 |
D-Lib Magazine
January/February 2010
Volume 16, Number 1/2
Table of Contents
RDA Vocabularies: Process, Outcome, Use
|
Diane Hillmann
Information Institute of Syracuse
Metadata Management Associates
<metadata.maven@gmail.com>
|
Karen Coyle
kcoyle.net
<kcoyle@kcoyle.net>
|
Jon Phipps
JES & Co.
Metadata Management Associates
<jonphipps@gmail.com>
|
Gordon Dunsire
University of Strathclyde
<g.dunsire@strath.ac.uk>
|
Printer-friendly Version
Abstract
The Resource Description and Access (RDA) standard, due to be released this coming summer, has included since May 2007 a parallel effort to build Semantic Web enabled vocabularies. This article describes that effort and the decisions made to express the vocabularies for use within the library community and in addition as a bridge to the future of library data outside the current MARC-based systems. The authors also touch on the registration activities that have made the vocabularies usable independently of the RDA textual guidance. Designed for both human and machine users, the registered vocabularies describe the relationships between FRBR, the RDA classes and properties and the extensive value vocabularies developed for use within RDA.
Introduction
RDA (Resource Description and Access) is a new standard for metadata describing resources held in the collections of libraries, archives, museums, and other information management organizations [RDA prospectus]. It aims to provide a comprehensive set of textual guidelines and instructions for creating metadata covering all types of resource content and media. It builds on the Anglo-American Cataloguing Rules developed over the course of the 20th century and now in its second edition (AACR2), the development of the model of Functional Requirements for Bibliographic Records (FRBR) and the Statement of International Cataloguing Principles, formulated in the first decade of the 21st century [FRBR] [Statement of ICP]. RDA essentially standardizes how metadata content is identified, transcribed and generally structured, although it is independent of any specific metadata encoding. RDA also identifies a general set of metadata elements, and in many cases provides a controlled vocabulary for use as the content of an element. Although RDA is being developed primarily for use with resources curated in a library environment, consultations have been undertaken with other information management communities, including publishers and those operating in the digital world, to try to ensure effective alignment with the metadata standards used in those communities.
One such community is the Dublin Core Metadata Initiative (DCMI). Since May of 2007, the development of the textual guidance portion of RDA has been taking place in parallel with another effort to develop formal representations of the RDA element sets and value vocabularies for the use of humans and machines [DCMI]. This work began as a result of a meeting held at the British Library in April/May of 2007, which included representatives from the Joint Steering Committee for Development of RDA (JSC) and DCMI [JSC]. Included were DCMI community members with experience in Semantic Web technologies, and Gordon Dunsire from the University of Strathclyde, representing the RDA Outreach Group and the CILIP-BL Committee on AACR [DCMI/JSC Meeting] [CILIP-BL Committee on RDA]. Out of this meeting, which endorsed the immediate development of the full range of RDA vocabularies, grew the DCMI/RDA Task Group, co-chaired by Diane Hillmann and Gordon Dunsire [DCMI/RDA TG]. The Task Group raised funds from the British Library and Siderean Software to hire consultants and recruit volunteers for the project, and began using the NSDL Registry to develop and register the vocabularies [NSDL Registry]. As part of the Task Group mission, a wiki and discussion list were set up, and these have provided tools to build a community of interest around the work.
The charter of the Task Group is "to define components of the draft standard 'RDA - Resource Description and Access' as an RDF vocabulary for use in developing a Dublin Core application profile" [RDFS]. An application profile is defined by DCMI as "a set of metadata elements, policies, and guidelines defined for a particular application" [DCMI Glossary].
As the release of RDA draws closer, (1) it seems an appropriate time to review the decisions made and outcomes of the work of the Task Group, and provide an overview of what can be found in the registered vocabularies themselves [NSDL RDA].
RDF
The Resource Description Framework (RDF) is a group of specifications developed by the World Wide Web Consortium (W3C) as a model for metadata description. It is a language for the representation of information about resources in the World Wide Web [W3C] [RDF primer]. The concept of a resource is generalized in RDF to mean anything that can be described with metadata. This allows metadata to be applied to anything that can be identified, even if it it cannot be directly retrieved on the web. RDF is thus compatible with the most likely current real-world scenarios that RDA is intended to address, where the metadata is largely machine-readable and the resources described are not.
RDF is a good choice for application to RDA vocabularies for several reasons. The RDF model is based on the simplest of metadata structures, a single statement about a single property of a single resource. Such statements can be aggregated in flexible ways to form higher-level descriptions, or metadata "records", of a specific resource. Modelling the RDA entity vocabulary in RDF helps to meet the RDA aim of providing instructions for recording metadata that can be applied independently of any particular structure or syntax for data storage or display. RDF assumes an open world where metadata storage and maintenance is distributed and metadata content is intended to be shared rather than organized in closed data silos. This openness is essential if RDA is to break out of the confines of traditional library practices.
