| ||
D-Lib Magazine | |
| Paul Shabajee |
![]()
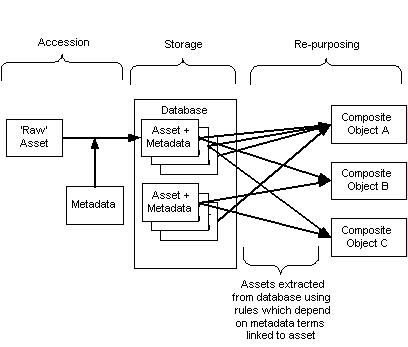
AbstractLarge multimedia database systems have great potential for educational use. Their assets can often be used to support educational and research activities in a wide variety of educational contexts, supporting learners and educators from many subject areas. This article focuses on what appears to be a fundamental dilemma for the developers of such systems regarding how to tag or index their assets with metadata so as to support discovery of the assets by these educational users. On the one hand, developers are unlikely to want (or be able) to restrictively specify who their users should be and, in particular, how they should use individual assets in their particular educational contexts. Thus they would not want to tag assets with metadata related to how the object should be used. On the other hand, they must make decisions about what metadata terms to choose to describe their assets. To do this, they must make a very limited choice, from the many thousands of potential terms available from different subject disciplines and different levels. Thus developers are seemingly forced to make choices about who their target users are and how they will want to use the resources. In other words developers may have to do exactly what they do not want to do. This article explores in detail the causes of this dilemma and introduces three complementary approaches to resolving the situation. Introduction and Educational AimsThis article stems from work of the ARKive-ERA (Educational re-purposing of Assets) project set up to investigate how best to design the underlying technological infrastructures and architectures to enable large multimedia database systems such as the ARKive project, described below, to maximise the educational potential of their multimedia assets for users. The development of such architectures and their educational uses are currently very important in that they underpin the ability of developers to provide valuable educational resources to their users. It is through these architectures that the full educational potential of the very large investments taking place in digitisation projects across the world in public, not-for-profit and commercial sectors can be realised. For some examples of projects, see nof-digitise (2002) and the Australian Libraries Gateway (2002). ARKive (Wildscreen Trust, 2002) is characteristic of many of the larger projects. During its initial phase of development, it will contain data that profiles some 1,500 globally endangered and native UK species and their habitats. This will take the form of approximately 9,000 minutes of digitised video and 30,000 still images, along with hours of audio, maps, textual information and other supporting media and educational materials. Central to any such architecture is the ability to re-purpose or enable others to locate and re-purpose a single digital asset in different contexts, e.g., taking a single digital image and reusing it on multiple web pages relating to different topics; as part of an on-line tutorial; as an image on a printable handout for students; or in interactive quizzes or support materials for teachers. ARKive as an organisation plans to focus on developing learning resources, built from its own multimedia assets, focused on biodiversity and sustainable development issues. However, ARKive is very aware that the media and other assets held in its database will have great potential for many other areas of education (for example, arts, media studies, geography, chemistry, anthropology, medicine and many others). ARKive and, one assumes, many other similar projects aim to enable users to gain maximum educational benefit from available resources, regardless of the user's subject of study or interest, level of study, age, cultural background, intellectual background, disabilities or, indeed, any other characteristic. The crux of the problem described in this article is, therefore: How can ARKive-type resources be designed and created such that users who wish to do so can access and use the assets as effectively and efficiently as possible—for learning and teaching from a wide range of subject disciplines, from different phases of education, from formal or informal education, and from different cultural backgrounds? Re-purposing, Metadata and Resource DiscoveryIt is not the aim of this article to review the literature on the re-purposing of educational assets (see Dingley and Shabajee, 2001 for more background). However, it is necessary to provide an overview of the basic processes involved. Figure 1 shows a highly simplified diagram of the necessary processes. The 'raw' digital asset has metadata (see below) linked to it and is then stored with its metadata in a database. The asset is then available to be used to produce composite objects, e.g., Web pages, on-line tutorials and interactive games. The re-purposing is done by extracting the individual assets from the database. In order to do this, it is necessary to use the metadata, e.g., unique ID (identifier), aspects of content description, and likely audience.
