|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Jeroen Bekaert Herbert Van de Sompel |
![]()
AbstractThis article describes results of a collaboration between the Research Library of the Los Alamos National Laboratory (LANL) and the American Physical Society (APS) aimed at designing and implementing a robust solution for the recurrent transfer of digital assets from the APS collection to LANL. In this solution, various recent standards are combined to obtain an asset transfer framework that should be attractive as a means to optimize content transfer in environments beyond the specific APS/LANL project. The proposed solution uses an XML-based complex object format (the MPEG-21 Digital Item Declaration Language) for the application-neutral representation of compound digital assets of all sorts. It uses a pull-oriented HTTP-based protocol (the Open Archives Initiative Protocol for Metadata Harvesting) that allows incrementally collecting new and updated assets, represented as XML documents, from a producing archive. It builds on an XML-specific technique (W3C XML Signatures) to provide guarantees regarding authenticity and accuracy of the transferred assets. 1. IntroductionSystematic and ongoing transfer of published content in a networked environment is a challenging task. Many degrees of freedom exist for devising a solution, including the choice between a push and a pull model, the choice of a method to package content for transport, and the choice of a method to transport the packaged content over the network. Typically, a different solution to the same problem exists per content producer and per content type. Hence, it does not come as a surprise that, during the last few years, a growing interest in the standardization of content transfer frameworks can be observed. Several use cases motivate this need for standardization:
Various projects have explored the possible standardization of the content transfer from publishers to libraries. The Networked European Deposit Library (NEDLIB) project (in 2000) [34] aimed at defining a workflow for ingesting, storing and accessing content in the context of deposit systems for electronic publications, while the BIBLINK project (in 1997) [31] focused on establishing authoritative rules for metadata transfer between publishers of electronic materials and national bibliographic agencies. Based on a thorough examination of the existing practices and enabling technologies, both projects concluded that it was unlikely that all content formats available on the market could be transferred through a single, standardized framework. As a result, the BIBLINK project recognized the existence of a heterogeneous environment by identifying a rather extensive list of formats and network protocols that should be supported by a national archive to facilitate metadata transfer from publishers to libraries. And, in order to be able to ingest electronic publications into the deposit system, NEDLIB introduced the concept of a pre-processing interface that is tasked with retrieving publications from a publisher, and with repackaging it to the format required by the deposit system. Both projects felt that, under the existing circumstances, aiming for a single transfer framework was unrealistic. The NEDLIB report formulates this as follows: The "pre-processing" interface is needed because deposit libraries cannot dictate submission formats to publishers: in principle, they have to accept all formats published on the market. In hindsight, it is interesting to observe that several core technologies required for the standardization of a content transfer framework were not yet available. Indeed, the BIBLINK project clearly identifies the need for a standardized packaging technique, but can only conclude that the one proposed in the Warwick framework [20] lacks maturity. In both projects, an interest in protocols with synchronization capabilities can be detected, but none is able to identify a protocol that meets the requirements. Also, both projects identify the need for ensuring authenticity and integrity of the exchanged information, but no technology can be selected that provides such guarantees across all packaging and transport techniques that are being considered. Since the finalization of these projects, several new technologies have emerged that warrant revisiting the conclusions that were reached. As will be shown in this article, a framework built on the combination of such new technologies may bring us closer to having the ability to devise a standards-based content transfer framework. Being a large-scale aggregator of published content, the Research Library of the Los Alamos National Laboratory (LANL) [note 1] has extensive experience with the significant overhead caused by the lack of standards in existing content transfer solutions. Therefore, it should come as no surprise that the Digital Library Research and Prototyping Team at LANL has opted to explore the establishment of a standards-based content transfer framework, in the context of an agreement between LANL and the American Physical Society (APS) [note 2]. Under the terms of that agreement, LANL will mirror the complete APS collection, both for the purposes of creating discovery services and preserving digital content. Over the last year, LANL has worked with the APS on the design and implementation of a solution aimed at replicating the assets of the APS collection at LANL. The project is partly funded by a grant from the Library of Congress's National Digital Information Infrastructure and Preservation Program (NDIIPP) [note 3]. Although the project has its origin in a specific publisher-to-library use case, it aims to explore a broadly applicable solution for the transfer of assets between a content provider and a content consumer. The core requirements for the transfer framework were formulated as follows: Requirements regarding the content transfer mechanism:
Requirement regarding accuracy and authenticity of the transfered content in light of digital preservation:
This article describes the design and characteristics of the solution that has emerged in response to the aforementioned requirements. The solution is based on the combination of standards that have emerged recently. The standards that play a core role in the design include: the MPEG-21 Digital Item Declaration (MPEG-21 DID) [17,18], the MPEG-21 Digital Item Identification (MPEG-21 DII) [5,19], the W3C XML Signature Syntax and Processing standard [2], and the Open Archive Initiative Protocol for Metadata Harvesting (OAI-PMH) [23]. The core characteristics of the solution are: To meet the requirements regarding the content transfer mechanism:
To meet the requirement regarding accuracy and authenticity:
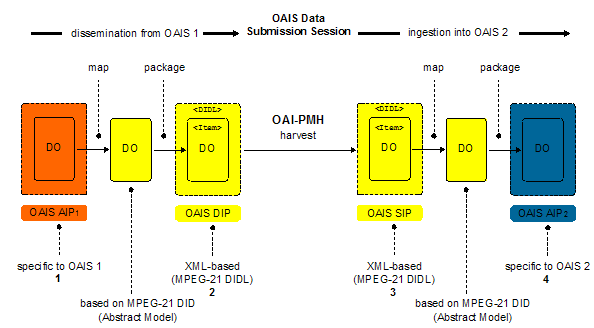
2. An OAIS perspective on the content transfer solutionEach asset of the APS collection coincides with a publication and is complex, in the sense that it may consist of multiple datastreams of a variety of MIME media types. Each asset also holds secondary information, such as an identifier and descriptive information about the publication. The Kahn/Wilensky framework [20] refers to such assets as Digital Objects. In the OAIS Reference Model [16], one may approximately equate an asset with the concept of a Content Information object. A Content Information object is a set of information that is the original target of preservation in an OAIS environment, and it is comprised of one or more Data Objects (or a constituent datastream) as well as secondary information related to the representation of these Data Objects. The identifier pertaining to a Content Information object is referred to as a Content Information Identifier. A Content Information object itself is encapsulated in a so-called Information Package, a container that holds and binds the various components making up the Content Information object. The OAIS Reference Model recognizes three subtypes of the Information Package: the Archival Information Package (OAIS AIP), the Submission Information Package (OAIS SIP), and the Dissemination Information Package (OAIS DIP). The definitions of these package types are based on the function of the archival process, which uses the package, and the translation from one package to another as it passes through the archival process. It is necessary to distinguish between an Information Package that is preserved by an OAIS and Information Packages that are submitted to, and disseminated from, an OAIS. This distinction is needed to reflect the reality that some submissions to a repository will have insufficient information to meet final requirements of that repository. In addition, different repositories may organize their content very differently, and hence, may warrant different environment-specific information to be contained within the archival packages. In accordance with the OAIS Reference Model, the terms 'producing archive' and 'consuming archive' will be used throughout the article, to refer to the archive providing the information and the archive requesting and receiving the information, respectively. The terms 'LANL' and 'APS' will be used when describing application-specific design choices. In the proposed solution, the manner in which the producing archive and the consuming archive internally represent and package the assets is of no importance. What matters is that both archives understand the application-neutral Information Packages holding the assets that are transferred between the archives during an OAI-PMH-based OAIS Data Submission Session. Indeed:
3. Exposing OAIS DIPs from the producing archiveThis Section describes the approach used to expose the assets stored in the producing archive to the consuming archive. The approach is standards-based. To meet the requirements regarding the content transfer mechanism the approach uses:
To meet the requirement regarding accuracy and authenticity the approach uses:
3.1. Using MPEG-21 DID to create XML-based, application-neutral OAIS DIPsAn asset created by the APS typically coincides with an APS publication. In the APS archive, an asset has multiple constituent datastreams, including expressive descriptive metadata, a research paper in various formats (PDF, SGML, etc.), and auxiliary content such as datasets and video recordings. Moreover, each such asset has a globally unique Digital Object Identifier [27], which the OAIS Reference Model categorizes as a Content Information Identifier. In the remainder of this article, a sample APS asset will be used to illustrate several design choices made. The main characteristics of the sample asset are given in Table 1.
Table 1. The sample APS asset. In order to be able to use the OAI-PMH to transfer assets between the producing and the consuming archives, they must be represented as XML. The compound nature of the assets requires a representation by means of a complex object format. Various candidate formats exist, including MPEG-21 DIDL [17,18], IMS-CP [14], METS [25] and XFDU [11], and of those, MPEG-21 DIDL was selected. MPEG-21 DIDL is the XML-based instantiation of the data model (or Abstract Model) for assets, as defined by the MPEG-21 DID Standard. Several reasons motivated the choice for MPEG-21 DID. A subjective motivator was the established expertise at LANL, resulting from using MPEG-21 DID in the aDORe repository environment [3,4,32], and from being actively involved in its ISO/MPEG standardization. Other, objective motivators, of importance to the described data transfer problem were:
An asset represented according to the MPEG-21 DIDL XML syntax is packaged in a so-called DIDL document. In the proposed solution, each asset of the producing archive is packaged in a DIDL document that wraps the constituent datastream(s) of that asset. The DIDL document also contains one or more identifiers, as well as secondary information such as media format of constituent datastreams. An example of a DIDL document resulting from the mapping and packaging of the sample APS asset is provided in Annex A. The core features of the mapping and packaging process are explained here and illustrated in Table 2. For simplicity, the explanation is given in terms of the XML elements of the package. Each such XML element corresponds to an Entity of the Abstract Model defined by MPEG-21 DID. The XML elements are shown in the
Table 2. An MPEG-21 DIDL perspective of the sample APS asset.