Expressing the RDA elements in a manner compliant with the Web Ontology Language (OWL) and the RDF Schema Language (RDFS) additionally supports the inferences so important in the RDF world, and allows RDA to benefit from the extensibility of the RDF model [OWL] [RDFS]. Likewise, value vocabularies in Simple Knowledge Organization System (SKOS), an RDF vocabulary built on OWL, allows those vocabularies to be used and extended by the communities with which RDA intends alignment. Use of SKOS also allows RDA to be better integrated with general developments in ontologies and knowledge organization that are important for improving user-centered information retrieval applications. RDF requires the use of machine-processable identifiers for structural and content entities. These identifiers are independent of human language considerations and allow RDA vocabularies to be translated into different languages without the need for different identifiers. This is a significant advantage for encouraging the use of RDA beyond the Anglophone community. Metadata expressed in RDF can be more easily processed to validate the semantics or truthfulness of its content without being entangled in the validation of its format or syntax, and is significantly different from the 'everyone must use the same schema' model of XML. This is important in an environment where increasing amounts of metadata are being generated by non-human or untrained human agents.
The work of the Task Group has also been informed by the RDA Database Implementation Scenarios developed by the RDA Editor (Tom Delsey) that illustrate how various database structures might implement RDA data [RDA Database Implementation Scenarios]. Three scenarios are described as: a relational or object-oriented database; a linked bibliographic and authority record database; and a flat file database. RDA is optimized for the first of these, where the database structure implements the conceptual models of FRBR and the Functional Requirements for Authority Data (FRAD) [FRAD]. This results in the metadata for a single resource being distributed across multiple records holding description and access data, with reduced duplication of data and better potential for re-use. The Task Group has assumed that this approach will be further developed, for example by treating the RDA value vocabularies as "authority files". This top-down decomposition of the monolithic catalogue record is compatible with a bottom-up aggregation of RDF statements.
But RDA needs to be compatible with current practices in order to encourage uptake, and the most prevalent database implementations in libraries today are those categorized by the linked bibliographic and authority record scenario best exemplified by Machine Readable Cataloguing (MARC). RDA attempts to be compatible with all three scenarios, but this hampers extension of the relational database scenario into a pure RDF representation of RDA, and has thrown up a number of challenges to the work of the Task Group.
Metadata Standards
In the past, the specific functions of metadata standards and their relationships to one another were not much discussed. Libraries generally enforced a monolithic approach to standards, where broad adoption of particular standards (AACR2 and MARC, in particular) was seen to be essential for efficient data sharing and interoperability. In those pre-XML days, a bespoke encoding and communication standard tied loosely to AACR2 made a great deal of sense, particularly in the early days when card production was the primary function of bibliographic data encoding.
The addition of new standards (some of them self-declared "standards" with minimal review by traditional standards bodies) created the need for some kind of categorizations of these efforts based on broad functions, in hopes of finding methods to explain their use to the newly confused. Steven Miller of the University of Wisconsin, Milwaukee, has perhaps gone furthest with this, defining a "Typology of Metadata and Cataloging Standards":
- Data Structure Standards (element sets; schemes, schemas, or schemata) (examples: Dublin Core, MODS, CDWA, VRA, [IEEE-]LOM)
- Data Content Standards (cataloging rules, input standards, best practice guides) (examples: AACR2, CCO, CDPDCMBP)
- Data Value Standards (controlled vocabularies, encoding schemes) (examples: LCSH, AAT, TGN, LCTGM, ULAN, W3CDTF, DCMIType)
- Data Format / Technical Interchange Standards (encoding standards for machine processing and interchange) (examples: XML, SGML, MARC)
- Data Presentation Standards (examples: ISBD punctuation, CSS and/or XSLT for display, OPAC display settings) [Miller]
The case could be made that MARC, given its relatively loose relationship with AACR2 and the importance of its structural documentation to the library cataloging world, operates both as a Data Structure Standard and a Technical Interchange Standard, although its own documentation emphasizes the latter as primary. Thomas Baker of DCMI argues that Dublin Core and the RDA Vocabularies occupy a missing category that he calls "Formal-Semantic Data Standards", given their common basis in RDF [Baker]. Librarians, and more specifically, catalogers, typically speak to one another in MARC tags, rather than AACR2 rule numbers, because their structural notion of the bibliographic record is based on the typical MARC tagged display. Although MARC has an XML expression, it is used by few systems except as an occasional output format useful as a precursor for other transformations [MARCXML].
Human users of most metadata standards generally have relied on textual documents, either traditionally printed, or, later, presented on the Internet in a document format using HTML or PDF. These documents were entirely intended for humans, and any corollary encoding instructions for the use of machine applications were made available separately, if at all. In MARC each application and each vendor system developed their own proprietary copies of the "MARC Standard" encoding, requiring sufficient resources to write and maintain code that contained each data element of the metadata scheme, along with rules for its use (such as "mandatory" or "repeatable" or "fixed length"). Maintenance was centralized and carefully controlled by the Library of Congress, under advice from the MARC Advisory Committee and the ALA inter-divisional committee known as MARBI [MARBI]. The process allowed vendors time to integrate new changes into their code prior to the date when the Library of Congress and OCLC (and formerly RLG, prior to its merger with OCLC) would begin using such changes in a bibliographic record exchange environment. Most other more recently developed Data Structure Standards, such as METS and VRA, followed the MARC approach to documentation and presentation of data elements and instruction, if not the open structure of its development and maintenance process [METS] [VRA].