As Figure 1 shows, metadata is central to effective re-purposing. Metadata is broadly defined as 'data about data' (Gilliland-Swetland, 1998). It provides 'hooks' by which the resources can be extracted from or discovered within a database. There are different types of metadata. Gilliland-Swetland (1998) distinguishes between 5 types:
The traditional library catalogue index card is a classic example of metadata. The publication date, author, title, publisher, Dewey decimal code, etc., are metadata elements within a clearly defined metadata schema and scheme (list of metadata elements, allowed states of those elements, and relationships between them). The individual fields of metadata are called elements. In relation to educational uses of such resources, the term most widely used to refer to multimedia and other assets that may be used for educational purposes is 'learning objects' (Wiley, 2002). There is no universally agreed definition of 'learning object'. Probably the most widely used is that developed by the IEEE Learning Technology Standards Committee (IEEE LTSC, 2002): " any entity, digital or non-digital, which can be used, re-used or referenced during technology supported learning". Some argue (e.g., Wiley, 2002) that such a definition is too general, as under this definition "The War of 1812" or the historical figure of "Joan of Arc" may be considered as learning objects. Wiley uses the less inclusive definition of 'learning object' " any digital resource that can be reused to support learning". As noted above, metadata provides the 'hooks' by which objects can be extracted from a database system. In the case of learning objects, it is necessary to have educational metadata (see below), a subset of 'use' metadata, to provide hooks related to educational uses of a learning object. One example of this need is the ability to differentiate between different types of learning objects, e.g., simulation, questionnaire and diagram. There have been various approaches to developing a taxonomy of learning object types (e.g., Currier and Campbell, 2000, IEEE LTSC, 2002) that could form the basis of metadata element sets describing them. In all of these, the most basic type of object is a 'raw' individual or fundamental 'learning object' uncombined with any other, e.g., a still image or self-contained video clip. This is by no means uncontentious, as the granularity (i.e., how big a single learning object is) could in principle be as small as a pixel in a still image or as large as a certificated course. However, in practice the smallest is broadly taken to be 'raw media data or fragments' (IEEE LTSC 2002, Wiley 2002). These fundamental objects are combined to produce the composite or aggregated learning objects that are generally utilised by educators and learners to support their study, e.g., simple Web pages, interactive quizzes, tutorials and on-line discussion. ARKive-type database systems can provide very rich raw material or fundamental learning objects for such resources. Educational Metadata and 'Raw' Multimedia AssetsMany educational metadata standards or learning object metadata standards have been developed to enable the systematic description of learning objects with relevant metadata (IEEE LTSC, 2002, EdNA, 2001, Ariadine, 1999). The elements of the metadata that are regarded as the "key educational or pedagogic characteristics" of a learning object in the IEEE LOM (IEEE LTSC, 2002) standard are:
While for composite resources these kinds of elements are meaningful, for raw assets they are generally either not relevant or could be labeled with all possible states. For example, the concepts of 'interactivity type', 'typical learning time', 'semantic density', 'intended end user role' of an image are not meaningful without a clear context, and 'typical age range' for the majority of images is simply 'all'. So, if educational or pedagogical metadata elements are not useful in answering our question above (see "Introduction and Educational Aims"), what metadata—if any—is relevant to providing educationally focused 'hooks' into the raw multimedia assets in a database? Or more fully: Given that ARKive-type projects aim to maximise the potential educational value of their multimedia assets for ALL educational users, what are the most appropriate metadata vocabulary terms to mark-up the 'raw' multimedia and other data, so as to enable the most effective information retrieval for educational re-purposing? The Developers DilemmaIn attempting to answer this simple question, our project hit what appears, at least at first sight, to be an irresolvable problem. There were three steps in identifying the problem: 1) Metadata is Fundamental to Resource DiscoveryAs can be seen from Figure 1, resource discovery is fundamental to any kind of re-purposing of assets. Unless a resource can be discovered when required, it cannot be re-purposed. This is akin to the famous philosophical question, "If a tree falls in a forest and there's no one there to hear it, does it make a sound?" — "If an digital resource is in a database but can't be found, is it really there?" The difference is that, here, the matter has very immediate and real consequences. If a digital resource (or any resource) can't be found in a database, it may as well not be there. However relevant to a query, beautiful, historically important or effective at illustrating a concept, it is effectively, simply not there. Thus the choice of metadata terms is fundamentally important for discovering or rediscovering a resource to be used in any re-purposing. This is especially the case for large or remote collections not easily searched by examining resources individually. For example, as noted above, ARKive estimates that it will contain some 9,000 minutes of video and 30,000 still images in its initial phase of development. Clearly it would be impractical to search for images or video clips 'by hand' in such an environment. 2) Context is Fundamental to MetadataAny object, physical or virtual, could be described and discussed in possibly limitless ways. The categories of metadata above (see the section on re-purposing, Metadata and Resource Discovery) indicate some of these. Possibly the richest types would be the description of content and uses to which the object could be put.
