D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
Table of Contents
Acquiring High Quality Research Data
Andreas Hense
Department of Computer Science, Bonn-Rhine-Sieg University oAS, Sankt Augustin, Germany
andreas.hense@h-brs.de
Florian Quadt1
Department of Computer Science, Bonn-Rhine-Sieg University oAS, Sankt Augustin, Germany
florian.quadt@h-brs.de
doi:10.1045/january2011-hense
Printer-friendly Version
Abstract
At present, data publication is one of the most dynamic topics in e-Research. While the fundamental problems of electronic text publication have been solved in the past decade, standards for the external and internal organisation of data repositories are advanced in some research disciplines but underdeveloped in others. We discuss the differences between an electronic text publication and a data publication and the challenges that result from these differences for the data publication process. We place the data publication process in the context of the human knowledge spiral and discuss key factors for the successful acquisition of research data from the point of view of a data repository. For the relevant activities of the publication process, we list some of the measures and best practices of successful data repositories.
1 Introduction
In the research community the culture of conveying knowledge by publishing papers has a long tradition, and in the last decade digital text publication has been fully established. In all research endeavours where data play a central role the expectations of verifiability of experiments have grown [1] and the need for reusing and recombining existing data sets for further investigations is growing, too [9]. The publication of data is still under development, and the state of the art differs a lot in the research communities and disciplines.
In this paper we will take a look at data publication in the context of the knowledge spiral of research. Looking at the different stages and activities of this spiral, we establish a list of key factors that are important for the acquisition of high quality research data. An overall study on the state of the art in data publication would be beyond the scope of this paper. The authors' experience comes from a DFG-funded project on the publication of meteorological data and an e-Research study tour in Australia.
2 Challenges of Data Publication
In comparison to traditional text publications, data publications present some new challenges. This section contains a selection of prominent aspects. Whenever we refer to the term paper we think of all kinds of publications in text form like journal articles, presentations, books, etc.
File formats
For text publications, there are several widely accepted file formats such as plain text, HTML, Rich Text Format, Microsoft Word, OpenOffice documents, Adobe's Portable Document Format (PDF), LaTeX code, etc. All these formats are used by researchers worldwide in all disciplines.
For research data, a variety of file formats exist, such as XML, spreadsheet files, database schemas, and many binary formats, which are optimised for the needs of a certain domain. Individual formats cannot be opened with standard tools but need the installation of specialised software analysis and visualisation.
Contents
It goes without saying that data files serve another purpose than research texts. A paper is written and consumed by a human being and thus necessarily has a subjective character. Since its purpose is to transfer knowledge, the author develops a logical and didactical structure, highlights important aspects, interprets data, and uses tables, figures, and pictures to illustrate specific statements.
On the other hand, data files are often directly or indirectly produced by a computer or an instrument. In general, the file formats used here have a strict structure and are optimised for being imported and processed by a computer. Thus, data files are objective and plain, and not always adequate for direct human inspection.
SQA
Scientific quality assurance (SQA) — especially in the form of a peer-review — has a long tradition. Since SQA is a substantial process, the reviewer needs to have a deep understanding of the topic. In the case of a paper, the auditor reviews the propositions, its reasoning and references to other publications. These checks must be performed by a human expert and are time-consuming. Since papers are optimised for human reception and hopefully have a restricted volume of pages, SQA is feasible in the majority of cases.
By contrast, data can be huge and stored in formats that are not optimised for human reception. Therefore, in the majority of cases, SQA on data cannot be done exhaustively and relies on the help of computers. It is still not clear in all cases how to systematically perform SQA on data. Moreover, the procedure is heavily dependent on the kind of data and the domain. Besides the primary data itself, its metadata needs to be checked. All in all, the reviewer must have the appropriate competence and software tools to perform scientific quality control. As a consequence of these difficulties, the quality level of data is not "peer-reviewed" but "approved-by-author".
FQA and TQA
In contrast to SQA, formal quality assurance (FQA) deals with aspects like word count, typesetting, and structure. In general, the FQA reviewer does not need to have a deeper understanding of the contents, and FQA is usually done in a fraction of the time needed for SQA.
