 |
D-Lib Magazine
July/August 2012
Volume 18, Number 7/8
Table of Contents
Semantic Enrichment of Scientific Publications and Metadata
Citation Analysis Through Contextual and Cognitive Analysis
Marc Bertin and Iana Atanassova
Maison de la recherche, STIH-LaLIC Laboratory, Paris-Sorbonne University
{marc.bertin, iana.atanassova}@paris-sorbonne.fr
doi:10.1045/july2012-bertin
Printer-friendly Version
Abstract
The last several years have seen the emergence of digital libraries from which documents are harvested using the OAI-PMH protocol. Considering the volume of data provided by these repositories, we are interested in the exploitation of the full text content of scientific publications. Our aim is to bring new value to scientific publications by automatic extraction and semantic analysis. The identification of bibliographic references in texts makes it possible to localize specific text segments that carry linguistic markers in order to annotate a set of semantic categories related to citations. This work uses a categorization of surface linguistic markers organized in a linguistic ontology. The semantic annotations are used to enrich the document metadata and to provide new types of visualizations in an information retrieval context. We present the system architecture as well as some experimental results.
Keywords: Semantic Annotation, Text-Mining, Scientific Publication, Digital Library, OAI-PMH, Open Access, Citation Analysis
1. Introduction
Today scientists are faced with an increasing amount of scientific production. Access to information and scientific publications plays a major role in the scientific process. In this context, researchers are less and less satisfied by traditional keyword search algorithms that return a list of locations in documents corresponding to search criteria. Together with the recent studies around the metrics of science, new tools need to be developed for text mining that will allow a better exploitation of the content of scientific articles. Several key advances make this possible today: 1) a long tradition in the study of citations and citation networks, 2) the use of communication protocols for exchange of bibliographic metadata, 3) the existence of a large number of scientific journals in open access and 4) recent advances in Natural Language Processing (NLP). New tools offering an efficient exploitation of the full text content of scientific publications are possible that will facilitate the access to information and enrich the user experience. As new digital libraries and academic repositories are created, the number of scientific publications available in open access is growing rapidly [18]. The OpenDOAR web site, which is an authoritative directory of open access repositories, shows a constant increase in the number of academic repositories (Table 1). The impact of these resources was discussed in a conference of IFLA (see [29]). Web services for open access to scientific publications such as CiteSeerX and Archive, alongside publisher sites, have grown to be very popular among scientists.
| Date |
2006-9 |
2007-9 |
2008-9 |
2009-9 |
2010-9 |
2011-9 |
| Number |
663 |
779 |
1020 |
1200 |
1430 |
1730 |
Table 1: Growth of the OpenDOAR Database — Worldwide Institutional Repositories
Currently, about 10% of the publications are available in full text in PDF format (see [20]), however, this situation is changing. For example, an agreement has been signed between Online Computer Library Center (OCLC) and HathiTrust, enabling OCLC to provide new services using full-text indexing in WorldCat that make it possible to search bibliographic metadata and full text content of documents. In the French-speaking community two major projects, Hyper Articles en Ligne (HAL) and Thèses en Ligne (TEL), provide open access to scientific publications and PhD theses in French and in English. In April 2012, HAL provided full text access to 193,206 documents. On the same date, 28,173 theses were available for download by TEL with Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). This is also the case for a number of French repositories using the works of Centre pour la Communication Scientifique Directe (CCSD). Other examples are Érudit and Revues.org.
2. Related Work
While a citation is the basic unit of analysis for a great number of studies, some recent works try to link citations to keywords or semantic information. For example, [43] shows the interest of lexical analysis in the mapping of scientific fields. The maps of science are used to reflect graphically the structure, evolution and main actors of a given scientific field, namely with the work of Garechana et al. [16], Klavans et al. [19], Leydesdorff et al. [22] and Small [36,37]. If the studies of networks of co-citations remain of interest, some recent works propose a fine study of the relations between citations, articles and authors. For example, the analysis of co-words becomes more and more important. We can refer to the work of Muñoz-Leiva et al. [27], Liu et al. [23], Wang et al. [40], Zhang et al. [42] and Yang et al. [41]. However, the analysis of terms is carried out generally on the level of the metadata, i.e., the title or the abstract. The work of Garechana et al. [16] takes into account the relative positions of citations in documents in order to optimize the similarity algorithms. The three stages of their approach are the following: Classifying context-based co-citation into types depending on the surface structures; Assigning each context-based co-citation a numerical weight based on the type to which it belongs; and Calculating the degree of similarity between two co-cited documents by summing the weights. It is interesting to note that this approach does not take into account citation contexts, i.e., the text surrounding citations, and they conclude by affirming that: "The combination of the citation context analysis approach and the content analysis of citation contexts approach may be better than a single approach".
