|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Ronald Jantz Michael J. Giarlo |
![]()
AbstractDeveloping preservation processes for a trusted digital repository will require the integration of new methods, policies, standards, and technologies. Digital repositories should be able to preserve electronic materials for periods at least comparable to existing preservation methods. Modern computing technology in general is barely fifty years old and few of us have seen or used digital objects that are more than ten years old. While traditional preservation practices are comparatively well-developed, lack of experience and lack of consensus raise some questions about how we should proceed with digital-based preservation processes. Can we preserve a digital object for at least one-hundred years? Can we answer questions such as "Is this object the digital original"? or "How old is this digital object"? What does it mean to be a trusted repository of digital materials? A basic premise of this article is that there are many technologies available today that will help us build trust in a digital preservation process and that these technologies can be readily integrated into an operational digital preservation framework. IntroductionDigital preservation is emerging as a trustworthy process, yet there is much ongoing debate, and skepticism abounds, concerning the viability and even the meaning of this process. Given the nature of electronic storage technologies and the ephemeral nature of Web pages, many are doubtful that digital preservation will ever become a reality. We are all familiar with the link failure syndrome that plagues the Web. Spinellis [1] indicates that approximately 28% of the URIs referenced in Computer and Communications of the ACM articles between 1995 and 1999 were no longer accessible in 2000 and the figure increased to 41% in 2002. Some scholars [2] have asked rhetorically, "How confident can we be when an object whose authentication is crucial depends on electricity for its existence?" For digital repositories, high-level architectures have been defined and there is extensive technology available in the form of specific tools and reusable platforms. In this article, the authors will focus on how certain technologies can assist academic and archival institutions in becoming trusted digital repositories and how these technologies can be readily integrated into a comprehensive repository architecture. To begin the discussion, the authors will present an overview of the digital preservation architecture established at Rutgers University Libraries (RUL). This architecture is based on the Flexible Extensible Digital Object Repository Architecture [3] (Fedora), a framework and implementation funded by a grant from the Andrew W. Mellon Foundation and available at no cost through an open source Mozilla Public License. The Fedora architecture meets many of the requirements outlined by Suleman and Fox [4], especially those of modularity and extensibility. Emphasis will be placed both on the integration of key technologies into a coherent and operational digital repository and digital preservation platform. DefinitionsIn order to understand the tasks of digital preservation, we need to devise some working definitions for the concepts of "document" and "digital object." David Levy [5] has offered some useful intuitive definitions: "Documents are talking things. They are bits of the material world – clay, stone, animal skin, plant fiber, sand – that we have imbued with the ability to speak." As paper and printing technologies have matured, people have grown to expect a document to hold human verbal communication fixed so that it can be repeated. This notion of fixity, however, is a relative term that takes on greater meaning and challenges in the world of digital documents. The fixity of microfilm and paper is generally considered to be much greater than any of the digital media. The great advantage of digital media, the ease of copying and modification, also becomes a major liability. Clearly, we are dealing with a situation that requires active management in that many digital objects that are not given migration attention will become inaccessible within a few short years. Further, since the digital object [6] or digital surrogate is not a document, it cannot "speak" to humans without a technological infrastructure that transforms the object into a representation of the original. Hence, we must find ways to "fix" both the digital object and the repository infrastructure in order to become a trusted repository. The phrase "digital preservation" creates confusion since readers, familiar with traditional approaches, assume that "preservation" involves the use of well-defined techniques to prevent the original artifact from deteriorating further and to perhaps even improve it to the point where it can be used again. Digital preservation involves quite different methods, skills, and outcomes and can complement traditional preservation services, while simultaneously providing unique and dynamic new uses of information. In this article, we will use the definition of digital preservation as proposed by the Research Libraries Group [7] as follows: Digital preservation is defined as the managed activities necessary: 1) For the long term maintenance of a byte stream (including metadata) sufficient to reproduce a suitable facsimile of the original document and 2) For the continued accessibility of the document contents through time and changing technology. We will further define the digital object as the basic unit of both access and digital preservation and one that contains all of the relevant pieces of information required to reproduce the document including metadata, byte streams, and special scripts that govern dynamic behavior. This data is encapsulated in the digital object and should be managed as a whole. If our archive is organized in such a way that bits and pieces of the object are scattered throughout the storage system, it becomes difficult, perhaps impossible, to keep track of all these pieces, and the digital archivist risks the possibility of not migrating all the relevant material as one unit. The RLG report on trusted digital repositories provides a starting point and framework for explaining and demonstrating the important concepts of digital preservation. In particular, the concept of a "trusted digital repository" is based on two major requirements: 1) the repository with associated policies, standards, and technology infrastructure will provide the framework for doing digital preservation, and 2) the repository is a trusted system, i.e., a system of software and hardware that can be relied upon to follow certain rules. A proposed definition of a reliable digital repository, also from the RLG report, is as follows: "A reliable digital repository is one whose mission