 |
D-Lib Magazine
July/August 2011
Volume 17, Number 7/8
Table of Contents
Building a Sustainable Institutional Repository
Chenying Li, Mingjie Han, Chongyang Hong, Yan Wang, Yanqing Xu, and Chunning Cheng
China Agricultural University Library
Point of contact for this article: Chenying Li, licy@cau.edu.cn
doi:10.1045/july2011-chenying
Printer-friendly Version
Abstract
Institutional Repositories (IRs) are becoming important library resources, and increasing utilization of IR content is a key to building sustainable IRs. The China Agricultural University Library has developed a proven, successful service delivery model for IRs, through multi-themed, multi-layered organization of content, modular content publishing, and closely matching user requests, as is described in this paper.
Introduction
Institutional Repositories (IR) are becoming an increasingly important type of special resource and service offered by libraries. In Japan, for example, research and experimental work on IRs started in 2005, and IRs were formally introduced and have been promoted since 2006; as of July 19th, 2010, libraries in 155 universities had their own IR. [1, 2] However, the Directory of Open Access Repositories (OpenDOAR) studied 1,383 IRs globally and found that only 15.9% of them have more than 5,000 data records. [3] Among the biggest challenges to IR researchers is how to enrich the content of IRs and increase their utilization.
There are different types of knowledge repositories. Commercial databases offered by publishers, and openly accessible knowledge databases of various disciplines, collect similar content to that of an IR. However, the amount of data collected in an IR is typically far less than that of a commercial database, and the depth of specialty of IR content cannot match that of disciplinary repositories. Therefore IRs need to offer unique value in order to be viable and sustainable.
The China Agricultural University (CAU) Library was the first among university libraries in China to start digitization of antique books, and was a pioneer in digitization and online submission of Master's and Doctor's theses and dissertations. Over the years we have focused our research and practice on building and servicing featured digital resources, and constructed an end-to-end model of digital content collection, processing, organization, and servicing. The effort has resulted in rapid growth and accumulation of content in the China Agricultural University Institutional Repository (CAUIR). As of June 2010, CAUIR had built a collection of 9 types of resources and 88,000 metadata records, including 32,000 full text records, on the teaching and research achievements by faculty and staff of CAU.
In this paper we present in detail the methods of content organization and the servicing model of CAUIR. Additionally, we analyze the user access logs and demonstrate that closely meeting user requests is a key to improving utilization of an IR and achieving sustainable growth.
The content of CAUIR includes many different types of resources: published books and journal articles, dissertations, other types of academic publications, and various types of unpublished articles, such as journal preprints, technical reports, research progress reports, courseware, and other gray literature. Diversified types and sources of IR content make collection and organization far more difficult than it is for commercial databases and discipline repositories; at the same time, this attribute provides a foundation for a unique IR value proposition.
1. Structured Content Organization
Our research and practice over the years demonstrated that structured organization of IR content leads to more in-depth revelation of resource characteristics and inter-relationships. Organizing IR content according to its role in the University, as explained below, results in a clearer expression of goals and a more orderly process of content organization. This, in turn, leads to more efficient cataloging of metadata. Specifically, CAUIR adopted the principles of minimization of resource units, diversification of taxonomy, and standardization of attribute indexing in order to achieve high efficiency in content buildup and refined content structure.
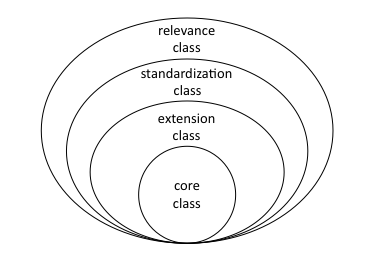 Figure 1: Structure of CAUIR Resource Repository
Figure 1: Structure of CAUIR Resource Repository
A resource repository is the basic component of an IR, and the structural design of the resource repository has important bearing on metadata design, content organization, and service model. CAUIR uses the type of document as the basic unit of a resource repository, and organizes resources into four classes, according to the criteria of recognition, audience, requirements of management and services: core class, extension class, standardization class, and relevance class (Figure 1).