We consider that citation contexts are of key interest for the semantic analysis of citations. Other studies confirm the interest of linguistic analysis of bibliographic references [3,4,6,39] by the examination of linguistic markers and surface forms in order to produce finer categorizations. This phenomenon is studied in a number of other works. For example, in 1964 and later in 1977, Garfield [17] identified fifteen different reasons for citation, such as: paying homage to pioneers, giving credit for related work, identifying methodology, providing background reading, correcting a work, criticizing previous work, etc. In 1982, Small [35] made five such distinctions and proposed the following classification: Refuted, Noted Only, Reviewed, Applied, Supported. These categories can be considered respectively as: negative, perfunctory, compared, used and substantiated. The information expressed by citations in scientific literature is difficult to extract and categorize automatically because of the different motivations underlying the citation act. In 1975, Moravcsik and Murugesan [26] proposed an organization of citation functions with the purpose of explaining citation quality. In the same year their categories were modified by Chubin and Moitra [8]. In 2000, Nanba and Okumura [28] used cue words to extract relationships between papers for automatic generation of review articles. They try to automatically identify the types of citation relationships that indicate the reasons for citation. In 2006, Xerox [34] developed the concept-matching framework based on the co-occurrence of expressions, that allows the detection of sentences containing expressions having discourse functions in scientific argumentation. They use Xerox Incremental Parser (XIP), a natural language analysis tool designed for extracting dependency functions between pairs of words within sentences. At the same time, on the semantic level, Bertin and Desclés (see [3,6]) proposed a categorization of relationships between authors using a semantic map for the annotation of scientific articles, including categories such as method, result, comparison. Teufel et al. [39] introduced a citation annotation scheme based on empirical work in content citation analysis. She used twelve different categories to mark the relationship of a work to other works, each citation being labeled with exactly one category. The universal categories called "argumentative zones" used for the classification are: Explicit statement of weakness; Contrast or comparison with other work (4 categories); Agreement/usage/compatibility with other work (6 categories); and a neutral category.
The most important aspect of these works is the increased possibility for automated semantic analysis of sentences containing bibliographic references. In this paper, we propose a method for the exploitation of the full text content of scientific publications through the enrichment of bibliographic metadata harvested by the OAI protocol. To do this we use a method for automatic annotation and full text semantic analysis specifically designed for scientific publications processing. Our aim is to design tools that offer new functionalities for more efficient exploitation of scientific literature that correspond to specific user needs.
3. Proposed Approach
We are interested in semantic annotation of texts and we propose data structures that meet the constraints of some linguistic approaches in NLP, specifically the discourse semantic annotation. Our aim is the automatic annotation of discourse categories expressed in the context of bibliographic references. Our working hypothesis is that the author's motivation for a citation, if it is expressed in the text, is conveyed by linguistic markers present in the textual space close to the bibliographic reference, that we will call research scope. In our approach we assume that the research scope is the same sentence. This assumption has some intrinsic limitations. Firstly, the argumentation around a citation can evolve throughout the text and therefore overlap sentence boundaries. Secondly, segmentation into sentences is not sufficient to take into account multiple citations within the same sentence.
In spite of these two limitations, in the great majority of cases, the motivation for a citation is given in the same sentence and at this stage we will try to automatically annotate these cases. The other cases, where the semantic category of citation is not expressed in the same sentence, can be processed by complementary methods at a later stage, for example by using anaphora resolution. We have implemented a tool for the exploitation of full text scientific publications. After the metadata is harvested using the OAI protocol, it is stored in a NoSQL database. The full text document, generally in PDF format, is converted into text encoded in UTF-8. The text is then analyzed by Finite State Automata (FSA) that are specifically designed to identify bibliographic citations and link them to the references in the bibliography. The last stage is the semantic annotation of the text by using the bibliographic citations that have been identified and the presence of linguistic markers in the research scope. Each sentence containing a citation can be annotated by one or several semantic categories. This approach enables the development of various information visualization tools.
3.1 Reference Extraction Using FSA
The automatic identification of reference keys in texts may seem trivial at first glance. However, as shown by [6], the FSA must account for a large number of morphological variations. We have to take into consideration the norms established on the one hand by idiosyncratic practices proper to authors and on the other hand by the usage in different scientific domains. The method we use is proposed in [3,6]. The implementation takes into account a list of regular expressions that we have created in order to cover the different forms of reference keys present in texts. We have considered several norms for bibliographic references, namely the norms ISO-690 and ISO 690-2, which are the international standards from the International Organization for Standardization, as well as the French norms AFNOR NF Z 44-005 and AFNOR NF Z 44-005-2. In practice the norms are not rigorously applied by authors of scientific texts. For this reason, FSA based only on the norms described above would not be sufficient to carry out the text processing on a large scale. That is why in order to create robust FSA, different corrections had to be made to take into consideration the different customs in writing bibliographic reference keys. Figure 1 gives an example of an FSA that matches one specific type of reference keys.