is to provide long-term access to managed digital resources; that accepts responsibility for the long-term maintenance of digital resources on behalf of its depositors and for the benefit of current and future users; that designs its system(s) in accordance with commonly accepted conventions and standards to ensure the ongoing management, access, and security of materials deposited within it; that establishes methodologies for system evaluation that meet community expectations of trustworthiness; that can be depended upon to carry out its long-term responsibilities to depositors and users openly and explicitly; and whose policies, practices, and performance can be audited and measured." We are clearly in uncharted waters when we try to operationalize concepts such as "community expectations of trustworthiness." Over the years, libraries and archives have built up considerable trust within the communities that they serve; however the accumulated trust derives from traditional services. How do we transform these institutions to become trusted repositories of digital information? Trusted RepositoriesFor academic libraries and trusted digital repositories, the trust issues are somewhat different than those encountered in e-commerce. In both academic and commercial organizations, a climate of trust must be established. However, users of e-commerce are typically concerned about financial fraud or credit card theft. In contrast, for the digital repository, trust involves scholarship, authenticity, and persistence over time and has little relationship to immediate financial rewards. Researchers have been examining the issue of trust in electronic commerce, and many of the same issues will plague digital repositories in executing the digital preservation role. Many of us have experienced concerns about using a credit card for online purchases or believing that an airline's electronic ticket is really as valid or reliable as the traditional printed ticket. For repositories of scholarly materials, trust can become a significant long-term barrier and considerably increases the complexity of the digital preservation task. A typical example raises some very interesting questions about trust and decisions that are made by librarians and archivists. Figure 1a below depicts a page image of one of the historic newspapers in Rutgers University's Special Collections and University Archives. Figure 1b is a text-only rendition of the short article on the Hightstown Auction. Intuitively, the reader will likely put more trust in the page image of Figure 1a that has the discoloration of an old, original newspaper and even a marking from some previous reader (the arrow pointing to the article). The excerpt on the right is more legible but suffers from uncertainties that are surely lodged in the reader's mind. How was the text created and could the text have been altered in the process of human markup and error correction?
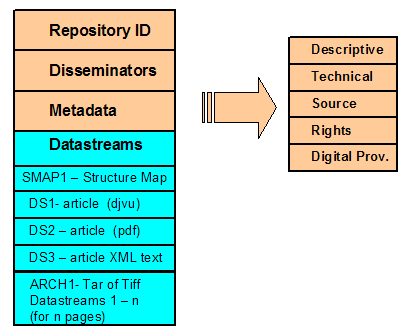
To deliver advanced features, optical character recognition (OCR) techniques can be applied to the images of the newspaper so the user can do full-text searching. OCR software will produce some errors, and the plain text, corrected version in Figure 1b, may actually offer better full-text searching results and require less management and technical overhead for long-term preservation. It is possible, perhaps likely, that preservationists will make decisions in the future to simplify their digital holdings by retaining the text-only versions, abandoning the digital surrogates forever. Assuming we have offered full-text searching as a service, we realize that different indexing and search algorithms will produce different results. This complex issue suggests that we cannot preserve the digital object without also preserving the corresponding software that delivers full-text search results to the user. We not only have trust issues related to the digital object but also with the human aspects of competency and trustworthiness. How do we ascertain the quality of metadata or detect some intentional or inadvertent effort that results in alteration of the content? Should we certify our metadata creators in some way? Lynch [8] suggests that we are really concerned more about human behavior than human identity, but we could likely improve the level of trust by requiring those who create metadata to also digitally sign the results of their efforts. Digital preservationists and archivists will be confronted repeatedly with decisions on what to retain and what constitutes the archival master, requiring many trade-offs among issues such as administrative support, storage costs, dynamic features, and more fluid concepts such as avoiding risk and engendering trust in the repository. Digital Repositories and the Preservation ArchitectureA digital repository is simply a "place" to store, access, and preserve digital objects. Digital objects can be quite complex reflecting the structure of the physical artifact and including multiple content byte streams and special software used to deliver dynamic results to the user. A flexible digital repository should allow us to store all types of digital objects along with the appropriate descriptive and administrative metadata. A digital object might be an electronic journal article, a digitized image of a photograph, numeric data, a digital video, or a complete book in digital form. Although our emphasis here is on digital preservation, the RLG definition implies that preservation and access are inextricably linked. As a result, the repository not only provides for preservation but also creates an environment for access to the objects that have been preserved. The Rutgers University Libraries (RUL) digital repository architecture, based on Fedora, has been discussed previously in the context of preserving public opinion numeric data [9]. In this article, we will focus on the architecture of the digital object and the technologies required to preserve the digital object. The Digital ObjectFrom a digital preservation perspective, perhaps the single most important design process is to define the architecture or "model" of the digital object. Each format to be preserved (book, newspaper, journal, etc.) has an architecture appropriate for the unique characteristics of that format. Taking the historic newspaper from Figure 1 as an example, presentation (or access) images, digital masters, and OCR-ed text are all encapsulated in the digital object. In this case, at RUL we have made a preservation decision to preserve the digital masters (TIFF images) and the uncorrected, OCR-ed text in XML format. Each newspaper issue is exported in METS-XML format and the resulting file becomes the Submission Information Package as defined in the OAIS reference model [10]. The object architecture for a newspaper issue is shown in Figure 2 below.