Core class includes peer-reviewed publications: books, journal papers, dissertations for Master and Doctorate degrees, conference and symposium contributions, teaching and research achievements, patents, etc; core class content is the focus of content collection, management, and service.
Extension class covers academic achievements by faculty and staff to fulfill requirements and assignments of their respective posts, and are published to a limited audience; this class mainly includes course information, class syllabi, instructor's notes, reports on experiments, reports on research progress, meeting minutes, statistical data, and information on research projects. The core class and extension class form the foundation of the IR.
Standardization class is a collection of standardized names, terms, and attributes used to organize resources in a logical and efficient manner. Currently, the standardization class includes standardized titles of faculty and staff, standardized names of disciplines, standardized names of organizations, and standardized attributes of various types of resources. Standardization class is the basis for establishing inter-relationships among data records.
Relevance class covers resources related to research achievements and faculty and staff and their organizations, to facilitate and enhance understanding and utilization of resources. This class includes course text books and reference materials (books/journals/databases/online resources), media reports on faculty and staff members, web sites about teaching and research activities carried out by faculty and staff members, and academic resource on the web related to research projects.
This document-type based structure of resource units enables a thorough description of resource attributes, a refined expression of contents, laying a solid foundation for metadata extension, metadata re-organization, and content correlation.
Based on academic subject classification and faculty organizations, we weave the IR content into a highly interconnected structure. IRs typically contain multiple types and media formats of resources, and the nature of institutes dictates a wide range of disciplines and extensive coverage of knowledge fields. Compared to commercial databases and discipline repositories, the loose nature of the contents of IRs poses challenges for search and query. The purpose of IRs is to archive and preserve academic achievements by the institutions, and furthermore, to publicize and promote those achievements.
One important aspect of services delivered by IRs is to provide guidance to users. Since the activities of teaching, research, and services in institutes of higher education are carried out by the organizational units of colleges, departments, and focused research groups, CAUIR uses the faculty and staff as anchors, and organizes the IR contents by academic discipline and structure of colleges and departments (Figure 2). In this way, all the academic achievements of teaching and research by faculty and staff are interconnected, laying the foundation for implementing multiple navigation schemes.
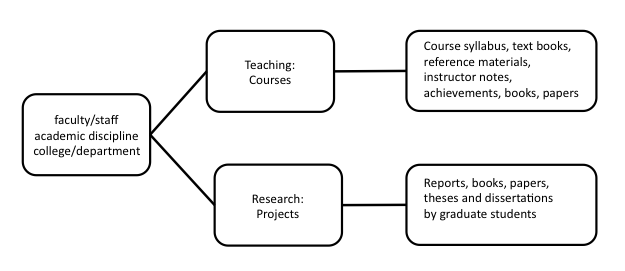 Figure 2: Basic Structure of IR Content and Organization
Figure 2: Basic Structure of IR Content and Organization
Although in this digital era more varieties of technologies (and more intelligent technologies) are at our disposal for organizing information resources, formal metadata cataloging is still the most commonly used method to achieve more efficient data collection, classification and cataloging, and improved navigation. In the design of the content organization for CAUIR, we focused on normalization of metadata cataloging; through in-depth analysis of the characteristics of resources, we standardized a set of titles, names, and resource attributes to facilitate data record inter-relating and data filtering. The standard titles and names consist mostly of names of faculty/staff, names of academic disciplines, names of organizations, types of resources and catalog numbers; standard attributes consist of type attributes of faculty/staff, characteristic attributes of resource content, service attributes of content, copyright attributes, and access attributes. Adoption of these standards resulted in improved efficiency in metadata cataloging, and made it feasible to inter-relate and filter data records; all of which are of great benefit to deep data mining.
