|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
William H. Mischo |
![]()
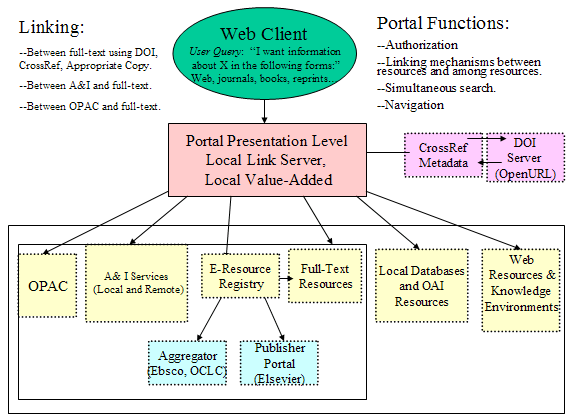
IntroductionAs information professionals, we live in very interesting times. Effective search and discovery over open and hidden digital resources on the Internet remains a problematic and challenging task. The difficulties are exacerbated by today's greatly distributed scholarly information landscape. This distributed information environment is populated by silos of: full-text repositories maintained by commercial and professional society publishers; preprint servers and Open Archive Initiative (OAI) provider sites; specialized Abstracting and Indexing (A & I) services; publisher and vendor vertical portals; local, regional, and national online catalogs; Web search and metasearch engines; local e-resource registries and digital content databases; campus institutional repository systems; and learning management systems.
For years, information providers have focused on developing mechanisms to transform the myriad distributed digital collections into true "digital libraries" with the essential services that are required to make these digital libraries useful to and productive for users. As Lynch and others have pointed out, there is a huge difference between providing access to discrete sets of digital collections and providing digital library services (Lynch, 2002). To address these concerns, information providers have designed enhanced gateway and navigation services on the interface side and also introduced federation mechanisms to assist users through the distributed, heterogeneous information environment. The mantra has been: aggregate, virtually collocate, and federate. The goal of seamless federation across distributed, heterogeneous resources remains the holy grail of digital library work. Background WorkAs we look back over the evolution of digital library technologies and reflect on how we got where we are, it is important to consider the contributions of federally supported projects and also to note the provenance of other emerging information technologies. Federal programmatic support for digital library research was formulated in a series of community-based planning workshops sponsored by the National Science Foundation (NSF) in 1993-1994. The first significant federal investment in digital library research came in 1994 with the funding of six projects under the auspices of the Digital Libraries Initiative (now called DLI-1) program. These DLI-1 research and development projects were jointly funded by a federation comprised of the National Science Foundation (NSF), the National Aeronautics and Space Administration (NASA), and the Defense Advanced Research Projects Agency (DARPA). (Griffin, 2000). In 1998, at the cessation of the DLI-1 program, federal funding for the DLI-2 program was instituted with support from NSF, NASA, DARPA, the National Library of Medicine (NLM), the Library of Congress (LC), the Federal Bureau of Investigation (FBI), and the National Endowment for the Humanities (NEH). Also, in 1998, the Corporation for National Research Initiatives (CNRI), under DARPA support, funded the three-year D-Lib Test Suite program which provided continuing funding for several of the digital library Testbeds created under DLI-1. In aggregate, between 1994 and 1999, a total of $68 million in federal research grants were awarded under DLI-1 and DLI-2 (Fox, 1999). Following on two prototype projects awarded under DLI-2, the National Science, Technology, Engineering, and Mathematics Digital Library (NSDL) program began its first formal funding cycle during fiscal year 2000 and awarded 119 grants between FY 2002 and FY 2004. DLI-1 funded six university-led projects to develop and implement computing and networking technologies that could make large-scale electronic test collections accessible and interoperable. The projects employed multi-departmental teams in tangent with commercial vendors or software companies to push the envelope of digital library research. The six funded institutions with their primary focus were:
In the Illinois project, the overarching focus of the Testbed component was on the deployment and evaluation of journals in a marked-up format within an Internet environment. Probably the most significant contribution of the Illinois project was the transfer of technology to our publishing partners and other publishers (Mischo and Cole, 2000). It has now become commonplace for both major and small-scale publishers to provide Web-based access to their full-text journal issues and articles. To illustrate this, the TDNet e-resource manager presently lists over 80K unique online full-text journal titles. It is astounding how far online journals have come in a very short time. Many of these publishers support feature sets that closely follow those that were originally developed within the Illinois Testbed project. These include: full-text display using HTML and Cascading Style Sheets (CSS), internal linking between citations and footnotes, forward and backward links to cited articles using DOIs and OpenURLs, and, less commonly, the display of complex mathematics and special Unicode characters directly in the HTML or XML full text. When DLI-1 began, the World Wide Web was in a very nascent stage. At that time, the University of Illinois' National Center for Supercomputing Applications (NCSA) Mosaic 2.0 beta was the Web browser of choice, the HTML 2.0 standard was still under development, Netscape had yet to release its first Web browser and Microsoft Windows 3.1 was the standard personal computer operating system. In the area of focus of our Illinois grant, the few full-text journals at that time were primarily comprised of static, proprietary files in the form of bit-mapped images. All of these 1994 emergent digital library technologies remain relevant and vital today. The DLI projects took an "over-the-horizon" view that contributed greatly to advancing the state-of-the-art in their selected areas. Just as earlier federal grant work led to the development