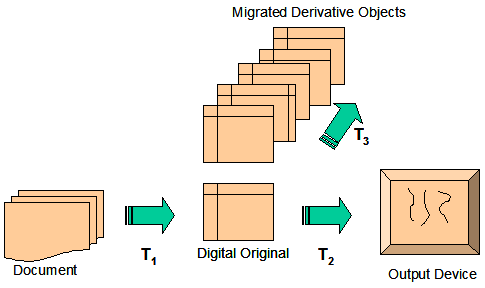
Given the bibliographic data supplied by the preservationist or librarian, the Submission Information Package for each object is generated and ingested automatically into the repository. In addition to the metadata supplied by the librarian or archivist, there are five datastreams in the object of Figure 2 as follows: 1) a METS [11] XML structure map (SMAP1) that specifies the logical and physical structure of the newspaper issue; 2) a presentation file in DjVu [12] format (DS1); 3) a presentation file in PDF format (DS2); 4) the text of the newspaper issue in XML format (DS3); and 5) the archival digital masters (TIFF images) encapsulated in a widely available archival format such as a tar file or zip file (ARCH1). (Note that the term "datastreams" is used in the Fedora architecture and can be considered roughly equivalent to the concept of "byte streams" as used in the RLG definition of digital preservation.) The archival master provides the digital preservationist with a non-proprietary version of the original source content in the event that the presentation formats need to be regenerated or migrated to new formats or platforms. Although we will not discuss the Fedora disseminators in detail that are shown in Figure 2, it should be noted that these special objects provide the ability to create services for unique content transformations and presentation of objects, thus allowing for the preservation of the object behavior as well as the content of the digital object. At this juncture, it is important to highlight a process, supported by the underlying Fedora framework, that is critical for managing and preserving digital objects for long periods of time. The process, referred to generally as "encapsulation", is simply a way to group together all the relevant material for the digital object and to manage the resulting digital object as one. As can be seen from Figure 2, we have encapsulated all the relevant information about the newspaper to be preserved into one digital object. One can easily imagine a digital book object consisting of several hundred files being easily rendered into a similar object structure. Encapsulation therefore becomes an essential process to enable the preservationist to keep all these files together and to migrate, delete, purge or perform other similar operations on the object as a whole. Technologies for Enabling TrustIn this section, we will review several technologies and processes that have been integrated into the above architecture to help improve trust in digital repositories. Our focus will be on using existing or emerging standards and open-source software. Digital Signatures. Once we ingest a digital object into a repository, we want to have a high degree of assurance that the object has not been modified either accidentally or fraudulently. The change of a single bit in numeric data or a software program can radically alter the content and function of the digital document. For analog data that has been digitized (e.g., images, video, audio), we are unlikely to notice a single bit change in the presentation document; however, as a trusted digital archive, we need to detect, report, and correct all such changes. To address this issue, we are using digital signatures as a method to detect changes in the object. A digital signature is a critical technology that must be operational in a digital preservation repository to guarantee the integrity of the digital object. Integrity is defined here as a property that conveys that data has not been changed, destroyed, or lost in an unauthorized or inadvertent manner. A digital signature provides an integrity check on digital content that is to be preserved. The core technology used in this process is a hash algorithm that takes, as input, an arbitrary byte stream and converts this stream to a single fixed-size value known as a digest [13]. The significant aspect of this algorithm is that it is one-way; it is computationally impossible to recreate the original byte stream from the digest and, further, no two byte streams can have the same digest. Using SHA1 (Secure Hash Algorithm [14]), the resulting hash fingerprint is a 160-bit message that is computationally unique. SHA1 will take an input stream of up to 2**64 bytes (this power of 2 is equal to 18,446,744,073,709,551,616) and the 160-bit precision of the output provides for 2**160 unique digest values. Our policy is to compute a digital signature for the digital masters (ARCH1 in Figure 2) and to store this signature in the technical metadata of the object. Further, we compute a signature for the complete object and store that signature externally to the repository. As part of our authentication architecture, a background process periodically re-computes the hash for each byte stream and compares it with the originally computed hash. Any differences are reported and offline storage or mirrored repositories are used to restore the integrity of the object. Persistent Identifiers. It