RDA in RDF
A significant aspect of RDA is its use of the entity-relation (ER) model of FRBR. The use of ER models is a key component of the semantic web, but is entirely new in library cataloging rules. Revisions of RDA issued by the JSC over time provide evidence that the integration of FRBR and RDA caused the committee to rethink certain traditional concepts. It was clearly important that the development of RDA elements reflect the JSC's commitment to FRBR principles, although RDA's interaction with FRBR was not always developed in such a way that would translate directly to the corresponding RDF relationships. The DCMI/RDA group working on vocabulary development and registration needed to bridge that gap.
The interaction between RDA and FRBR meant that RDA in RDF would need to interact with an RDF-compatible treatment of FRBR, preferably one with official status. However, IFLA was unable to provide the FRBR entities with the requisite identifiers and RDF structure in a timely manner. In addition, the IFLA work on FRAD only recently reached completion. Therefore, to accomplish the creation of the RDA properties in RDF within the desirable timetable (so that the RDA guidance text and the vocabularies could be released together), it was necessary to create a transitional version of FRBR, preferably in the same registry as RDA. This RDA-specific version of FRBR includes "Family," from FRAD, and "Agent" from the object-oriented model of FRBR, and includes only the entity level, with the entities identified as classes and subclasses [FRBRoo]. Once the RDF version of FRBR is officially available from IFLA, relationships between the same classes in the RDA-defined version of FRBR and IFLA version of FRBR will be made to indicate that these are actually the same entities.
Making the connection between FRBR entities and the RDA properties was not straightforward. The first pass at defining the RDA elements as RDF properties attempted to assign each property to one and only one specific FRBR entity. There were significant concerns with this approach, not the least of which was that it limited all the RDA elements to only one possible view of how FRBR might be implemented in practice. Specialized communities with a different view of their and their users' needs would have no alternative other than to create new data elements (with different relationships to FRBR entities) to express their metadata. Studies by music librarians and audiovisual catalogers show that the definition of FRBR Group 1 entities is highly nuanced when dealing with different forms of creative expression [MLA BCC] [MIWLRTF]. There are, in addition, RDA elements that are tied explicitly in the RDA rules to one FRBR entity, generally by virtue of the inclusion of the entity in the name of the element. Examples of these latter are elements like "Identifier of the Manifestation" and "Language of the Expression."
Where there is no inherent FRBR entity assignment in the name of a property, two properties were created for the RDA elements: first, a general property with no explicit FRBR assignment; and second, a FRBR-bounded subproperty. The general property carries no specific association with a FRBR entity and can be used by any application that determines that it is useful in its context, whether or not the application is based on FRBR. These general properties are fully compatible with the Semantic Web and not specific to library applications. In addition, the general property can be used to extend RDA by associating the property at an application level with a different FRBR entity, other than the one chosen by the RDA developers.
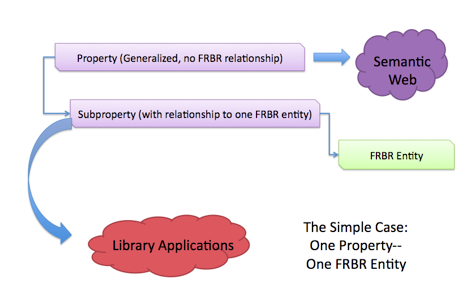
As an example, the property "Book format," which is defined in the RDA rules with a single FRBR relationship, appears in the Registry as a general property with no FRBR relationship defined, and again using the RDA definition of Book format with an explicit relationship to FRBR Manifestation. The addition of the FRBR relationship creates a property with a narrower definition, and therefore is defined as a subproperty of the more general, FRBR-less property.
The declaration of generalized properties that have subproperties with specific relationships to FRBR entities also accommodates the more complex case of elements that are associated with more than one FRBR entity in RDA. This approach, illustrated below, provides an attractive balance between the need to make it possible for users to adhere strictly to RDA specifications while also providing important flexibility for other community members without the need or desire to conform at that level.
In the structural illustration above, relationships with more than one FRBR entity can be accommodated, such as is the case with the RDA element "Extent," illustrated below:
The Entity Relationship Diagrams (ERDs) created for use with RDA Online were the main source for the RDA property definitions and their relationships to FRBR entities. Because the RDA Online product required a separate ERD for each entity, it is not clear from those ERDs which RDA elements are related to multiple entities. When elements and sub-elements appear multiple times in the ERDs, there is no indication that they might be repeated elsewhere, whether they carry the same definition, etc. The RDA properties in RDF make these relationships explicit through the property/subproperty relationship.