In the context of data files, a comparable approach to FQA is technical quality assurance (TQA). In the course of this procedure, reviewers check whether the data are complete and do not show any syntactical abnormalities (e.g. validation of an XML file against an XML schema). The comparison of checksums asserts an error-free transfer from source to target location.
Browsing and searching
Since research papers contain directly indexable words and are often accompanied by explicit metadata, the classification and indexing process is relatively straightforward. In practice, modern repositories support all of the formats for text files mentioned before.
If research data are saved in file formats that are not recognised by the search engine or the data themselves are too large, the indexing must be restricted to the given metadata. Therefore the metadata of data files are crucial for browsing and searching.
Storage site
Even a very comprehensive text publication can be saved as a single file and be stored in a repository. Thus, the repository can serve as a long-term archive and can directly answer requests for access to a paper.
When dealing with data files, we are easily confronted with volumes of gigabytes and terabytes. Files of this size pose problems with respect to storage space, bandwidth, backup mechanisms, and costs. Usually, text repositories do not meet the requirements for managing huge data files. Instead they allow for linking to external resources — being accompanied by problems like dead links and synchronisation. Data management and curation become an issue here [10, 7].
3 The Data Publication Process
3.1 Knowledge Acquisition
The acquisition of knowledge is characteristic of all human beings and especially of researchers. According to Nonaka and Takeuchi [8] knowledge exists in an implicit and an explicit form and transits between these forms by socalisation, internalisation, externalisation, and combination. The two relevant transitions in the context of publications are internalisation and externalisation.
Internalisation describes the transition from explicit to implicit knowledge, for example by reading documents or manuals. Externalisation is the process of expressing implicit knowledge as explicit concepts. If we apply these two transition types to a researcher, we can regard internalisation as reading publications and watching presentations, thus receiving information of all kinds and learning from it. Externalisation is the dissemination of personal knowledge like giving presentations at conferences and publishing papers.
From a community point of view, we can observe that there are interactions between the internalisation state of one researcher and the externalisation states of others. This happens when the information demand of one researcher meets the information offerings of another.
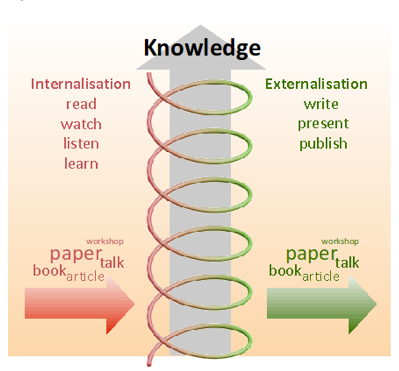 Figure 1: The knowledge spiral for a researcher.
Figure 1: The knowledge spiral for a researcher.
A common metaphor for the acquisition of knowledge is a spiral which evolves continuously [8]. In Figure 1 we show such a knowledge spiral in a research context. We suppose that in each winding, the researcher first is in an internalisation state, in which he has to learn, e.g. by reading books or by listening to talks (corresponding to the externalisation output of other researchers). After that he moves into the externalisation state, in which he writes documents or gives presentations. The arrows on the left and right of the spiral represent the scientific input and output respectively.
3.2 The Data Publication Cycle
If we focus on one single winding of the spiral introduced in Section 3.1, we get a simplified publication process (see Figure 2). Since this article is about the acquisition of high quality research data, we have put this process in the context of data publication. In the following, we will briefly describe the six phases of this data publication cycle. We start with a researcher looking for data, thus with the phase 'search and browse' in the lower left section of the cycle.
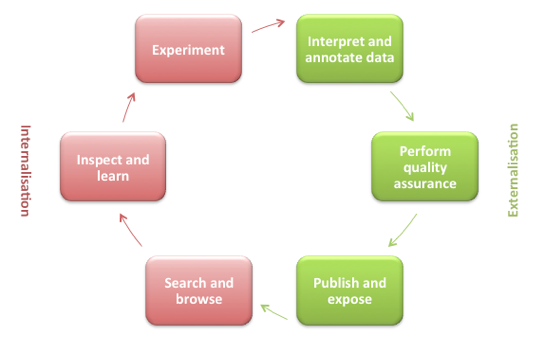 Figure 2: The data publication cycle.
