|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Stefaan Ternier(2), David Massart(3), Alessandro Campi(1) (1) Politecnico di Milano (POLIMI), Italy |
![]()
AbstractWith the worldwide adoption of the Internet as a ubiquitous platform for exchanging information, new opportunities are available for sharing educational experiences and material. Thousands of institutes worldwide offer access to courses, lessons, seminars, and exercises, typically stored in repositories and offered to users under a variety of formats. Due to their educational nature, these contents are often referred to as Learning Objects. This article describes the "ProLearn Query Language", a query language that we have developed for repositories of learning objects. PLQL is primarily a query interchange format, used by source applications (or PLQL clients) for querying repositories (or PLQL servers). In defining PLQL, we have combined exact search, used for selecting learning objects by means of queries on their metadata, and approximate search, used for locating learning objects by means of keyword-based search. A query in PLQL contains both "exact clauses" and "approximate clauses", where each clause is syntactically well-defined; exact clauses match keywords against metadata with a known structure, while approximate clauses match keywords freely, either against metadata or against indexes based upon the documents' contents. In this article, we give a precise description of the semantics of PLQL, concerning both kinds of clauses and their mutual relationship and describe two experimentation efforts around PLQL: one involving the ARIADNE repository and the other the EUN Learning Resource Exchange initiative. 1 IntroductionThe IEEE Learning Technology Standards Committee [1] defines a learning object as "any entity, digital or non-digital, that may be used for learning, education or training". Over the last decade, a substantial industry and research community has developed around the notion of such reusable learning objects, addressing a wide variety of contexts including training, schools and academia. A crucial problem faced by the learning community is how to produce and deliver quality content for online learning experiences. Thousands of educational institutes worldwide offer access to their learning objects. By improving share and reuse of learning objects, the cost of creating them declines. A first problem to address is that of finding the most useful learning objects for performing a given educational task. For this purpose, learning objects are collected within dedicated repositories that can be accessed by query and search engines. Every learning object can be tagged with metadata, which is descriptive information that allows the learning object to be found easily. Figure 1 depicts an example of a learning object together with associated metadata. The most relevant standards for describing learning objects are LOM, Dublin Core, and MPEG-7.
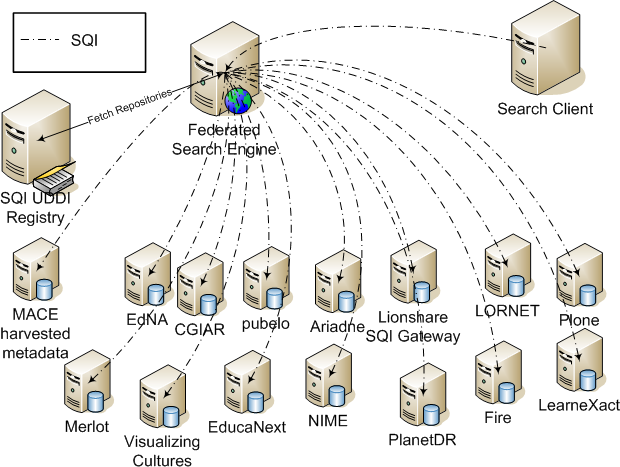
The IEEE Learning Object Metadata (LOM) [1] is a hierarchical metadata standard usually encoded in XML, published by the IEEE in 2002. Its purpose is to enable the description of learning objects through attributes that include the type of object, author, owner, terms of distribution, and format, as well as pedagogical attributes, such as typical learning time or interaction style. LOM is based on early work in ARIADNE [3] and IMS [4]. Dublin Core (DC) [5] is a standard for generic resource descriptions. The simple DC metadata element set consists of 15 elements, including title, creator, subject, description, publisher, contributor, date, type, format, identifier, source, language, relation, coverage, and rights. MPEG-7 is an ISO/IEC standard for describing multimedia content. MPEG-7 Multimedia Description Schemes (DSs) are metadata structures in XML that facilitate searching, indexing, filtering, and access [24]. Learning objects in repositories are usually described by metadata. Therefore, access to learning objects can take advantage of queries upon metadata for selecting the objects that are most suited to the needs of learners or teachers. In addition, many learning objects include textual material that can be indexed, and such indexes can also be used to filter the objects by matching them against user-provided keywords. This article describes PLQL, a proposal for a simple query language standard for retrieving learning objects from heterogeneous repositories. PLQL is primarily a query interchange format, used by source applications (or PLQL clients) for querying repositories (or PLQL servers). PLQL has been designed with the goal of effectively supporting search over LOM, DC and MPEG-7 metadata. However, PLQL does not assume or require these metadata standards. Figure 2 shows an example of an architecture, set up within the GLOBE initiative, interconnecting several networks of learning object repositories. Clients direct queries to a federated search engine, which in turn forwards the query to a number of repositories and returns the answer to the client.