The availability of relationships between entities as described in FRBR is new to the library catalog rules, and is arguably the most innovative aspect of RDA. Some of the relationships are entirely new to library cataloging, such as relationships between Works. Other relationships, in particular the relationships of persons to Works and Expressions, have traditionally been expressed in library metadata as attributes of the person heading. In MARC, roles are attributes added on to names, such as "700 $a Smith, John, $e ed." This states that a person (700) named "Smith, John" ($a) is the ($e) editor of the resource. In RDF, the role would be a relationship, in the same way that a corporate body has the relationship "publisher" to the resource. Appendix I of the RDA final draft, covering the RDA Roles (relationships between FRBR Group 1 and Group 2 entities), treated these relationships differently from the other RDA relationships, possibly to better support mapping to MARC. This difference in approach was acknowledged by the authors of RDA in the Appendix I document itself:
"Based on earlier JSC instructions, particularly the editor's comments on the 'rules' of the RDF syntax and the DCMI Abstract Model, the following factors were used in compiling the draft list of roles:
- There should be no assumptions as to how the designations should be encoded (e.g., represented as "add-ons" as in MARC 21 relator terms or some other method), because RDA data should function independently of the format, medium or system used to store or communicate the data.
- To satisfy the RDF specifications and the DCMI Abstract Model, each designation of role must function as an element sub-type of one (and only one) of the higher-level elements defined in Chapter 6 (e.g., creator, originating body, contributor, etc.). If a given role is appropriate to more than one element, different designations must be made." [Tillett]
The DCMI/RDA vocabulary team based its approach to relationships in general on prior relevant work on roles done in 2005, when the Dublin Core Metadata Initiative and the Library of Congress collaborated to build a formal representation of the MARC Relators, allowing these terms to be used with DC [MARC Relators]. This earlier work provided a useful and fully vetted model for the basic development strategy for the RDA Appendix I role terms, as well as the other relationships in appendices J and K. All of the relationships are therefore defined as properties at the same level as the descriptive elements, rather than as attributes, as they are in MARC. This is one of the primary ways to ensure that the elements and vocabularies are compatible for use in RDF and with linked data as well as in XML.
However, in the ERDs some role terms were also given associations with the Dublin Core properties "Creator" and "Contributor," although RDA re-defined the DC properties somewhat. All terms associated with a "Creator" were also related to the FRBR entity "Work," but not all roles related to the FRBR Work entity were associated with "Creator." A similar pattern occurred with "Expression" and "Contributor." There were also other categorizations, for instance, the roles used with Work that were not related to Creator appeared under the category "Other person, family, or corporate body associated with the work." Although it wasn't difficult to see where the Creator/Contributor characterization might be useful in mapping those roles to MARC 1XX/7XX (the encoding tags for main entry and added personal name access points - main entry is another legacy from catalogue card days), the usefulness of the additional characterizations in an RDF-based element vocabulary is less clear, so those "other" categorizations were not included.
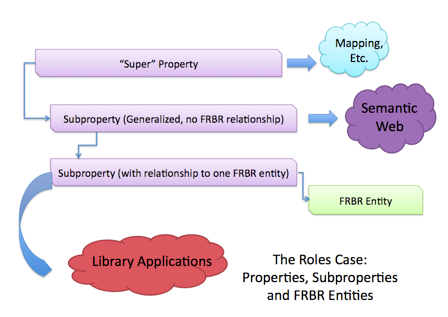
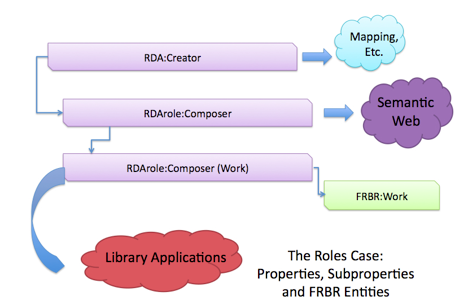
As an example, the role of "Composer" is listed as associated with "Creator" and would be related as below:
Relationships between Works, Expressions, Manifestations, Items (as expressed in the constituent review version of RDA Appendix J, though not in the ERDs) include the name of the FRBR entity in each property name. In that version and the ERDs, each of the Appendix J relationships carries separate definitions, usually reflecting a specific FRBR entity relationship. In the RDA vocabularies, relationships are structured, as are other RDA properties, with generalized properties extrapolated from the more specific named and FRBR-bounded properties, to accomplish a similar outcome. Because the relationships often contain up to three levels of hierarchy (and the hierarchies can vary between entities), generalized properties were created routinely at each level to allow the appropriate hierarchical levels to be maintained clearly both with generalized and bounded properties. For now, the generalized properties will not contain definitions, as the definitions appearing in the bounded subproperties use the FRBR entity as part of the definition, making the building of general definitions a task for later enhancement.
In the special case of the property "Name," the description is specifically related to the two FRBR(er) Group 2 entities "Person" and "Corporate Body" and the FRAD entity "Family." After some discussion the decision was made to accomplish this most efficiently by registering the FRBRoo class "Agent" in the "FRBR in RDA" vocabulary and making "Person," "Corporate Body" and "Family" subclasses of "Agent," allowing the relationship to be made at the "Agent" level without unnecessary duplication at the subclass level. For several of the properties that appear in each of the Group 2 ERDs, for instance "Note," "Source consulted," and "Status of identification," the Agent class is used to make the FRBR relationship, for similar reasons of efficiency, and the Group 3 properties are handled similarly. Some of these "efficiency" decisions were motivated by the view that these areas of RDA are not yet fully cooked, and as actual experience informs additional development, some of these decisions may be re-visited.