3.2. Using W3C XML Signature to enable verification of integrity and authenticityWhen transferring assets packaged in a DIDL document from the producing archive to the consuming archive, there may be a requirement to guarantee the integrity of the transferred content and the authenticity of the sender. This is the case in the APS/LANL project. We next explore the technologies used to achieve these goals. 3.2.1. Digests, digital signatures, certificates, and XML SignaturesThis Section provides a crash-course in issues related to data security, in order to allow an understanding of the approach that is used to enable verification of integrity and authenticity in the context of the proposed data transfer solution. The following concepts from the domain of data security play a fundamental role [2,30]:
Because DIDL XML documents are transferred in the proposed data transfer solution, usage of the XML Signature & Processing specification [2] has been explored and adopted. This specification defines an XML-compliant digital signature syntax that adds authentication, data integrity, and support for non-repudiation to the data that is signed. It builds on the previously described digest, signature and certificate concepts. A detailed walk-through is provided in Section 3.2.2 . Dependent on the relative position of the XML Signature and the signed data, three different types of XML Signatures can be distinguished:
3.2.2. XML Signatures for constituent datastreams of an asset
In the proposed solution, an XML Signature is provided for each constituent datastream of an asset of the producing archive. Following MPEG-21 DIDL, each such XML Signature is provided as secondary information using a
An XML Signature is represented by a
Table 3. Use of W3C XML Signatures to sign datastreams referenced or embedded in a DIDL document.
A second part of the XML Signature is related to the generation of the signature value. It identifies an algorithm – conveyed by the
An optional third part of the XML Signature, represented by the
Table 4 shows an XML Signature pertaining to the PDF datastream of the sample APS asset. The XML Signature is conveyed using a
Table 4. W3C XML Signature pertaining to the PDF datastream of the sample asset 3.3. Exposing OAIS DIPs via the OAI-PMH3.3.1. Use of complex object formats with the OAI-PMHThe Open Archives Protocol for Metadata Harvesting (OAI-PMH) [23] has been widely adopted as an approach to facilitate discovery of distributed resources. The OAI-PMH achieves this by providing a simple, yet powerful, framework for metadata harvesting. Harvesters can incrementally gather metadata records contained in distributed OAI-PMH repositories and use them to create services covering the content of those repositories. Due to its origin in the realm of resource discovery, the OAI-PMH mandates the support of the Dublin Core [28] metadata format, but strongly encourages supporting more expressive formats. In essence, any metadata format that is defined by means of an XML Schema [13] can be used to describe resources in the OAI-PMH Framework. In typical use cases, metadata exposed by OAI-PMH repositories is descriptive, and it is expressed by means of metadata formats of varying complexity, such as simple Dublin Core or MARCXML [24]. In the described content transfer solution, the OAI-PMH is used to harvest metadata that are highly expressive and accurate in their representation of assets. Such metadata formats are typically referred to as complex object formats. Introducing complex object formats as metadata formats in the OAI-PMH framework yields a robust and general solution to the resource-harvesting problem [33]. Especially, unlike other approaches aimed at gathering resources (not just metadata) based on OAI-PMH harvesting, an approach based on complex object representations of assets guarantees that a change to any constituent of a resource will result in a change of the OAI-PMH datestamp of the complex object representation of the resource. As a result, the OAI-PMH datestamp becomes a fully reliable trigger to incrementally harvest updated and added resources when those resources are represented using a complex object format. In light of the proposed content transfer solution, this feature is essential to trigger harvesting of assets that were added to or updated in the producing archive. The OAI-PMH repository operated by the producing archive has the following properties:
3.3.2. XML Signatures for DIDL documents
In addition to the XML Signatures provided at the level of each constituent datastream of an asset of the producing archive, an XML Signature is also created for the complete DIDL document that packages the asset, and that is exposed through the OAI-PMH repository of the producing archive. This XML Signature will allow checking the integrity of the transferred Information Package as a whole, after it has been harvested. The DIDL-level XML Signature provides guarantees that are not provided by the datastream-level XML Signatures. Indeed, data-corruption may, for example, occur in secondary information ( This DIDL-level XML Signature is provided in the 'about' container of the OAI-PMH record that contains the DIDL document as metadata. Doing so is in accordance with the OAI-PMH, which specifies that an 'about' container provides secondary information pertaining to the metadata provided in an OAI-PMH record. Table 5 summarizes the properties of this XML Signature. Annex B shows an example.