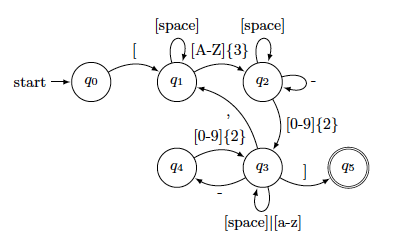 Figure 1: Example of FSA for matching alpha-numeric bibliographic reference keys
Figure 1: Example of FSA for matching alpha-numeric bibliographic reference keys
The identification of reference keys in scientific papers allows us to identify the text segments (sentences) that contain bibliographic citations. These segments will be taken into account in the semantic annotation stage.
3.2 Reference Linking
We want to establish the link between sentences containing citations (and therefore reference keys) in the text and the corresponding bibliographic references in the bibliography of the publication. This task is straightforward if the reference keys are in numerical or alphanumerical form (e.g. '[75]', '[BER08]') because in this case they are also present at the beginning of the corresponding reference in the bibliography. The difficulty arises when the bibliography style does not include the reference keys themselves and the keys present in the text are formed from the authors' names and the year using a specific syntax that may vary from one publication to another. This type of reference keys is more often used in human and social sciences. A classification of the different types of reference keys in scientific texts has been proposed by [4]. The algorithm is a simplified form of the complete algorithm. It works in a large number of cases with an accuracy of about 90%. For the complete algorithm some adjustments must be made in order to take into account complex bibliographies where the same author is cited several times in the same year, or the same list of authors, but in different order, appears in the bibliography more than once in the same year.

3.3 Semantic Enrichment
Citation analysis is often related to research evaluation. Bibliometrics is largely based on the analysis of bibliographic references in publications. Further development of 'qualitative' citation analysis through contextual and cognitive-relational analysis is necessary. In 2005 Moed writes [25,p. 310]:
"Quantitative analysis of science could develop more 'qualitative' citation based indicators, along a contextual or a cognitive-relational viewpoint, thus abandoning the principle underlying more citation analysis that "all citations are equal". Such indicators potentially have an enormous value, both in the sociology of science and in a research evaluation context, but are currently generally unavailable."
The analysis of the rhetorical function of citations in scientific texts is today a subject of interest. There exist several approaches to the automatic classification and annotation of scientific articles at different levels. They are often motivated by the necessity to improve present bibliometric indicators which in many cases are not efficient enough.
3.3.1 Citation Analysis and Linguistic Ontology
This study has led us to propose a linguistic ontology of bibliographic citations (Figure 2). The categories are organized in a hierarchical structure, from general to specific. The categories of this ontology (see [3]) are instantiated through surface linguistic markers that constitute the knowledge base used by the EXCOM semantic annotation engine. The method and engine of semantic annotation is described in Subsection 3.3.2.
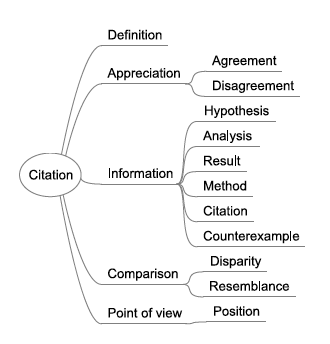 Figure 2: Linguistic ontology of bibliographic citations
Figure 2: Linguistic ontology of bibliographic citations
3.3.2 Semantic annotation
We use a knowledge-based Natural Language Processing approach to annotate the corpora. The linguistic units identified by the automata are used as indicators in the framework of the Contextual Exploration Method [13]. This is a decision-making procedure, presented in the form of a set of annotation rules and linguistic markers that trigger the application of the rules. The Contextual Exploration rules are applied to the segments containing indicators. After the initial identification of the indicators in the text, the rules carry out the localization of complementary linguistic clues which are co-present in the research scope of the indicators. After the verification of the presence or absence of the linguistic clues, the rules attribute a semantic annotation to the segment. By establishing a hierarchy between the indicators and complementary linguistic clues, the Contextual Exploration Method defines an inference process: the presence of an indicator of a semantic category in a given segment corresponds to the hypothesis that this segment belongs to the category. The application of the Contextual Exploration rules permits affirming or negating this hypothesis, or in some cases refining the category, and eventually annotating the segment. Both the indicators and the clues can be words or expressions, regular expressions, or the absence of an expression.