Aggregated Statements
RDA sets up Publication, Distribution, Manufacture and Production statements, and other pre-coordinated groupings of elements, very much the way they have been done since catalog card days. As an example, the pre-coordinated aggregation of Place of publication, Publisher's name and Publication date into a Publication Statement is an obvious leftover from catalog cards, and the aggregation of these elements provides value primarily as an option when text strings are used, as will likely be the case when MARC records are initially transformed into RDA. Other aggregations, such as Uniform titles, are viewed primarily as identification, and aren't included as specific aggregated statements in the vocabularies. These syntactic constructs provide tremendous value as formalizations of some of the string-based contents of some of the MARC21 fields. They're incredibly useful for defining the data that appears on a physical card in a card catalog. They make very nice semi-semantic containers in an XML representation of RDA data, and MARC21 data:
<Publication statement>
<Place of publication> Austin, TX </Place of publication>
<Publisher's name>The University of Texas at Austin, College of Liberal Arts </Publisher's name>
<Date of publication> [2001]- </Date of publication>
</Publication statement>
260 $a Austin, TX : $b The University of Texas at Austin, College of Liberal Arts, $c [2001]-
But unfortunately, given their composite nature, in an RDF context composite statements don't contribute much value to the description of the resource. This use of pre-coordination as an inherent part of the property definition had the unintended result of limiting the ability for others not interested in these pre-coordinated statements to use RDA properties outside of a library-flavored application. This concern was validated when the team was actually told by two Semantic Web developers that they wanted to use "Place of Publication" but couldn't because in our initial pass we had tied its use too tightly to the aggregated structure of Publication Statement. The ultimate solution was to provide both the ability to use the elements within the aggregations as well as separately, in part by explicitly defining the aggregations themselves as "Syntax Encoding Schemes, as defined in the Dublin Core Abstract Model [DCAM]:
As an example, Publication Statement is structured as below:

A significant part of the challenge of expressing a Syntax Encoding Scheme (SES) is the lack of a standard way of describing the syntax of an SES in the RDF data model — we can say that an rda:publicationStatementManifestation has a datatype of rda:PublicationStatementEncodingScheme but can't as easily declare the composition and ordering of the required strings. In addition, DCMI hasn't been explicit about associating the DC Abstract Model (DCAM) with OWL, although it is explicit about defining some very similar constraints. For instance, in order for an Ontology to be OWL-DL compatible it must explicitly declare whether the object of a triple is a resource (owl:objectProperty) or a literal (owl:datatypeProperty). The OWL specification does allow ambiguity, but at the cost of reduced compatibility with standard reasoners. The DCAM simply states that you must choose and your schema must not be ambiguous. A possible solution is illustrated below:
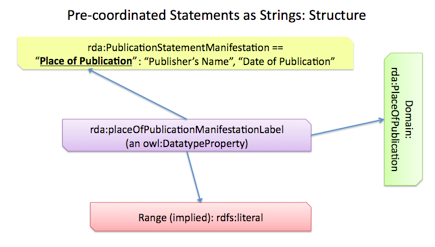
In this example we want Place of Publication to support the broadest possible range of bibliographic data, so we define it as an RDF Schema property rather than an OWL property and define no domain and no range — and this effectively becomes part of an 'upper-level' ontology, an ontology intended to be localized and extended to be most useful. We want to be OWL-DL and DCAM compliant though, so we create a manifestation-specific subproperty as an owl:objectProperty: 'Place of Publication (Manifestation)' with a domain of rda:Manifestation and an implied range of rdf:resource. This allows instance data to identify the place of publication using a URI rather than a literal. But this creates a problem for our SES, since by definition the Publication Statement SES consists of an ordered list of strings. We also have created a problem for those needing, because of legacy data, to identify the Place of Publication using a literal, but still wanting their ontology to be OWL-DL compliant.
To solve this we create a new owl:datatypeProperty — rda:PlaceOfPublicationManifestationLabel, that has an rdfs:domain of rda:PlaceOfPublication and an implied rdfs:range of rdfs:Literal. This property, when applied to a resource, will imply the existence of an unidentifed rda:PlaceOfPublication resource or, if provided as a property of an rda:PlaceOfPublication resource, it can then be used to provide a string literal to the Publication Statement SES.
Metadata Registration
The Dublin Core Metadata Initiative, begun by a group that included librarians but also a significant number of non-librarians, developed a metadata registry early on, where the official information about terms was made available [Wagner]. A public registry provides information about the metadata standard in a machine-actionable format, capable of integration into applications. Use of registered data elements increases the consistency of uses of the same metadata over a variety of services because all applications are built on the same machine-readable definitions. Despite its early foray into registries, DCMI never committed to the DCMI Registry as its primary source of information on the data elements and vocabularies, instead providing and pointing to HTML versions of the terms on the DCMI Website. Early in its history, DC's primary data encoding was HTML, but as XML gained traction (and later, RDF) Dublin Core metadata was actively promoted as usable in a variety of encodings, and a variety of XML schemas using DC are also available on the DCMI website [DC XML].
