| ||
D-Lib Magazine | |
| Johan Bollen Rick Luce |
![]()
AbstractAt present, digital library (DL) policy is largely informed by management intuition and coarse measures of user satisfaction. Most DLs, however, maintain extensive server logs of user retrieval requests that contain a wealth of information on user preferences and the structure of user retrieval patterns. We propose a quantitative approach to DL evaluation that analyzes the retrieval habits of users to assess the impact of a collection of documents and to determine the structure of a given DL user community. We discuss a system that we have developed to automatically generate extensive journal and document networks from an efficient and simple analysis of user retrieval sequences registered in a particular DL's server logs. IntroductionThe proliferation of DL services has given rise to the problem of evaluating their quality and impact [Kaplan 2000]. Although many have discussed the benefits DL services bring to users and some efforts have been made to establish an objective basis for such claims, few techniques are available at present to quantitatively evaluate the impact of a DL's collection and the characteristics of its user community. This situation leaves DL management with few established techniques to assess the efficiency and impact of their collections and services, or how well they address user needs and preferences. DL evaluation techniquesThe evaluation of DL services and collections is a multi-faceted problem that cuts across a wide range of systems, interfaces, and user communities as well as a multitude of issues in Human-Computer Interaction. Present DL research does not differ much from other engineering domains in the sense that the development and implementation of novel DL applications have generally taken priority over the evaluation of their actual effectiveness and the degree to which they efficiently address existing user needs. Any evaluation of DL collections and services must inevitably take into account the characteristics of the DL's user community. However, the study of user needs and preferences has largely eluded quantitative analysis. Although some efforts have been made to register user satisfaction and preferences, the mere registration of user preferences cannot suffice to adequately capture the perspectives and preferences of a large community of users. User preferences and satisfaction tend to be highly transient and specific. User search focus can shift from one scientific domain to another between, or even within, retrieval sessions. Analysis of user preferences and user satisfaction therefore needs to focus on more stable characteristics of a given user community such as the community's perspective on general document impact and the relationships between documents in a collection. A user-centered approach to DL evaluationWe have developed a DL evaluation system that allows DL management to conveniently generate journal and document rankings over an existing collection based on the preferences of users as they are expressed implicitly in the users' collective patterns of document retrieval. Rather than rely on explicit measures of user satisfaction, interest and preference, we focus on implicit, community-determined measures of document relationships derived from the retrieval patterns recorded for a large community of users. These relationships represent features of the user community and can be used to generate a community-specific measure of document impact. Clusters of documents can be generated from the same data and may reveal structural features of the composition of the user community. This data will inform DL policies regarding acquisition, collection and services organization, general science objectives, etc. Our approach to analyzing the characteristics of specific user communities is founded on the analysis of user document retrieval requests in a DL's World Wide Web (WWW) interfaces. We generate document and journal networks from user retrieval sequences as they can be reconstructed from DL WWW server logs. These networks express a collective "mental map" of the preferred relationships among documents as they exist among a specific community of DL users, namely those for which the DL server logs have been registered. The generated networks can be analyzed to reveal user preferences, and the structure of that user community, in terms of journal and document relationships. Document and journal impact measures can be derived from the graph-theoretical properties of these networks and applied to any documents for which retrieval requests have been registered, including technical reports, multimedia documents, etc. The derivation of document networks from DL server logsOn-line DL services generally maintain a log of user requests in a set of log files. These log files contain detailed information regarding user requests such as the originating IP number, date and time of the request, a document identification number corresponding to the requested document (often including an ISSN for the publishing journal), etc. DL server logs thereby contain valuable information on past user interaction with a DL service and may yield information on regularities in user interests and preferences. The most common analysis of such DL server logs is the generation of access statistics (e.g., which documents have been retrieved most frequently, or from which network domains have the most requests originated, etc.). This type of analysis can yield interesting results on the general characteristics of user request frequency, but little information is generated regarding the structure of user preferences or the structure of a user community. Instead of simply knowing which documents are most popular, one might like to know, for example, to which other documents is a retrieved document strongly similar, and to which groups of users do these