|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Marilyn Domas White Eileen G. Abels Neal Kaske |
![]()
IntroductionThis article reports on a pilot study. The pilot will inform the methods for a larger, evaluative study of the quality of chat reference service. The evaluative study will use obtrusive observation techniques to look at several aspects of chat-based reference service from the information seeker's perspective including: the overall session, the chat or negotiation process, and the provision of answers, including the sources used. The evaluative study will specifically address the quality of output by assessing the accuracy and completeness of answers provided to chat reference service clients. Several researchers writing about digital reference services have suggested methods or measures for evaluation, but they have tended to emphasize service-related characteristics that are likely to lead to outputs that are of high quality [Kasowitz et al., 2000; White, 1999; White 2001; McClure et al., 2002). These are generally easier to measure than outputs or responses to actual questions, which are more difficult to evaluate, although user satisfaction is often used as an acceptable surrogate. In evaluations of traditional reference service, unobtrusive observer studies have provided the basis for assessing the quality of question responses. In unobtrusive observation evaluations, trained questioners act as real clients to pose reference questions in the actual reference setting; the information specialists responding to the questions are not aware that the questioners are not actual clients. Human subject concerns are usually addressed by obtaining permission from the information specialists or library administrators prior to the reference encounter(s), with the understanding that the questioners would not identify themselves in the encounters to insure that the encounters represented what would occur normally. Question content is carefully controlled to insure consistency in the stimulus across multiple libraries, and the answers to the questions asked are judged against pre-determined standards, usually for accuracy. The early studies by Crowley and Childers; Childers; and Hernon and McClure are standard examples of such studies and provide guidance on methodological design, problems in establishing standards for individual questions, and factors in training questioners [Crowley & Childers, 1971; Childers, 1978; and Hernon & McClure, 1983 and [1987b]. They also suggest analytical approaches to data analysis. Childers is especially useful for this pilot study since he considered the possibility of question negotiation during the encounter and established scales for evaluating quality of response [Childers, 1978]. The latter allowed him to find a higher rate of success than normally found in such studies [Hernon & McClure, 1983; Durrance, 1989; and Saxton, 1997]. Childers was not able to assess the nature of the reference negotiation, as will be done in the large chat evaluative study, however, because recording the encounters would have been obtrusive. In another study, Hernon and McClure summarize methodological concerns and suggest procedures to follow in unobtrusive observer studies, such as carefully preparing and testing questions [Hernon & McClure, 1987a]. More recently, Saxton's meta-analysis of unobtrusive evaluation studies in reference points out inconsistencies and commonalities among the studies, for example, inconsistencies in the types of questions considered [Saxton, 1997]. One of the typologies of questions used in the pilot study had not been used previously in unobtrusive observer studies, but it is a standard typology based in psycholinguistics that can be applied across reference settings. Kaske and Arnold discuss preliminary results of a class-based project to evaluate chat reference services [Kaske & Arnold, 2002]. Their study indicated the feasibility of doing an unobtrusive observer study of chat reference services and stimulated the large evaluation project. Findings of the large, evaluative study of service quality in chat reference services will be compared with the findings of these studies where appropriate and will also be examined for new trends. Chat session transcripts allow for evaluating not only the answer but also other aspects of the chat session that are factors likely to influence the quality of the answer, such as the quality of the negotiation. Research QuestionsThe pilot study described in this article was designed to pre-test some aspects of the methodology and analysis for an unobtrusive observer study of chat reference service quality. The research questions for the final study of service quality will be:
The pilot study looked specifically at several aspects of the methodology intended to support the larger study, including:
The results of the pilot study may stimulate the reformulation of the original research questions or may lead to development of totally new questions. MethodologyThe pilot study used trained questioners posing as real chat reference service clients to ask a limited set of questions in two chat reference services (one in a public library and the other in an academic library). The questions represented direct and escalator questions and solicited different types of information, based on Graesser's typology of questions. The process and data were analyzed to answer methodological concerns and to test possible qualitative and quantitative techniques for data analysis. ParticipantsSince the large study will analyze chat reference services in both academic and public libraries, participation for the pilot study was solicited from one library from each type. Within each library, librarians or others staffing the chat reference services were considered the information specialists, i.e., those answering the question asked by a questioner. For the pilot study, the questioners were the three researchers engaged in the study, plus a colleague in a University of Maryland library. The questioners posed as real chat reference service clients and asked questions; the information specialists responded to those questions. All questioners were knowledgeable about reference generally and chat reference service specifically. In three cases, the questioners have or have had operational responsibilities for a chat reference service. In the final study, questioners will be persons familiar with reference work. QuestionsEstablishing the questions to be used in the study was a multi-step process in itself. This objective was divided into five tasks:
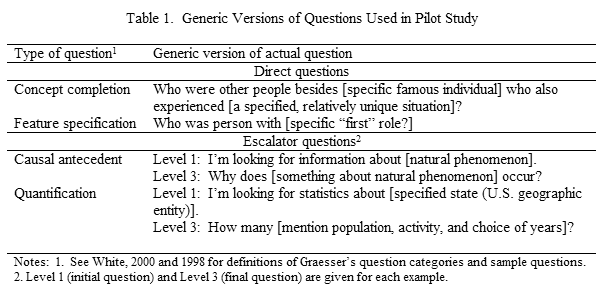
Tasks 1, 2, and 5 involved only the researchers. Tasks 3 and 4 required the participation of others. Task 1 First, the researchers determined that the study would include a range of questions categorized in two ways. In the first categorization, the questions included both direct and escalator questions. A direct question is phrased as a traditional interrogative statement (beginning with an interrogative word and ending with a question mark) that is clearly stated and accurately reflects the desired information. Childers incorporated escalator questions into his study of information service in public libraries in Suffolk County, New York [Childers, 1978]. The pilot study used his definition of an escalator question as one in which "the initial question presented in the library was not the exact thing needed. The proxy [questioner] was ready with one or more detailed questions on the same topic as the original inquiry, should the respondent show signs of negotiating the original inquiry". The eventual question in all cases was a request for factual information, not judgments or opinions. In the second categorization, the questions represented categories based on Graesser's typology of questions [Graesser, 1994]. Graesser's categories are based on the nature of the information requested, independent of the question's subject. As a result, the typology is useful in the chat reference service environment where subjects of questions may vary widely. (See White (1998) for an application of Graesser's typology to questions posed by both intermediaries and clients during reference interviews. A chart explaining all categories and giving reference interview examples is included [White, 1998].) The typology contains twenty types of questions (including assertions, requests, and directives), but the pilot study questions represented just four categories, three intended to elicit short answers, and one that would require a longer answer [Graesser, 1994]. In the final study, when more questions are used, the questions will represent additional types of questions according to Graesser. Other studies in library and information science use Graesser's typology for categorizing questions as well [Slaughter, 2002; White, 1998 and White, 2000; Keyes, 1996; and Stavri, 1996]. No other unobtrusive study of reference has used Graesser's categories for determining question types. Task 2 Next, the researchers devised a large set of questions, aiming for diversity in subject matter, type of question based of the direct/escalator question dichotomy, and type of question based on Graesser's categories. Fifty questions were established at this stage. Some of these were based on actual questions used in chat services. Then, each researcher determined his or her best set, i.e., the questions he or she considered the best mix for achieving diversity, based on the characteristics noted above. These votes were tallied, and the focus shifted to the questions with the greatest agreement. Task 3 The third task addressed the question of fairly using one set of questions for both academic and public libraries. In other words, to what extent are questions appropriate in one library type equally appropriate for another? A set of likely questions for the pilot study (N = 9) was sent to a convenience sample of academic librarians and public librarians. They rated the questions on a 5-point Likert scale, assessing the likelihood that they would encounter a question like it in their type of library. The four questions with considerable agreement between the libraries were used for the pilot study. Generic forms of these are included in Table 1; the actual questions are not included since they or variants of them will be used in the final study. The questions represented different Graesser categories. Two were selected to be the basis of escalator questions, and two were phrased as direct questions. Additional comments about this phase of the methodology are included in the discussion of methodological findings.
