|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Tony Hammond, Timo Hannay, and
Ben Lund |
![]()
IntroductionRSS is one of a new breed of technologies that is contributing to the ever-expanding dominance of the Web as the pre-eminent, global information medium. It is intimately connected with—though not bound to—social environments such as blogs and wikis, annotation tools such as del.icio.us [1], Flickr [2] and Furl [3], and more recent hybrid utilities such as JotSpot [4], which are reshaping and redefining our view of the Web that has been built up and sustained over the last 10 years and more [n1]. Indeed, Tim Berners-Lee's original conception of the Web [5] was much more of a shared collaboratory than the flat, read-only kaleidoscope that has subsequently emerged: a consumer wonderland, rather than a common cooperative workspace. Where did it all go wrong? These new 'disruptive' technologies [n2] are now beginning to challenge the orthodoxy of the traditional website and its primacy in users' minds. The bastion of online publishing is under threat as never before. RSS is the very antithesis of the website. It is not a 'home page' for visitors to call at, but rather it provides a synopsis, or snapshot, of the current state of a website with simple titles and links. While titles and links are the joints that articulate an RSS feed, they can be freely embellished with textual descriptions and richer metadata annotations. Thus said, RSS usually functions as a signal of change on a distant website, but it can more generally be interpreted as a kind of network connector—or glue technology—between disparate applications. Syndication and annotation are the order of the day and are beginning to herald a new immediacy in communications and information provision. This paper describes the growing uptake of RSS within science publishing as seen from Nature Publishing Group's (NPG) [6] perspective. Data Syndication using RSSRSS is not such a simple thing to pin down, though it's simple enough to use. It is by nature a hydra-headed creature. RSS goes by many names [n3] and sports multiple version numbers that do not reflect any true lineage or patronage so much as a branding (and it must be confessed, a fervoured and sometimes fevered politics). RSS is not any formal standard but is rather a tribe of competing 'street' standards (although it should be remarked that the newest addition to the family is currently developing its specification through the IETF process). The similarities, however, outweigh the differences between the various versions. They all provide specifications for an XML document that lists items containing titles and links, and (optionally) descriptions and other terms. These XML documents are made available on a webserver and can be pulled down by any RSS aggregator on a user's preferred schedule. No negotiation is required bar standard HTTP protocols. The most common use of RSS is in RSS readers, desktop and handheld applications that alert users when new content is detected on a site by means of changes to the XML document, although a growing number of server-side aggregators are also becoming very popular [n4]. Figure 1 shows an RSS feed for the journal Nature rendered on a Palm handheld device.
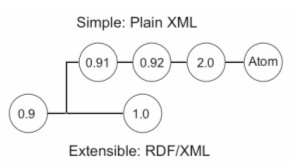
Broadly speaking there are two main branches: one (RSS 1.0) a descendant of the early Netscape implementation (RSS 0.9) that adopts the Resource Description Framework (or RDF) data model, the other (RSS 0.91–Atom) more basic XML implementations that err on the side of simplicity and generally eschew the use of exotica such as XML namespaces. The difference between the two arises essentially from their intended purposes. The 'Really Simple Syndication' branch is concerned primarily with syndicating ephemeral content such as news headlines and users' blog entries, while the 'RDF Site Summary' branch (although also actively used for news syndication) is more focussed on a generic means of exchanging structured metadata and provides a simple modular extension mechanism [7] to accommodate new vocabularies [8]. See Fig. 2 for a schematic of RSS development and the fork in its evolution.