similarities apply and why. Our research has focused on determining the structure of relationships among documents from registered patterns of user retrieval, and the analysis of these relationships to determine document impact and the structure of the DL user community. Hebb's law of learning for document retrievalsUnfortunately, server logs do not contain explicit statements of user interests, the structure of document relationships or the structure of DL user communities. However, this data can be derived from the information in most DL server logs on the basis of one rather straightforward assumption commonly applied to models of human learning and machine learning. When Donald O. Hebb formulated what is now known as Hebb's law of learning, he did not intend to promote a logical fallacy [1], but rather to describe the neural mechanism by which the human brain was assumed to learn to associate events and concepts. Simply stated, Hebb's law of learning postulated that when two neurons fire in close temporal proximity the strength of their connection—or rather the ability of the synapse connecting the two neurons to transmit potentials—would be increased. In other words, when neurons A and B fire in close temporal proximity, the weight of their connection increases. This principle has been applied countless times to machine learning and the simulation of human learning [Rosenblatt 1962, Rumelhart and McClelland 1986]. We have applied a similar law of learning to the generation of document relationships from their co-occurrences in DL server logs. Our central assumption is that when an individual user is searching for documents in a DL, this search focuses on a given subject matter. Therefore, when a user retrieves two documents within a short period of time, it adds support to the claim that some level of similarity exists between these documents. When many users repeatedly retrieve the same pair document within a short period of time, this is an even stronger indication that the two documents are related or similar. In other words, the frequency by which two documents are retrieved in temporal proximity over a population of DL users corresponds to the strength of the relationship between these documents. When users retrieve documents from DL services, the relevant data associated with their retrieval requests (e.g., date and time of the requests, originating IP number, document identifier, etc) are recorded in the system's server logs. A system can scan the DL server log files for documents that are retrieved in close temporal proximity or within the same user session by the same user. Each time a given pair of documents A and B are thus "co-retrieved", the system can increase the weight of their relationship by a certain small amount. After scanning a large set of recorded document retrieval requests, the weights between pairs of documents will have accumulated differing weight values, which can be held to indicate the degree of similarity of these documents as perceived by that group of users. The generated document relationship weights can be combined to form document networks whose structure represents the views and perspectives of a specific community of users as they were implicitly expressed in the retrieval patterns recorded for that community. These networks can then be analyzed to yield measures of document impact specific to that community of users, and to reveal characteristics of the community. Document co-retrieval and link weight generationThe procedure for generating document relationships from DL server logs is a fairly simple one. We define a document co-retrieval event as a pair of sequential retrieval requests for a pair of documents by the same user within a given period of time labeled ?(t). From that definition, co-retrieval events can be reconstructed from DL server logs by scanning the time sorted document retrieval requests issued from the same IP number and determining that any two subsequent requests whose date and time stamps differ less than the quantity Delta (t) constitute a co-retrieval event. Once a DL server log has been scanned for co-retrieval events, the system can start generating weighted document relationships by increasing the weight of the relationship between each pair of documents involved in a co-retrieval event by a certain small amount, r. Table 1: An example of a
DL server log containg a user ID,
Table 2: Co-retrieval events derived from the set
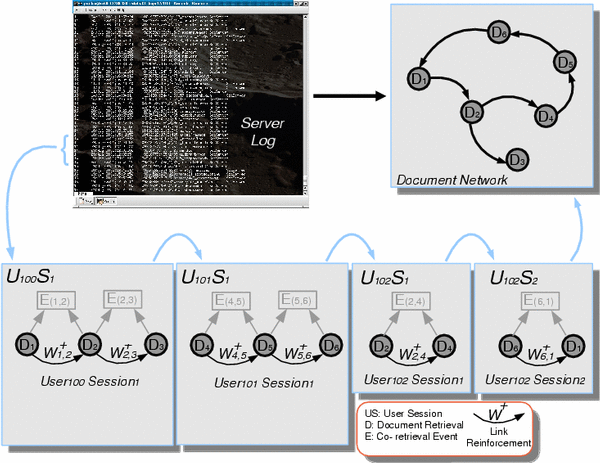
For example, a sample of a DL server log is shown in Table 1. A set of co-retrieval events is derived from this server log, as shown in Table 2. A user identified by the number [2] 100 retrieved three documents in sequence, namely documents 1, 2 and 3, and each pair of retrieved documents was separated by less than 3600s, which for this example is chosen to be the threshold for co-retrieval event detection. Thus, two co-retrieval events are generated denoted e(1,2) and e(2,3). The link weight between the two documents involved in these co-retrieval events is consequently increased by a small amount. Similarly, the user identified by the number 101 retrieves 3 documents in a session, namely documents 4, 5 and 6. Again two co-retrieval events are generated as all retrieval requests occurred within a period of time smaller than the defined threshold. The link weights between the retrieved documents are then updated. User 102 retrieved documents during two separately registered sessions. In each session, two documents have been retrieved within a time period smaller than the threshold. Consequently, two co-retrieval events are generated for documents 2 and 4, and 6 and 1. Again, link weights between these documents are updated. A schematic representation of how this procedure scans a DL server log for co-retrieval events and generates a network of weighted document relationships as shown in Figure 1.
