D-Lib Magazine, December 1996

Abstract |
Abstract: [top]
There are many ways to publish information on the Internet: through the WorldWide Web, ftp archives, or on-line databases. However, the process of converting or transferring content from the point of origin (e.g., desktop computer word processing file) to the point of dissemination (e.g., a popular World Wide Web page) so far has not been easy to do, much less simple to replicate. The University of Colorado at Boulder in conjunction with Enfo (a telecommunications company) has begun work on a new digital publishing system known as the Integrated System for Distributed Information Services (ISDIS) which implements the proposed Distributed Information Processing Protocol (DIPP) in such a way as to make publishing digital information in distributed environments as simple as sending e-mail to a colleague or saving a file to a local directory.
DIPP has been used for the past year as the core technology for publishing and maintaining web content at public information sites including the Boulder Community Network, some of the State of Colorado World Wide Web pages, as well as some other sites in Colorado. Up to this point, each application of DIPP had to be "hand wired" or customized for the particular input and output. Now, with funding from the National Science Foundation (NSF), the DIPP project team will be working to develop a public standard that uses a proscribed set of API's and "agents". This "work in progress" can be found at the following web address: http://www.colorado.edu/DIPP/. (NB: The site is new and content is being added as available. Currently there are links to recent papers and presentations as well as links to other sites using early versions of the "hard wired" DIPP).
1.0 Introduction [top]
One of the more evident features of the emerging public on-line information space is the importance of aggregator and integrator services that collect and combine information. Examples of these services include: academic campus-wide information servers (CWIS), scholarly and government on-line information sources, community networks, and other such on-line service providers.
Acting as digital editors, these services collect and organize information from disparate sources to create content that is well organized to ensure overall ease of use. By managing and structuring information, such services can serve as beacons in the multi-dimensional Internet ocean, that serve communities of end-users, helping them to find information in the disparate streams of information that characterize the distributed environment.
Essential to the continued growth of public information services is development of effective means to manage information whose ownership extends across a broad range of autonomous units. Currently, the operation of such services is a highly manual and fragile task, requiring extensive hands-on labor at the server side as well as considerable technical expertise from information providers. These requirements are often in conflict with the limited resources of these organizations. The inability to maintain existing services as the information volume increases exponentially is perhaps the single greatest weakness in the effective management of networked information. There is a strong need to automate these information management processes.
It should be noted that public sector environments have
issues in integrating
and presenting information that vary from those of
corporate or commercial
environments. These include:
Despite these differences network tools developed for the public sector environment have immediate application in the corporate environment as well as scholarly (research and education) situations. That is to say, these tools are broadly applicable.
Working within a large and complex network of information servers, a task force centered around the University of Colorado at Boulder has developed a fundamental understanding of the requirements and constraints that shape the distributed information publishing environment. Based on experience and extensive discussion with research and education organizations, the task force project has developed a Distributed Information Services model which includes prototypes of a Distributed Information Processing Protocol (DIPP) and associated application programmer interfaces (API's).
The initial goal of this project was to automate the acquisition, conversion, and mounting of information from a variety of autonomous sources onto a common Web platform. Ultimately, the Integrated System for Distributed Information Services will provide a basis to implement additional information services across any distributed environment.
Specifically, the project seeks to:
Building on a National Technology Initiatives Agency (NTIA) supported environment with direct support from the National Science Foundation (NSF), the project has made steady progress over the last year. DIPP has demonstrated to be a value asset for those persons and agencies responsible to providing timely content for public information sites.
This paper describes a process model and identifies roles of the Distributed Information Processing Protocol (DIPP) and associated Application Program Interface modules. Future papers and technical reports (Requests for Comments [RFC]) will advance the technical specifications and bindings.
It is anticipated that DIPPswitch 1.0 will be freely available to non-profit agencies by the end of the first quarter of 1997.
2.0 The Distributed Information Services Model [top]
2.1 Motivation
As indicated above, public sector information providers need simple tools that provide flexibility in submitting material for posting to online services. The tools that they use should invoke standard network utilities and require minimal additional operations. In addition, there is a need to accommodate a variety of network applications for the transmission of information such as e-mail, file transfer protocol (ftp), and World Wide Web. These software tools are on the client side of the client/server metaphor that is often used to describe networking and distributed information services.
On the server side, an automated environment is needed to assist in the operation and the management of information services. Such an environment includes applications to convert information, processes to index and archive content, and methods to audit system activities.
2.2 Context
As we view the distributed information services model, it is useful to reflect upon roles of participants within the traditional print environment. Typically, there are authors, editors, and publishers. In keeping with this hierarchy, we think of these roles in the following way in our model: Authors create information. Editors collect information and organize it into coherent blocks. Publishers choose the distribution form, market, and audience. In information space, these relationships are more often a heterarchy which is defined as "a form of organization resembling a network or fishnet. Authority is determined by knowledge and function." [ref. http://pespmc1.vub.ac.be/ASC/HETERARCHY.ht ml].
In the DIPP model, the role of the author is assigned to those persons who create content that is to be published. For example an administrative staff person produces a weekly agenda that traditionally had been printed and distributed. In the DIPP environment, this individual can e-mail the final document to the DIPP server. The outcome will be an on-line document or multiple documents ready to be used on-line.
The DIPP editor works with the authors to make sure that the DIPP server functions smoothly. Editors have technical authority to adjust certain parameters of the control database sets in order to meet changing authors or create new branches of information.
Finally the DIPP publisher manages editors and authors as well as the DIPP server. The publisher is the final authority for technical decisions and changes. In effect, this person operates as the system administrator for the host computer and network as well as for the DIPP system itself.
