 |
T A B L E O F C O N T E N T S
J U L Y / A U G U S T 2 0 1 4
Volume 20, Number 7/8
10.1045/july2014-contents
ISSN: 1082-9873
E D I T O R I A L
July/August Issue
Editorial by Laurence Lannom, Corporation for National Research Initiatives
A R T I C L E S
On Being a Hub: Some Details behind Providing Metadata for the Digital Public Library of America
Article by Lisa Gregory and Stephanie Williams, North Carolina Digital Heritage Center
Abstract: After years of planning, the Digital Public Library of America (DPLA) launched in 2013. Institutions from around the United States contribute to the DPLA through regional "service hubs," entities that aggregate digital collections metadata for harvest by the DPLA. The North Carolina Digital Heritage Center has been one of these service hubs since the end of 2013. This article describes the technological side of being a service hub for the DPLA, from choosing metadata requirements and reviewing software, to the workflow used each month when providing hundreds of metadata feeds for DPLA harvest. The authors hope it will be of interest to those pursuing metadata aggregation, whether for the DPLA or for other purposes.
The SIMP Tool: Facilitating Digital Library, Metadata, and Preservation Workflow at the University of Utah's J. Willard Marriott Library
Article by Anna Neatrour, Matt Brunsvik, Sean Buckner, Brian McBride and Jeremy Myntti, University of Utah J. Willard Marriott Library
Abstract: This article presents a case study of the Submission Information Metadata Packaging (SIMP) tool developed at the University of Utah's J. Willard Marriott Library. The Library designed this platform-independent tool to facilitate the deposit of descriptive metadata and derivative formats into CONTENTdm, the Library's current digital asset management system. It also supports the submission of technical metadata and archival content into the Ex Libris Rosetta digital preservation system. The Marriott Library deliberately developed the SIMP tool to accommodate multiple workflows and ingestion processes in a modular fashion, which allows the Library to easily modify the tool to extend its functionality to other digital asset management and preservation systems or enterprise repositories.
Managing Ambiguity In VIAF
Article by Thomas B. Hickey and Jenny A. Toves, Online Computer Library Center, Inc.
Abstract: The Virtual International Authority File (VIAF) is built from tens of millions of names represented in more than 130 million authority and bibliographic records expressed in multiple languages, scripts and formats. VIAF does not replace the source authority data, but creates something new built upon the relations mined from it. A common use of VIAF is in the creation of new 'local' authority records for authors based on information already in VIAF about the entity. VIAF can also be used as an authority file in its own right, for instance OCLC is now using VIAF as part of its identification of works and expressions. In a series of automated steps these names are linked and combined into VIAF clusters. Ambiguity occurs at several stages in VIAF, from the initial matching to cluster creation. VIAF's approach to managing this gives us a great deal of flexibility to deal with additions, deletions and changes to the underlying authority data. VIAF's approach to clustering has several rather novel aspects. The clustering itself proceeds in multiple stages in what could be called progressive refinement. It uses fairly loose matching to bring in candidates and then gradually brings them into the finished clusters using the information that can be gleaned from the rough groupings to make more informed decisions than could be made a priori. Another aspect is that all the information from all the records is used during the clustering. This results in a more fluid view of identity than hand-built authority files provide, while giving VIAF the ability to react to refinements in the clustering algorithms and new data on a regular basis. Finally, just the scale of VIAF provides opportunities the library community has not previously had to analyze and use authority data in machine processing. The problems and approaches used by VIAF may have implications in the use of linked data for other information services.
Degrees of Openness: Access Restrictions in Institutional Repositories
Article by Hélène Prost, Institute of Scientific and Technical Information (CNRS) and Joachim Schöpfel, Charles de Gaulle University Lille 3
Abstract: Institutional repositories, green road and backbone of the open access movement, contain a growing number of items that are metadata without full text, metadata with full text only for authorized users, and items that are under embargo or that are restricted to on-campus access. This paper provides a short overview of relevant literature and presents empirical results from a survey of 25 institutional repositories that contain more than 2 million items. The intention is to evaluate their degree of openness with specific attention to different categories of documents (journal articles, books and book chapters, conference communications, electronic theses and dissertations, reports, working papers) and thus to contribute to a better understanding of their features and dynamics. We address the underlying question of whether this lack of openness is temporary due to the transition from traditional scientific communication to open access infrastructures and services, or here to stay, as a basic feature of the new and complex cohabitation of institutional repositories and commercial publishing.
What Do Researchers Need? Feedback On Use of Online Primary Source Materials
Article by Jody L. DeRidder and Kathryn G. Matheny, University of Alabama Libraries
Abstract: Cultural heritage institutions are increasingly providing online access to primary source materials for researchers. While the intent is to enable round-the-clock access from any location, few studies have examined the extent to which current web delivery is meeting the needs of users. Careful use of limited resources requires intelligent assessment of researcher needs in comparison to the actual online presentation, including access, retrieval and usage options. In the hopes of impacting future delivery methods and access development, this article describes the results of a qualitative study of 11 humanities faculty researchers at the University of Alabama, who describe and rate the importance of various issues encountered when using 29 participant-selected online databases.