Table 5. Use of W3C XML Signatures to sign DIDL documents.
The OAI-PMH framework allows for batch retrieval of DIDL documents (using the OAI-PMH
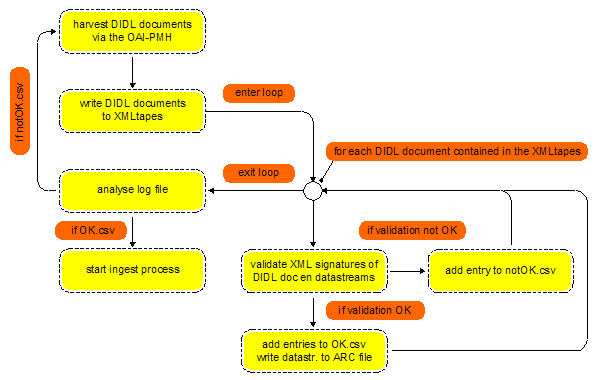
4. Ingesting OAIS SIPs in the consuming archiveThis Section describes the process that runs at the end of the consuming archive, and that is devised to recurrently collect new and updated assets from the producing archive and to store those in the pre-ingest area of the consuming archive. As will be described, and as is illustrated in Figure 2, the process consists of: Related to the transfer mechanism part of the solution:
Related to the accuracy and authenticity part of the solution:
Once this process has been concluded, and the resulting materials have been collected into the pre-ingest area of the consuming archive, they can be further processed to meet the criteria for ingestion into the consuming archive and to be ingested consecutively.
4.1 Harvesting of DIDL documents via the OAI-PMHThrough recurrent OAI-PMH harvesting, the consuming archive can collect DIDL documents from the OAI-PMH repository at the end of the producing archive. These DIDL documents are XML-based packagings of assets from the producing archive. The semantics of the OAI-PMH datestamp for the exposed DIDL documents ensures that all DIDL documents that are packagings of assets that have been added or updated since the previous harvesting session will be harvested. The harvested DIDL documents are stored in the pre-ingest area of the consuming archive. The specifics of this part of the OAI-PMH-based resource harvesting process as implemented by LANL are as follows:
4.2 Gathering constituent datastreams of assetsOnce the harvesting of DIDL documents, as described in Section 4.1, is completed, a separate process run by the consuming archive is tasked with:
In the LANL implementation, this process starts by parsing the XMLtape(s) resulting from the harvesting process, and by passing, one-by-one, each DIDL document contained in the XMLtape on to a sub-process tasked with collecting datastreams and verifying authenticity and integrity. That sub-process operates as follows (see also Figure 2):
4.3 The verification of W3C XML SignaturesIn the proposed data transfer approach, XML Signatures are provided for both the DIDL document as a whole, and for all the constituent datastreams of the asset represented by the DIDL document. Only the successful validation of the XML Signatures at both levels guarantees the faultless transfer of a packaging of an asset. The validation of an XML Signature requires the verification of the digest value by repeating the digest calculation over the transferred data and by confirming the signature value by using the signer's public key. Below, the process and the interpretation of its possible outcomes are discussed for both types of XML Signatures. Checking the DIDL-level XML Signatures. A DIDL-level XML Signature is extracted from the 'about' container of a harvested DIDL document and is processed to check its validity:
Checking the datastream-level XML Signatures. A datastream-level XML Signature is extracted from a
4.4. The pre-ingest area of the consuming archiveAs a result of the processes described in Sections 4.1 to 4.3, the pre-ingest area of the consuming archive now contains a collection of harvested DIDL documents, datastreams associated with all assets of which those DIDL documents are XML-packagings, information on the authenticity and integrity of both the DIDL documents and the datastreams, and information on the successful or unsuccessful dereferencing of datastreams. In the LANL implementation of the process, this translates to the availability of:
Table 6. OK.csv: log information for all DIDL documents for which processing was successful.