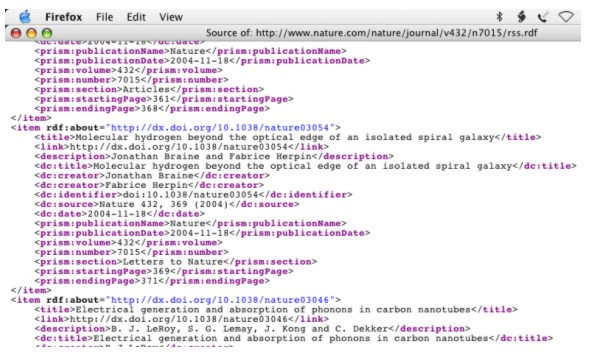
The fact, however, is that most RSS readers and other RSS applications support both branches, and as far as an end user is concerned, there is really little or no difference to choose between them. Even for a provider of RSS there are code libraries that manage the generation of the appropriate XML markup transparently [n5]. Some supporters of the 'Really Simple Syndication' branch hold to the 'view source' argument [n6], although as many who have looked at HTML pages from one of today's content-rich websites will know, these pages are generally produced programmatically and are not manufactured by hand. There is anyway an underlying paradox at work: apparent simplicity leads to a downstream complexity, while seeming complexity finds for a future simplicity. One might think of this in terms of comparing HTML with XML. An excellent overview of RSS history and usage is to be found in Ben Hammersley's book Content Syndication with RSS [9], which is currently under revision [n7]. As a science publisher we are used to handling citation metadata and are thus more inclined to use the extensible format, as this allows us to bundle rich descriptive metadata along with the staples of all RSS feeds, i.e., titles, links and (optionally) descriptions. We see RSS as providing an information backbone on which new application opportunities can be built. We note that other science publishers are now beginning to provide RSS and often are also choosing to adopt the RDF flavour. This in our opinion is fortunate, as the RDF data model readily allows for the merging of different descriptions. Thus, aggregates of multiple RSS feeds can be simply merged together as well as with descriptions coming from other sources, allowing rich information structures to be created. The reason this is possible is that the RDF data model builds upon a set of triples (subject, predicate, object), and merging of two arbitrary descriptions is as simple as concatenating the two sets of triples. By contrast, merging of two arbitrary XML documents requires schema negotiation—knowledge of both the input schemas and the output schema is required. The reasons for preferring RSS 1.0 have been detailed in various papers, see e.g., [10, 11]. A new initiative within the RSS community—Atom [12]—was started in mid-2003 and is still in the throes of vigorous development, although feeds in this format are already widely available [n8]. At the time of writing, Atom appears to be leaning towards the 'Really Simple Syndication' branch and, as such, represents a cleaning-up and general overhaul of RSS 2.0 [13]. It should be pointed out that Atom is aiming to define both a syntax and a protocol for updating user blogs and thus goes beyond the simple remit of RSS. There has been much talk about how much support (if any) Atom will provide for the RDF data model and what would be the tangible benefits to users for RSS producers to provide additional metadata. As a science publisher, however, we are minded to continue to produce RSS 1.0 for the immediate future, since it meets all our current needs, while monitoring the Atom development to see what end utility it might afford. Our current view is that Atom does not provide the necessary level of metadata extensibility and interoperability that we are able to achieve with RSS 1.0. Metadata Annotation using RSSOne of our main interests in RSS is the ability to include additional metadata. RSS 1.0 is both a constrained form of RDF/XML (to follow the basic RSS feed pattern) and a constrained form of XML (to make it conform to the RDF/XML specification). Because of its RDF pedigree, RSS 1.0 is ideally suited to the inclusion of supplementary metadata. An obvious candidate vocabulary for including metadata elements within an RSS feed is the ever-familiar Dublin Core vocabulary [14] that provides for a