The work presented in this article builds on previous standardization work in the area of technology-enhanced learning. The CEN/ISSS Simple Query Interface (SQI) [7][15] specifies an abstract search protocol that can be bound to various technologies and has been designed to support external query languages and metadata standards. The SQI protocol builds the software interconnections represented in Figure 2 and enables the transferring of a query from a client to a server, but it does not include a query language. Therefore, the interaction between a client and a server takes place by using a query language agreed between each client-server pair. PLQL aims to be the query language of choice in this context. 2 Definition of PLQLPLQL is based on existing language paradigms, and aims to minimize the need for introducing new concepts. Specifically, we have borrowed approximate search concepts from Contextual Query Language (CQL) [13], a well-established language used for library search. Given that an XML binding is available for all relevant metadata standards for learning objects, we have also decided to express exact search by using query paths on hierarchies, borrowing concepts from XPath [18]. Thus, PLQL combines two of the most popular query paradigms, allowing its implementations to re-use existing technology from both fields: approximate search (using information retrieval engines such as Lucene) and exact search (using XML-based query engines). The result of a PLQL query is normally a set of URI's pointing to documents, possibly augmented with meta-information describing them; the actual retrieval of each document is a task that should be performed by the PLQL client. If the query includes approximate clauses, then the result is an ordered set; ordering of result URI's is determined by the PLQL server and takes into account approximate clauses. The implementation of PLQL can therefore use existing technology for both exact search (using, e.g., XML-based or relational database technology) and approximate search (using, e.g., information retrieval engines such as Lucene). Language implementations consist primarily of translators of the two kinds of clauses to the corresponding engines, because the adopters of PLQL are not concerned with "query optimization". In designing PLQL, we have also aimed at allowing very simple repositories to support at least a subset of the functionalities. Thus, one of the main concerns of the language design was to provide progressive levels with increasing expressive power. This permits different repositories to support PLQL levels according to their specific capabilities. The structure of the result returned by a PLQL query is defined similarly. We next present the current specification of PLQL, which introduces three query levels and four query result levels. For each level, we present the syntax and the semantics, and we provide the motivations that have led us to introduce the level. 2.1 Query LevelsInitially, the SQI initiative was bootstrapped using an extremely lightweight query language. This query language was the minimum common denominator in terms of the search features all the partners had in common: an approximate keyword-based search. Integrated as level 0 of PLQL, this query language enables a low cost of adoption. Unfortunately, however, its expressive power is not always sufficient. Although we envision that more levels will be required (and some query language features have already been classified according to a level hierarchy which goes up to 5), only the levels 0-2 have been defined in detail, as they serve the needs of the repositories that we have considered so far. The remaining three levels may be detailed in future versions of the specification. 2.1.1 Level 0As previously mentioned, level 0 mainly covers simple conjunctive approximate search. Search terms must match the metadata or the textual content of the learning objects themselves. All the search terms must be matched for the object to be selected. The implementation of ranking is delegated to the repository being searched. If no ranking method is explicitly specified by the PLQL client, ranking can be based on the relevance of keywords. Notice that level 0 is absolutely metadata schema independent. This is obviously a limitation in expressive power, but it introduces clear advantages in federated searches, since no mediation is necessary. Syntax The syntax is defined by the following Backus Naur Form productions:
0-1: PLQLQuery ::= approximateClause Level 0 is identified by the following URI: http://www.prolearn-project.org/PLQL/l0. The Simple Query Interface offers a setQueryLanguage method through which a source can set the language and level of the queries it will submit. With this URI, a PLQL client can indicate that a PLQL level 0 will be submitted. Examples The following are valid examples of level 0 queries.