Table 7. notOK.csv: log information for all DIDL documents for which processing was unsuccessful. The notOK.csv file provides a starting point for undertaking actions regarding harvested DIDL documents that were processed unsuccessfully. It is expected that acting upon information in this file will remain a manual task until the moment that enough knowledge has been acquired about the possible error-scenarios; once such knowledge is available, certain follow-up actions could be automated. Based on the analysis provided in Section 4.3, it was decided that all actions aimed at correcting problems start by re-harvesting the DIDL document in which the error was detected, and by consecutively repeating the sub-process described in Section 4.2. As will be explained in Section 4.5, the OK.csv file is crucial for ingesting the obtained assets into the consuming archive. 4.5. Ingesting assets into the consuming archiveThe pre-ingest area of the consuming archive now effectively contains all information required to (re)construct an asset from the producing archive; all datastreams and secondary information that were shared by the producing archive are available locally. This means that an application-neutral representation, based on the MPEG-21 DID Abstract Model, of an asset from the producing archive can be recreated in the pre-ingest area of the consuming archive. Using knowledge of both the MPEG-21 DID Abstract Model, the data model used by the consuming archive, and the structure of Archival Information Packages in the consuming archive, an ingestion process can be devised that processes this information and turns it into an OAIS AIP that can be stored by the consuming archive. It can be seen that conceptually this process is very similar to the map/package process that occurred at the producing archive when it exposed its assets as XML-based packages (see Figure 1). In the LANL implementation, the OK.csv file (Table 6) unambiguously ties a DIDL document stored in an XMLtape to its constituent datastreams stored in one or more ARC files. As such, the file allows for the (re)construction, at the end of the consuming archive, of an MPEG-21 DID-based representation of the asset that was exposed by the producing archive. In this representation, all constituent datastreams of an asset are provided By-Reference, with the references being pointers into the ARC files stored in the pre-ingest area of the LANL aDORe repository. As a result of the described data transfer process, and the consecutive ingestion process, an OAIS AIP exists in both the producing archive and the consuming archive. Both OAIS AIPs package the same asset. The actual packaging of the asset as an AIP in both archives can very well be different, because those packagings are based on the data models used by the repository architectures of the respective archives. It should be noted that, especially in the context of use of the described solution for preservation purposes, the following information should be available in the OAIS AIPs in the consuming archive:
5. DiscussionThe actual size of the complete data collection of the American Physical Society is about 700 GB. For rather obvious reasons the APS/LANL content transfer project does not intend to transmit this complete collection in the manner described. Rather, an initial batch of the APS collection covering all materials up to a specific moment in time is being delivered on tapes. All materials that are added to the collection beyond that moment in time will be collected using the described approach. An estimation of the size of the dataset that will be collected by LANL is obtained by considering that, in 2004, the APS published 16,500 papers, corresponding with an archival dataset of approximately 44 GB. The APS expects a 5-10% annual increase in the amount of publications over the coming years. A quick calculation shows that, on a daily basis, around 120 MB of archival data will be collected by LANL and ingested into the aDORe repository. Such an amount seems well within the limits of the capabilities of the described solution and its underlying technologies. In the current implementation, all datastreams of an updated asset will be collected, irrespective of which actual datastreams were updated. Given that the amount of APS assets that were updated after initial publication was only around 500 in 2004, this approach does not seem to cause significant overhead for the given project. However, scenarios can be imagined that would require optimization in this respect. An obvious optimization would build on the comparison of the digests of the datastreams of the harvested DIDL document that represents the updated asset (available in the DIDL document) with the digests of constituent datastreams of the previously stored version of the asset (stored in the consuming archive). In the course of the project, a significant lesson has been learned regarding the manner in which to deliver datastreams in DIDL documents. Initial implementations made use of both the By-Value and By-Reference capabilities available in MPEG-21 DIDL. However, use of the By-Value technique, by which binary datastreams are base64-encoded before they are embedded in a DIDL document, rapidly leads to memory problems at both the producing and consuming archives. This is, amongst other factors, because large XML documents must be constructed and