basic level of interoperability through its 15-element generic term set. Guidelines for using the Dublin Core term set within RSS 1.0 [15] have long been defined for use within the RSS community. (Companion guidelines for qualified Dublin Core metadata are also available [16].) Unfortunately the trade-off in using a high-level vocabulary to supply rich descriptive metadata is the lack of specificity, and the basic Dublin Core term set does not present the level of granularity required to codify discrete bibliographic elements. Enter, PRISM—'Publisher Requirements for Industry Standard Metadata' [17]. The PRISM initiative has been sponsored by IDEAlliance [18] with a view to describing content assets from trade serials publications for syndication. PRISM defines a small set of vocabularies that work together to address industry requirements for resource discovery. Adopting the Dublin Core vocabulary (with certain qualifications), PRISM defines an additional basic vocabulary of some 50 terms, plus three smaller, more specialized vocabularies for dealing with rights, inline markup, and controlled vocabularies. We are especially interested in the basic PRISM vocabulary, which extends the utility of Dublin Core by catering for specific bibliographic metadata fields such as issn, volume, number, startingPage, etc. Any RDF vocabulary that adheres to this prescription can be freely used with RSS 1.0. However, to assist RSS 1.0 producers a number of extension 'modules' have been defined, which essentially provide guidelines for usage. Such modules [n9] are really only devices, aide memoires, and exist purely to guide the producer. Below we introduce certain proposed RSS 1.0 modules, recognizing that these are not required for RSS 1.0 but rather are simply usage guides. Last year we defined an RSS 1.0 module based on the basic PRISM vocabulary and recently republished this [19] to align it with the latest PRISM specification [20]. This time we took extra steps to make the RSS 1.0 module more 'official'—i.e., to give it a greater visibility and stability by a) lodging it with the IDEAlliance PRISM website as a contributed resource, b) getting it listed on the 'RDF Site Summary 1.0 proposed modules' page, and c) assigning it a PURL, or persistent URL [n10]. We also lobbied the PRISM Working Group for, and were granted, two new PRISM elements that seemed important to us as science publishers: endingPage and eIssn. Differently from trade publications, scientific articles are generally printed contiguously and endingPage is a usual component of a bibliographic citation, while ISSNs are often required for different formats. Figure 3 shows the descriptive metadata carried in a Nature RSS feed.
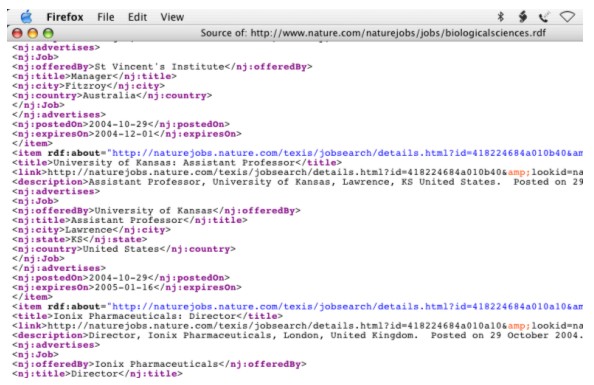
Besides tables of content with associated bibliographic metadata, we also syndicate feeds of the current jobs advertisements that are held in our scientific jobs database. As no obvious vocabulary seemed to be available, we took the step of defining a small set of terms that could serve as the basis for further elaboration. Figure 4 shows this jobs metadata carried in a NatureJobs RSS feed. This mini-vocabulary includes terms to describe simple job advertisement concepts like offeredBy, city, country, postedOn, expiresOn, etc. We would like to develop this vocabulary further with industry partners. We note in passing the ongoing work on the Advertising Markup Language (AdsML) by the AdsML Consortium [21] and have had some preliminary exchanges with them, although that initiative is of a significantly larger scope than our more limited application. An RSS 1.0 module [22] for the IEEE Learning Object Metadata term set [23] has been defined by Stephen Downes. Though not as yet widely implemented, this is nevertheless illustrative of how the simple extensibility mechanism built in to RSS 1.0 can be used to effect.