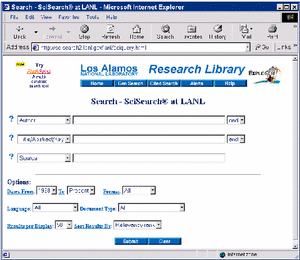
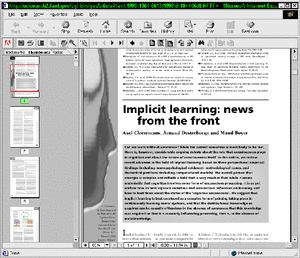
This procedure scans a DL server log for document retrievals by the same user within a certain period of time. Each time such a co-retrieval is found, the weight of the relationship between the two retrieved documents is increased. After scanning a large DL server log, the generated network will represent the structure of the relationships between documents as implicitly expressed by the DL user community in their document retrieval requests. The network can be expanded at any point by analyzing additional DL server logs. What does it all mean?In many ways, the generated networks can be thought of as a measurement of the notions of document relationships as they exist in the user community for which the DL server logs have been registered. The networks represent an essential feature of the user community that can perhaps best be described as the collective common-sense knowledge of document relationships. Rather than focus on individual, inherently transient preferences for specific documents, the generated networks embody aspects of the knowledge of document relationships collectively held by a community of DL users. The focus is not on what individual users happen to like, but on the knowledge users share of general relationships and similarities of documents in a given DL collection. The discussed methodology to derive large document networks from user co-retrieval patterns was first developed for adaptive hypertext linking and has been modified for applications to DL document linking and DL evaluation [Bollen 2000]. It has been applied in this context to the server logs of the Los Alamos National Laboratory [Bollen 2000]. In both simulations and the above mentioned applications, the methodology has been shown to reliably and validly generate document networks that represent the collective preferences of a specific user community, namely those whose recorded retrieval patterns have been used to generate the network [Bollen 2001]. Network analysisClearly, the generated networks, as a representation of the knowledge of document relationships held by a community, can be put to use for the evaluation of how well a DL collection and its organization match the views and perspectives of its users. We have focused on two specific graph-theoretical features of the generated networks: the impact or influence of specific documents and journals, and a hierarchical cluster analysis of network structure. Document and journal consultation frequencyJournal impact has traditionally been assessed in terms of journal citation frequency [Garfield 1979]. ISI® yearly publishes the Journal Citation Record database that lists a particular journal's Impact Factor (IF): a citation frequency-based measure of general journal impact. The IF for a given journal for a specific year x is defined as the ratio of two quantities A and B, so that The IF has found widespread acceptance for assessing the impact of scholarly publications, as well as for assessing individual researchers by proxy of the journals in which they published, etc. However, a number of authors have pointed to problems associated with the use of citation frequency [Opthof 1997, Seglen 1997, MacRoberts 1989] such as author biases, weak relationship of a journal's IF to the published articles, etc. We feel that the IF, due to its reliance on citation frequencies, suffers from a number of additional problems, namely its inherent disregard for the preferences of readers or DL users, who constitute a larger community than that of authors, and the fact that it is only relevant for scholarly, text-based publications. A wide range of electronic publications (multimedia, WWW publications, etc.) eludes traditional citation analysis, and the impact or importance to the scientific community of these electronic publications is consequently disregarded or underestimated. A measure of article and journal impact can, however, be derived from the structure of the document networks generated according to our methodology. Similarly to Darmoni [Darmoni 2001], we define a measure of document and journal impact, namely the Journal Consultation Frequency (JCF), based on patterns of usage or readership rather than frequency of citation. The JCF is defined as the sum of the in- and out-degree of each document in the network, or the number of connections from other documents to the document in question, added to the number of connections from the document to all other documents in the network. The JCF therefore expresses the degree to which a specific document is connected to other documents, or its general centrality to network structure. Since it is calculated based on connections in a network generated from user retrieval requests, the calculated journal impact is tailored to a specific user community. Furthermore, the JCF expresses document impact regardless of language or media. It can inform DL management which documents are most important to the DL's local user community for a wider range of collections than can the IF, and offers a means to evaluate the impact of the DL's collection in terms of its specific user community. At the least, supplementing IF with other measures would yield a clearer mosaic of measures reflecting actual impact. Hierarchical cluster analysisThe generated document networks are taken to represent