Figure 2: The data publication cycle.
Search and browse
New research usually starts with searching and browsing for relevant data. The starting points and tools depend on the research domain and on the individual. The most obvious criteria for using a specific data repository are the quality and quantity of the items in its catalogues. These factors depend directly on the quantity and the quality of other researchers' input. Whether a researcher commits or does not commit his work to a specific repository depends on the attractiveness of the repository, which is influenced by obvious qualities like functionality, design, performance, stability, usability etc., but also by factors like usage parameters, acceptance, and reputation in the community.
Inspect and learn
When data from the previous activity are available, the researcher inspects, visualises, and processes the data. This activity comprises all efforts of the researcher to acquaint himself with the data and learn from them. This is an essential procedure in the internalisation stage since we have a straight transition from explicit to implicit knowledge at this point.
In the context of text publications, this activity would be the reading part, but since data usually cannot be read in a traditional sense, we consider the term 'inspect' more suitable.
Experiment
During this activity, the researcher applies the acquired knowledge to new problems. This can be done by conducting novel experiments or processing the data from a different point of view. As a result the researcher may gain new data that can be contributed to the community.
Interpret and annotate data
This activity deals with the preparation of a data publication, and thus is the first activity of the externalisation stage. As data files are plain, the researcher needs to interpret and annotate the data to attract other researchers. This can be done by writing a paper which is based on the data and which highlights the interesting parts. For later use and registration in repositories the data file must be augmented with metadata.
Perform quality assurance
Quality assurance exists in a vast variety of procedures. As mentioned in Section 2 we can differentiate between scientific and formal/technical quality assurance. The simplest form is quality assurance by the author himself, but it is well-known that it is hard to find all of one's own mistakes. A more advanced form is peer-reviewing, in which one or more researchers review the paper and the data and can reject the submission if it does not meet the formal or scientific quality standards. This method is used by a lot of repositories and scientific journals. With respect to data files which are to be published it is important to extend the quality assurance on data and metadata. Metadata are of equal importance because they are crucial for registering the data in search engines and repository catalogues.
Quality assurance should be done thoroughly, particularly with regard to the immutability after publication (see Section 4).
Publish and expose
Once data files, metadata, and additional documents have passed quality assurance, the files are published and registered. The term 'publish' refers to storing the data files in a publicly shared, long-term available space and assigning persistent identifiers such as DOI or URN. Under 'expose' we subsume the registration at search engines and repository catalogues. While it is technically possible to change data after publication it should be common practice to lock the data (immutability) and publish corrected data as new versions. After this activity, a publication cycle of another researcher can be initiated and we start over with the activity 'search and browse'.
4 Key Factors for High Quality
How can a data repository acquire high quality research data? The answer is simple: the repository has to be attractive for researchers, both in the externalisation and the internalisation phase. Only if a repository attracts enough high quality submissions is a thorough selection possible, and many researchers will use the data sets in a repository if quality and quantity are right.
The attractiveness of a repository can be seen as a high-level key factor. Attractiveness itself depends on the following three key factors:
Reputation. If a repository has the reputation of accepting only high quality research data and the visibility of its publications is high, a publication there is of great value for the researcher.
Reliability. If the organisation which is running the repository is known to be well-financed and has a long tradition, researchers will believe that their data are stored safely and for the long term.
Process. If the submission and quality assurance process is well documented and user-friendly it will engender trust and lower the workload for potential submitters.
According to the data publication cycle of Section 3.2, the acquisition of high quality data mainly happens in the externalisation stage. We will focus on the associated activities 'interpret and annotate data', 'perform quality assurance', and 'publish and expose', and present factors on optimising these activities in order to acquire high quality data.
4.1 Interpret and Annotate Data
The first factor to be taken into consideration is whether a researcher is motivated to publish his data. Data publication still is in a very early stage, but we are convinced that in the future, researchers of data-centric disciplines will not only be evaluated by their text publications but also by data publications (and the corresponding citations).
