| ||
D-Lib Magazine
|
|
|
John S. Erickson |
![]()
1. IntroductionThis article builds upon previous work in the areas of access control for digital information objects; models for cross-organizational authentication and access control; DOI-based applications and services; and ongoing efforts to establish interoperability mechanisms for digital rights management (DRM) technologies (e.g., eBooks). It also serves as a follow-up to my April 2001 D-Lib Magazine article, where I argued that the introduction of additional levels of abstraction (or logical descriptions) above the current generation of DRM technologies could facilitate various levels of interoperability and new service capabilities [ERICK01]. Here I advocate encapsulating data structures of heterogeneous information items as digital objects and providing them with a uniform service interface. I suggest adopting a generic information object services layer on top of existing, interoperable protocol stacks. I also argue that a uniform digital object services layer properly rests above existing layers for remote method invocation, including IIOP, XML-RPC or SOAP. Many of the components suggested within this article are not new. What I believe is new is the call for an identifiable information object services layer, the identification of an application layer above it, and the clear mapping of an acceptable cross-organizational authentication and access control model onto digital object services. 2. Aspects of "The Problem"2.1 Logical Bundling of ContentDuring the media production or publication lifecycle, it is often preferable to manage creative works as single entities. Such logical "bundling" allows related aspects of a work, including source material and ancillary information, to be uniformly accessed, maintained and augmented. From a commercial perspective, the conceptual bundling of works allows information creators and providers to disseminate content and manage rights from a single virtual source while maintaining appropriate control of their materials, even after their materials have been "deployed." Discussions of these issues have often been wrought with confusion -- sometimes the focus is on the abstract work, and at other times the focus may be specific manifestations. In all cases, it is preferable to think of manifestations as aspects of a base work, but this is difficult when there are no formal models that enable this to be done conveniently, and no technical infrastructure that would aid in applying such models.
The <indecs>TM data model provides a rigorous, abstract information model for creative works that can serve as a fundamental basis for data interoperability [INDECS00]. <indecs> defines interoperability as enabling information that originates in one context to be used in another in ways that are as highly automated as possible. The <indecs> framework is primarily concerned with metadata, which it sees as data of all kinds relating to creations, the parties who make and use them, and the transactions which support such use [Note1]. The limitations of current digital packaging mechanisms may introduce further confusion. For example, we sometimes think of a particular manifestation in general terms (e.g., "the PDF version of an article"), when in reality many content deployment systems create and deploy individually packaged/serialized copies of works -- meaning, there might very well be no single manifestation of that particular format. 2.2 Objects as ServicesIn the digital realm, the requirements of information discovery agents suggest that opaque materials, such as securely packaged content (e.g., eBooks), need to be modeled at higher levels of abstraction; these higher-level models may then supply the metadata required by indexing and search services. Furthermore, the ability of these services to access metadata in an automated, programmatic fashion will enable radically improved search performance and more powerful applications. For example, the search service Google uses references to pages in its algorithm for weighing search results [PAGE98]. Key to the operation of PageRank is its accumulation of data regarding links to any particular page. One can see that it would be straightforward for information objects to provide this metadata themselves, as a service, particularly when well-known models such as Google/PageRank are available [Note 2]. 2.3 Open Interoperable Data StructuresIn the long run, interoperability tends to benefit technologists as much as it does information providers and consumers. Interoperability preserves the opportunity for freedom in choosing and applying content formats. In particular, the ability of information consumers to independently contextualize content as they see fit should not be unduly constrained by implementers of technology. Preserving this capability is analogous to the ability and necessity of librarians and archivists to utilize library binding services to collate and preserve traditional print materials [Z39.78]. 