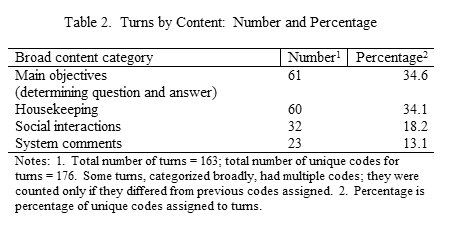
For escalator questions, three levels of questions were developed to establish a consistent pattern for revealing additional information if negotiation occurred. Two levels are shown for each escalator question in Table 1. Level 1 shows the question as originally asked; Level 3 shows the desired final level. The specificity of the question increases as the numbered level increases. This formulation is similar to that used by Childers [Childers, 1978]. In Table 1, concept completion, feature specification, and quantification questions typically call for short answers. A causal antecedent question usually requires a longer answer. A concept completion question specifies a particular event with one missing component and asks for completion of the event. It resembles a fill-in-the blank question and includes many who, what, where, and when questions. A feature specification question is similar to a concept completion in that it, too, can be regarded as a fill-in-the-blank question, but it asks about static or relatively unchanging properties of objects, not about missing components in actions as in concept completion questions. A quantification question asks for an amount that can be counted or expressed as a continuous quantity; it is usually expressed as a "how" question, e.g., how many, or how often. A causal antecedent question involves a causal chain that may consist of one or more links; the question seeks to identify the unknown that led to a stated result. Charts explaining Graesser's twenty categories and giving examples of actual questions found in different information-seeking situations are included in two articles by White, one for reference interviews and the other for consumer health-related electronic lists [White, 1998 and White, 2000]. Task 4 The fourth task focused on measuring the accuracy of the responses to the questions. Two library school students (a doctoral student and an experienced master's student near the end of her program) searched each question to provide an accurate answer for each question. For each question, each student found the answer in a print source and in an electronic source. For the electronic source, preference was given to free web sources, but common, fee-based electronic resources available via the web from the university's web site were allowed. They recorded their search time in each case, so that search time could serve as an informal, indirect measure of difficulty. Their answers were subsequently checked for agreement, and their times were averaged for each question to indicate the question's level of difficulty. Because the pilot study asked so few questions, level of difficulty was not used in selecting questions. Each question had a pre-determined "correct" answer, which served as the basis for determining the accuracy and completeness of answers provided by information specialists during chat sessions. Task 5 In the fifth task, researchers developed scenarios appropriate across institutions for each of the four questions eventually used in the pilot study. These scenarios were intended to establish the bases for the questioners to provide information about motivation, problem orientation, and external constraints if solicited by the information specialists. Eliciting this kind of information can influence the answer quality and will be an indicator of good question negotiation. An example of a scenario is: "You and your friends were discussing the last presidential election and this question came up." Data and Data GatheringFor each chat session, data consist of information related to time, judgments of effectiveness and efficiency, comments from the questioner (see Appendix for data collection form), and a transcript of the session, including question negotiation, the answer to the question, and the source(s) recommended. Four questioners gathered the data unobtrusively (see Appendix for questioner directions) by posing as regular chat reference service patrons. For each library, the questioners had institution-specific identification numbers so that they could pose as legitimate clients of the service. Each questioner was responsible for asking one question of each of the two libraries. The questions were randomly assigned to the questioners. In addition, the times for asking the questions were randomly selected within the hours of operation for each service and allocated across questioners. For each service, the hours of operation were arranged sequentially and then the appropriate number of hour slots was selected by using a table of random