of the Internet and the Web browser – albeit as offshoots from the primary work that was funded – the DLI programs contributed to the development of best practices and standards for digital library work. Some of the work led to significant technology transfer and spinoffs (e.g., Google grew out of research performed under the Stanford DLI-1 project). An international collaboration by Cornell and the UK ePrint project, under DLI-2, contributed to the development and adaptation of the Open Archives Initiative for Metadata Harvesting (OAI-PMH) specifications and protocols. Overall, the DLI-1 projects served to identify and define important document and data metadata standards, protocols for Web-based access, and the issues surrounding federated and broadcast search protocols. Another interesting effect of the increased federal funding for digital library research was that senior scholars from other computing disciplines were brought into the field (Lesk, 1999). Whether digital library work will continue to be interesting to the computer science community at large is an open question. Computer and networking technology has changed dramatically over the last 10 years and nowhere is this more evident than in the rapidly evolving world of digital library implementation and practice. A large number of significant digital library standards and technologies have been developed by entities outside of the federally funded projects. A sampling of these include:
Also, government funded projects outside the U.S. have made major contributions, including JISC (Joint Information Systems Committee) in the UK, the EnrichUK project, and the Minerva eEurope Knowledge Base. Federation SolutionsSeveral of the DLI-1 and DLI-2 projects examined issues connected with federation. In retrospect, the DLI projects did not have the requisite technology to federate and integrate what was then an expanding universe of discrete, distributed information resources. The development of mechanisms for distributed search is an area of focus within the NSDL Core Integration project. The Illinois, Stanford, and Michigan DLI-1 projects all addressed issues connected with search interoperability and federated searching. It is interesting to contrast these interoperability approaches. The Stanford model employed a shared information bus that utilized metadata schemes and search threading operating across heterogeneous information resources in a stateless Web environment. The Michigan view was built around a collection of collaborating software agents that tied together a set of servers spread throughout the Internet. The Illinois approach utilized broadcast, asynchronous searching of distributed, heterogeneous repositories. These approaches presaged the development of Web Services architectures. Of course, these technologies remain relevant and help to delineate the issues surrounding federation. There has been a surge of interest in metasearch or federated search technologies by vendors, information content providers, and portal developers. These metasearch systems employ aggregated search (collocating content within one search engine) or broadcast searching against remote resources as mechanisms for distributed resource retrieval. Google, Google Scholar and OAI search services typify the aggregated or harvested approach. Vendor systems such as Ex Libris Metalib, Endeavor Encompass, and WebFeat utilize broadcast search approaches. Another one-stop shopping aggregated approach is represented by Elsevier's comprehensive (in the sciences) Scopus A & I service. It is interesting that Google Scholar is being held up as the competition for both campus institutional repository systems (at least in terms of search and discovery) and academic library federated searching. A related or connected issue is the debate surrounding the efficacy of metadata searching vs. full-text searching. This issue pits Google-type Web search against OAI harvested search and discovery. One promising supplement to OAI item-level metadata is collection-level metadata search. In fact, the aggregated and broadcast approaches can be complementary and synergistic. However, to facilitate this, broadcast searching needs to become standardized. The NISO Metasearch Initiative (http://www.niso.org/committees/MetaSearch-info.html) seeks to develop industry standards for one-search access to multiple resources that will allow libraries to offer portal environments for library users offering the same easy searching found in Web-based services like Google. The NISO Metasearch Initiative is proposing a standard built around a streamlined SRU/SRW protocol with REST (Representational State Transfer) queries that return XML. So, we return to the fact that we have, in our armamentarium, some powerful tools for resource access. In the next several years, we will extend the current standards and practices to offer more effective and efficient access to the distributed information environment. ReferencesEdward A. Fox. 1999. "Digital Libraries Initiative: Update and Discussion" Bulletin of the American Society for Information Science, 26(1):7-11. October/November. Stephen M. Griffin. 1998. "NSF/DARPA/NASA Digital Libraries Initiative: A Program Manager's Perspective." D-Lib Magazine July/August. doi:10.1045/july98-griffin. Accessed April 15, 2003. Michael Lesk. 1999. "Perspectives on DLI-2 - Growing the Field." Bulletin of the American Society for Information Science, 26(1):12-13. October/November. Clifford Lynch. 2002. "Digital Collections, Digital Libraries and the Digitization of Cultural Heritage Information" First Monday, 7(5). May 2002, <http://firstmonday.org/issues/issue7_5/lynch/index.html>. William H. Mischo and Timothy W. Cole. 2000. "Processing and Access Issues for Full-Text Journals." Successes and Failures of Digital Libraries: Papers Presented at the 35th Annual Clinic on Library Applications of Data Processing. Eds. Susan Harum and Michael Twidale. March 22-24. Copyright © 2005 William H. Mischo |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/july2005-mischo
|