Metadata Registries have been a topic of discussion for over a decade, as the proliferation of metadata formats and the ideas of mixing and matching began to be discussed seriously. Duval described registries as having the "characteristics of an electronic dictionary, available for consultation by:
- Application designers, who will be able to consult registries to identify existing metadata schemas and schema components that might meet their needs or to identify extensions to those schema that other application designers have developed to meet a given local need.
- Creators and managers of metadata, who can consult a registry to ascertain the definition or usage statements concerning an element or the available or preferred candidate value sets to be used to populate particular elements.
- Applications, which can resolve URIs associated with a schema, an element, or a value set in order to compare or evaluate elements or their values in a set of metadata.
- End users, who might consult a registry to better understand definitions or context of metadata terms, and thereby improve their search or processing effectiveness." [Duval]
An effective metadata registry facilitates the declaration, management, and discovery of machine-readable metadata schemas, application profiles, and controlled vocabularies with much greater efficiency than simple human-readable documentation produced in a variety of layouts. Although three of Duval's categories of consultation involve humans, the fourth (Applications) requires machine-readable documentation. With registration the capabilities of interoperability increase many-fold, as does the accuracy of any sharing of data elements and vocabularies. Thus, registries provide the means to move toward a global information network with much greater interaction among information services.
A key aspect of a registry is that it can provide a unique identifier (URI) for each data element and for each member of a vocabulary as well as one for the vocabulary or element set as a whole. With registered elements and vocabularies, labels can be identified for different languages or different communities, though the identifier can remain the same. The registered identifiers allow the human-readable labels to vary while maintaining compatibility between applications using the metadata. Abstract or numeric URIs that don't contain a language-specific label can help maintain the language-neutral sense of the element or concept.
Public registration also allows anyone on the Internet to discover metadata elements that they may wish to use for their own purposes. These purposes may include verifying the structure of an instance record (a specific record for a bibliographic resource), extracting data from instance records, and developing cross-walks or mappings. Metadata strategies can be developed using a "mix and match" method that is commonly used in the XML environment. With this technology it is no longer necessary to create a single comprehensive metadata format for an application; instead, appropriate elements from existing vocabularies can be used together in a single metadata record. This technique is also used in Application Profiles (APs) or Description Set Profiles (DSPs), as defined by the Dublin Core community in its Singapore Framework [DC Singapore]. These techniques facilitate the use of elements from different vocabularies to build up the metadata structure that suits a particular application. Greater re-use of existing metadata vocabularies will save the time of application developers and will also result in greater potential for low-cost metadata exchange in the future.
Why Register RDA?
Possibly the most important service that the NSDL Registry has provided for the RDA vocabularies during the registration process is reliable change management. The Registry includes integrated change history and version management as part of its basic services, allowing vocabulary owners the ability to designate time-stamped or named versions of vocabularies at any time. This eases the maintenance burden for many vocabulary consumers seeking to limit or schedule changes to instance data [Hillmann]. The change history and version management capabilities of the NSDL Registry were built based on research by ontology experts Dr. Joseph Tennis and Dr. Stuart Sutton [Tennis]. Tied to the change management functionality is a flexible notification system, now available only in a basic RSS format but planned to evolve into a user configurable set of choices that can allow RDA users to manage their local systems rationally on their own schedule, regardless of the maintenance process developed for RDA.
The Registry also provides easy discoverability of elements and concepts in RDA and in other vocabularies. Within the Registry there are evolving tools to allow users to build application profiles and extension vocabularies, as well as to support communities around these vocabularies. Upon registration, vocabularies are immediately available in a variety of syntaxes to serve a number of important functions. XML schemas of the entire vocabulary are available at any time for the purposes of validation and are updated in real time within the Registry software. RDF ontologies at the vocabulary or term level are also available in real time, making updates available immediately and supporting the semantic consistency required in most environments. The Registry's vocabulary development support includes simple import and export of vocabularies (support of external round-trip editing is planned), managed discussion capability at the individual element, term or statement level, and customer service support through GetSatisfaction.com (accessed via a feedback button on every Registry page).
The Challenges of RDA Registration
Registration of the RDA elements and vocabularies posed some particular challenges; some due to the unfinished state of RDA, and others because RDA was initially developed with neither RDF nor a rigorous registration process in mind. The registration process was started while the text and element set of RDA was still in flux and the only version of the vocabularies was contained in a spreadsheet built by the RDA Editor. The NSDL Registry had only recently implemented registration of element sets when registration of the RDA element vocabularies began, and the availability of "how-to" documentation required to develop RDF vocabularies in the context of a standard like RDA was very limited.
Most elements and vocabulary concepts were updated at least once as the vocabularies continued to develop and new lists were issued. Some term names flip-flopped several times ("Title of Work" vs "Title of the Work" holds the record). The fact that revised documentation emerging from JSC processes did not specifically record what had changed and what had been deleted made the development of quality control processes far more difficult. Any gaps in the DCMI/RDA team's appreciation of the value of versioning have been filled during the experience of a few rounds of RDA edits.
