since 2013 Dr. Geipel has worked on software architecture for machine learning and data analytics at Siemens Corporate Technology. His latest open source project is Omniproperties.
|
 |
Christoph Böhme graduated from Technical University Ilmenau (Germany) in computer science and received a PhD in Psychology from the University of Birmingham (UK). Since 2011 he has worked at the Germany National Library. Together with Markus M. Geipel, he founded the open source project Metafacture/Metamorph to facilitate the processing of bibliographic metadata. In 2013 he assumed his present position as head of a software development group at the German National Library. He is the current maintainer and lead developer of Metamorph/Metafacture.
|
 |
Jan Hannemann received his PhD in Computer Science from the University of British Columbia (Canada). While working for the German National Library he was the head of the System Innovation group and managed several data-focused projects, such as the research and development project CONTENTUS and the creation of Germany's first Linked Open Data service for bibliographic data, for which Metafacture/Metamorph was first used. He is currently working as a product manager for Google.
|
|