numbers. To allow for problems in reaching the service, the questioners asked the assigned question at various times during the hour slot. The hours of operation varied across the participating institutions. At the end of each session, the questioner completed the data collection form for the question and either appended a transcript of the session or indicated where the transcript was archived so that it could be obtained. Data AnalysisThe pilot used a mixed mode of data analysis. It computed evaluation measures based on question response and the chat transcript. Qualitatively, it analyzed content of the chat transcript to detect patterns, suggest additional research questions, and perhaps establish the basis for quantitative measures. Content of chat sessions was analyzed iteratively using a constant comparison approach to derive coding categories. Definitions and examples were devised and revised as necessary. The level of analysis was the turn. In chat sessions, as in conversations, the information specialist and questioner typically take turns communicating, with the communication of one individual establishing the direction of subsequent talk and the basis for understanding on the part of each participant [Heritage, 1989]. The coding schema that evolved consisted of 22 relatively specific coding categories reflecting the purpose or function of the turn. These specific categories were subsequently grouped into four major categories: main objectives, housekeeping, social interactions, and system messages. Usually a turn had only one function, but occasionally more than one function was necessary to represent a turn that had multiple sentences addressing different issues. The turns were also coded to indicate the source of the comment, i.e., questioner or information specialist. ResultsResults had implications for future research into service quality and for methodology. The service quality results, although interesting, are based on a very small sample of questions and libraries, but they suggest additional methodological issues and are based on testing elements in the plan for analysis. Findings Related to Service QualityThe foci for analysis were on: a) the overall session; b) the encounter, i.e., the chat itself; and c) the answer, including the sources used. Overall session—Data were gathered on the overall duration and the length of individual segments and/or aspects of the chat session. These provide a descriptive basis for understanding the distribution of time across the sessions. The average session length was 12 minutes, 57 seconds (Standard Deviation (SD) 7 minutes, 39 seconds). The large standard deviation indicates considerable differences across the interviews. The range was from 3 minutes to 29 minutes, 33 seconds. Not surprisingly the distribution was bi-polar with shorter sessions for the direct questions and longer sessions for the escalator questions. Other studies are reporting length-of-session data so, in the final study, findings can be compared to other studies. Queuing time was the only segment measurement that was officially included in the pilot study, and thus it was consistently measured across the questions. Queuing time is defined as the length of time between the system's recognition of the questioner and the questioner's contact with an information specialist. Queuing time ranged from 10 to 60 seconds. However, experience in the sessions strongly suggested that down time and time lag from response to an information specialist question to time of acknowledgement of the response are two other time-related variables that need to be noted. Down time is broader and includes time lag, as well as the length of other types of down times. For one question, for example, the questioner waited 10 minutes between the time the information specialist said he would look for the information and the time that the information specialist returned an answer. Chat—This segment of the analysis looks at the number of turns in each session and the content of the session. On average, a session contained about 20.4 turns (SD 11.2), and ranged from 7 to 37 turns. Again, as with the time measures of the overall session, the distribution was bi-polar based on direct and escalator question types. As noted earlier, the coding schema that evolved consisted of 22 relatively specific coding categories reflecting the purpose or function of the turn. These specific categories were subsequently grouped into four major categories: main objectives, housekeeping, social interactions, and system messages. Table 2 shows the distribution of each type.