"ship" 2.1.2 Level 1As previously mentioned, the expressive power of level 0 is not always enough. Communities such as EUN, delivering quality content to schools all over Europe, expressed a strong need for extending queries with the ability to specify selection criteria based on the language of the learning object and the age range for which it is targeted. Authoring applications, such as the ALOCOM [9] plug-in for MS-office, required the ability to select content based on the document type (e.g., slide, slide set, image, diagram, etc). These and other simple extensions are tackled by PLQL level one. Since many metadata schemas are hierarchical structures, level 1 introduces the notion of paths (separated by dot '.' symbols) for navigating them. Level 1 also assumes that metadata will be either of LOM, DC, and MPEG-7; therefore, the path's root can only be one of the following: 'dc', 'lom', and 'mpeg-7'. Level 1 mixes exact and approximate search criteria. Therefore, we need to clarify the semantics of having both in the same query. Exact clauses are executed first to produce a result set, which is then pruned by executing the approximate clauses. The latter are also responsible for the ranking of results. When the exact clauses do not match any metadata, an error code is returned to the query designer, who can accordingly modify the query being issued. However, we also allow designers, when they are defining the query, to specify an alternative behavior for those times when exact clauses do not match any metadata. Designers can require that, in such a case, the exact clauses be transformed into approximate query keywords. If this happens, a special code is returned, so that the designer can know that these alternative semantics have been used. Level 1 only supports conjunction, meaning that all exact clauses need to be considered. Moreover, we only allow the equality predicate for exact clauses. Both level 0 and 1 allow for clauses to be surrounded by parentheses. Note that in these two levels, their use cannot change the semantics of a query. Syntax Notice that the definition inherits already existing productions from PLQL level 0. If we present a new production rule with the same number as an earlier production, the old one is replaced by the new one.
1-1: PLQLquery ::= clause Level 1 is identified with the following URI: http://www.prolearn-project.org/PLQL/l1. Examples The following queries are valid level 1 PLQL queries.
lom.general.title = "ship" and lom.general.language = "en" 2.1.3 Level 2Level two of PLQL takes into account the hierarchical nature of Learning Object Metadata. Query Languages such as CQL, work well for flat metadata schemas, such as DC, but they fail at exploiting the hierarchic features of LOM or MPEG-7. These changes introduce new expressiveness both in the exact clauses and in the approximate ones. For exact clauses, level 2 makes it possible to use disjunction and all the conventional comparison predicates, and not just conjunction and equality as in level 1. In addition, path expressions can now use parentheses. This allows traversing the hierarchical structure to stop at given nodes and express criteria on several of the descendants. Level 2 is also open to arbitrary namespaces beyond 'lom', 'dc', and 'mpeg-7'. For approximate clauses, we introduce the use of the 'exact' symbol to indicate exact string matching. Syntax Once again, already defined productions are replaced by new ones that have the same production number.
2-1: PLQLquery ::= clause Level 2 is identified with the following URI: http://www.prolearn-project.org/PLQL/l2. Examples The following queries are correct level 2 PLQL queries.