processed, a task that is typically achieved by building an in-memory copy first. As a result, it was decided to implement an approach whereby data is only provided By-Value up to a threshold size for a DIDL document that met the hardware restrictions at the APS end. Once that threshold was reached, all datastreams of a specific asset were delivered By-Reference. Interestingly enough, setting a safe threshold turned out not to be the easiest of tasks, and consecutive iterations kept leading to memory problems. The memory problems also inspired an implementation whereby DIDL documents were streamed out of the APS OAI-PMH repository rather than being completely built before being put on the wire. In such an implementation, it becomes impossible to verify the validity of exposed XML documents. Moreover, that implementation is typically not supported by off-the-shelf OAI-PMH repository tools. Above all, none of the described approaches addressed possible restrictions at the end of the LANL consuming archive. The problems discovered in all these implementation iterations led to the decision to deliver datastreams By-Reference only. Such a solution can be deployed on the basis of off-the-shelf OAI-PMH tools, imposes hardware requirements on the OAI-PMH implementations of both the producing and consuming archives that are very similar to those imposed by a scenario in which – say – MARCXML is harvested, and, as a result, is generic. The By-Reference-only approach has a significant additional advantage in cases where (some) datastreams need to be delivered from near-line or off-line storage. Indeed, in such cases, the OAI-PMH harvesting process can be conducted without interruption, while the waiting times to retrieve those datastreams can be postponed to the dereferencing sub-process described in Section 4.2, and can be throttled by a dedicated process at the producing archive end. The By-Reference approach also has advantages from the perspective of access rights. Indeed, a DIDL document without embedded datastreams could be exposed to all downstream harvesters without limitations, while access to specific datastreams could be controlled by a dedicated front-end to the producing archive. For completeness, it should be mentioned that the By-Reference approach also may introduce certain complexities because it requires the provision of a dereferencable URI per individual datastream of the producing archive. The URI should be independent of the actual storage layout of the producing archive as URIs are expected to be dereferencable into the indefinite future. It is envisioned that they will be used when cross-checking the integrity of the copy of the producing archive. URIs had to be created that combine the Content Information Identifier with metadata aimed at unambiguously typing individual datastreams of the identified asset. This requirement led to a significant reorganization of the APS archive to make it easier to map these URIs to specific files. Another design choice that requires further attention is the use of the content-decoding transform indicating the use of compression as described in Secion 3.2.2. Such a transform specifies which content-decoding algorithms must be applied to identified data before a digest can be calculated. In the APS/LANL project, to improve performance of the content transfer mechanism, large datastreams are compressed using the 'GNU Zip Compression' algorithm. MPEG-21 DIDL allows expressing both the MIME type of the original, uncompressed data and the compression that was applied to it. Hence, it is possible to transfer such datastreams unambiguously and to provide an XML Signature for the compressed datastream, requiring no indication of a content-decoding transform at the level of the XML Signature. However, such an approach does not make possible detecting problems that might occur during the process of compressing/decompressing the datastream. Such detection is only possible when the digest is computed over the original, uncompressed datastream. In the APS/LANL project, this has been achieved through the introduction of a transform that indicates the need to unzip the identified datastream before computing the digest. This transform is not supported by the W3C XML Signature specification, and hence requires additions to XML Signature processing software, but it was felt that the introduction of this transform was important with regard to the digital preservation goal of the APS/LANL project. LANL intends to publicly release several of the tools that were used in the context of this project. In the near future, a Perl package will be released on CPAN that facilitates the writing and reading of DIDL documents. This is the package that is being used by the APS to generate DIDL documents that are exposed through their OAI-PMH repository. This summer, LANL also plans to release a similar package written in Java. Around the same time, a bundle of packages will be released that, when combined, allow for the implementation of the OAI-PMH-based resource harvesting solution as described in Section 4. However, the resource harvesting capabilities provided by this bundle will not be limited to OAI-PMH repositories that support MPEG-21 DIDL and/or XML Signatures. Rather, harvesting from any kind of OAI-PMH repository will be possible, and a plug-in architecture will allow the use of code tailored at dereferencing datastreams. The code used will depend on the actual repository from which metadata is being harvested, the actual metadata format that is harvested, and the knowledge on how to interpret the harvested data in terms of locating datastreams. Harvested records will be written to XMLtapes, and collected datastreams to Internet ARC files; the resource harvesting process will be logged in control files. 6. ConclusionTechnologies that have emerged since the BIBLINK and NEDLIB projects reached their conclusions provide capabilities that were previously not available to address the context transfer problem. When combined, those technologies facilitate devising a standard-based solution to the content transfer problem. The proposed solution, as designed and tested in the APS/LANL project, uses:
Because the proposed solution is standards-based, it is largely deployable using off-the-shelf tools, and it is well-suited for cross-archive and cross-community content transfer. The proposed solution also has interesting characteristics that are not available in typical deployed solutions. The following characteristics that derive from the use of the OAI-PMH as a synchronization protocol are especially noteworthy:
It is hoped that the solution will attract the interest of content producers other than the APS, and content consumers other than LANL. Highly encouraging in this respect is the fact that the APS intends to start using the described mechanisms for the transfer of content with consuming archives other than LANL. Clearly, the solution addresses only part of the content transfer problem, namely the recurrent and accurate transfer of content between a producing archive and a consuming archive. Content-level problems such as the processing of received content by the consuming archive to meet the requirements of a service remain unaddressed. A typical example is the normalization of metadata and/or content from a variety of origins to a single format suitable for use in a search engine. While such processing is typically computing-intensive, it is mainly the intellectual effort required to devise accurate cross-walks between formats that is forbidding. It can only be hoped that content producers will increasingly converge towards the use of a limited amount of XML-based formats. Meanwhile, it is felt that the proposed content transfer framework can result in a significant optimization of the process of exchanging content between nodes in our networked information environment. Annex A: APS DIDL document Annex B: OAI-PMH GetRecord response containing an APS DIDL document Annex C: XMLtape containing the harvested OAI-PMH records AcknowledgmentsThe authors would like to thank their colleagues Lyudmila Balakireva, Mariella Di Giacomo, Xiaoming Liu, and Thorsten Schwander of the LANL Digital Library Research and Prototyping Team for their enormous contributions to the reported work. Many thanks also to Mark Doyle and Gerard Young from the American Physical Society for their input in the design of the mirroring process and for its concrete implementation at their end. Thanks also to Justin Littman from the Library of Congress for his efforts related to testing the OAI-PMH repository of the American Physical Society, and to Patrick Hochstenbach, at Ghent University, for his work on a previous version of the XMLtape. Jeroen Bekaert wishes to thank the Fund for Scientific Research (Flanders, Belgium) for his Ph.D. scholarship. The reported work is partially funded by a grant from the Library of Congress's National Digital Information Infrastructure Program. References1. Apache XML Security for Java (2005, March). Retrieved from <http://xml.apache.org/security/>. 2. Bartel, M., Boyer, J., Fox, B., LaMacchia, B., & Simon, E. (2002, February 12). D. Eastlake, J. Reagle & D. Solo (Eds), XML-Signature syntax and processing (W3C Recommendation). Retrieved from <http://www.w3.org/TR/xmldsig-core/>. 3. Bekaert, J., Balakireva, L., Hochstenbach, P., & Van de Sompel, H. (2004, February). Using MPEG-21 and NISO OpenURL for the dynamic dissemination of complex digital objects in the Los Alamos National Laboratory Digital Library. D-Lib Magazine, 9(11). Retrieved from <doi:10.1045/february2004-bekaert>. 4. Bekaert, J., Hochstenbach, P., & Van de Sompel, H. (2003, November). Using MPEG-21 DIDL to represent complex Digital Objects in the Los Alamos National Laboratory Digital Library. D-Lib Magazine, 9(11). Retrieved from <doi:10.1045/november2003-bekaert>. 5. Bekaert, J., & Rump, N. (Eds.) (2005, January). ISO/IEC 21000-3 PDAM1 Related Identifier Types (Output Document of the 71th MPEG Meeting, Honk Kong, China, No. ISO/IEC JTC1/SC29/WG11/N6928). Retrieved from the NIST MPEG Document Register. 6. Boyer, J. (2001 March). Canonical XML Version 1.0 (W3C Recommendation). Retrieved from <http://www.w3.org/TR/xml-c14n>. 7. Boyer, J., Eastlake, D. E., & Reagle, J. (2002, July). Exclusive XML Canonicalization (W3C Recommendation). Retrieved from <http://www.w3.org/TR/xml-exc-c14n/>. 8. Boyer, J., Hughes, M., & Reagle, J. (2002, November). XML-Signature XPath Filter 2.0 (W3C Recommendation). Retrieved from <http://www.w3.org/TR/xmldsig-filter2/>. 9. Burner, M., & Kahle, B. (1996, September 15). Arc File format. Retrieved from <http://www.archive.org/web/researcher/ArcFileFormat.php>. 