From conversations with other researchers we have learned that they often do not know where to store their data permanently and that data publication appears difficult and costly to them. We found a very promising approach in the e-Research community of Australia. The national initiative called Australian Research Collaboration Service (ARCS) aims among other things at providing Australian researchers with tools and services around data storage, transport, access and sharing. These data services contain a service called Data Fabric. This service provides researchers with free data storage, which can also be shared. The idea is to put data on Data Fabric as early as possible to optimise collaboration, reduce data redundancies, and avoid later transfer steps. Other interesting features of the Data Fabric are operating system integration and professional data backup in other sites. For solar, geophysical and related environmental data there exists the World Data Center System (WDC). Researchers of these disciplines can approach the data centers, which are specialised and distributed all over the world, and submit their data for long-term archiving.
Besides simplified data storage, the annotation of primary data with metadata should also be easy. To avoid errors later, the metadata should be captured as early as possible, e.g. by entering the metadata in the field [5]. This way the researcher can enter metadata right at the moment that the primary data are gathered. The costs of metadata creation can greatly increase depending on its point of time: a project in the Netherlands estimated that it costs approximately 333 euros for capturing the metadata of a batch of 1,000 records at creation, whereas the costs may rise to 10,000 euros if appropriate metadata is not created until 10 years later [2].
4.2 Perform Quality Assurance
We distinguished between scientific and technical quality assurance. Technical quality assurance procedures on data are driven by technical specifications such as accepted file formats or specified XML schemas. This makes TQA a systematic procedure which can be partially automated. We will therefore focus on scientific quality assurance.
As we learned from Section 2, SQA on data needs some kind of computer support in order to deal with huge amounts of data. From our experience, quality assurance of the primary data is mostly done by the author himself. There are efforts to support the author in this process by providing software tools which inspect the data, visualise the data and hint at abnormalities.
Examples of this approach are the activities in the research project Publication of Environmental Data funded by the German Research Foundation (DFG). In the course of this project, a standalone software package for reviewing meteorological data was developed. This software detects outliers and other deviations based on user parameters. After the analysis, the software writes out an XML report which can be annotated by the author to justify the findings. To make the results reproducible, the system stores the used parameters and version information in the report file as well. Then this report together with the data can be submitted to the long-term archive to document the quality measures.
Checking the metadata is another essential part of the SQA process and needs similar attention. This issue is also dealt with in the research project mentioned above. A web-based software reads existing metadata from the relevant long-term archive and presents the metadata as a series of thematically differentiated forms which the user can traverse, similarly to a software installation wizard. The individual input forms are as user-friendly as possible, utilising search functions for selections from comprehensive lists, drop-down menus for selections from controlled vocabularies, and map views for previewing geographical references, all with help texts available at all times.
4.3 Publish and Expose
We have already defined the publishing process as storing and identifying the data, and the exposing process as registering at repositories and making data findable to search engines. In Subsection 4.1 we presented some approaches for simplifying storing in a long-term archive. Identification with persistent identifiers can be made easy as well: another Australian national initiative called Australian National Data Service (ANDS) [4, 6]) aims at helping researchers to publish, discover, access and use research data. Some interesting services in this context are the Publish My Data service, which helps an individual researcher to publish a collection of research materials with basic metadata, the Register My Data service, which assists researchers and research organisations in publicising their research data collections as a whole, and finally the Identify My Data service, which provides persistent identifiers for researchers' data.
Science happens on an international level. This is why several national institutions joined forces in January 2010 and founded an international initiative called DataCite, [3]). DataCite is a not-for-profit agency which enables organisations to register research datasets and assign persistent identifiers. Some of the benefits will be reduced infrastructure costs, better integration of national infrastructures, and advanced search capabilities for improving researchers' awareness of available datasets.
5 Conclusion
We have placed the subject of data publication in the context of the knowledge spiral in research. We have identified the key factors for data repositories for achieving the necessary quantity and quality of data submissions. We have given best-practice examples of measures taken to support the key factors in the different activities of the data publication process. We hope that placing this topic in the context of the knowledge spiral sheds some light on the priorities to be taken in optimising the knowledge spirals of individuals and the worldwide research community.
Acknowledgements
We are indebted to Anthony Beitz from Monash e-Research Centre for his advice and help with his vast network of contacts. We thank Paul Bonnington and the people of his Monash e-Research Centre for their kind hospitality in November 2009.