is surprising that the scholarly community has not risen up to loudly protest citation failures in the digital realm. For scholars to confidently cite a digital object, they must be assured that the object will be accessible via the citation for many years, sometimes referred to as "referential integrity" or "citation persistence". As Spinellis' [1] data demonstrates, web references are distinctly untrustworthy. The evolving and rapidly changing digital environment in which digital objects reside suggests that references to these objects have a high probability of becoming inoperable in a few short years. In an attempt to address this problem, the concept of a persistent identifier (PID) has been developed. The concept is fairly simple. We would like to assign a globally unique name to a digital object, a name that can be used, in perpetuity, to refer to and retrieve the digital object. Uniform resource names (URNs) refer to a generic class of persistent identifiers and are defined by the Internet Engineering Task Force [15] as follows: "It is intended that the lifetime of a URN be permanent. That is, the URN will be globally unique forever, and may well be used as a reference to a resource well beyond the lifetime of the resource it identifies or of any naming authority involved in the assignment of its name." However, there are several real-world practicalities that suggest that this vision of a persistent identifier is achievable only in a limited fashion. Ultimately, we must rely upon the persistence of organizations and their ability to implement sustainable preservation policies and human workflow processes. The practical obstacles in our digital environment are twofold. First, the digital object is created and resides in an environment with many technological dependencies, including computing hardware, operating systems, file systems, and servers. Ultimately, any persistent identifier has to be resolved to a specific address (e.g., a URL). Servers and file systems are routinely moved, renamed, or retired resulting in the familiar link failure syndrome we see all too often. Secondly, some organization has to take on the responsibility of managing the assignment of names. Although much of the routine work of assigning names can be automated, we must realize that this organization must ultimately do its work on behalf of the world community and must be able to do this work in perpetuity. Having raised these fundamental issues, it should be noted that similar systems are working today, albeit not perfectly. Telephone numbers, IP addresses, and social security numbers share some of the same properties as persistent identifiers. Active management and organizational persistence is required in all these systems. Given these caveats, there are at least two approaches available today that allow us to get started with the process of providing persistent identifiers: the CNRI Handle [16] and the Archival Resource Key [17]. Before exploring these two approaches, there are several issues that must be clarified.To What Does the PID Point? The PID should point to a "place" that will provide the user some context. For example, if it points directly to an image, the user will not have any descriptive metadata to explain what the image is about. For this reason, we believe the PID should either point to a bibliographic record that, in turn, allows one to access the digital object or, alternatively, the PID should carry some descriptive metadata with it. Many of our digital objects will have several representations for presentation on the Web (e.g., DjVu, PDF, JPEG, MP3, etc.) in addition to having an archival, uncompressed format such as a TIFF or WAV file. If the PID is used for citation purposes and is pointing at the specific object, then we must provide PIDs for all representations. There are different methods of doing this. First, the PID can point to a single bibliographic record that in turn allows access to all formats. This approach inserts more structure (e.g., the application displaying the bibliographic record) and is therefore more subject to being lost due to infrastructure changes. Secondly, there can be multiple PIDs, each pointing to a separate rendition of the object. Although both Handles and ARKs can accommodate this latter approach, the ARK format specifically provides for multiple representations by providing syntax that can be used to identify variants. What are Proper Naming Conventions? Although the PID is embedded in a URL in order to serve it on the Web, the PID naming convention should generally be free of technology dependencies, protocols, and local naming conventions. The premise behind this convention is that these technology and naming conventions will change over time so the name should be chosen to be perpetual. We first present some simple examples of both Handles and ARKs to familiarize readers with the syntax and alternative naming conventions. CNRI Handle. The CNRI Handle syntax is of the following form: prefix/suffix where the prefix (e.g. 1782.3) is assigned by the CNRI Global Registry and thus is globally unique. The suffix can be any user-assigned character string. For the RUL Digital Library Repository, we have chosen a string with the following syntax: [collection].