In considering an automated system that dynamically integrates and presents information from various content providers, it is useful to distinguish several steps:
(1) Registration -- a component, involving the system operator and an information provider, that establishes the key parameters and processing patterns for documents that will be submitted on a regular basis. In other words: authorization and authentication of submitted materials. Determining what processing methods are required, certification that the submitted materials are complete and authentic.
(2) Processing -- the conversion of submitted documents, operation of automated tools, response to diagnostic and error messages, and interface with central server operating system. In other words: converting submitted materials into edited output contents with repeated checks to ensure quality control.
(3) Maintenance -- modification of registration data, which includes information about those who are approved to submit information as well as other data on the server used to manage the system. In other words: some method of system administration that allows updates and changes to various controlling elements by the appropriate levels of staff members.
2.3 The Logical Model:
The following logical model describes an analysis of the typical activities in operating a distributed information server. These activities include major elements and interactions of the processing systems based on an open protocol standard and an open application program interface process (API).
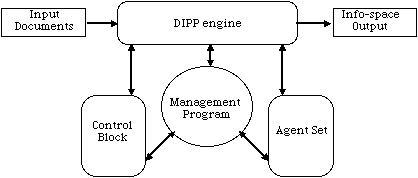
Figure
1.
2.3.1 Control Block
The control block consists of information data sets that direct the processing pattern which are applied to individual documents. These data sets reside on the server, contain pre-defined parameters and control the processing through application of selected elements including: "agents", parameters provided to those "agents," and special instructions. The control block also contains authorization information and other management information.
2.3.2 Agent Set
Agents are specific program segments that receive input, act on provided data and transform information space. They also help administer the operation of the DIPP engine. Three major categories are:
2.3.3 Delivery Clients
Delivery Clients receive the information sent from the user by a variety of methods (e.g., electronic mail, file transfer protocol (ftp), etc., etc.). The delivery clients then deliver both the raw data and information about the data (meta data) to the DIPP server using the DIPP protocol.
2.3.4 DIPP Engine
The DIPP Engine invokes agents, as directed by parameters set by the control block. This series of processes serve to automate all steps of publishing between initial receipt of the original document to the final publishing of the information to a proscribed location.
2.3.5 Management Program
Administrators use the management program to access and edit the various parameters controlling the DIPPswitch program. This management program is the interface for the system administrator, which in turn must be able to communicate with the control block data sets, agent sets, and directly to the DIPPswitch program.
3.0 Process Elements and Interactions [top]
Functional elements of the logical model have a set of interactions among them. For example, submitted material must include authenticating information; DIPP software agents must negotiate parameters with the control data sets; and the management interface has to manipulate content in the control database sets. These interactions are built on two processing standards: DIPP & the DIPP API.
DIPP: The Distributed Information Processing Protocol negotiates data and parameters between originator (delivery client) and central server (DIPP engine).
DIPP API: The DIPP Application Program Interfaces,
define parameters
passing between the DIPP engine and elements of the
administrative pipe.
These include the control block database set, the
agent pool, server data
and access control language.
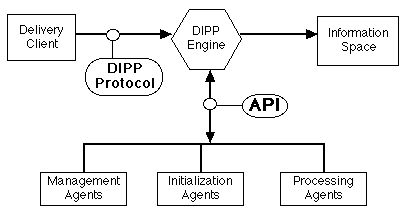
Figure 2.
3.1 The Distributed Information Processing Protocol
DIPP - the Distributed Information Processing Protocol is comprised of a set of message formats and reserved words which encapsulate meta data passed from the delivery client (originator) to the DIPP engine. The protocol proscribes the initiating data the delivery client sends to the DIPP engine. The initiating information is parsed to identify and authenticate the submitter as well as define the "job" to be done. The DIPP protocol permits author and server to securely pass both documents and meta-information to manage the processing of the data.
3.2 The Distributed Information Processing API
As a self-contained system on the server, the set of cooperating processes in the DIPP system need to exchange information through an established set of rules. These rules will include a set of subroutines or executable programs with a common call syntax (also know as the DIPP API and language bindings) which may be executed by the DIPP Engine.
Because the API's are open standards, other programmers can construct additional features and enhancements for the DIPP system. The DIPPswitch software is built upon an open standard intended to encourage broad development in the future.
4.0 DIPP Taskforce Work Plan [top]
The DIPP Taskforce is working to produce a stable beta environment as well as begin to develop the necessary documentation to introduce the DIPP system in the standards process of the Internet Engineering Task Force (IETF).
The project team has been working with pre-alpha versions of DIPP that were used to support various agencies in the Boulder-Denver, Colorado region. These pre-alpha versions served as proof-of-concept for the DIPP system. Currently these early elements are being revised and codified to function as core elements of the DIPP system. The project team has a target delivery date of mid-November for the initial beta releases to a group of pre-determined sites on the Internet. Subsequently it is planned that the first public release of DIPPswitch 1.0 will be released later in first quarter of 1997.
Meanwhile, other members of the taskforce are working with the core materials to document and present them for review as an Internet standard with the Internet Engineering Task Force.
5.0 Summary [top]
The DIPP system,
through the use of standard protocol and API's, is a
model that parallels
established procedures for producing, publishing, and
disseminating printed
information. Transfer of those concepts from print
to digital environments
will permit academic institutions and other information
providers to create
and manage information much more easily than they have
been able to
previously. The Distributed Information Processing Protocol
will enable us
to produce information in a timely manner without the current
restraint of
technical expertise. We can hope that DIPP will lower the thresholds
for
Internet users and foster easier information exchange.



hdl:cnri.dlib/december96-brett