2.4 Rendering, Extensibility and Policy EnforcementThe choice of specific mechanisms to use when disseminating content to end-users should be made at application level, informed by the context of presentation and discovered capabilities of the rendering platform, and not by the limitations of object services or below. To meet this requirement, information items must eventually provide natural, durable extensibility mechanisms. This means that neither providers nor users would ever need to worry about whether a "Rocket Edition" exists for a particular textual work, for example. In the long run, information providers will wish to reduce the risk and long-term cost of support resulting from being "locked in" to particular type-specific deployment schemes [Note3]. One practical and much-needed application of this capability would be the extension of digital materials for accessibility purposes. The seamless integration of alternative, access-facilitating delivery mechanisms such as digital talking books, with or without intervention of the content provider, would be a significant advancement in the modeling of information items [Z39.86]. Other related examples might include automated language translation services. In all, we cannot conceive of the entirety of applications that may be enabled by opening up the structure of information objects, and expressing/enforcing policies in appropriate and helpful, rather than harmful and impeding, ways. It must be emphasized that such applications are only possible by keeping a separation between policy enforcement and content-type rendering mechanisms. Each should be thought of as having its own separate tradeoffs and value propositions, which should be separately weighed based upon requirements. They can and should, however, share a common infrastructure; this is the model that I present in the balance of this article. Later, I will describe how policy expressions can be thought of as data streams within digital objects, not unlike content [PAYETT00]. 3. Applying the Digital Object Services FrameworkThe digital object approach (Kahn/Wilensky) is a convenient way to organize our thinking about information items [KAHN95]. In this section I'll provide a brief overview of the Kahn/Wilensky model, consider some of the general advantages of that approach, and then specifically address how we can apply one implementation of this model, the Repository Access Protocol, as an infrastructure service layer. 3.1 Overview of the Digital Object ModelKahn/Wilensky defines the components of an open system for storage, access, dissemination, and management of information in the form of digital objects. This overview has been adapted from a concise summary provided by Carl Lagoze et.al. in [LAGOZE95]:
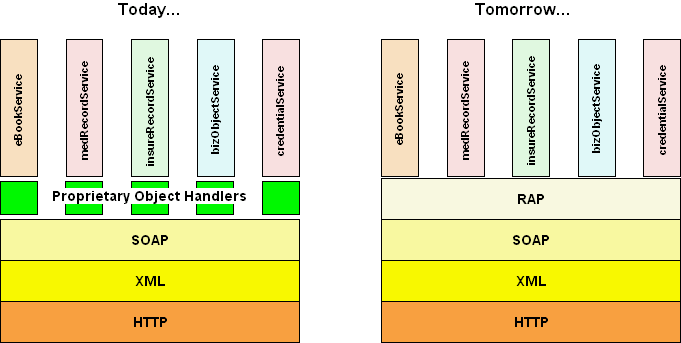
Finally, Kahn/Wilensky sketches a Repository Access Protocol (RAP) that provides services for depositing and accessing digital objects. An implementation of RAP is discussed later, as an approach to binding policies to object services. 3.2 Advantages of Encapsulation and AbstractionA characteristic of hierarchical information systems is that lower-level data models bear little resemblance to the abstractions that we construct for applications above them. From disk drives to communication protocols, each layer or shell that we introduce provides a mapping between some higher, applications-oriented view and its lower-level implementation. When these abstractions have done their jobs and properly encapsulate the underlying implementations, we don't care what lies underneath; the abstraction provides a sufficient interface, and makes the job of application development easier. This is fundamental to the principles of data interoperability [MELNIK01]. Similarly, the publishing business has historically dealt with information items as abstract entities and, indeed, has found this convenient and preferable for most forms of commerce, including the majority of rights management transactions. Unfortunately, we technologists have not yet been able to produce a pervasive information model that maps into these abstractions, and encapsulates various lower-level structures and protocols in serviceable ways. Sometimes there may be uniformity in the ways we think of and interact with information items. At other times we search for shortcuts, for business or other purposes, and introduce application-specific interaction models. But underlying these "layers" it is possible to identify a common view of information objects. Later I'll argue that several other application domains can also share this common view of the information object. To empower information objects to provide useful services for themselves, we must introduce at least two additional layers of abstraction (above a generic service transport layer such as SOAP, XML-RPC or IIOP) that will serve to organize and unify our information models and provide natural opportunities for interoperability. We can think of the first of these layers as a generalized, pervasive information object services layer, logically equivalent to the Kahn/Wilensky repository interface, and the second as an applications services layer, consisting of any number of interfaces that encapsulate the information object services below them to provide a variety of domain-specific services. 