document relationships as they are perceived or preferred by a community of DL users. Therefore, a hierarchical cluster analysis will yield information on the general structure of these relationships and, consequently, on the composition of the underlying user community. In many cases, when DL services attempt to take into account the structure or characteristics of its user community, the structure of such community will be organized according to institutional boundaries or existing subject matter classifications. For example, a DL search service will focus on mathematics or computer science, since these subjects correspond to actual university departments or existing subject classification such as the Library of Congress Classifications. However, in a modern multi-disciplinary research environment many users elude such classifications. For example, a member of a Computer Science department may be active in both DL research and Cognitive Science, and collaborate with other researchers in the Mathematics, Psychology and Computer Science departments. A group of such researchers may form a research domain that exists implicitly but has not yet been named or appropriately categorized. These types of user clusters are neither expressed in the institutional adherences of these researchers, nor in any existing subject matter classification. Furthermore, the clusters may shift over time and make obsolete any existing categorization. Nevertheless, such an informal group of researchers will focus their document retrievals on a certain subset of a DL collection. The generated document networks can therefore contain cliques of documents corresponding to the interests of certain informal groups of users. A cluster analysis on document networks can reveal user clusters that may or may not be reflected in institutional boundaries or subject classifications, and to which DL management may respond by changes in the organization of their collections and services. Preliminary resultsWe tested our analysis for a set of document networks generated from the retrieval patterns recorded for users of the Los Alamos National Laboratory (LANL) Research Library (RL). The LANL RL has implemented a large number of DL services that allow users to search a collection's meta-data and retrieve the digitized version of the requested articles. We focused specifically on users of the LANL RL SciSearch retrieval service, because its server kept the most complete records of user article retrieval requests. Since 2001, the set of registered logs has been expanded to all LANL RL services. The Los Alamos National Laboratory SciSearch database is based on the Science Citation Index, a product of the ISI(R) that provides indexing, citation and meta-data for articles published in the large number of scientific domains such as astronomy, biology, physics, computer science, engineering, etc. The LANL Research Library has subscriptions to a large number of publisher services offering access to digital copies of the documents bibliographically indexed in the SciSearch database. SciSearch users can search and retrieve an article's bibliographic information, and can also download the actual articles from any of these subscribed services. The collection of downloadable full-text documents contains over 4,000,000 records at present, and it is updated on a weekly basis. User interactionFigure 2, left is a screenshot of the Los Alamos National Library web page offering access to the SciSearch database. A number of text fields allow the user to search on several kinds of bibliographic information such as "author name","title", "publication year", "ISSN", etc. When a search request is issued, the SciSearch database returns a list containing the abbreviated meta-data for all matching articles as well as links to their full-text versions. The abbreviated meta-data is hyperlinked to an information page offering more extended meta-data for the selected article, accompanied by another hyperlink pointing to the full-text version of that article. The user can download a given article by selecting the hyperlink pointing to its full text. A new browser window will open and the PDF file of the article (see Figure 2, right) will be downloaded and displayed.
Figure 2: The Los Alamos National Laboratory SciSearch database web page (left) and PDF file displayed (right) after user retrieval request on results returned for "implicit learning query. All retrieval requests are recorded in the LANL RL server logs. One set of logs recorded in 1998 for retrieval requests in the LANL SciSearch database was selected for further analysis. These web logs had registered 31,992 retrieval requests for 17,896 unique documents published in a total of 472 unique journals, issued by 1,842 unique users. Although an article network could, in principle, be generated, we chose to restrict our analysis to the journal in which a retrieved article was published for a set of initial test runs. Since every article in the SciSearch database is published in a journal, the generation of a journal network did not differ from the generation of a possible article network. A network of 472 journals from which articles had been retrieved in the LANL RL SciSearch database was generated and analyzed according to the measures described above. Table 3 lists the 10 journals corresponding to the highest JCF values in the generated network.