It may also be of interest to mention yet another RSS 1.0 module [24] published last year by some of us. This allows a ContextObject—the data structure at the heart of the new OpenURL Framework that is being developed by ANSI/NISO as information standard Z39.88-2004 [25]—to be embedded within an RSS feed. This enables contextual information to be passed along within the body of the RSS feed to a downstream application that could then provide the consumer of the feed with context-sensitive services. Use cases presented in the module include simple preservation of state, walking a 'feed of feeds' hierarchy, and a request for contextual services. We intend to republish this module shortly and realign it with the new ANSI/NISO standard for the OpenURL Framework, once published. One well-known RDF vocabulary that might be used to advantage with RSS is FOAF [26], the 'Friend of a Friend' vocabulary [n11]. The FOAF vocabulary includes terms to describe people and their work, which seems to us like an interesting area to explore in connection with authors of our content. It is intriguing to consider that FOAF terms could be used together with the OpenURL Framework to give a rich description of an OpenURL requester—and hence the recipient of context-sensitive services. And these separate data structures, by following a common data model, can be embedded within a single RSS feed. Syndication and Annotation in UseSo, what are publishers using RSS for? One obvious application is as an alerting service for tables of content information, or (as in the case of Ingenta) to send out notifications of new issues without going down to the article level. Some publishers (notably Nature Publishing Group, International Union of Crystallography, Ingenta) are already adding rich metadata using both the Dublin Core and PRISM term sets, while other publishers (BioMed Central, Institute of Physics, Oxford University Press, Extenza) are providing basic Dublin Core. (We note that BioMed Central is also now beginning to develop RSS feeds enhanced with PRISM metadata.) Table 1 charts some known RSS offerings from science publishers that we are aware of (with apologies for any errors or omissions).
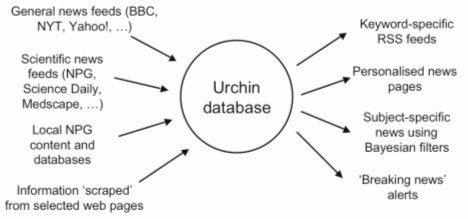
Beyond providing a basic alerting service, we note that science publishers are also offering RSS feeds for a whole range of other news services—jobs, product data, events, etc. But it is not just news of the moment that RSS is suited for. Another important use case is to build up and maintain an archive of RSS feeds [n12] that constitute a repository of structured data. Why is this useful? Simply that RSS provides an open means of structuring or packaging metadata, and many code libraries are available to applications to parse this data transparently. But RSS is not just for syndicating textual information, it is also being used to transmit complete scientific data sets. For example, Peter Murray-Rust and Henry Rzepa are using RSS to deliver chemistry data encoded as CML (Chemical Markup Language) [27] and are experimenting with MathML (Mathematical Markup Language) and SVG (Scalable Vector Graphics), while biological databases such as WormBase [28] and Reactome [29] are beginning to issue RSS feeds for news and may also be expected to use RSS to deliver data sets. An even more recent trend in RSS is podcasting [30], whereby audio and image data can be downloaded to an iPod or similar handheld device. In this latter case, the RSS feed does not contain the content but rather references to that content that an application can use to load the actual data to an appropriate rendering device. Will librarians and other service providers want to, or even be able to, make use of additional metadata included within RSS feeds? We do not know, but still we are optimistic that third-party services can be built on top of rich data payloads. At NPG we are also experimenting with providing an OpenURL interface into our growing RSS archive, which is essentially a repository of bibliographic metadata. This does beg the question of why NPG and other publishers should want to syndicate their metadata. Our view is that providing RSS is a natural means of expanding web-based interfaces into NPG content. In essence, RSS allows us to dramatically increase the surface area of our website and to project that presence across the Web. Moreover, by disseminating DOI identifiers [n13] via RSS we have a much-expanded set of stable and persistent access points into our content. A second reason is the downstream potential for generating advertising revenue. It is largely accepted, even generally expected, that RSS will be used to deliver advertising [n14], the only real outstanding question is: 'How?'