3.3 Defining an Object Services LayerRecognizing the need to establish digital object services as an infrastructural layer is critical. For the purposes of this discussion, I will adopt the interoperable repository model developed by CNRI and the Digital Library research group at Cornell, codified as the Repository Access Protocol (RAP) [RAPIDL]. RAP is a robust interface that provides distributed access and management of digital objects and repositories. Specifically, RAP provides a set of mechanisms to create, delete and edit digital objects as well as to operate on their properties, data and behaviors. Because RAP specifies a consistent way to access and maintain digital objects regardless of their application, we introduce it as a unique layer and propose it as a key defining element of the digital object infrastructure [PAYETT99]. RAP can be broken into four main parts or classes, corresponding to the major components of the Kahn/Wilensky model: the Repository, the Digital Object, the Disseminator and the Datastream. The repository class provides the functionality to create, delete and administer the digital object contained within a particular system. Clients wishing to interact with a specific digital object must first locate the repository that contains that object (by way of an object naming infrastructure such as the Handle System® [HANDLE], perhaps in the form of a Digital Object Identifier (DOI®) [DOI]), and then initiate a RAP "connection" with that repository. Once connected, the client then requests the digital object from the repository. As with all protocols, the value that RAP provides will derive from our ability to construct multiple, unique application spaces on top of it. These spaces will share the information object model defined by RAP, but will accomplish very different things. Thus, a variety of digital object-based services may be constructed based upon a consistent repository model, creating the benefits of market scale similar to those enjoyed due to the proliferation of web hosting platforms. 3.4 RAP Meets the Web Services StackBriefly, a web service may be defined as a set of network endpoints operating on messages containing either document-oriented or procedure-oriented information. In web service descriptions, operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint. Related concrete endpoints may be combined into abstract endpoints (or services) [WSDL01]. In this article I am proposing to combine digital object services, as defined by RAP, with this notion of web services. An important result of the CNRI/Cornell Experiments was the establishment of progressive levels of interoperability above the transport layer (in their case, IIOP [CORBA01]). Viewed from the perspective of the interoperability stack that has enabled the recent influx of web services, we see a number of potential adoption and interoperability barriers due to the RAP implementation model. This leads us to propose a transformation: http, xml, SOAP, RAP, and InfoObjectServices.
|
|
|
|
For this discussion, InfoObjectServices represents the family of services that populates the applications layer above the digital object services provided by RAP. Examples of domain-specific, service-oriented applications in this layer might include: eBookService, medRecordService, insureRecordService, bizObjectService, credentialService, etc. Each of these would be defined by an interface that captures common activities and transactions within its domain, while encapsulating a more complex implementation based upon the common digital object services below it. 3.5 Comments on InteroperabilityIn this discussion, I have taken for granted the ability of RAP to provide a basis for widespread interoperability and the digital object level. Previous results, such as the Cornell/CNRI work, demonstrate that this assumption has merit, within certain limits. But how well might RAP satisfy more generalized interoperability requirements? Upon scrutiny, we see that it inherently provides information components the ability to discover the interfaces of other components and to engage with those components using a uniform interface, two principles of extensibility that have been proposed [PAEPCK98]. 