Table 3: List of 10 most frequent journals in
This ranking of journals indeed differs strongly from a ranking achieved by the IF and, in addition, corresponds strongly to the general mission and research interests of the LANL RL user community, e.g., "PHYS REV L", "J BIOL CHEM", etc. It informs the LANL RL management which journals can be considered of highest impact to its user community and which, in spite of high IF values, are not of high local impact. The striking difference between JCF and IF values for the set of 472 journals is revealed when a Spearman rank order correlation (see Appendix 1) is calculated. Although the correlation coefficient indicates a statistically significant correlation between JCF and IF values, its low value indicates this relationship is weak. It points to the fact that IF values can only be used with caution to assess journal impact for a specific DL user community. A cluster analysis was performed on the network generated from the LANL RL 1998 server log. Several clusters were generated and only those containing 6 or more journals were taken into account. Each cluster was denoted by an intuitive description of the research domain associated with the set of journals it contained. A set of 7 selected clusters is shown in Table 4.
Table 4: Hierarchical cluster analysis on journal title
associations
The clusters reveal how the interests and preferences of the LANL DL user community can be grouped according to domains that do not always correspond with institutional boundaries and divisions, e.g., "environmental sciences" and "metallurgy". They can inform DL management on acquisition decisions, more efficient organization of DL interfaces, and the general distribution of resources. Development of analysis softwareThe presented analysis is not overly complicated yet requires considerable logistical efforts in terms of gathering sufficient DL server logs, performing the mentioned JCF ranking, generating a cluster analysis, generating network graphs for visual inspection of the data, etc.
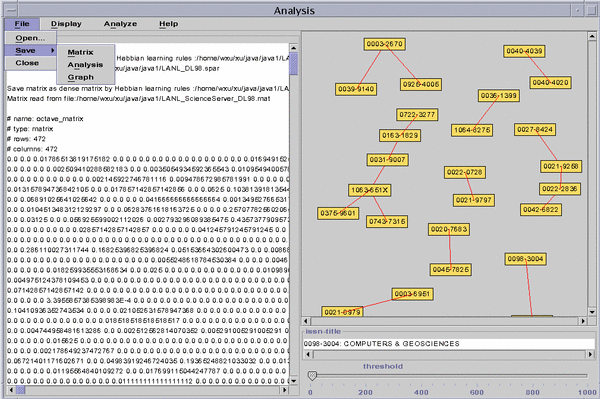
The DL team at Old Dominion University's Computer Science department has developed an application that will allow DL management to easily open DL server logs and conveniently perform analyses within a well-designed GUI. The first prototype of the system that automatically performs the described analyses has recently been tested. A screenshot from the prototype is shown in Figure 3. At present, the application allows users to open any server log file, choose among three pre-defined Hebbian reinforcement functions, and generate either document or journal relationship matrices that can be saved in sparse or dense matrix formats. All formats are designed to be compatible with open-source data analysis software such as Octave (Matlab compatible) and R. The application currently generates journal and article JCF rankings and adaptive graph representations of the generated journal networks, and it will shortly be expanded by libraries for hierarchical and k-means cluster analysis. Other methods appropriate for the analysis of document and journal relationships are also being considered for inclusion. This tool provides DL management with the means to analyze both the impact of their DL collections in terms of the needs and preferences of their local DL user community, and analyze the composition and characteristics of this community. We expect a final version to become available as an open-source tool within the next year. ConclusionIn this article, we have outlined a methodology for the generation of networks of document links from user retrieval patterns recorded in DL server logs. The generated networks can be analyzed to assess document and collection impact, and analyze the properties of a specific DL user community. A Java tool was written to transparently and efficiently perform the required analysis. In addition to the production of document rankings and the analysis of the characteristics of a DL user community, we feel the presented methodology introduces a number of possibilities in the domain of DL collection organization and user community evaluation that may be of equal interest. First, the generated document networks can be applied to automated systems for general document linking in DLs. At present, we envision systems that could, independently from the availability of proprietary citation data, transparently link documents across formats, languages, and DL services while they are in use, gradually adapting document links to the changing preferences of a given user community. The advantages of this approach compared to other methods of document linking are numerous: Implicit Users implicitly express the strength of document relationships from their actual retrieval patterns; therefore, the approach is non-intrusive and less subject to biases commonly associated with questionnaires or other instruments used to record user preferences. Text and Language Independent Since document relationships are detected from user retrieval patterns, and not from document content, this methodology operates independently from text content, language or media formats. Any pair of documents retrieved by a given user within a certain period of time can be connected. Adaptive User preferences may change, and these