2. Modular Content Publishing
Compared to commercial databases or discipline repositories, IRs can be less appealing to users due to the fact that IRs may have less content of more complex and varied types. Achieving high utilization is the driving force for sustaining growth of IRs. From many years of research and practice, we have developed a methodology of modular publishing for driving up user demand and utilization. Our content publishing system is comprised of multiple logical modules; each module is an independent publishing unit, and all the modules work together as a complete and comprehensive publishing system. We deploy techniques such as themed publishing, multiple navigation methods, and metadata aggregation. We take full advantage of rich functions offered by the CDI CM platform developed by Content Digital Innovation Technology Co., Ltd., to deliver modular content publishing through content filtering and re-assembly of related contents from multiple repositories.
The modular content publishing of CAUIR serves the goals of strengthening content publishing and improving service effectiveness. Themes are designed around which the resources of core class, extension class, and standardization class are re-organized for the presentation layer. We attract users by offering links to featured and recommended contents, and links to richer, related contents in relevance class. Table 1 lists the themes used by CAUIR.
Table 1: CAUIR Content Publishing Platform
CAUIR
Service
Platform |
Collections of publications by faculty and staff |
| Collections of Master and Doctorate thesis and dissertations |
| Discipline Topics |
Biology |
| Crop Sciences |
| Plant Protection and Preservation |
| Horticulture |
| Utilization of Agriculture Resources |
| Animal Sciences |
| Veterinary |
| Agricultural Engineering |
| Food Sciences and Engineering |
| Agricultural Economy |
| Graduate School Admission and Faculty Information |
While designing the service model of CAUIR, we decided to provide refined and flexible services to users by publicizing and promoting resources from various angles and multiple layers. Effective navigation is essential to guiding users and promoting resources. In addition to the primary navigation functions based on major classification systems of academic disciplines, and the organization structure of colleges and departments, CAUIR also offers navigation to featured content and latest collections that are selected based on the criteria of user interests, such as the type of resources, and resource attributes. We make primary navigation available on the secondary pages showing search results to provide increased flexibility. System logs show that users have a strong preference for using navigation functions over the search function.
Compared to physical resources, a distinctive feature of digital resources is that relevant information of different granularity forms a network and can be connected seamlessly. Based on theme and requests, CAUIR re-organizes metadata of different resource databases and presents related information in the same page. Figure 3 is an example page of integrated information of individual faculty and staff members, showing an introduction to the individual, media coverage, published books and papers, theses and dissertations of graduate students, teaching activities, research projects and achievements, patents, etc. Such integration of related information increases utilization of resources, enriches contents, and greatly reduces the amount of work for metadata recording.
Rich information in CAUIR on faculty and staff members and their academic achievements attracted the Graduate School of CAU, and in November 2008 the Graduate School started to integrate CAUIR into its information platform for graduate student admissions; in August of 2009, the integrated platform was formally launched as the information center for YR2009 Doctorate and Master Student Admissions, disciplines, and advisors. CAUIR expanded the metadata standards to include subjects of entrance examinations, designated reference materials, research directions, and advisors; furthermore, names of graduate advisors are linked to detailed information pages on them, giving candidates convenient access to comprehensive information on prospective advisors (Figure 3).