4. Transforming Digital Rights Management4.1 The Power of Open Data StructuresIn an idealized, perhaps even over-simplified model, we see information objects as singularly identified, heterogeneous logical bundles of metadata and content. "Metadata" and "content" are merely data streams that are defined by the semantics of their application; "content" will usually consist of those data streams of primary information value, while "metadata" are those data streams that support services such as discovery, retrieval, rendering and management of the content streams. Metadata may itself be logically described, supplied by multiple sources and consisting of data streams in multiple formats (and structure). Note that a mature and valuable information object is likely to provide a rich selection of multi-sourced metadata. Examples for book-like objects that are often given include Dublin Core (DC), MARC, etc., but other types that might be of value would include reviews, vendor listings, rights and recordation, etc. There is also the possibility of associating rich "process" and "business" metadata with the digital object, including rights management information obtained during the early stages of producing and licensing the work. As we'll see later, we can tightly control access to all of this, since they are all "in" (or at least referenced from) the object, and we can associate policies with each behavioral aspect. An ideal content structure might consist of a single data stream expressed in some base markup format, possibly expressed in a dialect of XML; the digital object would accommodate requests for other content-types by referencing a variety of disseminators with appropriate transformational capabilities. Thus a wide selection of content-type requests would be fulfilled by the object's rich, extensible set of disseminators, for a variety of purposes. Clients for disseminations would not just be end-users; they might be intermediaries as well, re-packaging content (virtually or otherwise). It is important to emphasize that the value of applying the digital object model is that it creates a common platform for producing and managing creative works. So, for example, an eBook object would not simply facilitate dissemination of content to end-users; it would carry through the entire cycle. Indeed, the "eBook object" might simply be a sub-type of an object that encapsulates the greater work (include other manifestations, including paper, translations, etc.). 4.2 A Whole-Object Approach to Policy EnforcementThe fine-grained function or behavior of an object's content-type disseminators must be dependent upon policies. We must be able to bind a particular policy or set of policies, to the methods used to access individual information nodes within the object; in particular, this means binding policies to method calls for content-type disseminators. Fundamentally, whether we're talking about viewing content or executing a remote method, these policies implement access control at various levels of granularity. Given all of the interested parties that must at one point or another obtain access to the services of an information object (for "content" or "metadata"), it is obviously impossible to centrally manage access control policies and the credentials that would be bound to them. There is therefore a critical need for an authentication model that provides multiple levels of indirection, allowing trust relationships to be established in a pair-wise, peer-oriented fashion. Clifford Lynch gives a compelling and seminal argument for this in a 1998 white paper [LYNCH98]. In this article, I have adopted the "safe dealing" approach for cross-organizational authentication and access control, as presented by Henry Gladney [GLADNY01]. We can see how a uniform credentialing approach and shared access control framework may be applied across heterogeneous e-publishing technologies. And as we'll see below, this does not mean that identical access control policies need be applied to all manifestations of content, or to other content-type data streams within the object (like metadata). Rather, the digital object approach allows us to bind arbitrary policies to individual elements of structure within the information object. But more than structure, it gives us the ability to map policies in a fine-grained way to services. This is truly exciting, but is only made possible through the kinds of services provided by a pervasive information object infrastructure. 