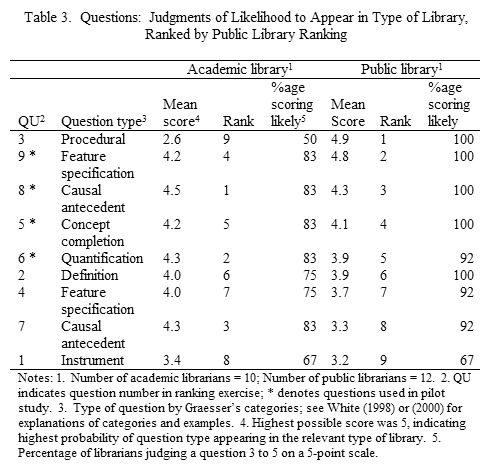
Only one of four escalator questions reached the final question level without the questioner's help. This finding indicates that question negotiation was frequently incomplete. For example, in one situation in which the question had been negotiated to the second level, the questioner returned to the chat service after checking a web site to indicate that the information required was not available there. At that point, she voluntarily moved the question to the third level, and the information specialist began a more involved search. Answer, including sources—In responding to questions, information specialists provided, on average, references to two sources. Most of the sources (73 percent) were web sites, and ten of the eleven sites were pushed to the questioner. Four (27 percent) were print sources, and one source (7 percent) was an electronic, proprietary database, providing full-text. Three-fourths of questions were answered accurately, usually in the first source consulted, but sometimes only after the original questioner did considerable additional searching within the site. In other words, the information specialist took the questioner to a site and "dropped him off" to fend for himself in finding information on the site. Two questions were only partially answered, even after consulting two to three sources. The escalator questions were more problematic than the direct questions. What sort of information was provided to the questioner about the answer? In providing the sources, the URLs were always provided for web sources, either on the pushed site or in the chat so that the questioner could access the sites. In three sessions (37.5 percent), the information specialist commented about one or more characteristics of the source, often indicating other reasons besides subject relevance for selection of the source. The specialist referred to the language (technical or not); the authority of the author or publisher; and the treatment, e.g., style of writing. In the other cases, the information specialists commented only that the answer should be or is in a specific source. For the print sources, only the title was provided (with an error in one case). For the electronic database, the information specialist gave instructions via the organization's web site through several different pages to the list of databases, to the database itself, and finally to the entry term that should be entered in the search engine for the database. In this case, the entry retrieved the full-text of a particular, lengthy, government publication. The information specialist made no effort to find the actual answer to the question within the full-text of the publication. Findings Related to MethodologySample of questions—The first finding addresses the possibility and wisdom of devising a single sample of questions to be used across academic and public libraries. Table 3 shows the results of having librarians from each type of institution rate the larger sample of questions for the likelihood that they would encounter a question like it in their type of library. As the table indicates, there are some questions with high agreement, but others occupy polar positions. Question 3, for example, which calls for identifying a procedure for doing an ordinary but legally-required task, was considered highly likely to be asked in a public library and only rarely in an academic library. The likely modification to the final study design is to create three sets of questions, covering: 1) those applicable in both settings; and 2) two sets of questions (one set per institution type) that tend to appear in only one type of institution.
Although scenarios were prepared for each question in the pilot study, no information specialist asked a question that called for the questioners to provide scenario-based information. Scenarios will still be provided for each question in the final study to insure consistency in the information provided if the need should arise. Measure of answer quality—More work still needs to be done in this area. In the pilot study, the standards were set relatively low. In many cases, the information specialist's response was to refer the questioner to a complicated web site with little guidance about how to navigate the site to find the specific, desired information. The question was considered to be answered accurately if the questioners (all experienced professional searchers) were able to locate the pre-determined answer, even though sometimes finding the actual answer required either significant time browsing or fairly sophisticated searching and term selection. In these situations, gradations of accuracy, based on variations in the amount of effort required after the answer is provided are being considered. Coding schema for qualitative data—The specific schema and the broad categories provide useful insights into the focus and content of the