Realizing Lessons of the Last 20 Years: A Manifesto for Data Provisioning & Aggregation Services for the Digital Humanities (A Position Paper)
Article by Dominic Oldman, British Museum, London; Martin Doerr, FORTH-ICS, Crete; Gerald de Jong, Delving BV, Barry Norton, British Museum, London and Thomas Wikman, Swedish National Archives
Abstract: The CIDOC Conceptual Reference Model (CIDOC CRM), is a semantically rich ontology that delivers data harmonisation based on empirically analysed contextual relationships rather than relying on a traditional fixed field/value approach, overly generalised relationships or an artificial set of core metadata. It recognises that cultural data is a living growing resource and cannot be commoditised or squeezed into artificial pre-conceived boxes. Rather, it is diverse and variable containing perspectives that incorporate different institutional histories, disciplines and objectives. The CIDOC CRM retains these perspectives yet provides the opportunity for computational reasoning across large numbers of heterogeneous sources from different organisations, and creates an environment for engaging and thought-provoking exploration through its network of relationships. The core ontology supports the whole cultural heritage community including museums, libraries and archives and provides a growing set of specialist extensions. The increased use of aggregation services and the growing use of the CIDOC CRM has necessitated a new initiative to develop a data provisioning reference model targeted at solving fundamental infrastructure problems ignored by data integration initiatives to date. If data provisioning and aggregation are designed to support the reuse of data in research as well as general end user activities then any weaknesses in the model that aggregators implement will have profound effects on the future of data centred digital humanities work. While the CIDOC CRM solves the problem of quality and delivering semantically rich data integration, this achievement can still be undermined by a lack of properly managed processes and working relationships between data providers and aggregators. These relationships hold the key to sustainability and longevity because done properly they encourage the provider to align their systems, knowing that the effort will provide long lasting benefits and value. Equally, end user projects will be encouraged to cease perpetuating the patchwork of short-life digital resources that can never be aligned and which condemn the digital humanities to a pseudo and predominantly lower quality discipline.
Report on Libraries in the Digital Age (LIDA 2014)
Conference Report by Darko Lacović, University of Osijek, Croatia and Mate Juric, University of Zadar, Croatia
Abstract: Libraries in the Digital Age (LIDA) is a biennial international conference that focuses on the transformation of libraries and information services in the digital environment. It was held 16 - 20 June 2014 in Zadar (Croatia). The main theme of LIDA was "Assessing libraries and library users and use" which was realized through many presentations, workshops and posters. This report highlights the sessions which the authors attended, and which are related to their research interests.
N E W S & E V E N T S
In Brief: Short Items of Current Awareness
In the News: Recent Press Releases and Announcements
Clips & Pointers: Documents, Deadlines, Calls for Participation
Meetings, Conferences, Workshops: Calendar of Activities Associated with Digital Libraries Research and Technologies
|
|
F E A T U R E D D I G I T A L
C O L L E C T I O N
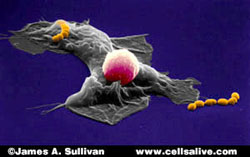
Human macrophage ingesting a strand of Streptococcus. Sitting atop the macrophage is a lymphocyte. Color enhanced scanning electron micrograph.
[Courtesy of CELLS alive!. Used with permission.]
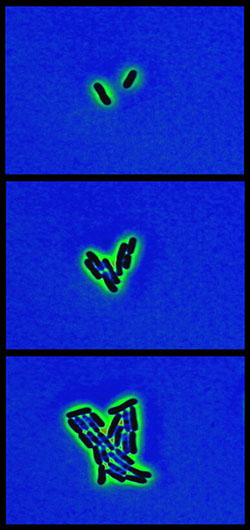
Sequence showing the growth of E. coli. Frames from computer enhanced phase contrast video.
[Courtesy of CELLS alive!. Used with permission.]
CELLS alive! is a web-based library containing a diverse collection of biological images, interactive animations and video microscopy of live cells. The mission of this site is to demonstrate basic concepts in cell biology, microbiology and immunology. CELLS alive! represents the author's 30 years of capturing film and computer-enhanced images of living cells for education and medical research. The site is purposely designed as an eclectic compilation of unique images, video and animated interactions to capture the reader's attention and imagination and to promote a desire to explore further. Also, this site includes study aids, puzzles and quizzes for classroom use to support retention of the presented material.
The content of CELLS alive! ranges from interactive animations of animal, plant and bacterial cells to pages dealing with how the innate and acquired immune systems protect us from infection. There are videos of live immune cells interacting with pathogens, bacteria being killed by antibiotics and heart cells beating. Other covered themes include comparative cell structure and function, the cell cycle, mitosis, meiosis and a comparison of the relative sizes of microscopic organisms. Included are time-lapse "CAMS" of dividing mammalian and bacterial cells and descriptions of varying microscopic techniques for capturing the included images.
D - L I B E D I T O R I A L S T A F F
Laurence Lannom, Editor-in-Chief
Allison Powell, Associate Editor
Catherine Rey, Managing Editor
Bonita Wilson, Contributing Editor
|