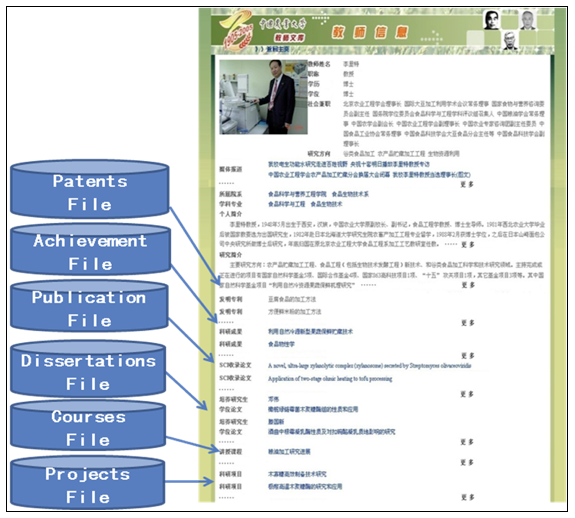 Figure 3: An Example of Re-organizing CAUIR Metadata
Figure 3: An Example of Re-organizing CAUIR Metadata
3. System Logs
The system logs showed that, since the inception of CAUIR in November 2007 to the end of June 2010, registered users made 4.574 million visits; in 2009, users made 2.684 million visits, and 1.265 million visits in 2008. In 2009, January and February had the largest increase of more than 1000% over the year before (Fig. 4). Since CAUIR was integrated into the platform of graduate school admissions, visits to academic discipline databases and the faculty and staff database increased greatly from 26,000 and 250,000 in 2008 to 126,000 and 578,000 in 2009. The average increase of visits to all databases in 2009 over 2008 is 93.5%. The data demonstrated increased awareness and utilization of CAUIR and its success.
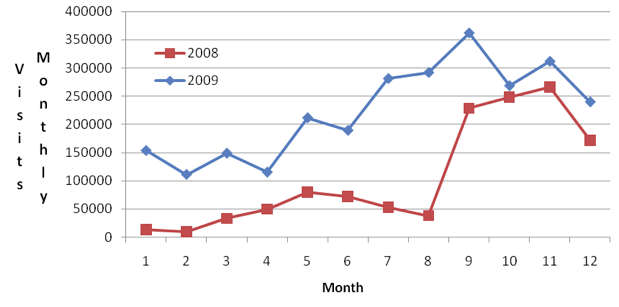 Figure 4: Trend of CAUIR Repository Monthly Visits (2008-2009)
Figure 4: Trend of CAUIR Repository Monthly Visits (2008-2009)
Conclusion
In this age of explosive growth of digital resources, it is becoming ever more important for libraries to provide the variety of contents and services that IRs play an important role in delivering. More and more users are taking advantage of what IRs have to offer. IR builders need to be cognizant of the different characteristics and approaches required compared to OPACs. CAUIR demonstrated success by designing and building an IR focused on fulfilling user requests, and providing refined content organization and services to users.
References
[1] NII Institutional Repositories program: http://www.nii.ac.jp/irp/en/about/.
[2] Japanese Institutional Repositories Online (JAIRO): http://jairo.nii.ac.jp/en/.
[3] The Directory of Open Access Repositories — OpenDOAR: http://www.opendoar.org/index.html.
About the Authors
 |
Chenying Li is a research librarian and director of the Digital Library Research Department at the China Agricultural University Library, where she has been working for 20 years. As a faculty member, Chenying's interests focus mainly on the methods and standards of Japanese online cataloging and digital resource collections and services. As a visiting scholar, Chenying worked in Tsukuba University in Japan on digital library research. She got a BS degree in Engineering at Northwestern University of Agriculture and Forestry.
|
 |
Mingjie Han is a research librarian and Associate Curator at the China Agricultural University Library. He graduated from the China Agricultural University and has been working in the Library for more than 30 years. Mingjie has extensive experience in the application of computer technology to library research.
|
 |
Chongyang Hong is an associate research librarian at the China Agricultural University Library. A graduate of Beijing Jiaotong University, Chongyang Hong has been working in the Library for 20 years, specializing in the application of computer technology.
|
 |
Yan Wang is an associate research librarian at the China Agricultural University Library. She graduated from Southwestern Agricultural University with a BS degree and has been working in the Library for 14 years. She specializes in research and use of digital resources.
|
 |
Yanqing Xu is an associate research librarian at the China Agricultural University Library. She got a BS degree in Veterinary Medicine at the China Agricultural University and has been working in the Library for 20 years, specializing in metadata research and practice.
|
 |
Chunning Cheng is a librarian at the China Agricultural University Library. She graduated from the China Agricultural University and has been working in the Library for 8 years, focusing on the formulation of metadata.
|
|