3.3.3 Annotation Engine
We use the semantic annotation engine EXCOM (Multilingual Contextual Exploration) [14] that is developed in Java and is available online. It takes as input the linguistic resources and a corpus of texts and carries out the segmentation and automatic annotation of the texts. The system uses the UTF-8 encoding which permits the processing of different languages. The output is in XML format compatible with the DocBook schema, where the annotations are given as attributes to the segment elements. This annotation engine has been used in other works, for example for definition extraction [5] and for the categorization of hypotheses in biological articles [12]. Our approach permits enriching the bibliographic metadata using the semantic information issued from the automatic annotation and citation analysis.
3.3.4 Annotation-driven Clustering
In order to provide relevant information retrieval results in a large scale corpus it is necessary to minimize the redundancy. In our case, we need to identify paraphrases or sets of sentences having the same semantic content. There exist different approaches in this field that introduce similarity measures between sentences and clustering algorithms. The analysis can be carried out on different levels: surface markers comparison using n-grams [30]; concept matching [9] based on ontology structure [15,31]; syntactic analysis and similarity measures between trees [32,33]; extractions based on multilingual paraphrase corpora [2,24].
In our approach, the semantic annotation is an element of the retrieved results and can be integrated in a clustering algorithm. Our hypothesis is that paraphrase sentences are annotated either by the same categories or by categories that are situated very close to each other in the structure of the ontology. We can therefore use new similarity measures that combine term vector similarity and annotation vector similarity. Let s1=(t1, a1) and s2=(t2, a2) be two annotated sentences where ti are binary term vectors and ai are binary vectors of semantic categories. We can then define the distance D(s1, s2) as the product of the Eucledean distances:
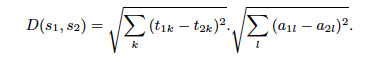
This distance accounts for the hierarchy and the relation between semantic categories in the ontology in the following manner: if a sentence is annotated by a child category, it is also implicitly annotated by all its parent categories. For example if s1 is annotated as 'result', s2 as 'method', and s3 as 'position', then D(s1, s2) < D(s1, s3) because s1 and s2 have a common annotation category which is 'information' (see Figure 2).
4. Implementation
The development of tools for the automatic processing of scientific publications on a large scale has become possible thanks to two advances. Firstly, OAI-PMH facilitates the exchange of bibliographic metadata. Secondly, different approaches have been developed for the text-mining of the scientific publications by using statistical methods based on machine learning techniques, or by using knowledge based methods relying on linguistic models. Our approach relies on a linguistic ontology that organizes surface markers used for the annotation.
In order to establish links between the metadata and the textual elements, the database must contain the metadata — the annotations that are the result of the text analysis — as well as the document itself. A text segment in a document can carry more than one semantic annotation. The structure of the table depends on the nature of the information and cannot be defined in advance. In fact, the types of data and the values that will come to enrich the document metadata are not necessarily known in advance and depend on the semantic annotation tools as well as on the level of analysis and the user. Historically, the development of different document representation structures has been conditioned by the idea that the text is an ordered hierarchy of content objects (OHCO). This term was first introduced by [11] in order to propose data exchange formats ensuring the portability, the data integrity and the possibility of multiple visualization at different levels of representation. XML trees are often used for full text document representation but they are less adapted to manage multiple relations and links between different objects.
4.1 Bibliographic Metadata
The OAI-PMH plays a major role in the development of digital libraries. It is invoked within HTTP and uses six different verbs that permit identifying the repository, listing the repository's metadata prefixes, listing the repository's sets, listing the records corresponding to a given period of time and a metadata prefix, listing the record identifiers and getting a record given a specific identifier. The document descriptions are provided in the XML format which can encapsulate various metadata schemas, among which are oai_dc, marcml, didl. The Library of Congress lists some of the schemas taken into account: Dublin Core Record Schema, MODS Schema, ONIX DTD, MARC 21 XML Schema, etc. The aim of Dublin Core (DC) is to provide a common trunk of descriptors and a structure which is sufficient to facilitate the exchange and search of resources across different communities and description formats proper to each discipline. DC defines 15 elements which are all optional and multivalued. The elements can be divided into three groups; for content description: Title, Subject, Description, Source, Language, Relation, Coverage; for intellectual property: Creator, Contributor, Publisher, Rights and for instantiation: Date, Type, Format, Identifier. Although they provide only a weak structure expressiveness, these 15 elements are considered to be part of the OAI-PMH [21]. DC offers conceptually an implementation and interoperability within the semantic web that uses the RDF format. According to the DC community, the metadata can be conceptualized in four levels of interoperability: L1—Shared term definitions, L2—Formal semantic interoperability, L3—Description Set syntactic interoperability, L4—Description Set Profile interoperability.