reference interview. In addition to the quality of the answer provided, the focus of the interview seems to influence user satisfaction with the entire encounter. Although subject to refinement and modification in the final analysis, the preliminary coding has been very useful in pre-testing a methodological approach to the analysis and suggesting a coding schema that addresses the research questions. Additional categories may be necessary when a greater variety of question types are used in the large study. Measures of efficiency and effectiveness—The data-gathering instrument (see Appendix) asked questioners to assess the effectiveness and efficiency of the chat session on a scale of 1 to 5. The purpose was, first, to assess the questioner's ability and comfort in making these overall judgments and, second, to understand the factors that underlie these judgments, i.e., the more concrete measures that correlate with the judgments. The questioners had no difficulty making these general assessments and felt comfortable doing so. Regarding the factors that underlie the overall judgments, efficiency seems to be based primarily on the extent of focus on main objectives (based on content analysis of the transcripts) and on the total time allocated to the interaction itself (measured by the formula: session time—down time). Effectiveness seems to be based primarily on the accuracy and completeness of the answer (using the pre-determined acceptable answers as a standard). Measure of quality of experience—An unexpected finding was the need to create a measure that reflected the quality of experience of the chat session. The positive factors underlying this measure seem to be: accuracy of the answer; focus during the chat on main objectives; and reflection of positive information specialist traits, such as patience, helpfulness, and undauntedness, in the interchange. The latter will be difficult to measure. Negative factors are: down time; the questioner's frustration in using a suggested source; long queuing time; lag time in acknowledging responses; and technical problems. Questioner guidelines—Questioners need to be very carefully coached to insure consistent delivery of the question and nature of the responses. Training sessions should include actually posing questions to chat services. The chat services may be simulated so that, during the sessions, the questioners act both as questioner and as information specialist/answerer. Scheduling of questioning—The system for assigning questions and question times across the services was workable and will be used in the large study. For questioner convenience, the times will be translated into Eastern Standard Time. ConclusionsThe pilot study results related to service quality are based on very few cases, but they have implications for future research into chat reference service quality. Positively, they suggest that answer accuracy, assuming the questioner can search a web site effectively, is higher than for in-library reference service. This finding is important if it is substantiated in the large study. Answers often consisted only of referral to one or more web sites, perhaps with suggested query terms for searching within the sites. Rarely did information specialists comment on their factors for selecting the site; they lost an opportunity to provide evidence of evaluation criteria and to indicate authority in choosing an information source to the questioner. The study suggests reporting average session length, queuing time, and number of turns per session as quantitative measures that can be compared across services and questions. Future study should also incorporate measures of down time and lag time since these seem to influence judgments of user satisfaction with the overall encounter. The pilot study also provides evidence the questioners' subjective judgments about effectiveness and efficiency are correlated with criteria that can be measured more directly. The study suggests the usefulness of, and complexity involved in, incorporating different types of questions into an evaluative study of chat reference service, especially in a multi-type library study. In the larger study, analyses by question types should allow for judging the types of questions for which chat reference service is more useful. The fact that few escalator questions were adequately negotiated raises questions about effective use of the interactive aspects of chat reference service. This finding is corroborated by the fact that information specialists did not inquire into the context of the question (the scenarios). The study points to the need for a measure that reflects the quality of experience of the chat session and suggests both positive and negative factors that should be incorporated into that measure. Finally, the study proves it is possible to use unobtrusive observation to gather data related to service quality in chat reference services