4.3 Policy-Aware Content DisseminationThe implementation of content-type disseminators is an issue of practical concern. In order to write code, developers, at the very least, must have access to format specifications or, even better, access to code libraries that expedite the construction of type-specific disseminators. A preferred solution would be for content-type disseminator development to follow the open-source approach, which would not only ease the development of disseminator types, but would increase the likelihood of cross-platform implementations as well. The inherent extensibility of the repository model suggests other possibilities for making disseminators available. For example, format transcoding services could be made readily available as networked "components," accessible as an alternative content-type by reference within the object. Alternatively, the current "Servlet" model of transferring compiled code (to other repositories) could be extended to accommodate platform-specific code. Note that while Servlet interoperability is a fundamental notion, it is of primary concern at the repository level. It is possible for us to conduct useful experiments to test the dissemination of multiple content-types, even before we have the ability to transcode into different content-types from a single object source. For example, self-publishing tools may be used to create content data streams of a variety of different types. These would be deposited in a repository and included in the object structure. The principle of content type equivalence [FEDORA98] means that an object should disseminate precisely the same data stream; the difference between these approaches would be in the administrative work required to create a collection of individual disseminations (of different content types). The preferred approach would be to systematically specify disseminators by reference. The preceding discussion has focused on the construction of disseminators. But where exactly does rights management come in? The point is that the objects that are providing authorization decisions are themselves being made available through the object services layer, and are fed by policy expressions that are data streams, similar to the content or metadata considered before. This gives us extreme flexibility (because we can arbitrarily associate these policy-enforcers to content disseminators), but only if we keep rendering and policy enforcement separate and orthogonal. 5. Fine-Grained, Cross-Organizational Rights Management for ObjectsMuch of the lack of progress in rights management may be attributed to a general lack of data interoperability models for information items and rights management data structures. Early attempts at encapsulating content with object technologies for the purposes of rights management were only partially successful, primarily due to the lack of sufficient interoperability layers [ERICK97]. The opportunity at hand, as reflected in this article, is to build upon the emerging stack of interoperable protocols and data models and create an even more powerful information object services model that inherently accommodates a variety of policy enforcement mechanisms. Previous sections have stressed many of the theoretical and practical advantages of representing information items as digital objects. Throughout this discussion, I have suggested or implied that the object approach contributes a powerful capability to apply fine-grained control over object behaviors, for many aspects of an object. This section now focuses on key factors that contribute to a robust, pervasive policy enforcement approach that works for object administration as well as content-type dissemination. 5.1 Policy Expression and Object ServicesOne aspect of the previously missing infrastructure was an object serialization, or structured storage, model that could be readily adopted across applications and platforms. We now have that model with the emergence of XML [XML]. In general, an advantage that data models with explicit structure have is that they naturally accommodate mechanisms for binding policy expressions to structural sub-trees within the information object hierarchies they represent [DAMIAN00], [KUDO00]. My focus here is on fine-grained policy expression and enforcement. Or, perhaps more accurately, policy expression at an appropriate level of granularity, since it is clear that not all object behaviors may require uniquely expressed policies. Generally, policy expression concerns the creation of tuples relating subjects, objects and actions, where in this context a "subject" can be (loosely) thought of as a requestor for a service, an "object" as a specific service (or behavior) of an information object, and an "action" as some permissible action [Note 4].
Later in this section I will address the implementation of policy-interpreting objects -- for example, whether policies should be interpreted by separate objects or somehow as part of a primary content disseminator. 5.2 "Safe Dealing" and Cross-Organizational AuthenticationCross-organizational authentication and access control, when done properly, decentralize trust administration as much as possible. Authorities, and individuals within the scope of those authorities, will only be required to deal with what they need to deal [LYNCH98]. In his safe dealing model, Gladney provides us with an authentication and access control model that appears to meet these requirements, and therefore his model serves as the authentication substrate for the remainder of this article [GLADNY01].