For example, Figure 2 shows an image from the ARKive database. Two questions might be asked: a) How might Figure 2, or any part of it, be used in an educational context? b) How might the content of the image be described? It could be argued that the answer to a) is 'in an almost infinite number of ways, limited only by the imagination of the educator and/or learner.' Similarly, the answer for b) is 'any number of ways depending on the perspective from which one approaches the image (e.g., historical, artistic, ecological, socio-cultural, horticultural, etc.).' A simple way to illustrate the situation is to look at metadata vocabularies used by specialist interest groups (Shabajee et al., 2002).
While any particular collection of multimedia will not necessarily contain objects that would be appropriately indexed under many of the terms from each and every available specialist vocabulary, it is nonetheless possible that some terms from all of these will be applicable to some objects. In practical and theoretical terms, it would be impossible for every single ARKive-type project to tag all of their multimedia assets with all of the possible metadata terms from all possible metadata vocabularies to support all possible educational uses of an asset. Choosing a manageable number of metadata terms (from the very large number possible) will depend on the context in which the resource will be sought and utilised. This means that even if it was decided to say nothing about how an asset might be used, that is, not to use the metadata elements related to 'possible use' (i.e., question a) above), the descriptive metadata terms chosen would necessarily depend on conscious or sub-conscious assumptions about who will use it and how. For example, in the case of traditional systems such as library catalogues, the assumed model of use is embedded in the system. If a library user doesn't know the details of a book (i.e., those types of data in the database) but remembers the graphic design of the cover sleeve in great detail, the system is useless to them for that specific enquiry, even though the book may be on the shelves. Indeed, user centred design or contextual design approaches (e.g., Noyes and Barber, 1999 and Beyer and Holtzblatt, 1998) to the development of information tools, which aim to ensure that a system will meet the needs of users effectively, argue that it is necessary to understand in detail the context in which information is to be used in order to design and build an effective system. 3) Catch 22 - You Can't, But You Have ToCombining 1) and 2) we find that: The resources held by large multimedia databases such as ARKive, have almost limitless educational potential. The collection may be used by learning resource developers, learners or educators from different subject disciplines and sub-disciplines, phases of education, using different curricular, etc. As outlined above, the specific needs of each of these groups would differ to a greater or lesser degree. Thus if developers of ARKive-type resources want to enable all potential educational users to gain maximum benefit from the assets held in their database, they do not want to dictate or second guess how people might use a resource. This is particularly the case for very long-term projects such as ARKive, as they cannot possibly reliably predict how educational users will want to use the assets in the future. However, in order to allow anyone to find anything in a usable and effective manner—with finite time and budgets available to index assets—requires that specific choices of metadata terms to be used must be made, which in turn require assumptions about the users and likely uses to which the resource might be put! Put more succinctly: You don't want to (and can't) predict what your users will want to use the 'raw' multimedia assets for, but if you don't, your users can't get to the assets. Implications for educational metadataApproaching this from another direction; we said in step 2 above; " even if it was decided to say nothing about how an asset might be used, that is, not to use the metadata elements related to possible use the descriptive metadata terms chosen, would necessarily depend on conscious or sub-conscious assumptions about who will use it and how." The existence of the dilemma indicates that it is simply not possible to say nothing or more exactly assume nothing, about possible [educational] uses of raw assets. All of which takes us back to the section on educational metadata above, where it was said that the educational metadata elements in common usage, are not generally meaningful with respect to raw assets, which still appears to hold true. So what is going on? I would argue that the existing situation with regard to educational metadata could be summed up as follows:
The description of context and, in particular, educational context is highly problematic. As Shabajee and Postlethwaite (1999) argue, there are possibly thousands of contextual variables that may impact on any single educational event. Probably the most common approach to dealing with this is to decide which of the thousands of variables are significant in any particular situation(s) (Shabajee, 1999) and to use those variables to describe or model the context. This is broadly the approach of the existing educational metadata standards; they focus on what the developers of the standards have collectively decided are significant about the contexts with respect to the purposes of the standards. Could a model be devised which fully and accurately described all possible educational contexts? I would argue strongly that the answer is no. As can be seen by studying any educational research journal, as researchers we are still struggling to understand the interactions of simple variables, in general at levels of statistical probabilities, let alone how thousands of these variables are interacting simultaneously. Thus the best approach for educational metadata may be to focus on a small set of variables or elements and their possible states that are the most relevant to their purposes. Whether the current standards meet that requirement is, of course, another matter. Perhaps the simple metadata approach, coupled with other approaches such as the Educational Modelling Language (EML) under development (Koper, 2001), might offer additional elements to describe the mapping between context and descriptive metadata described above. Beyond Metadata - The Need for Semantic ToolsThis article has set out to describe the fundamental dilemma identified by the author, while investigating the requirements for the development of ARKive-type systems. The author does not have any well developed solutions to the problem identified. However, what seems clear is that metadata alone is not sufficient to resolve the dilemma. So what can developers do to balance the wish to serve a diverse range of users while making the indexing and management of their raw assets tractable? The author would argue that it comes down to what we, as developers, aim to do. Unless our aims with respect to serving our users are made explicit, it is difficult to make informed decisions about even basic questions such as where the balance between completeness and tractability should lie, or what vocabularies or metadata standards should be used. If, as developers, we do want to serve our non-target users effectively, making explicit what we aim to do is probably a good first step. However, that alone is not sufficient to resolve the dilemma. All that extending the metadata vocabulary can do, in principle, is extend the usefulness of the system to a wider range of users. It does not solve the fundamental problem that it is not possible to know or predict what users will want to access the collection of raw assets to do, or from what perspective. To begin to solve that more fundamental problem, the author has identified three complementary approaches:
By combining these and other approaches, it might be possible to at least partially resolve the dilemma. While a comprehensive system to automatically index multimedia objects is not in place—and there may be underlying reasons why it may be impossible to develop such an all encompassing system—there are already tools, and many others under development, that if combined, offer the beginnings of a set of tool sets to help developers help their users do just this. Some of these are outlined more fully in Shabajee et al (2002) in their paper that focused on community annotation to add value to on-line multimedia collections. Such tools provide means of semantic bootstrapping, a process described by Shabajee et al. (2002) as: " that is, when a collection has been indexed from one perspective (i.e., for its primary target use or user group) using one set of vocabularies, it is necessary to have or create some kind of 'semantic hook(s)' in the data to allow users to begin the process of indexing the collection from the new perspective, using the new vocabulary." Three illustrative examples of such tools include: The development of interoperable domain ontologies: Broadly speaking, an ontology is a formal, explicit specification of a shared conceptual model; it describes the terms used and their relationships in a machine-readable manner (see W3C 2002b for more detail). By using the vocabulary and the defined relationships between the terms, it is possible (although very problematic at present) to map the terms in one ontology (thus vocabulary) to those in another. Concept extraction tools such as the 'Non Zero Match' tool developed at the University of Bristol (http://nzm.dig.bris.ac.uk/index.html). The tool allows users to auto-index text-based documents using concepts defined by a list of words/phrases with positive and negative weights. Another approach is taken by Bobrovnikoff (2000) using the DIPRE (Dual Interative Pattern Relation Extraction) algorithm to recognise patterns in existing data. Auto-indexing of still and moving images also provides the potential to extract and index new concepts related to the content of the images. See Campbell et al. (1997) and Lew (2000) for examples of this approach. Whilst these and other related tools and approaches have a long way to go before they are robust over a wide range of concept domains, and usable by end users, as Shabajee et al. (2002) indicate "These developments