 |
D-Lib Magazine
July/August 2012
Volume 18, Number 7/8
Table of Contents
Specialized Research Datasets in the CiteSeerx Digital Library
Sumit Bhatia, Cornelia Caragea, Hung-Hsuan Chen, Jian Wu, Pucktada Treeratpituk, Zhaohui Wu, Madian Khabsa, Prasenjit Mitra and C. Lee Giles
The Pennsylvania State University
Point of contact for this article: Sumit Bhatia, sumit@cse.psu.edu
doi:10.1045/july2012-bhatia
Printer-friendly Version
Abstract
We provide an overview of some of the specialized datasets that were created for various projects related to the CiteSeerx digital library. These datasets are not those usually available from CiteSeerx and awareness of these datasets may further advance state-of-the-art research in academic digital library data management and analysis.
Keywords: CiteSeerX, Academic Digital Library, Datasets Documentation, Standardization
1. Introduction
The large volume of scientific literature being published today requires the development of new techniques for efficient management and analysis of the content of the literature. The techniques and methods developed should be scalable to meet the demands of managing even greater amounts of scientific content in the future. A major bottleneck in research in academic document mining and analysis is the unavailability of public datasets for use in evaluating and comparing proposed techniques with existing methods. In this paper, we provide an overview of seven different specialized datasets derived from CiteSeerx, a digital library and search engine with a focus on computer science publications. For some, generating datasets from the data provided with CiteSeerx is not easy, given the amount of data — more than 1.6 million documents at time of writing — and the computing resources required to process the data. These specialized CiteSeerx datasets can be made available for use by the research community, and it is hoped that making them available will help to move the state-of-the-art of academic data management and analysis forward.
2. Document-element Summarization Dataset
A document-element is defined as an entity, separate from the running text of the document, that
either augments or summarizes the information contained in the running text [2]. In academic documents, a number of document-elements are used for a variety of purposes like reporting and summarizing experimental results (plots, tables), describing a process (flow charts) or presenting an algorithm (pseudo-code). Given the importance of these document-elements, a number of document-element search engines have been proposed [3,4,10]. These search engines, however, only provide a thumbnail view of the document-elements and a small snippet describing the dataset that is usually the element's caption. Oftentimes, the captions do not provide sufficient details to understand the content of the document-element. In our previous research [1,2] we explored the problem of generating descriptive summaries of these document-elements that can help end-users to understand their content without having to read the entire paper. For testing the proposed algorithms, a dataset consisting of 290 document-elements (163 figures, 78 tables and 49 algorithms) from 152 different computer science publications was prepared. Full text of each paper in the dataset is available. Further, a gold set of summaries of each document-element created by two human evaluators is also available. This dataset can be used to further develop and evaluate the document-element summarization systems.
3. Citation Graph and Citation Recommendation Dataset
The citation recommendation dataset is compiled from the CiteSeerx citation graph and the metadata available for each paper indexed in CiteSeerx, as of December 2011. We define a citing paper as a paper for which we have access to its content and the reference list, and a citation as a paper that occurs in the reference list of at least one citing paper in the corpus, and for which we have access to its content, but may or may not have access to its reference list. In the CiteSeerx citation graph, there are 1,345,249 citing papers and 9,150,279 citations. The total number of links in the graph, i.e., [citing paper → citation], is 25,526,384. Figure 1 shows that the citations in the citegraph typically follow a Zipf distribution, i.e., only a few citations are cited by many citing papers, whereas the majority of them are cited rarely.
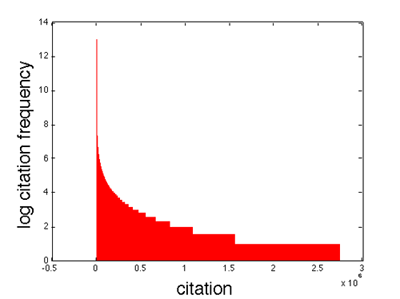
Figure 1: The citations in the CiteSeer citegraph follow a Zipf distribution, i.e., only a few citations are cited by many citing papers, whereas the majority of them are cited rarely.
|
Figure 2 shows the number of citations per citing paper, i.e., the size of the reference list. As shown in Figure 2, very few citing papers have a large number of citations. For most of the citing papers the number of citations ranges between 8 and 32.
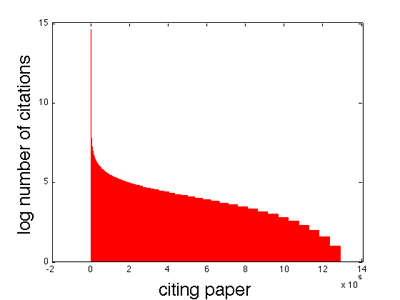
Figure 2: Number of citations per citing paper in the CiteSeer citegraph.
|
From the citegraph and the available metadata, a smaller dataset is constructed for the task of citation recommendation by filtering out papers that do not have title and abstract, have less than 5 or more than 200 citations, or cite less than 5 or more than 100 other papers. In the graph, there are 190,450 citations, 293,711 citing papers, and 2,839,455 links. This dataset can be used for a variety of academic literature analysis tasks such as citation recommendation [7], studying research trends and identifying influential papers and author.