lom.general.(title.langstring.string = "ship" and (language = "de" or language = "en")) 2.2 Query Result LevelsBesides the query format to be exchanged, we also need to agree on the results format in order to complement the SQI protocol and achieve full search interoperability between learning object repositories. The current PLQL specification defines four levels of query result formats with increasing levels of detail, ranging from a format that only includes the number of results, to a format with detailed specific metadata regarding these results. When issuing a PLQL query through SQI, the designer is required to specify the desired result level. In addition, the designer can also specify two optional parameters:
The four levels are defined incrementally as follows:
Syntax The Backus Naur Form definition follows:
1: PLQLRES ::= 'http://www.prolearn-project.org/PLRF/' level ['/' standard '/' method ] Result example In the following example, the query has returned a level 3 result using the 'lom' metadata standard. This is indicated by the URI: http://www.prolearn-project.org/PLRF/3/lom, where 3 indicates the level and 'lom' indicates the selected standard. The result is bound in XML. <?xml version="1.0" encoding="UTF-8"?><Results xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.prolearn-project.org/PLRF/ http://www.cs.kuleuven.be/~stefaan/plql/plql.xsd http://ltsc.ieee.org/xsd/LOM http://ltsc.ieee.org/xsd/lomv1.0/lom.xsd" xmlns="http://www.prolearn-project.org/PLRF/"> <ResultInfo> <ResultLevel>http://www.prolearn-project.org/PLRF/3/lom</ResultLevel> <RankingMethod>NrOfDownloads</RankingMethod> <QueryMethod>http://www.prolearn-project.org/PLQL/l1</QueryMethod> </ResultInfo> <Record position="1" rankingValue="80"> <Metadata> <lom xmlns="http://ltsc.ieee.org/xsd/LOM"> <general> <title> <string language="en">ship</string> <string language="nl">boot</string> </title> </general> <technical> <location>http://en.wikipedia.org/wiki/Image:Bateaugoelette.jpg</location> </technical> <classification> <keyword> <string language="en">schooner</string> <string language="nl">schoener</string> </keyword> </classification> </lom> </Metadata> </Record> </Results> 3 Implementation of PLQLPLQL was designed in a way that allows for easy mapping to various paradigms for metadata management. So far, we have mapped PLQL to Lucene, XQuery, and SQL. Apache Lucene is an important deployment context for PLQL as this open source toolkit for text indexing and searching is widespread and easy to use. XQuery is the W3C recommendation for querying XML data; with this mapping, all PLQL levels can be mapped and executed on XML database systems. All mappings were done following the same principles: For each level of PLQL, flex technology was used to generate a lexer that maps a PLQL input stream to tokens. These tokens are to be interpreted by a yacc parser that closely follows the structure of the PLQL statements. A yacc parser is usually generated from yacc rules that define the legal sequences of tokens in a language. Every BNF statement corresponds to a yacc rule that maps the statement to a concrete query. 3.1 Mapping to LuceneLucene queries apply to documents that contain one or more fields, where every field is a name-value pair. For a given LOM instance, a list of name-value pairs can be easily generated by using XML path expressions as names. Table 1 illustrates how the simple LOM instance, depicted in Figure 1, is mapped to a Lucene document:
This serialization into Lucene documents is straightforward; hence, setting up a Lucene index of metadata for use in PLQL is very easy. 3.2 Mapping to XQueryMapping PLQL to XQuery requires generating suitable expressions, as suggested by the following examples in Table 2:
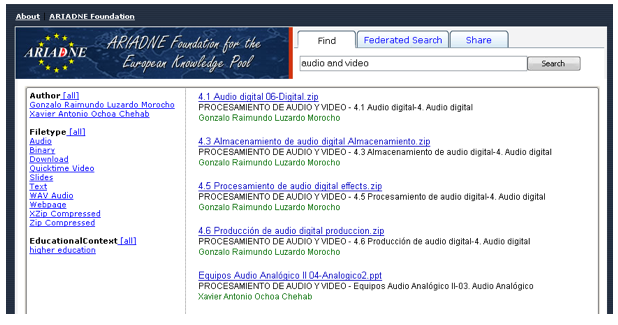
4 PLQL Experimentation4.1 PLQL in ARIADNEThe ARIADNE repository toolset features a metadata store component that exposes its functionality through web services [19]. We have implemented an SQI interface with support for PLQL on this metadata store, integrating the previously discussed mappings. A Lucene index offers support for PLQL level 0 and 1, while PLQL level 2 support is offered through XQuery. Currently, both IBM DB2 and eXist, an open source project, are supported for executing XQuery statements. The ARIADNE query and indexing tools enable the sharing and reuse of learning objects. Through PLQL, this tool now supports faceted search. A search box enables a PLQL level 0 search to be expressed. Once results have been retrieved, the user can, for instance, select the "higher education" facet, which will result in the PLQL level 0 query being rewritten as a level 1 query. For example, a PLQL query like "Ship" can be refined in this way to: "Ship" and lom.educational.context = "higher education" As a result of integrating PLQL and SQI in this query tool, the tool can now be reused in a loosely coupled fashion with other learning object infrastructures that implement the same specifications. Through this experience, we learned that some features are not supported by PLQL. For instance, faceted search gives a better user experience when a tool displays the amount of results per facet. Future work will focus on profiling the PLQL results so that this facet information can be returned as part of a response.