form, what can be seen as part of a larger movement in Web technology development towards a more semantically interoperable Web (W3C 2001a, Berners-Lee et al 2001) in which information is globally interoperable." This type of approach seems to offer the potential to at least begin to resolve the dilemma outlined above. ConclusionsThere appears to be a fundamental dilemma for the developers of large on-line multimedia archives who wish to serve their educational users as effectively as possible. They do now wish to, and cannot, predict how users from a diverse range of perspectives (and futures) might wish to access the raw multimedia objects in their collections: in particular, what search terms that they might use, which reflect the concepts that are of interest to them, that the object(s) illustrate. It seems that the underlying problem is that it is simply impractical, if not impossible, to index all objects under all possible and appropriate indexing terms. Thus it appears that better metadata alone cannot be the solution to the dilemma. Three complementary approaches have been identified to help resolve the dilemma:
The author hopes that these and other approaches will provide the basis of a set of approaches and tools to help developers of multimedia archives support all of their potential educational users' access to their raw assets, as effectively as possible. AcknowledgementsThe ARKive-ERA is funded by Hewlett Packard Labs, Bristol. ReferencesARIADNE. (1999) ARIADNE Educational Metadata Recommendation, Version 3, December 1999. available online: <http://ariadne.unil.ch/Metadata>. Berners-Lee, T., Hendler, J. and Lassila, O. (2001) The Semantic Web, Scientific American, May 2001. Australian Libraries Gateway (2002) Australian Digitisation Projects, Available on-line: <http://www.nla.gov.au/libraries/digitisation>. Beyer, H. and Holtzblatt, K. (1998) Contextual Design, Morgan Kaufmann. Buckingham Shum, S., E. Motta, et al. (2000). International Journal on Digital Libraries, 3(3): 237-248. Campbell, N. W., Thomas, B. T. and Troscianko, T. (1997) Automatic Segmentation and Classification of Outdoor Images using Neural Networks., International Journal of Neural Systems, 8, 137—144. Currier, S. and Campbell, L. M. (2000) SeSDL taxonomy. November 2000, Scottish Electronic Staff Development Library (SeSDL). Available: <http://www.sesdl.scotcit.ac.uk:8082>. Dingley, A. and Shabajee, P. (2001) In IEEE International Conference on Advanced Learning Technologies (ICALT 2001)IEEE Computer Society Press, Madison, USA EdNA. (2001) EdNA Metadata Homepage. Available online: <http://standards.edna.edu.au/metadata/index.html>. European Environment Agency (2002). GEneral Multilingual Environmental Thesaurus (GEMET): The GEMET 2.0 Approach. Available on-line: <http://www.mu.niedersachsen.de/cds/etc-cds_neu/library/Gemet.pdf>. Gilliland-Swetland, Anne J. (1998) "Setting the Stage: Defining Metadata" in Introduction to Metadata: Pathways to Digital Information, Murtha Baca, ed. Los Angeles: Getty Information Institute, Available on-line: <http://www.getty.edu/research/institute/standards/intrometadata/2_articles/index.html>. IEEE Learning Technology Standards Committee (LTSC). (2002) Draft Standard for Learning Object Metadata, ver. 6.4. Available: <http://ltsc.ieee.org/doc/wg12/LOM_WD6_4.pdf>. Koper, Rob. (2001) Pedagogical meta-model behind EML, First draft, version 2, June 2001. Available on-line: <http://eml.ou.nl/introduction/docs/ped-metamodel.pdf>. Lew, Michael (2000) "Next-Generation Web Searches for Visual Content," IEEE Computer, 33(11) p46-53, November, 2000. New Opportunities Fund (2002) nof-digitise homepage. Available on-line: <http://www.nof-digitise.org>. Noyes, J. and Barber, C. (1999) User-Centered Design of Systems, Springer, London. Qualifications and Curriculum Authority (2002). National Curriculum Online Metadata Standard Overview. Available on-line <http://www.nc.uk.net/metadata/>. Shabajee, P (1999) "Modelling the Dynamic Nature of Interactivity in Teaching and Learning," British Educational Research Association (BERA) Conferenece 1999, Brighton, 1999 Shabajee, P. and Postlethwaite, K. (1999) "Interactivity towards a framework to describe, model, visualise and harness its dynamic nature," British Journal of Educational Technology, 30, p371-373. Shabajee, P., Miller, L. and Dingley, A. (2002) In Museums and the Web 2002: Selected Papers from an International Conference (Eds, Bearman, D. and Trant, J.) Archives & Museums Informatics, Boston, USA. Available: <http://www.archimuse.com/mw2002/papers/shabajee/shabajee.html>. W3C. (2001a) Semantic Web. <http://www.w3.org/2001/sw/>. W3C. (2002b) Web-Ontology (WebOnt) Working Group Homepage. W3C. Available: <http://www.w3.org/2001/sw/WebOnt/>. Wildscreen Trust (2002) ARKive, Available online: <http://www.wildscreen.org.uk/arkive.htm>. Wiley, D. A. (2000) Connecting learning objects to instructional design theory: A definition, a metaphor, and a taxonomy. Available: <http://reusability.org/read/>.
Copyright © Paul Shabajee | |||||||||||||
| | |||||||||||||
| Top | Contents | |||||||||||||
| | |||||||||||||
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/june2002-shabajee
|