4.2 NoSQL Database
The NoSQL ('Not Only SQL') database model offers more flexibility than the relational database model. The differences between these two models are studied in [7,38]. We have chosen to use MongoDB, as document stores support more complex data than key-value stores. Compared to traditional RDBMS, in MongoDB, collections are analogous to tables, and documents to the records. This model permits querying collections of documents with loosely defined fields. In a relational database, each record in a table needs the same number of fields, while in a document oriented database documents in a collection can have different fields. So, a document oriented database stores, retrieves, and manages semi-structured data. Document databases use object notations such JSON [10] (Javascript Object Notation) which is a 'lightweight, text-based, language-independent data interchange format'. MongoDB uses BSON as a data storage and network transfer format which is the binary variant of JSON, a computer data interchange format. It was designed to be lightweight, traversable and efficient. Version 1.0 uses the standard BSON pseudo-BNF (Backus-Naur Form techniques for context-free grammars) syntax notation. BSON format offers the ability to embed various formats such as PDF, which represents a considerable advantage compared to the technical specifications of our requirements specification.
4.3 Server
The implementation of different servers is based on the virtualization of operating systems. The first virtual machine under Ubuntu Server runs Apache2, PHP, Perl, and MongoDB. The second virtual machine under Windows 7 runs a professional solution used for the conversion of PDF into text which is the input of the semantic processing tools. The web interface is developed using AJAX to provide dynamic functionalities, i.e., the ability to browse metadata and semantic annotations from the heart of documents. Various graphical information representations enhance the understanding of the source document.
5. Experimentation
The user interface proposes document descriptions that resemble bibliographic record references, but that contain, together with the traditional metadata fields, other information issued from the semantic annotation, which contribute to the construction of a better representation of the source document (see Figure 3). This approach also achieves a certain optimization of the services of the providers of scientific publications and remains compatible with existent business models on the web.
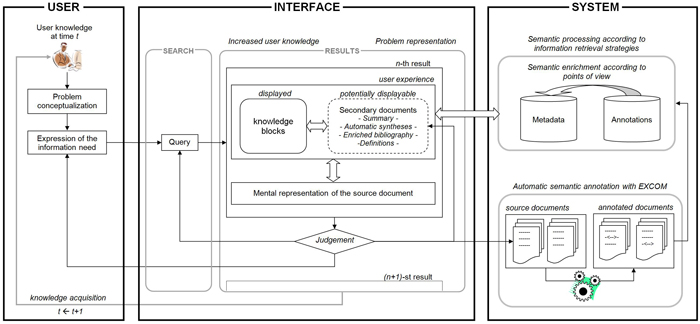 Figure 3: System-User Interaction and Data Processing (See larger version of Figure 3.)
Figure 3: System-User Interaction and Data Processing (See larger version of Figure 3.)
If the metadata harvested by the OAI protocol gives access to full text publications, the latter can the exploited in order to enrich the metadata. The automatic semantic analysis of the text can therefore provide new metadata descriptors that give information on some specific parts of the publication's content that are extracted and categorized through automatic semantic analysis. For example, our interface proposes semantically enriched bibliographies (see Figure 4), that list citations together with text extracts containing the corresponding reference key in the text.
 Figure 4: Semantically Enriched Bibliography
Figure 4: Semantically Enriched Bibliography
The system permits processing of articles and PhD theses and visualizing the annotations distribution. Figure 5 shows the distribution of bibliographic citations in Natural Language Processing PhD theses [4]. On the horizontal axis we have the values corresponding to the text segments, starting with the first sentence of the document and going to the end. On the vertical axis we have the different semantic categories.
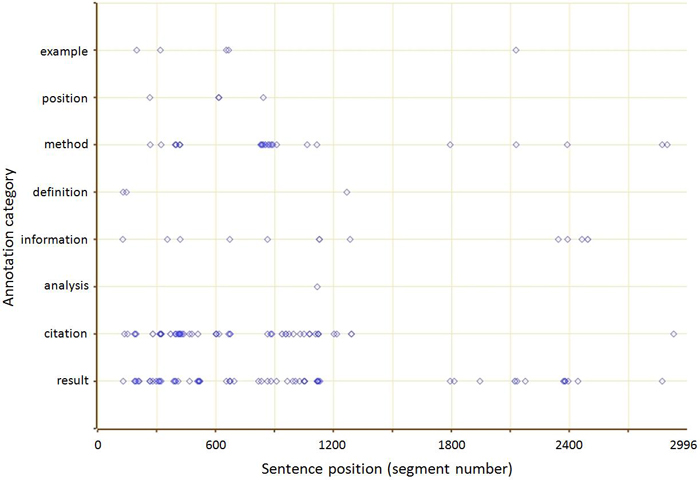 Figure 5: Distribution of annotations in a PhD thesis in NLP
Figure 5: Distribution of annotations in a PhD thesis in NLP
The purpose of this approach is to enable the development of new information retrieval applications providing rapid access to some specific types of information that are difficult to identify by a simple keyword search. [1] have proposed ranking algorithms for information retrieval on annotated corpora using the same semantic ontology. Their evaluation of the precision shows some promising results and underscores the interest in semantic annotation of information retrieval. The aim is to accelerate access to information and knowledge acquisition by categorized text syntheses generated dynamically according to the user's need.