[format].[unique-id within RU namespace]. An example, embedded within a URL , is shown below. http://hdl.rutgers.edu/1782.1/spcol.newspaper.196 Archival Resource Key (ARK). In the sample ARK below, the number "15230" is a globally unique number assigned by the maintainers of the ARK infrastructure at the California Digital Library, and mirrored at the National Library of Medicine. On the surface, the "15230" is roughly equivalent to the "1782.3" of the CNRI Handle. A tool designed to support ARKs [18] can be used to generate opaque names, including a check character, that can be combined with semantically loaded access service identifiers (often transient by nature); for example, http://noah.rutgers.edu/ark:/15230/jn678h492s/newspaper.djvu This URL illustrates the ARK syntax rules reserving the '/' and '.' characters so that a persistent opaque name pointer to a conceptual object can be joined with a kind of service address that points into the object. Since, to retain viability, a preservation system needs the freedom to migrate or alter the mix of individual components within a conceptual object to which it has committed, the persistence of the combined identifier may or may not be as strong as that of the foundation (opaque) name. The ARK philosophy encourages semantically opaque names, the idea being that if long-term persistence is desired, the name should not reflect transient realities such as the current collection name, or contemporary vocabulary for describing the object type. Depending on the needs of the institution, semantically loaded names can provide practical benefits to the repository user and manager and the same tool can be used to assign specific, requested names, such as http://noah.rutgers.edu/ark:/15230/spcolPhotograph196 We believe that both the Handle [16] and ARK [17] approaches have advantages and that the associated organizational and technological approaches will continue to mature. At this juncture in our digital preservation architecture, we have chosen to implement the CNRI Handle solution. Referring to Figure 2, each handle is generated automatically from the metadata submitted by the user. The handle is stored in the descriptive metadata as an identifier and is available for harvesting via the OAI Protocol for Metadata Harvesting [19]. Audit Trails. The audit trail is critical for maintaining an uninterrupted record of the life cycle of the digital object. The audit trail, a feature of the Fedora platform, records two essential pieces of information that are inserted automatically into the digital object metadata whenever the object is edited by authorized personnel. For example, if an edit is made on the descriptive metadata, the old copy of the metadata is saved, the new descriptive metadata receives a version number, and a record for this transaction is inserted into the digital provenance metadata for the object, indicating that an edit transaction has occurred. If this change to the object is conducted through the authorized management interface, the digital signature for the object is updated to reflect the new content. As we shall see in the next section, audit trails provide an essential technology for managing the life cycle of the digital object. The Digital Original and the Digital DerivativeGiven that we have a digital object stored in the repository, how do we guarantee its persistence over time? How can we assure the scholar that she is using a surrogate that has been faithfully created from the original? To better understand and answer these questions, it is useful to discuss the transformations that will occur on a digital object in its life cycle and the concept of the digital original. Transformations. During the life cycle of the object, there are transformations from the original print or non-digital object to the digital representation and subsequent transformations that can occur through editing and migration of the digital content. As the diagram in Figure 3 depicts, we are faced with three major transformations that can affect the physical form and that pose the question: "how does one know that the digital object viewed on the computer screen is a faithful reproduction of the original artifact?" Transformation T1 represents the digitization process that results in creating the digital object. Transformation T2 represents the transformation of the digital object to an output device, such as a printer or computer display, and depends on the software used to move the byte stream from disk storage to the computer output device. Transformation T3 represents the multiple transformations due to editing or migrating the object over time and that usually will result in a modification of the object content, either metadata or byte streams.
