D-Lib Magazine
March/April 2014
Volume 20, Number 3/4
Table of Contents
Preserving Web-based Auction Catalogs at the Frick Art Reference Library
Gretchen Nadasky
Optimity Advisors
gretchennadasky@gmail.com
doi:10.1045/march2014-nadasky
Printer-friendly Version
Abstract
The Frick Art Reference Library (FARL) has a collection of over 90,000 auction catalogs and they are one of the most requested resources at the library, as more auction houses are publishing on-line. FARL began the "Reframing Collections for a Digital Age" project to address the stability of born-digital art research materials. The first phase of the project identified the basic risks and determined that Archive-It software was the best means of capturing this information. The second phase, described in this paper, identified criteria to determine preservation priorities and evaluate what has already been captured by the Internet Archive, with the goal of creating a list of websites that can and should be harvested immediately. The study also examined the pilot seed crawl results which monitor quality of materials being collected.
Introduction
Auction catalogs are essential tools for the sale of art and foundational texts for art researchers. The Frick Art Reference Library (FARL) in New York has one of the largest collections of sales catalogs and is a recognized leader in art scholarship globally. Web-publishing of auction catalogs is both an opportunity and a preservation concern for art libraries. Currently, FARL continues to regularly receive paper catalogs from 72% of the auction houses they have chosen as central to their users. A combination of cost-cutting and a move to digital production have made it more difficult to collect all of the resources FARL would like to have. Going forward, it is believed that more auction houses will move to produce their materials solely on-line. To assure that FARL can continue to build its art auction collection regardless of original format, the "Reframing Collections for a Digital Age" project was initiated by Deborah Kempe, Manager of Collections in partnership with the New York Art Resources Consortium. The on-going project seeks to identify how born-digital1 auction catalogs can be preserved, archived, described and made accessible to researchers.
Web-archiving is not an automated process and can be costly and time-consuming. Identifying specific websites to be preserved is a collection development process. Comparing the cost of a web-harvesting program to the risk of the information being made inaccessible is another reason to begin a web-preservation program with a thorough analysis. It can't be assumed that born-digital materials are being 'automatically' preserved. Additionally, web archiving programs like the Internet Archive's Wayback Machine were designed to capture URL's but not necessarily documents that have been embedded in web pages, such as auction catalogs. However, a large number of art auction sites have already been captured, so it makes sense to explore the possibility of leveraging that previous work through links to the Wayback Machine.
The initial phase of the project identified the URL's for all of the auction houses whose catalogs FARL collects, and chose the Archive-It software from the Internet Archive as the tool. A pilot test was initiated on a limited number of websites. The second phase of the project is addressed here. It focused on prioritizing auction catalog websites for preservation by identifying criteria, gathering data and creating a list of sites that can realistically be collected. The full report by Sean Leahy was published on the NYARC website in 2011 2.
Methodology
For this phase of the project, 137 auction house websites that were identified in the initial phase were selected, and the following tasks were performed. (The FARL collection includes materials from some houses that are not on-line and those were excluded.)
- a study of the profile of the websites;
- a survey to ascertain if FARL still receives the catalog in print form;
- an investigation of Internet Archive's Wayback Machine to determine which sites are already being preserved, to assess websites that have not been archived, and to identify possible technological issues that arise that would make harvesting by FARL impossible or impractical.
Concurrent with this research was the continuation of a live web-archiving pilot project. The final product will be a priority list to web-archive. (The priority list will not be made public).
Results
Print Acquisition
The print survey revealed that FARL continues to regularly receive paper catalogs from 72% of auction houses whose websites we examined. Of the balance, 15 auction houses no longer send catalogs at all, 8 auction houses send them on request (a burden on staff time) and 5 require payment for either the catalog or for shipping costs. Three of the auction houses had discontinued operations. A brief review of costs to acquire catalogs was also undertaken. Prices for auction subscriptions can range from $25 per catalog to $4,000 a year for a full subscription.
Auction Websites Profile Summary
The study identified the primary language of 75.9% of the websites as English or German, with the remaining sites in a variety of other languages. One of the difficulties for developing a preservation strategy is the variety of web design and file delivery techniques on the sites. Many sites use several technologies. The lack of standardization makes establishing an automated harvesting program very difficult and post-collection quality control more important. Some technologies, like HTML, are more 'archive-friendly' and 76% of the websites contained at least some HTML catalog content. Catalogs in PDF format were detected on the auction house website 11% of the time. Flash technologies were evident on 9% of the sites. (When the study was initiated Archive-It crawlers could not harvest Flash files, however subsequent upgrades remedied that issue.)