6. Evaluation
Our evaluation consists of the observation of the performance of the annotated method on a corpus of documents. The 330 publications we considered are relatively long; each document contains an average of 1,000 sentences. Among the 359,354 sentences only about 8,000 contain bibliographic references, and of them 1,739 were annotated by the system. Table 2 presents some statistics resulting from the corpora that were processed. This shows that only a small number of the sentences in the documents are relevant.
| Documents |
Sentences |
Indicators |
Annotations |
| 330 |
359,354 |
7,913 |
1,738 |
Table 2: Evaluation of annotated corpora
Table 3 presents the distribution of the annotation categories. Twenty-two percent of the sentences that contain bibliographic references were categorized by the annotation. The 78% that remain uncategorized are sentences that do not contain any of the linguistic markers that allow annotation. This is the case when the author cites other work without explicitly expressing the motivations for the citation. This also means that the annotation permits identifying a small number of the citation sentences that carry specific semantic relations. This approach is used for the construction of an IR system that extracts highly relevant segments from large corpora.
| Automation category |
Percentage |
(number) |
| Point of view |
0.126% |
(10) |
| Comparison |
0.291% |
(23) |
| Definition |
0.986% |
(78) |
| Information |
20.321% |
(1,608) |
| Appreciation |
0.240% |
(19) |
| Uncategorized |
78.036% |
(6,175) |
| Total |
100% |
(7,913) |
Table 3: Distribution of the annotations
Table 4 shows the distribution of the annotations of the semantic category of "Information". We can see a majority of results and citations in the corpus.
| Annotated category "Information" |
Percentage |
(number) |
| Hypothesis |
0.311% |
(5) |
| Analysis |
1.679% |
(27) |
| Result |
31.219% |
(502) |
| Method |
3.980% |
(64) |
| Citation |
58.644% |
(943) |
| Information |
4.167% |
(67) |
| Total |
100% |
(1,608) |
Table 4: Distribution of the annotations for the category "Information"
7. Conclusion and Future Work
This work relies on several different disciplines: computer science, information science and NLP, and is being performed at a time when each of these disciplines are growing to a maturity that permits elaborating new approaches for semantic text processing. This work represents an important first step because it provides a fully automated processing chain for harvesting, conversion and semantic annotation. The relations established between metadata and semantically annotated textual elements in scientific publications give qualitative information to improve measures for mapping science. This approach emphasizes the organization of linguistic markers that are used as resources by the semantic annotation engine.
The first results are encouraging, but it is still necessary to address some of the limitations of this approach related to the working hypotheses. Moreover, an evaluation on a bigger corpus is necessary in order to confirm the reliability of the tool for citation analysis. Finally, the construction of multilingual resources is also under development, primarily for English, which will allow us to process larger corpora.
The approach that is proposed in this article can open a new discussion on bibliometric indicators. At this early stage of the implementation, we can start by studying the citation contexts and discuss the relevance of this approach for further applications. Moreover, by exploiting the semantic annotations of citations, when they are considered in relation to document metadata, we can provide a better access to the document content in an information retrieval perspective. In fact, the annotations identify some of the textual segments as relevant according to specific points of view. This orientation was considered in previous work [3,39]. However, OAI-PMH, by providing access to full text documents, allows us to envisage new perspectives for the mapping of science.
8. Acknowledgements
This work is supported by the Francophonie University Agency which is a global network of 693 institutions of higher education and research, Paris-Sorbonne University and John Libbey Eurotext edition who allow us to annotate their scientific journals. The application will be presented at the XIV Summit of the Francophony in Kinshasa in 2012.
9. References
[1] I. Atanassova, M. Bertin, and J.-P. Desclés. Ordonnancement des réponses pour une recherche d'information
sémantique à partir d'une ontologie discursive. In RISE —2012, 12e Conférence Internationale Francophone sur
l'Extraction et la Gestion de Connaissance, Bordeaux, France, 2012.
[2] C. Bannard and C. Callison-Burch. Paraphrasing with bilingual parallel corpora. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pages 597—604. Association for Computational Linguistics, 2005.
[3] M. Bertin. Categorizations and annotations of citation in research evaluation. In Proceedings of the 21st International Florida Artificial Intelligence Research Society Conference, Coconut Grove, Florida, USA, 15—17 May 2008.