4. Author Name Disambiguation
Automatically identifying the author of a given scientific publication is a crucial pre-processing step in many bibliometric analysis tasks such as finding influential authors, finding researcher homepages and studying the temporal research interests of a given researcher [11]. The data for the disambiguated authors in CiteSeerx is available within the standard CiteSeerx databases. The dataset contains more than 300,000 unique authors found in CiteSeerx digital library using the disambiguation algorithm proposed by Treeratpituk and Giles [11]. The dataset also provides the canonical name of each disambiguated author, his or her total number of papers and number of citations, homepage URL (if available), and the list of affiliations found to be associated with the author. Further, for each disambiguated author a unique key is provided that can be used to retrieve all the papers related to the author. In addition, the standard dataset used for evaluating the disambiguation algorithm by Treeratpituk and Giles [11] is also available. The dataset contains author records of 10 highly ambiguous names sampled from the CiteSeerx database. There are 525 records corresponding to 99 unique authors.
5. Open Access Book Project
The aims of the Open Access Book Search project are to provide search and navigation inside freely available online books, and to extract and index metadata, hierarchy structure, table of contents and citations present in these books. The dataset used in this project consists of 5,945 books that are freely available online along with their associated PDF documents. The associated metadata consists of extracted text from the PDF files, book titles, authors, date of publishing, ISBN, page number, language and country of publication. It can be used to develop and evaluate information extraction and metadata extraction techniques, and entity recognition algorithms for books or for documents with heterogeneous format and structure.
6. AckSeer — Academic Acknowledgment Dataset
AckSeer is a beta automatic acknowledgment indexing search engine that explores automatic identification of acknowledgments in academic documents [8,9]. The system also extracts acknowledged entities (researcher names, funding agencies etc.) from the acknowledgments and indexes them to enable search. Currently, AckSeer indexes acknowledgments from more than 500,000 papers in CiteSeerx. These acknowledgments contain more than 4 million acknowledged entities with approximately 2 million of them unique. Entity extraction is based on multiple state-of-the-art Named Entity Recognizers (NER). Acknowledged entities are ranked by citation.
Two datasets related to this project are publicly available. The first one includes manually tagged acknowledgments to measure the performance of the extractors. The second dataset contains the acknowledged entities as extracted by the named entity recognizers deployed in Ackseer. The latter can be used to study the distribution of acknowledged entities, and perhaps build a graph between the authors and the acknowledged entities.
7. Coauthor Network Dataset
CollabSeer is a search engine for discovering potential collaborators for a given author [5,6]. It discovers potential collaborators by analyzing the structure of a user's coauthor network and research interests. Currently, CollabSeer supports three different network structure analysis modules for collaborator search: Jaccard similarity, cosine similarity, and our relation strength similarity. Users can further refine the recommendation results by clicking on their topics of interest, which are generated by automatically extracting key phrases from previous publications.
CollabSeer uses the CiteSeerx dataset to build a coauthor network, which includes over 1,300,000 computer science related documents and more than 0.3 million unique authors. This co-author network database can be used for evaluating bibliometric tasks such as identifying potential collaborators and for studying problems related to academic social networks.
8. Focused Crawling for Academic Content
The CiteSeerx crawler crawls the web and collects documents to be indexed by CiteSeerx. A major challenge for the crawler is to differentiate between academic and non-academic content so as to keep the CiteSeerx repository clean. The dataset used for focused crawling consists of a URL whitelist that contains the seed URLs used for crawling. The list is continually being updated to remove any dead links, blacklisted URLs and URLs which do not provide ingestable documents (not all downloaded documents are ingestable). At present, there are more than 100,000 URLs in the whitelist used by the CiteSeerx crawler to crawl new academic content. In addition to the URL whitelist, the statistical information of the crawling history for hosts, domains and top level domains is also available, and a collection of researcher homepages accumulated from a crawl (mime-type text/html) of fifteen US universities is also available as a dataset.
The crawl database described above is an invaluable resource for focused web crawling research. The dataset can be used for developing and testing focused crawling techniques [12,13], academic webpage classification, and identifying researcher homepages. The URL for this project is http://louise.ist.psu.edu/, enabling users to view the crawl history, document ranking, and submit URLs to crawl.
9. Conclusion
Though CiteSeerx is a popular data source for academic document research in data mining, entity disambiguation, information extraction, etc., there are other interesting data sets that can be extracted and used. We have offered an overview of seven available data sets, and discussed their possible uses in academic document data analysis and management.
10. Acknowledgements
This work was partially supported by the National Science Foundation (NSF) and the Defense Threat Reduction Agency (DTRA).
11. References
[1] S. Bhatia, S. Lahiri, and P. Mitra. Generating synopses for document-element search. In CIKM '09: Proceeding of the 18th ACM conference on information and knowledge management, pages 2003—2006, New York, NY, USA, 2009, ACM.