An advantage in starting the process before the text was completed, however, was that important issues were encountered at early stages and thus solutions could be discussed with librarians and semantic web experts prior to registration. Particularly problematic was the need to create relationships between RDA elements and FRBR entities — this stretched the team's creativity and knowledge significantly (particularly of RDF vocabulary standards), and there were a few false starts. Passing through the registered vocabularies repeatedly during the revisions to the text allowed for error checking on each pass, and also provided a good test of the registry software. Some changes were made in the Registry's element registration strategy based on RDA registration needs. As a result, the Registry software has matured and stabilized as RDA registration has proceeded.
Given that one important JSC goal for RDA specifies that the standard be usable beyond the library community, a major aim of the RDA registration has been that the registered elements and concepts would be available for use in applications using either XML or RDF, and potentially in other encodings in the future. Supporting these two disparate standards has required extra care in building the vocabularies and relationships, and help from the Semantic Web Community has been needed to accomplish these important goals in a flexible and functional manner. In order to signal Registry users that the RDA vocabularies are not yet "cooked," the status of all RDA registered elements and concepts are current set to "New—Proposed". Discussions are ongoing concerning the timetable and particulars for moving from "New—Proposed" to "Published".
Why Is All This Important?
Doing this work in parallel with the development of the RDA text was an enormous challenge, but its completion puts the library community in the position to move forward quickly into the broader world of information exchange and reuse outside the library silo created over the past 40 years. The RDA Elements and Vocabularies provide the basis for migrating from exclusive use of MARC, which is relevant only within libraries, to something that the broader information community can understand, interpret, and use. Recent discussions on several library lists point to the reality that large consumers of bibliographic metadata like Amazon and Google Books have used MARC data in ways that betray a certain lack of understanding of traditional library metadata, a situation that is unlikely to change so long as libraries rely exclusively on MARC.
But the benefit of using a modern and fully registered standard is not only to others — library reliance on data standards that require that all data be created by hand by highly trained individuals is clearly unsustainable. In a recent presentation to an audience at ALA Annual in Chicago, Jon Phipps demonstrated that continued library use of a standard only we understand has cut us off from reuse of data being built exponentially by entities such as DBpedia, which are clearly, for a host of reasons, choosing not to access and reuse library data [Phipps] [DBpedia]. Only by changing what we do in library environments can we hope to participate with other large users of data in building better descriptive data that we can then hope to reuse to improve our own services.
Other communities are watching how we meet these challenges, and how well we move forward to meet the potential of a future more open and less reliant on old assumptions. Cultural heritage institutions, publishers, and other communities with which libraries interact are facing similar challenges. If libraries can make this leap, we will be in a good position to help those communities do the same, to the benefit of all of us.
Notes
(1) RDA is now scheduled for release in June 2010. The RDA Element and Value Vocabularies are available for viewing and use at: http://metadataregistry.org/rdabrowse.htm.
References
[Baker] Baker, Thomas. Private email to the authors, December 9, 2009.
[CILIP-BL Committee on RDA] CILIP-BL Committee on RDA. Available at: http://www.slainte.org.uk/aacr/index.htm.
[DBpedia] DBpedia. Available at: http://dbpedia.org/About.
[DCAM] Dublin Core Abstract Model. Available at: http://dublincore.org/documents/abstract-model/.
[DCMI] Dublin Core Metadata Initiative. Available at: http://dublincore.org/.
[DCMI/JSC Meeting] Data Model Meeting, British Library, London, 30 April-1 May 2007. Available at: http://www.bl.uk/bibliographic/meeting.html.
[DCMI/RDA TG] DCMI/RDA Task Group Wiki. Available at: http://dublincore.org/dcmirdataskgroup/.
[DCMI Glossary] Available at: http://dublincore.org/documents/2001/04/12/usageguide/glossary.shtml.
[DC Singapore] The Singapore Framework for Dublin Core Application Profiles. Available at: http://dublincore.org/documents/singapore-framework/.
[DC XML] XML schemas to support the Guidelines for implementing Dublin Core in XML. Available at: http://dublincore.org/schemas/xmls/.
[Duval] Duval, E., Hodgins, W., Sutton, S., Weibel, S. L. "Metadata Principles and Practicalities," D-Lib Magazine, Apr. 2002. Available at: doi:10.1045/april2002-weibel.
[FRAD] [free online version to be published early 2010].
[FRBR] Functional Requirements for Bibliographic Records. Available at: http://www.ifla.org/en/publications/functional-requirements-for-bibliographic-records.
[FRBRoo] FRBRoo Introduction. Available at: http://cidoc.ics.forth.gr/frbr_inro.html.
[Hillmann] Hillmann, D.I., Sutton, S.A., Phipps, J., Laundry, R. "A Metadata Registry from Vocabularies UP: The NSDL Registry Project." Paper presented at the Dublin Core International Conference, 2006. Available at: http://arxiv.org/abs/cs/0605111.
[IEEE-LOM] IEEE Learning Object Metadata Standard. Available at: http://ltsc.ieee.org/wg12.
[JSC] Joint Steering Committee for Development of RDA. Available at: http://www.rda-jsc.org/rda.html.
[MARBI] MARC Development. Available at: http://www.loc.gov/marc/marbi/marcadvz.html.