[4] M. Bertin. Bibliosemantic: a linguistic and data-processing technique by contextual exploration. PhD thesis, University of Paris-Sorbonne, 2011. (in French).
[5] M. Bertin, I. Atanassova, and J.-P. Desclés. Extraction of author's definitions using indexed reference identification. In Proceedings of the 1st Workshop on Definition Extraction/WDE'2009, pages 21—25, Borovets, Bulgaria, September 2009. Association for Computational Linguistics.
[6] M. Bertin, J.-P. Desclés, B. Djioua, and Y. Krushkov. Automatic annotation in text for bibliometrics use. In Proceedings of the 19th International Florida Artificial Intelligence Research Society Conference, Melbourne Beach, Florida, USA, 11—13 May 2006.
[7] R. Cattell. Scalable SQL and NoSQL data stores. Association For Computing Machinery Special Interest Group On Management of Data Record, 39(4):12—27, 2011.
[8] D. E. Chubin and S. D. Moitra. Content analysis of references: Adjunct or alternative to citation counting? Social Studies of Science, 5(4):423—441, 1975.
[9] C. Corley and R. Mihalcea. Measuring the semantic similarity of texts. In Proceedings of the Association for Computational Linguistics Workshop on Empirical Modeling of Semantic Equivalence and Entailment, pages 13—18, 2005.
[10] D. Crockford. RFC 4627— The application/json Media Type for JavaScript Object Notation. Technical report, Internet Engineering Task Force, 2006.
[11] S. J. DeRose, D. G. Durand, E. Mylonas, and A. H. Renear. What is text, really? Journal of Computing in Higher Education, 1(2):3—26, 1990.
[12] J. Desclés, O. Makkaoui, and J.-P. Desclés. Towards automatic thematic sheets based on discursive categories in
biomedical literature. In Proceedings of the International Conference on Web Intelligence, Mining and Semantics, Songdal, Norway, 2011. Association for
Computing Machinery.
[13] J.-P. Desclés. Contextual exploration processing for discourse automatic annotations of texts. In Proceedings of the 19th International Florida Artificial Intelligence Research Society Conference (Invited speaker), Melbourne Beach, Florida, USA, 11—13 May 2006.
[14] B. Djioua, J.-P. Desclés, and M. Alrahabi. Next Generation Search Engines: Advanced Models for Information
Retrieval, chapter Searching and Mining with Semantic Categories, pages 115—138. IGI Publishing, Hershey-New York, USA, 2012.
[15] D. Dutoit and T. Poibeau. Inferring knowledge from a large semantic network. In Proceedings of the 19th international conference on Computational linguistics, pages 1—7. Association for Computational Linguistics, 2002.
[16] G. Garechana, R. Rio, E. Cilleruelo, and J. Gavilanes. Visualizing the scientific landscape using maps of science. In S. P. Sethi, M. Bogataj, and L. Ros-McDonnell, editors, Industrial Engineering: Innovative Networks, pages 103—112. Springer, 2012.
[17] E. Garfield. Can citation indexing be automated? Essay of an Information Scientist, 1, 1977.
[18] S. Gradmann, F. Borri, C. Meghini, and H. Schuldt, editors. Research and Advanced Technology for Digital Libraries — International Conference on Theory and Practice of Digital Libraries, TPDL 2011, Berlin, Germany, September 26—28, 2011. Proceedings, volume 6966 of Lecture Notes in Computer Science. Springer, 2011.
[19] R. Klavans and K. Boyack. Toward a consensus map of science. Journal of the American Society for Information Science and Technology, 60(3):455—476, 2009.
[20] P. Knoth, V. Robotka, and Z. Zdrahal. Connecting repositories in the open access domain using text mining and semantic data. Research and Advanced Technology for Digital Libraries, pages 483—487, 2011.
[21] J. Kunze and T. Baker. The Dublin Core Metadata Element Set. RFC 5013 (Informational), August 2007.
[22] L. Leydesdorff, S. Carley, and I. Rafols. Global maps of science based on the new web-of-science categories. CoRR, abs/1202.1914, 2012.
[23] G.-Y. Liu, J.-M. Hu, and H.-L. Wang. A co-word analysis of digital library field in china. Scientometrics, 91:203—217, 2012.
[24] A. Max and M. Zock. Looking up phrase rephrasings via a pivot language. In Proceedings of the workshop on Cognitive Aspects of the Lexicon, pages 77—85. Association for Computational Linguistics, 2008.
[25] H. F. Moed. Citation Analysis in Research Evaluation, volume 9 of Information Science and Knowledge Management. Springer, 2005.
[26] M. J. Moravcsik and P. Murugesan. Some results on the function and quality of citations. Social Studies of Science, 5:88—91, 1975.