Wayback Machine Preservation
The investigation showed that 27% of the auction house website catalogs are being "automatically" (though usually only partially) captured by the Wayback Machine. It was important to understand what was already being captured to avoid redundant effort and also to explore how the Wayback Machine could be referenced, in addition to conducting local crawls using Archive-It. The study also helped indicate issues that the archivists would have to remediate in the results of an Archive-It crawl. Finally, for auction houses that are very important to FARL, the investigation also indicated that it might be worth it to perform Archive-It crawls at closer intervals than the Wayback Machine crawls.
The chart below shows some of the technical issues that can arise in web-archiving that affect the success of harvesting auction catalogs. The top three issues are: the software opens into the live website; the website but not the catalogs are archived; and broken links. These issues arise both in the Archive-It and Wayback Machine crawls. However, the advantage of Archive-It is that the crawl scope can be customized to mitigate these problems. Scoping and adjusting crawl parameters is an important part of the quality-control step in an Archive-It initiative. However, it can require trial and error and a significant investment of staff time.
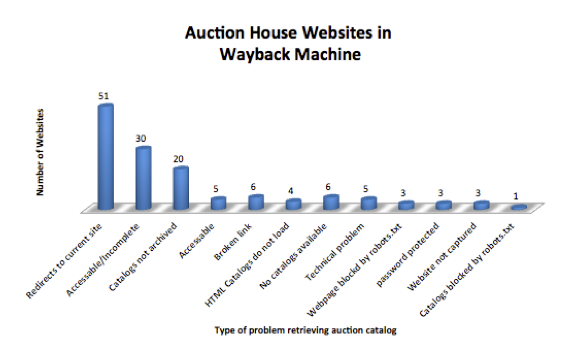
Figure 1: Crawl Issues
Results from the Archive-It subscription crawls
Initiating and maintaining a web-crawling schedule can be complex, and takes time and attention to detail. Once the candidate or 'seed' is chosen, a test crawl is run to determine what URLs, if any, can be harvested. The results of the test crawl reveal if the set is blocked by a robots.txt file, if there is an excess of unusable pages being collected, and if the crawl can capture a large portion of the site. If the test crawl looks successful, the seed is added to the regular schedule. Once the crawl is completed several reports must be examined to see if adjustments need to be made. In addition, at this point a user can actually examine the archived materials for completeness. One advantage of web-archiving in general is that the archived site is indexed by the program and can be key-word searched.
The crawls that were run from September 2012-2013 had varying results and levels of success. Only one was completely preserved with all of the materials. Some issues were:
- Web pages were captured but not the catalogs;
- Catalogs were archived without images;
- The crawler ran out of time and there were many documents in the 'queue';
- Catalogs of importance were identified as 'out-of-scope';
- Seeds were wholly or partially blocked by robots.txt;
- The catalog area of the site was protected by password (this issue was addressed in the latest version).
Some of these issues could be addressed by changing the scope but overall the process was cumbersome. The best results came from smaller sites that used mostly HTML technology and those that posted PDF versions of the catalog on pages close to the home page.
Conclusions
The results suggest that auction catalogs made available on-line can become an important resource for FARL, and preserving these materials is a priority for the library. Although most auction houses send print catalogs, the trend is starting to change so the shift to collecting web-based materials will need to accelerate. FARL and other institutions cannot rely on large-scale web-archiving initiatives like Internet Archive to preserve auction catalogs. The difficulty accessing catalogs underscores that web-crawlers are designed to capture web pages as opposed to documents posted to the web.
Executing web-crawls using Archive-It indicates that even archive-friendly materials can be hard to capture. Web-archiving initiatives require an investment of time to customize collection policy and crawl scope. Therefore, priorities must be set for which websites can and should be archived. The raw data, available here (spreadsheet), provides the criteria that can be sorted to design an efficient web-archiving strategy. (The priority list delivered to FARL is confidential.)
Next Steps
The next phase of the "Reframing Collections for the Digital Age" project will include a combination of leveraging the preservation efforts of the Internet Archive and continuing a limited number of Archive-It crawls. Users can now access links to the Wayback Machine in the library catalog, FRESCO. Archive-It crawls will be done based on the priority list developed here.
Long-term goals are to create an initiative to to add item-level metadata to the archived materials, and to create a record in the Frick's OPAC FRESCO. Regular quality assurance checks are necessary to make sure the links work and that the crawls continue to gather the appropriate materials. In an ideal situation, there would be a dedicated member of the FARL staff to undertake these steps while also engaging with collaborators globally in the art community and a formal preservation and access program for born-digital art resources would be established. In the meantime, the global art community is very fortunate that organizations like the Frick are undertaking to be guardians of born-digital materials.
Notes
1 Erway, Ricky. "Defining 'Born Digital'". OCLC Research. November 2010.
2 Leahy, Sean. "Archive-It and Online Auction Catalogs". New York Art Resources Consortium. February 2011.
About the Author
 |
Gretchen Nadasky received her MSLIS from Pratt Institute and is now a Senior Associate at Optimity Advisors consulting media clients on records management, digital asset management strategy, and data governance.
|
|