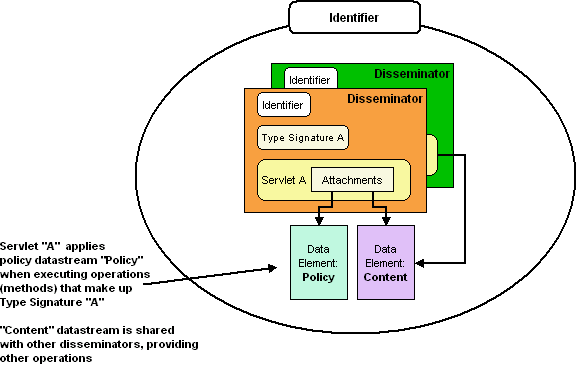
|
|
|
|
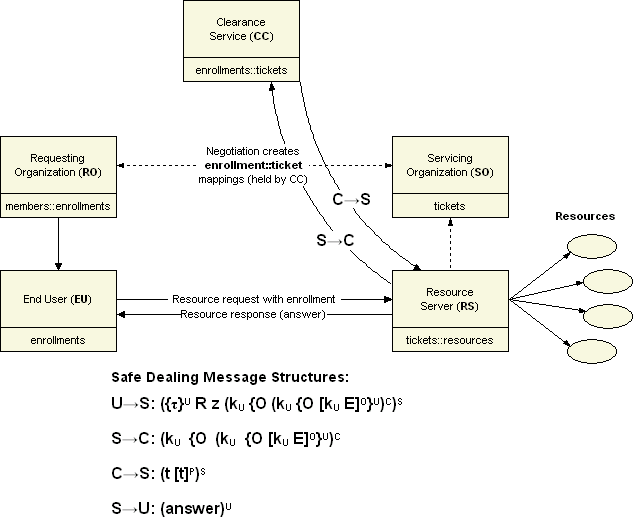
The safe dealing model is easily explained using the example of institutional access to online resources:
It is beyond the scope of this article to discuss the safe dealing model in more detail than this. I encourage the reader to read the Gladney papers (see the References section of this article) for further details on the protocol and, in particular, his recommended application of public-key encryption technologies to its implementation. The important contribution of the safe dealing model is it that it provides one way to establish trust relationships between pairs of entities, as appropriate, without propagating extraneous details that might lead to privacy and/or liability issues. The resulting web of relationships ends up being managed at peer level, resulting in a naturally scalable trust infrastructure. The safe dealing model, coupled with a flexible means of expressing policies for web service requests, provides a powerful and uniform way to manage digital objects within the repository as well as in the dissemination of content, which is usually our focus. In order to remain consistent with the end-to-end argument [ENDEND84], our model must apply policy enforcement at appropriate levels. The next section discusses how policy enforcement at the object and applications services layers are naturally kept separate. 5.3 Safe Dealing and Digital Object ServicesSafe dealing accommodates the transfer of credentials, but not the actual policies that have been expressed in terms of the credential (in the case of safe dealing, tickets). The technique for managing the mapping between credentials and policies would likely vary between RAP hosts, but must semantically be the same if they expect to honor the same "policies." From an implementation standpoint, the object service provider typically would treat enforcement as a filter-like function, whereby the service's remote service call gateway (e.g., a SOAP gateway) would need to decide whether to pass through a request, based upon the rule that applies for the subject:object:action tuple (where subject is the uniquely-identified credential, in this case the ticket; object is the specific RAP method request or part of the request; and action is one of a number of enumerated outcomes [DAMIAN01]. When considering how to map policies to object services, recall that RAP defines the primary interface to the digital object. Thus all policies, whether they apply to primary RAP components or content-types must be in terms of the digital object. Recall the three primary classes defined by RAP (Digital Object, Disseminator and Datastream). Every instance of the digital object, datastream and disseminator classes has associated with it a set of RAP methods. Each method may be the object of one or more policies, associating actions (like "accept") with credentials. Finally, every object may encapsulate multiple content-types. Each is defined by a set of methods; each method may be the object of one or more policies. From a practical standpoint, the most important requirement is that these policy expressions be done explicitly (rather than being hard-coded). Mechanisms for mapping policies to methods might include: (1) expressing policies in declarative structures that are referenced by the method; when needed they are retrieved and evaluated by the disseminator; or (2) policy objects are referenced by the method and asked to evaluate. Note that the policy in (1) would most likely be implemented as a data stream and sourced by a unique object anyway; the difference is that, instead of evaluating the policy and returning the result to the calling method, the object would supply the full policy declaration that would be the basis for an evaluation by another object. Thus each disseminator-level method call (e.g., "GetPDFPage(45)") would minimally have a policy data structure associated with it, and maximally would reference a policy object that would supply a result. In the case of the former, its structure would have to be content-type specific, and its association with the information object could be either explicit or implicit; in the case of the latter, it is just another data stream within the structure of the object. An unresolved question is how best to "position" the policy data stream in the object hierarchy -- indeed, whether it may be preferable to include policies by reference, since we assume them to be uniquely identified. In one view, we might like to manage all of the policies for an object, as a separate information object with its own services. In another view, there might be value in including them directly. The question may be resolved by invoking content-type equivalence.