10. Consultative Committee for Space Data Systems (CCSDS) Panel 2. (2004, May). Producer-Archive Interface Methodology (CCSDS Blue Book 651.0-B-1). Retrieved from <http://www.ccsds.org/CCSDS/documents/651x0b1.pdf>. 11. Consultative Committee for Space Data Systems (CCSDS) Panel 2. (2003, August). XML structure and construction rules (CCSDS Tech. Rep. No. 727/0831XFDUv09). Retrieved from <http://www.ccsds.org/docu/dscgi/ds.py/Get/File-727/0831XFDUv09.pdf>. 12. DCMI Usage Board (2004, April). DCMI Type Vocabulary (DCMI Recommendation). Retrieved from <http://dublincore.org/documents/dcmi-type-vocabulary/>. 13. Fallside, D. C. (Ed.). (2002, May 2). XML Schema Part 0: Primer (W3C Recommendation). Retrieved from <http://www.w3.org/TR/xmlschema-0/>. 14. IMS Global Learning Consortium. (2003, June). IMS content packaging XML binding specification version 1.1.3. Retrieved from <http://www.imsglobal.org/content/packaging/>. 15. International Digital Enterprise Alliance, Inc. (2004, March). PRISM: Publishing Requirements for Industry Standard Metadata. Version 1.2. Retrieved from <http://www.prismstandard.org/specifications/>. 16. International Organization for Standardization. (2003). ISO 14721:2003. Space data and information transfer systems -- Open archival information system -- Reference model (1st ed.). 17. International Organization for Standardization. (2003). ISO/IEC 21000-2:2003. Information technology -- Multimedia framework (MPEG-21) -- Part 2: Digital Item Declaration (1st ed.). 18 . International Organization for Standardization. (2005). ISO/IEC 21000-2:2005. Information technology -- Multimedia framework (MPEG-21) -- Part 2: Digital Item Declaration (2nd ed.). 19. International Organization for Standardization. (2003). ISO/IEC 21000-3:2003: Information technology -- Multimedia framework (MPEG-21) -- Part 3: Digital Item Identification (1st ed.). 20. Kahn, R., & Wilensky, R. (1995, May 13). A framework for distributed digital object services. Retrieved from <http://hdl.handle.net/cnri.dlib/tn95-01>. 21. Lagoze, C., Van de Sompel, H., Nelson, M. L., & Warner, S. (Eds.). (2002, June 21). Implementation guidelines for the Open Archives Initiative protocol for metadata harvesting (version 2.0): Specification and XML Schema for the OAI identifier format. Retrieved from <http://www.openarchives.org/OAI/2.0/guidelines-oai-identifier.htm>. 22. Lagoze, C., Van de Sompel, H., Nelson, M. L., & Warner, S. (Eds.). (2002, June 14). Implementation guidelines for the Open Archives Initiative protocol for metadata harvesting (version 2.0): XML Schema to hold provenance information in the 'about' part of a record. Retrieved from <http://www.openarchives.org/OAI/2.0/guidelines-provenance.htm>. 23. Lagoze, C., Van de Sompel, H., Nelson, M. L., & Warner, S. (Eds.). (2003, February 21). The Open Archives Initiative protocol for metadata harvesting (2nd ed.). Retrieved from <http://www.openarchives.org/OAI/2.0/openarchivesprotocol.htm>. 24. The Library of Congress: The Network Development and MARC Standards Office. (2004, June). MARC 21 XML Schema (MARCXML). Retrieved from <http://www.loc.gov/standards/marcxml/>. 25. The Library of Congress: The Network Development and MARC Standards Office. (2004, November). Metadata Encoding and Transmission Standard (METS). Retrieved from <http://www.loc.gov/standards/mets/>. 26. Liu, X., Balakireva, L., & Van de Sompel, H. (accepted). Using XMLtapes and Internet Archive ARC files to store Digital Objects and constituent datastreams in aDORe. In Proceedings of the 9th European Conference, ECDL '05, Vienna, Austria. Heidelberg, Germany: Springer-Verlag. Retrieved from <http://arxiv.org/abs/cs.DL/0503016>. 27. National Information Standards Organization. (2000, May). ANSI/NISO Z39.84-2000: Syntax for the Digital Object Identifier. Bethesda, MD: NISO Press. 28. National Information Standards Organization. (2001, September). ANSI/NISO Z39.85-2001: The Dublin Core Metadata Element Set. Bethesda, MD: NISO Press. 29. Nierman, Judith (1996). Major Milestone: Copyright Office Receives First Digital Deposit. Library of Congress Information Bulletin, March 4 1996. Retrieved from <http://www.loc.gov/loc/lcib/9604/cords.html>. 30. Siddiqui, B. (2003, April). Web Services Security Part 2. Retrieved from <http://webservices.xml.com>. 31. Sutton, C., & Clayphan, R. (1997, March). BIBLINK - LB 4034 - D5.1 Transmission of Data. Retrieved from <http://hosted.ukoln.ac.uk/biblink/wp5/d5.1.rtf>. 32. Van de Sompel, H., Bekaert, J., Liu, X., Balakireva, & L., Schwander, T. (accepted for publication). aDORe. A modular standards-based Digital Object repository. In The Computer Journal. Oxford, UK: Oxford University Press. Retrieved from <http://arxiv.org/abs/cs.DL/0502028>. 33. Van de Sompel, H., Nelson, M. L., Lagoze, C., & Warner, S. (2004, December). Resource Harvesting within the OAI-PMH Framework. D-Lib Magazine, 10(12). Retrieved from <doi:10.1045/december2004-vandesompel>. 34. van der Werf-Davelaar, T. (1999, September). Long-term Preservation of Electronic Publications. D-Lib Magazine, 5(9). Retrieved from <doi:10.1045/september99-vanderwerf>. Notes1. LANL: <http://www.lanl.gov/>. 2. APS: <http://www.aps.org/>. 3. NDIIP: <http://www.digitalpreservation.gov/>. 4. PREMIS: <http://www.oclc.org/research/projects/pmwg/>. Copyright © 2005 Jeroen Bekaert and Herbert Van de Sompel |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/june2005-bekaert
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||