[MARC Relators] Discussion available at: http://dublincore.org/documents/usageguide/appendix_roles.shtml.
[MARCXML] MARC 21 XML Schema. Available at: http://www.loc.gov/standards/marcxml/.
[METS] METS: Metadata Encoding & Transmission Standard. Available at: http://www.loc.gov/standards/mets/.
[Miller] Metadata and Cataloging Online Resources: Selected reference documents, web sites and articles. Compiled by Steven J. Miller, University of Wisconsin-Milwaukee School of Information Studies. Available at: http://www.uwm.edu/~mll/resource.html.
[MIWLRTF] Moving Image Work-Level Records Task Force. Available at: http://www.olacinc.org/drupal/?q=node/27.
[MLA BCC] The Music Library Association's Bibliographic Control Committee. Final Report of The BCC Working Group on Work Records for Music. Available at: http://www.musiclibraryassoc.org/BCC/BCC-Historical/BCC2008/BCC2008WGWRM1.pdf.
[NSDL Registry] NSDL Registry. Available at: http://metadataregistry.org.
[NSDL RDA] NSDL Registry, RDA Browse page. Available at: http://metadataregistry.org/rdabrowse.htm.
[OWL] Web Ontology Language. Available at: http://www.w3.org/TR/owl-features/.
[Phipps] Phipps, Jon. "Embracing the Chaos," Presentation at Ex Libris panel "Continuing the Conversation: A Further Exploration of the Brave New World of Metadata, July 11, 2009. Available at: http://www.slideshare.net/jonphipps/embrace-the-chaos.
[RDA Database Implementation Scenarios] Available at: http://www.rda-jsc.org/docs/5editor2rev.pdf.
[RDA prospectus] Available at: http://www.rda-jsc.org/rdaprospectus.html.
[RDF primer] Available at: http://www.w3.org/TR/rdf-primer/.
[RDFS] RDF Vocabulary Description Language 1.0: RDF Schema. Available at: http://www.w3.org/TR/rdf-schema/.
[Statement of ICP] Statement of International Cataloguing Principles. Available at: http://www.ifla.org/publications/statement-of-international-cataloguing-principles.
[Tennis] Tennis, J. and Sutton, S.A. "Extending the simple knowledge organization system for concept management in vocabulary development applications" (Journal of the American Society for Information Science and Technology, Volume 59 Issue 1, Pages 25 - 37).
[Tillett] Tillett, B. "Designation of Roles in RDA." Memorandum to the Joint Steering Committee for Development of RDA, Feb. 5, 2008. 5JSC/LC/11 Available at: http://www.rdaonline.org/constituencyreview/Phase1AppI_10_27_08.pdf.
[VRA] VRA Core 4.0. Available at: http://www.vraweb.org/projects/vracore4/index.html.
[Wagner] Wagner, H. and Weibel, S. "The Dublin Core Metadata Registry: Requirements, Implementation, and Experience." Available at: https://journals.tdl.org/jodi/article/viewFile/70/73.
[W3C] World Wide Web Consortium. Available at: http://www.w3.org.
About the Authors
 |
Diane Hillmann is currently Director of Metadata Initiatives at the Information Institute of Syracuse and Partner at Metadata Management Associates. She has worked in libraries and digital libraries for 40 years, including (prior to her recent retirement) 30 years at Cornell University Library in various capacities, including law library technical services manager, authorities librarian, manager of the library's MARC database, and Project Manager and Director of Library Services and Operations for the National Science Digital Library Project at Cornell. She is editor of "Using Dublin Core," a member of the DCMI Advisory Board and program co-chair for DC-2010. She edited (with Elaine Westbrooks) "Metadata in Practice," published by ALA Editions (2004).
|
 |
Karen Coyle is a librarian with nearly 30 years experience in digital libraries. She worked for over 20 years at the University of California, most recently for the California Digital Library, and is now a consultant on digital library technology. She has written and lectured on many technical issues, such as metadata and information retrieval, as well as social, political and policy issues that affect libraries.
|
 |
Jon Phipps is Lead Scientist for Internet Strategies at JES & Co. and a partner in Metadata Management Associates in Ithaca, NY. He was most recently the Lead Engineer and Principal Investigator of the NSDL Metadata Registry, continuing to manage and maintain that project. He was the Technical Lead of the National Science Digital Library (NSDL) Core Integration group at Cornell University, and an Invited Expert on the W3C Semantic Web Deployment Working Group where he was a co-editor of the SKOS Use Cases and Requirements document and a co-editor of the revised Best Practice Recipes for Publishing RDF Vocabularies. He is a member of the Dublin Core Metadata Initiative Advisory Board and co-chair of the Registries Community.
|
 |
Gordon Dunsire is Head of the Centre for Digital Library Research at Strathclyde University in Glasgow, Scotland. He is a member of the CILIP-BL Committee on RDA and the CILIP Committee on DDC, and is Chair of the Cataloguing and Indexing Group in Scotland. He is co-Chair of the DCMI RDA Task Group and a member of the FRBR Review Group. His research interests include collection-level description, metadata interoperability and wide-area resource discovery.
|
|