6. The Policies, and Thus the Power Are with the ObjectWe are now in an era when an onslaught of networked applications and services is being created; these applications connect various aspects of our professional and personal activities with distributed services, personal or commercial. The development and propagation of these new applications have accelerated as technologists have identified and encapsulated commonalities between these applications, and have "bottled" them in open and accessible ways. Important examples include communications protocols, mechanisms for structuring and expressing data, and (more recently) mechanisms for advertising and requesting network services. Even today, applications are required to create, interact with and share information items. These items usually look like mail, or streams of multimedia entertainment, or complex business documents, or collaborative workspaces. Increasingly, our everyday activities are being characterized by heterogeneous, connected combinations of these information items. Universally, object-based approaches are employed to deal with information inside these applications, and increasingly, the individual application spaces are standardizing the structure and behavior of information objects within their spaces [EBXML01]. There is, however, little shared work between application spaces, even though these spaces are invariably headed towards convergence. A common characteristic of the next generation of connected applications will be a ubiquitous ability to share information items as first-class objects. The migration to this state will be fueled by applications that have been built on top of a pervasive information object services layer, probably similar to what I have suggested in this article. An attribute of the objects that provide their services in this layer will be their inherent extensibility, which will radically transform the creation and use of information, as well as the tools for working with it and the platforms on which it is created and experienced. The capability that will power this transformation, and thus the adoption of the new infrastructural layer, will be the introduction of information objects (as defined by this layer) that have the ability to carry with them fine-grained policies concerning the services they offer. The importance of this transcends what we have called access control or rights management; it touches on how objects can assist applications in dealing with them intelligently in a variety of dimensions, rendering quality and format to bandwidth, to language, and to access control. The adoption of new infrastructural layers has a transformational effect on how the layers below them are provided, both technically and economically. In the case of a pervasive infrastructure of digital object services, we could imagine a "web" of cheap, powerful repositories, all servicing collections of diverse information objects in a common, highly interoperable way. Not only can we imagine categories of repositories servicing domains such as "publishing," "library," "medicine," "sports," etc., we can also see these repositories servicing each other, as the need arises. Digital objects rock! 7. AcknowledgmentsSpecial thanks go to Bob Kahn, Larry Lannom, Christophe Blanche and Jason Petrone at CNRI, with whom I had many formative conversations while preparing this article. Thanks also to Peter Rodgers, Dave Reynolds, Poorvi Vora, Matthew Williamson, Russell Perry and Royston Sellman of HPLabs (PSSL); each has helped shape this thinking. And a special thanks to Mark Schlageter, web services developer supreme. I humbly take sole credit for any errors and omissions that the reader may uncover. Notes[Note1] <indecs> introduces a powerful, event-oriented ontology for expressing rights-related metadata. Some of that ontology might be useful for expressing policies, even for traditionally up-stream rights. [Note2] In this type of application trust might be an issue; currently an advantage of the way Google accumulates their metadata is that it is self-verifying. One way to establish a trusted, programmatic capability in the future would be for Google-like services to provide their own, trusted metadata disseminator components for repositories. [Note3] On the other hand, in the short term information providers might feel comfortable having fewer choices on how to deploy content.[Note4] Sometimes the "action" may be implicit, and thus the policy would instead specify a "sign" signifying the authorization state. References[CORBA01] OMG, "The Common Object Request Broker: Architecture and Specification (Version 2.4.2)," (Febuary 2001).See < http://www.omg.org/cgi-bin/doc?formal/01-02-33.pdf> [DAMIAN00] E. Damiani, et.al., "Securing XML Documents." In Proceedings of the 2000 International Conference on Extending Database Technology (EDBT2000), Konstanz, Germany (March 2000).