[27] F. Muñoz-Leiva, M. Viedma-del Jesús, J. Sánchez-Fernández, and A. López-Herrera. An application of co-word analysis and bibliometric maps for detecting the most highlighting themes in the consumer behaviour research from a longitudinal perspective. Quality & Quantity, 46:1077—1095, 2012.
[28] H. Nanba, N. Kando, and M. Okumura. Classification of research papers using citation links and citation types: Towards automatic review article generation. In Proceedings of the SIG Classification Research Workshop, pages 117—134, 2000.
[29] K. Oliver and R. Swain. Directories of institutional repositories: research results & recommendations. In 72nd IFLA General Conference and Council, pages 20—24, 2006.
[30] M. Pasca and P. Dienes. Aligning needles in a haystack: Paraphrase acquisition across the web. In R. Dale, K.-F. Wong, J. Su, and O. Y. Kwong, editors, IJCNLP, volume 3651 of Lecture Notes in Computer Science, pages 119—130. Springer, 2005.
[31] S. Patwardhan, S. Banerjee, and T. Pedersen. Using measures of semantic relatedness for word sense disambiguation. Computational Linguistics and Intelligent Text Processing, pages 241—257, 2003.
[32] L. Qiu, M. Kan, and T. Chua. Paraphrase recognition via dissimilarity significance classification. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, pages 18—26. Association for Computational Linguistics, 2006.
[33] V. Rus, P. McCarthy, M. Lintean, D. McNamara, and A. Graesser. Paraphrase identification with lexico-syntactic graph subsumption. In Proceedings of the 21st International Florida Artificial Intelligence Research Society Conference, pages 201—206, 2008.
[34] A. Sandor, A. Kaplan, and G. Rondeau. Discourse and citation analysis with concept-matching. International Symposium : Discourse and document (ISDD), Caen, France, 2006.
[35] H. Small. Citation context analysis. B. Dervin and M. Voigt (Eds.), Progress in communication sciences, 3:287—310, 1982.
[36] H. Small. Visualizing science by citation mapping. Journal of the American society for Information Science, 50(9):799—813, 1999.
[37] H. Small. Paradigms, citations, and maps of science: A personal history. Journal of the American Society for Information Science and Technology, 54(5):394—399, 2003.
[38] M. Stonebraker. SQL databases v. NoSQL databases. Communications of the Association for Computing Machinery, 53(4):10—11, 2010.
[39] S. Teufel, A. Siddarthan, and D. Tidhar. An annotation scheme for citation function. In Proceedings of the 7th SIGdial Workshop on Discourse and Dialogue, Association for Computational Linguistics., pages 80—87, Sydney, July 2006.
[40] Z.-Y. Wang, G. Li, C.-Y. Li, and A. Li. Research on the semantic-based co-word analysis. Scientometrics, 90:855—875, 2012.
[41] Y. Yang, M. Wu, and L. Cui. Integration of three visualization methods based on co-word analysis. Scientometrics, 90:659—673, 2012.
[42] J. Zhang, J. Xie, W. Hou, X. Tu, J. Xu, F. Song, Z. Wang, and Z. Lu. Mapping the knowledge structure of research on patient adherence: Knowledge domain visualization based co-word analysis and social network analysis. PLoS ONE, 7(4):e34497, 04 2012.
[43] M. Zitt, A. Lelu, and E. Bassecoulard. Hybrid citation-word representations in science mapping: Portolan charts of research fields? Journal of the American Society for Information Science and Technology, 62(1):19—39, 2011.
About the Authors
 |
Marc Bertin is associate researcher at STIH-LaLIC laboratory at Paris-Sorbonne University. He received his MsC in "Information Society and Language Processing". He completed the first year of his Master degree at EBSI at the University of Montreal. He obtained his PhD with the highest level of distinction in Mathematics, Computer Science and Applications in Social Sciences at Paris-Sorbonne University. Prior to this, he worked on IT solutions for the Japanese pharmaceutical industry. His research interests include semantic annotation, knowledge extraction applied to digital libraries, and information retrieval.
|
 |
Iana Atanassova is associate researcher at STIH-LaLIC laboratory at Paris-Sorbonne University. After a BcS in Mathematics, she obtained her Master's degree in "Informatics and Language Processing". At the same time she attended courses in English Studies and Linguistics at Sofia University. She completed her PhD thesis with honors in the field of Semantic Information Retrieval at Paris-Sorbonne University. Currently, she works in as R&D project manager with the mission of developing a large-scale semantic search engine for open access scientific publications. Her research interests are in the fields of information extraction and semantic information retrieval, semantic annotation using knowledge-based methods and machine-learning, and multi-lingual automatic text processing.
|
|