[2] S. Bhatia and P. Mitra. Summarizing figures, tables, and algorithms in scientific publications to augment search results. ACM Trans. Inf. Syst., 30(1):3:1—3:24, March 2012.
[3] S. Bhatia, P. Mitra, and C. L. Giles. Finding algorithms in scientific articles. In WWW 2010, pages 1061—1062, 2010.
[4] S. Bhatia, S. Tuarob, P. Mitra, and C. L. Giles. An algorithm search engine for software developers. In Proceedings of the 3rd International Workshop on Search-Driven Development: Users, Infrastructure, Tools, and Evaluation, SUITE '11, pages 13—16, New York, NY, USA, 2011, ACM.
[5] H.-H. Chen, L. Gou, X. Zhang, and C. L. Giles. Capturing missing edges in social networks using vertex similarity. In Proceedings of the sixth international conference on knowledge capture, K-CAP '11, pages 195—196, New York, NY, USA, 2011, ACM.
[6] H.-H. Chen, L. Gou, X. Zhang, and C. L. Giles. Collabseer: a search engine for collaboration discovery. In Proceedings of the 11th annual international ACM/IEEE joint conference on digital libraries, JCDL '11, pages 231—240, New York, NY, USA, 2011, ACM.
[7] S. Kataria, P. Mitra, and S. Bhatia. Utilizing context in generative bayesian models for linked corpus. In M. Fox and D. Poole, editors, AAAI, AAAI Press, 2010.
[8] M. Khabsa, S. Koppman, and C. Giles. Towards building and analyzing a social network of acknowledgments in scientific and academic documents. Social Computing, Behavioral-Cultural Modeling and Prediction, pages 357—364, 2012.
[9] M. Khabsa, P. Treeratpituck, and C. Giles. Ackseer: A repository and search engine for automatically extracted acknowledgments from digital libraries. 2012, JCDL.
[10] Y. Liu, K. Bai, P. Mitra, and C. L. Giles. Tableseer: automatic table metadata extraction and searching in digital libraries. In JCDL, pages 91—100. ACM, 2007.
[11] P. Treeratpituk and C. L. Giles. Disambiguating authors in academic publications using random forests. In Proceedings of the 9th ACM/IEEE-CS joint conference on Digital libraries, JCDL '09, pages 39—48, New York, NY, USA, 2009. ACM.
[12] J. Wu, P. Teregowda, J. P. F. Ramírez, P. Mitra, and L. Giles. A study of the crawling strategy evolution for academic document search engines. ACM WebScience, 2012.
[13] S. Zheng, P. Dmitriev, and C. L. Giles. Graph-based seed selection for web-scale crawlers. In Proceedings of the 18th ACM conference on Information and knowledge management, CIKM '09, pages 1967—1970, New York, NY, USA, 2009, ACM.
About the Authors
[Note that biographical information for Jian Wu, Pucktada Treeratpituk, and Prasenjit Mitra was not available at time of publication.]
 |
Sumit Bhatia is a PhD candidate at the Pennsylvania State University. He is interested in research problems in the area of information retrieval. His current research focuses on problems related to search result diversification and search in social media such as online forums. He is associated with the CiteSeerX digital library and was responsible for developing the algorithm search functionality for CiteSeerx.
|
 |
Cornelia Caragea has been trained as a computer scientist with expertise in machine learning and data mining. The main focus of her research has been on the design of algorithms for learning accurate and compact predictive models from text data.
|
 |
Hung-Hsuan Chen is a Ph.D. candidate of Computer Science and Engineering department at the Pennsylvania State University. His research interests include social network analysis, digital library, and data mining. Much of his recent work has focused on uncovering the hidden relationship between any object pairs of a network. Before joining Penn State University, he was a research assistant at Academia Sinica.
|
 |
Zhaohui Wu is a Ph.D. student in Computer Science and Engineering Department of the Pennsylvania State University, working in The Intelligent Information Systems Research Laboratory. He received his M.S. and B.S. in computer science from Xi'an Jiaotong University. His main research interests include web search and mining, with emphasis on book and educational resources.
|
 |
Madian Khabsa is a PhD candidate in the department of Computer Science and Engineering at the Pennsylvania State University. Prior to that, he received his Masters Degree, also from Penn State. His research interests are in the areas of Information Retrieval, Information Extraction, and Social Network Analysis.
|
 |
C. Lee Giles is the David Reese Professor of Information Sciences and Technology at the Pennsylvania State University with appointments in Computer Science and Engineering and Supply Chain and Information Systems. His research interests are in intelligent cyberinfrastructure, search engines and information retrieval, digital libraries, web services, knowledge and information extraction, data mining, name matching and disambiguation, and social networks. He has published over 300 papers in these areas with an h-index of 62 according to Google Scholar. He was a cocreator of the popular search
engine, CiteSeer (now CiteSeerX) and is an ACM, IEEE and INNS Fellow.
|
|