The transformation T1 from paper to digital is a process in which humans are required to make many decisions. Therefore we will need to depend on how well the repository has defined and deployed its processes for scanning, creation of metadata, and the creation of the archival information package. The transformation T2 is typically verified during the digitization process through visual inspection. The transformations T1 and T2 that result in the creation of the digital original can be executed with high reliability and reasonable assurance that the physical form has been preserved. Transformation T3, the migration process, poses the most problems and the most risk of inadvertently modifying the physical and intellectual form of the object, given the many transformations that will occur over time. Originality. What is the digital original? In the traditional print world, the original is the artifact that has not been copied or derived. This concept in the digital realm, in its strictest interpretation, makes little sense in an environment where files are routinely copied for purposes of system administration, digital library maintenance, and migration. In the case of the newspaper cited above and other digital objects, it is likely over time that thousands of digital copies will be made. So, "oneness" and "uniqueness" have little significance in the digital context. However, we can re-interpret "originality" with some technological and process assistance. On ingest, the digital object is given a creation date-time stamp that is automatically inserted in the METS-XML header. Further, in the creation of the archival master, a unique digital signature is computed and inserted in the metadata for the object. A combination of technologies including encapsulation, simple date/time stamps, and digital signatures has enabled us to re-interpret the concept of "originality". The digital original has the key characteristics of 1) having the digital signatures continuously re-verified since the creation date of the digital object, 2) retaining versions and recording all changes to the object in the audit trail and 3) where the archival master retains the creation date of the digital object (i.e., it has not been changed). Under this definition, there are numerous editing scenarios in which we retain the concept of the "original". For example, if there is routine editing of the metadata or replacement of one of the presentation datastreams, these modifications are date-time stamped and the appropriate records are entered into the audit trail. The manager of the repository can trace back through the audit trail and examine each change, progressing backwards in time until the first modification is detected. In another scenario, let's assume that a copy has been taken of the object. If an unauthorized modification has been made, the signature authentication process will fail. In effect, we are providing reasonable assurance to the scholar that the digital object has not changed since the time the images were scanned and stamped, and that the copy retains the characteristics of the original object. Our task here is simply to demonstrate that current tools and technologies, assembled as part of the digital preservation infrastructure, can provide reasonable levels of assurance to the scholar and the owner of the digital object. Nevertheless, this assurance remains the responsibility of the consumer (the scholar) and the provider (the repository) to take appropriate actions in order to determine if intentional or inadvertent modifications have occurred. For verification purposes, the scholar can request an original copy from the repository or even request that the digital signatures be re-computed and compared to those of the original. Migration and the Digital Derivative. During the life cycle of the object, there will likely be many transformations of the archival master as it is migrated to new formats as illustrated in the transformation T3 of Figure 3. In the process of making these transformations, we want to protect against the modification of the physical form and the intellectual content of the original document. We will define a migration event as any action on the digital object that changes the archival masters, specifically the ARCH1 datastream as illustrated in the Figure 2. Migration events are undertaken typically to accommodate new standards and formats as they are developed. The migration process involves creating a derivative master from the original archival master. The description of the migration event appears in the digital provenance section of the digital object metadata as shown in Table 1 below. Although this example deals with a single object, it is clearly possible to automate much of the manual labor, including creating of the migration event metadata, for digital image collections with the same characteristics.
<migration ID="MIG1.0" TYPE="UPGRADE" DATE="2005-01-11T07:45:00">
<migration_process> format standardization </rulibadmin:migration_process> <migration_agency> RUL Scholarly Communication Center </rulibadmin:migration_agency> <migration_environment platform="server"> Linux Redhat 7.2, Fedora 1.2 </rulibadmin:migration_environment> <migration_software> (Open-source software -- version 1.0) </rulibadmin:migration_software> <migration_steps> Create datastream for JPEG2000 </rulibadmin:migration_steps> <migration_specifications> See Migration Document 1.0 </rulibadmin:migration_specifications> <migration_rationale> Create JPEG2000 datastream for presentation and standardize on JPEG2000 as an archival master format. </rulibadmin:migration_rationale> <migration_changes> New digital object created by adding a new archival datastream. Re-ingest was not necessary </migration_changes> <migration_result> Object verified visually and accessed through the PID </migration_result> </rulibadmin:migration> Table 1 - Metadata for a Format Conversion Migration Event These types of events should be managed as a whole on behalf of all affected objects in the repository. Although there has been considerable discussion on and research into related topics such as canonical forms [20] that have the potential of simplifying or eliminating the migration process, we are, at this juncture, left with a labor-intensive process that requires active management. Storage ManagementWhile the selection and installation of software components are crucial to building a digital repository, perhaps the core of the repository is the storage infrastructure. Likewise, the sometimes fragile trust that is placed in a repository may ultimately hinge upon the development of effective storage management policies. Even in instances where some ideal combination of software technologies has been incorporated into a repository – let us for now assume that such an objectively ideal combination exists – the "last line of defense," so to speak, against fraudulent or accidental loss or alteration of data is indeed the hardware. While hardware decisions do not end with those concerning storage management, they are outside the scope of this article. Returning for a moment to the RLG definition, "digital preservation is defined as the managed activities necessary ... for the long term maintenance of a byte stream ... sufficient to reproduce a suitable facsimile of the original document." Emphasis has been added to the definition to convey two points. First, a digital repository that is designed to provide digital preservation per the RLG definition must be able to produce a copy of the source content stored within that is "suitable," i.e., that displays the same text or image, for example, or more generally provides more or less the same experience. Since software cannot make this provision without some sort of underlying storage hardware, true providers of digital preservation will consider storage hardware as a key component of a repository. Second, if the definition is extended to cover the broader spectrum of tasks related to digital preservation, it is not sufficient to allocate vast amounts of storage space for a digital repository without regard for the management thereof. In order to satisfy completely the requirements for digital preservation, the Rutgers University Libraries have chosen a storage management solution based on the open architecture of a Storage Area Network (hereafter, "SAN"). The key advantages of using a SAN over those of direct-attached disks and Network-Attached Storage ("NAS") are:
The SAN that supports the Rutgers University Libraries digital repository is comprised of the following parts:
Although seven terabytes is a sizable amount of disk storage, digitized content in certain forms, video for example, may quickly consume the lion's share of free space. In order to manage and optimize the disk arrays, the SAM-FS software is being utilized. As stated above, SAM-FS is a filesystem like UFS, EXT2, or NTFS that supports the following four functions:
The Rutgers University Libraries digital repository is thus made up of cutting-edge SAN hardware and Hierarchical Storage Management (HSM) software, which essentially allows the repository server to address both the disk array and the tape library as though they were connected disks. The HSM software permits repository administrators to more effectively manage the storage system, optimizing usage of the disk and ensuring data is backed up via policies to store all presentation-form datastreams on disk and release rarely-accessed archival datastreams to tape. The hardware and software work together to ensure lost or mangled data may be regenerated to form a "suitable facsimile" should such an event occur. All of our digital recording media require active management in order to avoid problems due to media degradation and failure. The only approach to this generic problem is for the repository manager to put in place policies for periodically migrating content and to make sure that there is ample redundancy via routine backups, off-site backup, and the use of mirrored sites or other types of redundancy options [22] to ensure that there is always another digital "place" where one can find the original object. For several reasons, we ultimately want to have a network of interoperating digital library repositories. From a digital preservation perspective, redundancy of content is perhaps the most critical consideration. Although we have a data persistence strategy that includes RAID technology, daily backups, and weekly offsite delivery of backup tapes, we also want to replicate all object content in a mirrored server configuration. This type of configuration not only provides redundancy of content but also insures higher availability of the content. Although RUL has not yet implemented a mirrored repository configuration, this capability is planned as part of the ongoing Fedora development. ConclusionAcademic libraries and archival institutions have a unique opportunity in the area of digital preservation. From the viewpoint of communication, the digital repository must provide feedback about its policies and technologies, and be open to sharing this information with users. It is critical for the digital repository to be able to present the archival policy to a potential depositor or to explain in non-technological vocabulary how the digital objects are protected from fraudulent or inadvertent changes. As libraries and other institutions embark on the digital preservation process, judgment must be used to balance risk against the maturity of the process. Documents that are extremely rare or whose loss might cause considerable financial, environmental, or cultural disasters should not be entrusted to a relatively immature process. We