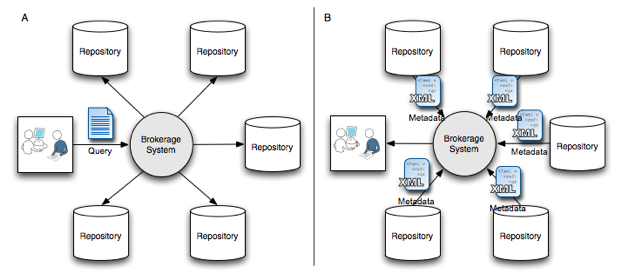
OAI-PMH [23] is a protocol for metadata harvesting (i.e., selecting metadata records from repositories based upon their identity, the date of their last modification, and their membership in predefined sets). As suggested by Sanderson et al. [10], we implemented an OAI-PMH component that builds on SQI and PLQL. The implementation requires a target to support a minimal LOM metadata application profile with mandatory support for lom.general.metaMetadata.identifier and lom.metaMetadata.contribute. Support for the identifier is necessary for implementing the OAI-PMH getRecord method that retrieves a record, using the record identifier. Selective harvesting in OAI-PMH requires datestamps to be available in the metadata. When harvesting all records that have been modified between two dates, all records are selected that have the contribute element with role "creator" and a date that falls within the specified range. Optionally, support for OAI-PMH sets can be mapped to a classification structure or to other LOM metadata fields. Furthermore, the minimal LOM application profile requires the number of contribute metadata elements in the lifecycle category of LOM with role "creator" to be exactly one. Doing so, a date-stamp based OAI-PMH request can be mapped to queries with the following structure: lom.metaMetadata.contribute.(role = "creator" 4.2 PLQL in the EUN Learning Resource ExchangeThe Learning Resource Exchange (LRE) is a pan-European federation of learning resource repositories [12]. It provides the means to unlock the educational content hidden in digital repositories across Europe and share it among all partners of the LRE and their users. The service is offered to actors providing digital content: ministries of education, regional educational authorities, commercial publishers, broadcasters, cultural institutions and other non-profit organizations offering extensive but heterogeneous catalogues and repositories of online content to schools. From a technical standpoint, the LRE consists of a brokerage system [14] to which independent systems (e.g., learning resource repositories, educational portals, learning (content) management systems, learning resource repositories) connect to share learning resources in a federated way. The LRE repositories are heterogeneous. They were designed independently and rely on very different technologies to manage descriptions of learning resources (e.g., relational databases, XML databases, object databases, file indexes, and other ad hoc solutions). The LRE aims at federating these repositories by providing a uniform access to their content through federated searching.
A federated search consists of an educational portal end-user (e.g., a teacher or a pupil) querying all the metadata repositories available on the LRE for references of learning resources matching the search criteria. The portal sends users' queries to the brokerage system that propagates the query to all the repositories of the federation (Figure 4A). The repositories process the query and return the results to the brokerage system that then forwards the results to the system that originally sent the query (Figure 4B). During LRE federated searches, interoperability is achieved by using the simple query interface (SQI) [15] in combination with PLQL and the LRE Metadata Application Profile (LRE-AP) [16], an application profile of the IEEE Learning Object Metadata [1] adapted to the context of primary and secondary schools in Europe. The LRE-AP consists of a conceptual schema (named information model) from which different bindings can be derived (e.g., an XML schema, a relational schema). The LRE-AP conceptual schema is used as an LRE federated schema that can be referred to when querying the federation. Its XML binding is used as an exchange format for learning resource descriptions (i.e., query results). PLQL was chosen as the LRE query language for its ability to express queries as arbitrary constraints on the LRE-AP conceptual model, including the 12 basic query types (and their Boolean combinations: and, or, not) identified by LRE teachers and pupils as necessary to support their learning discovery activities. These 12 queries consist of searching for resources:
Among them, queries 1, 2, and 10 can be expressed in PLQL layer 1 whereas the other ones require level 2. Until now, the LRE has been primarily developed within the CALIBRATE and MELT projects with support from the European Commission's IST and eContentplus programs. During the summer of 2007, PLQL and the LRE Context Set were implemented by most of the federation repositories. At the time of writing (November 2007), the language is supported by:
This represents a total of approximately 65,000 learning assets and resources that can be searched (using PLQL) by teachers and pupils across Europe. 5 Related WorkQuery LanguagesCQL (the Contextual Query Language) was an important starting point for our work on PLQL. Although we have borrowed many concepts, the approaches differ in some key aspects. CQL is a congress initiative often used in combination with the SRU/W search protocol for library search. Its objective was to offer a very expressive query language that would still be human readable and writable. With respect to PLQL, CQL does not treat hierarchical metadata structures, since they are not so important in the field of library search, where flat metadata schemas are mostly used. Commonly used metadata structures are Dublin Core [5], MARC [20], and Zthes [2]. Another difference is in result presentation. While CQL adopts result sorting based on metadata fields, PLQL offers more complex ranking features that are not bound to specific fields. However, ranking can be implemented in CQL if a metadata field contains a ranking value. QEL (the Query Exchange Language) [21] is an RDF query language that is expressed using Datalog syntax [22]. It has been implemented in the Edutella network, a P2P network that provides search interoperability between learning object repositories. Like PLQL, QEL is a metadata schema independent language. Since it is based on Datalog the language simply returns variable bindings that match an RDF subject, predicate, or object. This differs from PLQL, which is designed to retrieve metadata instances rather than partial results. Worldwide LOM RepositoriesPLQL is the result of a long stream of research. A fundamental step in this research was the ARIADNE initiative [3][19] that resulted in a network of learning repositories, based on a three-tier architecture:
Considerable work has been devoted to increase the interoperability between ARIADNE and other Learning Object Repositories that rely on IEEE LOM. To achieve this goal, the ARIADNE metadata profile has been mapped into the LOM standard, itself based on an early version of the ARIADNE metadata schema. Since 2004, the GLOBE initiative has been established to interlink networks of learning object repositories worldwide, so as to make all learning resources available to everyone, at a global scale. The GLOBE network relies on SQI and LOM for the interconnection of the networks of repositories, using a hybrid approach based on harvesting and federated search. 6 ConclusionsThis article presents PLQL as an emerging standard for querying worldwide, heterogeneous learning object repositories. This work has followed on the heels of previous achievements in defining SQI (the Simple Query Interface), a unified access point to distributed and heterogeneous repositories. PLQL is a "query interchange format" accommodating the great diversity of the different repositories and their capabilities. PLQL combines exact and approximate search, and supports queries on XML-based hierarchical metadata. Our objective of supporting even very simple implementations has led us to define incremental PLQL levels, with increased expressive power from one level to the next. Moreover, we have also provided a detailed query result format. In order to achieve lasting impact with PLQL, we will combine the following approaches:
We believe that this presents an important step forward for the learning technology community, as it completes the set of basic building blocks (that also includes SQI and LOM) and thus creates the opportunity for a global open learning infrastructure – an opportunity that can unleash the learning potential of a massive un-served (or under-served) community worldwide. AcknowledgementsThe authors would like to acknowledge: funding assistance of the ProLearn Network of Excellence; participants to PLQL meetings (Peter Dolog, Geert-Jan Houben, Mikael Nillson, Bernd Simon, Fridolin Wild, and Zhou Xuan); the members of the CEN/ISSS Workshop on Learning Technologies for their valuable suggestions and discussions; contributions from Xavier Ochoa and his team at ESPOL for implementing the PLQL language and giving valuable feedback on the specification; funding assistance of the eMapps.com project; and funding assistance of the MELT project. References1. IEEE Standard for Learning Object Metadata: <http://ltsc.ieee.org/wg12/>. 