Notes
1. Florian Quadt is funded by the DFG (German Research Foundation) under grant HE-1966.
References
[1] Steve Androulakis, Ashley M. Buckle, Ian Atkinson, David Groenewegen, Nick Nichols, Andrew Treloar, and Anthony Beitz. Archer — e-research tools for research data management. 2009. URL http://eprints.jcu.edu.au/9194/1/9194_Androulakis_et_al_2009.pdf. (Access restsricted.)
[2] Neil Beagrie, Julia Chruszcz, and Brian Lavoie. Keeping Research Data Safe (Phase 1) — A study funded by JISC. Technical report, Charles Beagrie, April 2008. URL http://www.jisc.ac.uk/media/documents/publications/keepingresearchdatasafe0408.pdf.
[3] Jan Brase. DataCite — A global registration agency for research data (working paper 149/2010). German Council for Social and Economic Data (RatSWD), July 2010. URL http://www.ratswd.de/download/RatSWD_WP_2010/RatSWD_WP_149.pdf.
[4] Adrian Burton and Andrew Treloar. Publish my data: A composition of services from ANDS and ARCS. In 2009 Fifth IEEE International Conference on e-Science, pages 164-170, Oxford, United Kingdom, 2009. doi:10.1109/e-Science.2009.31.
[5] Andreas Hense, Florian Quadt, and Matthias Römer. Towards a Mobile Workbench for Researchers. In Proceedings of the 2009 Fifth IEEE International Conference on e-Science, pages 126-131. IEEE Computer Society, 2009. ISBN 978-0-7695-3877-8. doi:10.1109/e-Science.2009.26. URL http://portal.acm.org/citation.cfm?id=1724812.
[6] Stefanie Kethers, Xiaobin Shen, Andrew E. Treloar, and Ross G. Wilkinson. Discovering Australia's Research Data. In Proceedings of JCDL 2010, June 2010. URL http://andrew.treloar.net/research/publications/jcdl2010/jcdl158-kethers.pdf.
[7] Jens Klump. Anforderungen von e-Science und Grid-Technologie an die Archivierung wissenschaftlicher Daten, 2008. URL http://edoc.hu-berlin.de/ docviews/abstract.php?id=29641.
[8] Ikujiro Nonaka and Hirotaka Takeuchi. The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation. Oxford University Press, USA, May 1995.
[9] B. Plale, D. Gannon, J. Alameda, B. Wilhelmson, S. Hampton, A. Rossi, and K. Droegemeier. Active management of scientific data. Internet Computing, IEEE, 9(1):27-34, 2005. ISSN 1089-7801. doi:10.1109/MIC.2005.4.
[10] Andrew Treloar, David Groenewegen, and Cathrine Harboe-Ree. The Data Curation Continuum. D-Lib Magazine, 13(9/10), 2007. ISSN 1082-9873. doi:10.1045/september2007-treloar.
About the Authors
 |
Professor Andreas Hense received his Ph.D. (Dr. rer. nat.) in computer science at Universitaet des Saarlandes in 1994. He has more than ten years experience as a project manager and consultant in banking and the public sector. He has been Professor of Business Information Systems at Bonn-Rhine-Sieg University oAS since 2004, where he teaches in the area of Development and Management of IT-Systems. His research interests comprise Workflow Management Systems, Document Management Systems, and e-Research. His interest in e-Research was sparked in 2006 by the eSciDoc-Project. Since then he has studied the combination of Mobile Clients, Workflow Management Systems and Digital Object Repositories. Since 2009 he has worked in the domain of Data Publication. In November 2009 he visited Australia on an e-Research-Study-Tour.
|
 |
Florian Quadt studied computer science at the Bonn-Rhein-Sieg University of Applied Sciences and received a Master's Degree in 2006. During his studies he focused on information retrieval and implemented a cross-lingual search engine in his master thesis. He worked for an IT consultancy for two years, specializing in code analysis, architecture evaluation and verification. In April 2009 he returned to Bonn-Rhein-Sieg University as project manager of a research project to develop a publication system for meteorological experiment data.
|
|