[DAMIAN01] Ernesto Damiani, et.al., "Fine Grained Access Control for SOAP E-Services, " In Proceedings of WWW10, Hong Kong (May 2001).
[DOI] The Digital Object Identifier.
[EBXML01] For example: ebXML Technical Architecture Team, "ebXML Technical Architecture Specification v1.0.4," (February 2001).
[ENDEND84] J.H. Saltzer, D.P.Reed, D.D.Clark, "End-To-End Arguments in System Design," ACM TOCS, Vol 2, Number 4 (November 1984). [ERICK97] John S. Erickson, "Enhanced Attribution for Networked Copyright Management." Doctor of Philosophy Thesis, Dartmouth College Thayer School of Engineering (June 1997).
[ERICK01] John S. Erickson, "Information Objects and Rights Management: A Mediation-based Approach to DRM Interoperability," D-Lib Magazine April 2001.
[FEDORA98] Sandra Payette and Carl Lagoze, Flexible and Extensible Digital Object and Repository Architecture, Second European Conference on Research and Advanced Technology for Digital Libraries, Heraklion, Crete, Greece, September 21-23, 1998 (Springer Lecture notes in computer science; Vol. 1513, 1998).
[GLADNY01] Henry M. Gladney and Arthur Cantu, Jr., "Safe Deals with Strangers: Authorization Management for Digital Libraries." To appear in Communications of the ACM (April 2001). Also, Henry M. Gladney, "Safe Deals between Strangers," IBM Research Report RJ 10155, (July 1999).
[INDECS00] Godfrey Rust and Mark Bide, "The <indecs> Metadata Framework: Principles, Model and Data Dictionary" (June 2000).
[HANDLE] The Handle System.
[KAHN95] Robert Kahn and Robert Wilensky, "A Framework for Distributed Digital Object Services," (1995).
[KUDO00] Michiharu Kudo and Satoshi Hada, "XML Access Control (Proposal)," Tokyo Research Laboratory, IBM Research (October 2000).
[LAGOZE95] Carl Lagoze et.al., "A Design for Inter-Operable Secure Object Stores (ISOS)." (1995).
[LYNCH98] Clifford Lynch, "A White Paper on Authentication and Access Management Issues in Cross-organizational Use of Networked Information Resources," Coalition for Networked Information, (1998).
[MELNIK01] Sergey Melnik et.al., "Generic Interoperability Framework (working paper)."
[PAEPCK98] A. Paepcke, et.al., "Interoperability for Digital Libraries Worldwide: Problems and Directions." Communications of the ACM, 41:4, pp. 33-43, 1998. [PAGE98] Lawrence Page, et.al., "The PageRank Citation Ranking: Bringing Order to the Web", (1998).
[PAYETT99] Sandra Payette et.al., "Interoperability for Digital Objects and Repositories: The Cornell/CNRI Experiments," D-Lib Magazine (May 1999).
[PAYETT00] Sandra Payette and Carl Lagoze, "Policy-Carrying, Policy-Enforcing Digital Objects," Fourth European Conference on Research and Advanced Technology for Digital Libraries, Portugal, (Springer, 2000).
[RAPIDL] Sandra Payette, Christophe Blanchi and Naomi Dushay, "Repository Access Protocol (RAP) IDL Version 1.3,"
[WSDL01] c.f. W3C, "Web Services Description Language (WSDL) 1.1," W3C Note (March 2001). [XML] W3C, "Extensible Markup Language (XML) 1.0 (Second Edition)," W3C Recommendation (October 2000). [Z39.78] c.f. ANSI/NISO/LBI Z39.78-2000 Library Binding
[Z39.86] NISO, "File Specifications for the Digital Talking Book, Version 3.8" Copyright 2001 John S. Erickson |
|
| |
|
|
Top | Contents |
|
|
|
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/june2001-erickson
|