2. Zthes, <http://zthes.z3950.org/cql/>. 3. E. Duval, E. Forte, K. Cardinaels, B. Verhoeven, R. Van Durm, K. Hendrikx, M.W. Forte, N. Ebel, M. Macowicz, K. Warkentyne, F. Haenni. The ARIADNE Knowledge Pool System: a Distributed Digital Library for Education, Communications of the ACM, 44(5):73-78, May 2001. 4. IMS Global Learning Consortium: <http://www.imsglobal.org>. 5. The Dublin Core Metadata Initiativa: <http://dublincore.org/>. 6. MPEG-7: <http://www.chiariglione.org/mpeg/standards/mpeg-7/mpeg-7.htm>. 7. F. Van Assche, E. Duval, D. Massart, D. Olmedilla, B. Simon, S. Sobernig, S. Ternier and F. Wild. Spinning interoperable applications for teaching & learning. Journal of Educational Technology & Society, 9(2):51-67, April 2006. Special Issue: Interoperability of Educational Systems. 8. C. Lagoze, H. Van de Sompel, M. Nelson, S. Warner. The Open Archives Initiative Protocol for Metadata Harvesting – Version 2.0 <http://www.openarchives.org/OAI/openarchivesprotocol.html>. 9. K. Verbert and E. Duval. Evaluating the ALOCOM Approach for Scalable Content Repurposing. Second European Conference on Technology Enhanced Learning (ECTEL) – Creating new learning experiences on a global scale, 17-20 September 2007, Crete, Greece. 10. R. Sanderson, J. Young, R. LeVan, SRW/U with OAI, Expected and Unexpected Synergies, D-Lib Magazine, Volume 11, Number 2, February 2005, <doi:10.1045/february2005-sanderson>. 11. E. Duval, S. Ternier, F. van Assche (eds). Learning Objects in Context, special issue of International Journal on E-Learning, Vol. 5, No.1, <http://go.editlib.org/p/21768>, 2006. 12. D. Massart. The EUN Learning Resource Exchange (LRE). The 15th International Conference on Computers in Education (ICCE2007) Supplementary Proceedings, volume 1, pages 170-174, November 2007. 13. CQL: Contextual Query Language (SRU Version 1.2 Specifications). Last accessed 12 November 2007 at <http://www.loc.gov/standards/sru/specs/cql.html>. 14. J.-N. Colin and D. Massart. LIMBS: Open source, open standards, and open content to foster learning resource exchanges. Proceedings of The Sixth IEEE International Conference on Advanced Learning Technologies, ICALT'06, pages 682-686, Kerkrade, The Netherlands, July 2006. IEEE Computer Society, Los Alamitos, California. 15. B. Simon, D. Massart, F. Van Assche, S. Ternier, E. Duval. A simple query interface specification for learning repositories. CEN Workshop Agreement (CWA 15454). 16. F. Van Assche, D. Massart, (eds). The EUN Learning Resource Exchange Metadata Application Profile Version 3.0. Last accessed November 13, 2007 at <http://fire.eun.org/LRE-AP-3.0.pdf>. 17. D. Massart. LRE-QL: Introducing an LRE Context Set For The Federated Discovery of Learning Resources. July 2007. Last accessed November 13, 2007 at <http://fire.eun.org/QueryingTheLRE.pdf>. 18. The XML Path Language: <http://www.w3.org/TR/xpath>. 19. S. Ternier, F. Neven, M. Macowicz, N. Ebel. Web services for Learning object Repositories – the ARIADNE Knowledge Pool System. 12th International World Wide Web Conference, Budapest, Hungary, pages 203-204. 20. W. Crawford. MARC for library use: understanding integrated USMARC (2nd ed.). 1989. K. Hall & Co. Boston, MA, USA. 21. W. Nejdl, B. Wolf, C. Qu, S. Decker, M. Sintek, A. Naeve, M. Nilsson, M. Palmér, T. Risch. EDUTELLA: a P2P networking infrastructure based on RDF. Proceedings of the 11th international conference on World Wide Web. 2002. Honolulu, Hawaii, USA, pages 604-615. 22. S. Ceri, G. Gottlob, and L. Tanca. Logical Programming and Databases. 1990. Springer, New York, NY. 23. H. Van de Sompel, M. L. Nelson, C. Lagoze, S. Warner. Resource Harvesting within the OAI-PMH Framework, D-Lib Magazine, Volume 12, Number 12, December 2004, <doi:10.1045/december2004-vandesompel>. 24. <http://www.chiariglione.org/mpeg/>. 25. J. Broisin, P. Vidal, M. Meire, and E. Duval. Bridging the Gap between Learning Management Systems and Learning Object Repositories: Exploiting Learning Context Information. In ELETE 2005, IEEE Computer Society, p. 478-483, Lisbon, July 2005. Copyright © 2008 Stefaan Ternier, David Massart, Alessandro Campi, Sam Guinea, Stefano Ceri, and Erik Duval |
|||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/january2008-ceri
|
|||||||||||||||||||||||||||||||||||||

{kind=link}