and shows the richness of the research data (and the resultant analyses) that result from chat reference service encounters. SummaryThis paper reports on a pilot study of chat reference service in academic and public libraries that addressed methodological concerns and provided data on which to test various analytical approaches to data analysis. The study was an unobtrusive observer evaluation study, similar to others done in more traditional settings (see, for example, Hernon and McClure [Hernon & McClure, 1983]). Although it is a small pilot study, the study is the first other than the class-based project by Kaske and Arnold [Kaske & Arnold, 2001] to assess the quality of the actual services provided to chat reference clients. AcknowledgmentThe authors wish to acknowledge with gratitude the help of Julie Arnold in gathering data and Joan Meyer and Jinsoo Chung in developing the questions, the librarians who rated the questions, and the administrators and staffs of the chat reference services. Bibliography[Childers] Childers, T. (1978). The Effectiveness of Information Service in Public Libraries: Suffolk County: Final Report. Philadelphia, PA: Drexel University, School of Library, and Information Science. [Crowley] Crowley, T., & Childers, T. (1971). Information Service in Public Libraries: Two Studies. Metuchen, NJ: Scarecrow Press. [Durrance] Durrance, J.C. (1989). Reference success: Does the 55% rule tell the whole story? Library Journal, 114, 31-36. [Graesser] Graesser, A.C. (1994). Question asking and answering. Handbook of Psycholinguistics. San Diego, CA: Academic Press. [Heritage] Heritage, J. (1989). Current developments in conversation analysis. In D. Roger & P. Bull (Eds.), Conversation: An interdisciplinary perspective (pp. 21-47). Philadelphia: Multilingual Matters, Ltd. [Hernon & McClure, 1983] Hernon, P., & McClure, C.R. (1983). Improving the Quality of Reference Service for Government Publications. Chicago: American Library Association. [Hernon & McClure, 1987a] Hernon, P., & McClure, C.R. (1987a). Quality of data issues in unobtrusive testing of library reference service: Recommendations and strategies. Library and Information Science Research, 9(2), 77-93. [Hernon & McClure, 1987b] Hernon, P., & McClure, C. R. (1987b). Unobtrusive Testing and Library Reference. Norwood, NJ: Ablex Publishing. [Kaske & Arnold] Kaske, N. & Arnold, J. (2002). An unobtrusive evaluation of online real time library reference services. Paper presented at the Library Research Round Table, American Library Association, Annual Conference, Atlanta, GA. <http://www.lib.umd.edu/groups/digref/LRRT.html>. [Kasowitz et al.] Kasowitz, A., Bennett, B. & Lankes, R.D. (2000). Quality standards for digital reference consortia. Reference & User Services Quarterly, 39, 355-363. [Keyes] Keyes, J.G. (1996). Using conceptual categories of questions to measure differences in retrieval performance. Proceedings of the Fifty-Ninth Annual Meeting of the American Society for Information Science. Medford, NJ: Information Today. [McClure et al.] McClure, C.R., Lankes, R.D., Gross, M., & Choltco-Devlin, B. (2002). Statistics, Measures and Quality Standards for Assessing Digital Reference Library Services: Guidelines and Procedures. Syracuse, NY: ERIC Clearinghouse on Information & Technology. [Saxton] Saxton, M.L. (1997). Reference service evaluation and meta-analysis: Findings and methodological issues. Library Quarterly, 67, 267-89. [Slaughter] Slaughter, L. (2002). Semantic relationships in health consumer questions and physicians' answers: A basis for representing medical knowledge and for concept exploration interfaces. Unpublished doctoral dissertation, University of Maryland, College Park. [Stavri] Stavri, P.Z. (1996). Medical problem attributes and information-seeking questions. Bulletin of the Medical Library Association, 84, 367-374. [White, 1999] White, M.D., (Ed.) (1999). Analyzing Electronic Question/Answer Services: Framework and Evaluations of Selected Services. CLIS Technical Report no. 99-02. College Park, MD: College of Information Studies, University of Maryland. <http://www.clis.umd.edu/research/reports/99/TR9902.PDF>. [White, 2001] White, M.D. (2001). Digital reference services: Framework for analysis and evaluation. Library & Information Science Research, 23 (2001), 211-231. [White, 2000] White, M.D. (2000). Questioning behavior on a consumer-health electronic list. Library Quarterly, 70, 302-334. [White, 1998] White, M.D. (1998). Questions in reference interviews. Journal of Documentation, 54, 443-465. [White et al.] White, M.D., Abels, E.G., & Kaske, N. (2002). Evaluation of chat reference services. Paper presented at the Virtual Reference Desk Conference, Chicago, IL. <http://www.vrd.org/conferences/VRD2002/proceedings/abels.shtml>. Copyright © Marilyn Domas White, Eileen G. Abels, and Neal Kaske |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/february2003-white
|