would like to say that we will preserve our cultural heritage materials in perpetuity; however the unknown – and, furthermore, unknowable – digital landscape suggests that any such guarantee would be inadvisable at this point. Indeed there are many challenges; nonetheless, academic libraries must begin to assemble and integrate the policies, standards, methods and technologies for doing digital preservation. There is much research yet to be done. For example, we can't yet easily discern if two digital objects are equivalent in structure and semantics [23]. Libraries and archives will have to deal with these types of uncertainties in addition to such active management issues as migration of data, an area that is largely indeterminate given the rapid evolution of technology. Although there certainly are risks in undertaking digital preservation, libraries must begin to establish their reputations simply by deciding to get started in this new role. The Association of Research Libraries has recently published a discussion draft that suggests the following action, in the context of using digitization as a reformatting strategy, "Libraries cannot wait for long-term solutions to be completely settled before testing the water" [24]. Finally, it must be said that there will always remain the element of trust in the organization that takes on the role of "trusted digital repository". We rarely doubt the accuracy and validity of our bank statements – although we suspect many of us perform quick little "sanity checks" to see if our balance is close to what we think it should be. We want to have at least this same level of trust in digital repositories. Ultimately, users will need to be able to trust the people and organizations who have taken on the responsibility for managing the processes and technology of digital preservation. Notes and References1. Spinellis, D. (2002). The decay and failures of web references. Communications of the ACM, 46, (1), 71 - 77. 2. Cullen, C. (2000). Authentication of digital objects: Lessons from a historian's research. In Authenticity in a Digital Environment (CLIR publication 92, pp. 1 - 7). Washington, D.C., Council on Library and Information Resources. Available at: <http://www.clir.org/pubs/reports/pub92/pub92.pdf>. 3. Staples, T., Wayland, R. & Payette, S. (2003). The Fedora Project: An open-source digital object repository management system. D-Lib Magazine, 9, (4). Available at: <doi:10.1045/april2003-staples>. 4. Suleman, H. & Fox, E. (2001). A framework for building open digital libraries. D-Lib Magazine, 7, (12), Available at: <doi:10.1045/december2001-suleman>. 5. Levy, D. (1998). Heroic measures: Reflections on the possibility and purpose of digital preservation. Proceedings of the Third ACM Conference on Digital Libraries, Pittsburgh, Pennsylvania, United States, pp.152 - 161. 6. Kahn, R., & Wilensky, R. (1995, May 13). A framework for distributed digital object services. Available at: <http://hdl.handle.net/cnri.dlib/tn95-01>. 7. Research Libraries Group. (2002). Trusted digital repositories: Attributes and responsibilities. An RLG-OCLC Report. Available at: <http://www.rlg.org/longterm/repositories.pdf>. 8. Lynch. C. (2001). When documents deceive: Trust and provenance as new factors for information retrieval in a tangled web. Journal of the American Society for Information Science and Technology, 52, (1), 12 - 17. 9. Jantz, R. (2003). Public opinion polls and digital preservation: An application of the Fedora Digital Object Repository System. D-Lib Magazine, 9, (11). Available at: <doi:10.1045/november2003-jantz>. 10. Consultant Committee for Space Data Systems. (January/2002). Reference Model for An Open Archival Information System, CCSDS Secretariat, Program Integration Division (Code M-3), National Aeronautics and Space Administration, Washington, DC. Available at <http://ssdoo.gsfc.nasa.gov/nost/wwwclassic/documents/pdf/CCSDS-650.0-B-1.pdf>. 11. Information on METS is available at the official website at <http://www.loc.gov/standards/mets/>.
12. For more information about DjVU, see <http://www.djvuzone.org/>. The DjVu browser plug-in can be downloaded from <http://www.lizardtech.com/download/dl_download.php?detail= 13. For more information, see the W3C website at <http://www.w3.org/Signature/>. 14. For more information on the secure hash algorithm, see <http://www.faqs.org/rfcs/rfc3174.html>. 15. IETF Network Working Group. (1994). Functional Requirements for Uniform Resource Names. Available at <http://www.ietf.org/rfc/rfc1737.txt>. 16. For more information, see the Handle System® website at <http://www.handle.net>. 17. Kunze, J. & Rodgers, R. (2004) The ARK persistent identifier scheme. Available at: <http://www.cdlib.org/inside/diglib/ark/arkspec.pdf>. 18. NOID(1), CDL 0.424. Available at <http://www.cdlib.org/inside/diglib/ark/noid.pdf>. 19. For more information, see the OAI website at <http://www.openarchives.org>. 20. Lynch, C. (1999). Canonicalization: A fundamental tool to facilitate preservation and management of digital information. D-Lib Magazine, 5, (9). Available at: <doi:10.1045/september99-lynch>. 21. W. Curtis Preston. 2002. Using SANs and NAS. O'Reilly & Associates, Inc: Sebastopol, CA. 22. Reich, V & Rosenthal, D. (2001). Lockss: A permanent publishing and web access system. D-Lib Magazine, 7, (6), Available at: <doi:10.1045/june2001-reich>. 23. Renear, A. & Dubin, D. Towards identity conditions for digital objects. Available at: <http://www.siderean.com/dc2003/503_Paper71.pdf>. 24. Association of Research Libraries. (2004/June). Recognizing digitization as a preservation reformatting method. Available at: <http://www.arl.org/preserv/digit_final.html>. Copyright © 2005 Ronald Jantz and Michael J. Giarlo |
|||||
| |
|||||
|
Top | Contents | |||||
| | |||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/june2005-jantz
|