changes in user preferences will be reflected in their retrieval patterns. Therefore, the generated document networks can be conveniently adapted to changes in retrieval patterns Second, given a previously generated document link structure, a class of novel recommendation systems can be implemented that does not require text-query matching for retrieval, but operates on network structure to generate document recommendations. We have explored the use of Spreading Activation recommendations [Crestani 2000, Anderson 1984, Woodruff 2000] on such networks. A number of prototypes have been developed for the Los Alamos National Laboratory Research Library and have been shown to be quite successful (see <http://biosis.lanl.gov:8077/jserv-bin/SpreadAct_SciS_loop) [3]. Further extensions of the existing prototypes to cover a more significant portion of the LANL RL collection are underway. AcknowledgmentsThe authors wish to thank Dr. Herbert Van de Sompel whose contributions to the ideas and principles outlined in this article were instrumental in the development of this research. This is particularly the case for his input concerning the generation of document relationships from user retrieval sequences recorded in DL server logs. Notes[1] Fallacy Post hoc, ergo propter hoc. (The translation is "After this, therefore because of this". It refers to a logical fallacy which consists of drawing the conclusion that something was caused by the thing that preceeded it.) [2] Number: To prevent privacy issues, all DL server logs we have used have been anonymized by replacing IP numbers and user names by unique, numerical user identifiers [3] <http://biosis.lanl.gov:8077/jserv-bin/SpreadAct_SciS_loop>. This service is presently maintained as a prototype. Expect delays and outages. BibliographyAnderson, J. (1984). Spread of Activation. Journal of Experimental Psychology: Learning, Memory and Cognition, 10, 791-798. Bollen, J. (2000). Group user models for personalized hyperlink recommendation. In Lecture Notes in Computer Science: International Conference on Adaptive Hypermedia and Adaptive Web-based Systems (AH2000) (39-50). Trento: Springer Verlag. Bollen, J. (2001). A cognitive model of adaptive web design and navigation. Vrije Universiteit Brussel, Brussels, Belgium. Bollen, J. Rocha, L.(2000). An adaptive systems approach to the implementation and evaluation of digital library recommendation systems. In Lecture Notes in Computer Science: Fourth European Conference on Research and Advanced Technology for Digital Libraries (ECDL2000). Lisbon: Springer Verlag. Crestani, F. Lee, P. (2000). Searching the web by constrained spreading activation. Information Processing and Management, 36(4), 585-605. Darmoni, S. J., Roussel, F., Benichou, J., Thirion, B. Pinhas., N. (2001). Reading factor as a credible alternative to impact factor: a preliminary study. Bulletin of The Medical Libraries Association, in press. Garfield, E. (1979). Citation indexing: Its theory and application in science, technology, and humanities. New York: John Wiley and Sons. Kaplan, N. R. Nelson, M. L. (2000). Determining the publication impact of a digital library. Journal of the American Society of Information Science, 51, 324-339. MacRoberts, M. H. MacRoberts, B. R. (1989). Problems of citation analysis: A critical review. Journal of the American Society for Information Science, 40(5), 342-349. Opthof, T. (1997). Sense and nonsense about the impact factor. Cardiovascular Research, 33, 1-7. Rosenblatt, F. (1962). Principles of neurodynamics; perceptrons and the theory of brain mechanisms. Washington: Spartan Books. Rumelhart, D. E. McClelland, J. (1986). Parallel distributed processing, vol. I. Cambridge: MIT press. Seglen, P. O. (1997). Why the impact factor of journals should not be used for evaluating research. British Medical Journal, 314-497. Woodruff, A., Gossweiler, R., Pitkow, J., Chi, E. H. Card, S. K. (2000). Enhancing a digital book with a reading recommender. In Proceedings of the CHI 2000 conference on Human Factors in Computing Systems, (153-160). The Hague, The Netherlands. Appendix 1: Journal Consultation Frequency vs. IF correlationA Spearman rank correlation coefficient was calculated between the JCF and IF values of the set of 472 journals. Spearman rank correlation values indicate the strength of relation between two variables whose values can be ranked (one is larger than the other), but have unequal intervals between subsequent values. Correlation coefficients vary in a range between -1 and 1. The latter values indicate a perfect relation between the two variables. Coefficients close to or equal to zero indicate the two variables are not related. In this case, the correlation coefficient between journal JCF and IF values was found to be 0.26, or rs=0.26. Considering the number of values compared this is a statistically significant correlation (p<0.05) but a low one. It indicates that JCF and IF are not strongly related, or in other words that journal impact derived from usage, in our data, does not strongly correspond to journal impact determined from citation counts. Appendix 2: Matlab and Octave references Octave
Matlab:
Copyright © Johan Bollen and Rick Luce | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/june2002-bollen
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||