. And thirdly, by providing descriptive (and rights) metadata within RSS feeds we enable the development of a whole raft of new applications that can exploit this additional information to good effect: the more data about our content, the more routes into it. It is still unclear what the general takeup of RSS will be within science publishing at large, although we see evidence of a continued growth. Other publishers may choose to be more cautious in releasing their metadata. They may also want to assess what ROI (or return on investment) they can expect before making RSS feeds available. It remains to be seen what penetration RSS achieves within the overall science publishing community, but there would be an obvious network effect were more publishers to adopt this technology with a consequent win/win for all. RSS and Other Syndication FrameworksOther notable syndication frameworks include Information Content Exchange (ICE) [31] from the publishing industries for syndicating content, while the digital library community has been actively deploying the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) [32] for syndicating metadata. Both of these frameworks support full transaction-based means for exchanging data, and also simpler web-based modes, which more closely resemble RSS. ICE is a protocol developed by the IDEAlliance grouping of industry content providers and software vendors to automate the scheduled, reliable and secure redistribution of valued content for publishers and for non-commercial content providers. ICE 2.0 distinguishes between levels of conformance. Basic ICE is comparable in complexity and capabilities to RSS and provides for an ICE catalog and packaging to be retrieved via HTTP, while Full ICE offers both push and pull delivery of ICE packages over SOAP, subscription management, incremental updates and delivery confirmation. ICE manages the syndication relationship and business rules that have been pre-established between syndicator and subscriber. It also allows for arbitrary content items to be packaged within a SOAP message format—even RSS feeds can be syndicated through the ICE packaging mechanism. But while the primary focus of ICE is on facilitating reliable, business to business (B2B) transactions, RSS is better suited as a simple, easy-to-use consumer solution to syndication and is now very well established and has good tools support. So, how does RSS stack up against OAI-PMH? Well, they both build on the same common technologies although their intents are rather different. Both use XML documents that are transported over HTTP, and both can support multiple vocabularies, although RSS is predominantly used for syndicating content (usually via references to that content), while OAI-PMH is primarily focussed on the job of harvesting metadata. RSS defines a simple encapsulation methodology that can be used by several classes of applications—typically (though not limited to) RSS readers, while OAI-PMH defines both a schema and an application-level protocol. RSS is particularly suited to lightweight data transfers to the user desktop or handheld, while OAI-PMH was developed to manage system-to-system processes (typically institutional repository-to-repository synchronizations). We should mention that small collections of metadata records (though potentially much larger than typical RSS feeds) can be exposed through an OAI static repository [33], not dissimilar from an RSS feed. Such OAI static repositories can also be accessed through OAI-PMH gateways. An interesting paper by Monica Duke in last October's issue of Ariadne [34] describes how OAI-PMH records can be delivered using RSS. This work, funded under the JISC/NSF Digital Libraries Initiative II, allows subject gateways from the UK Resource Discovery Network (RDN) to disclose their OAI-PMH record interchange format as RSS 1.0 feeds. This facilitates resource sharing and makes RDN subject gateway content accessible to a wider range of users and applications. RSS is best considered as a truly web-centric technology in that it is inherently dumb and defers all the 'smarts' to peripheral processes. Rather than mandate compliance, RSS can be freely repurposed and reinvented. A key differentiator between RSS and other syndication protocols is that RSS is mainly cut out to be a business to consumer (B2C) solution: it is lightweight and generally does not ship any significant volume of data. It is also a format for broadcast rather than narrowcast and is not supportive of point-to-point contracts. As free as cash, the RSS approach to metadata dissemination [n15] is, like the Web itself, cheerfully promiscuous and allows for, even encourages, casual and anonymous encounters with a consequent propensity for good or for bad. Urchin–An RSS AggregatorNPG's interests in RSS extend well beyond the production of RSS feeds. A new server-side application that has been developed by NPG is Urchin [35]—an open-source aggregator designed to aggregate and filter RSS feeds and other data sources. Urchin was initially funded by the JISC in the UK through its PALS Metadata and Interoperability Group [36] as Project ROSA [37], although further development has been funded directly by NPG. The basic design of Urchin was determined in-house while the bulk of the coding was contracted out to the independent software house NeoReality [38]. Urchin is an open-source application and is freely available from SourceForge [39]. It is a classic LAMP implementation, in that it has been developed using the open-source software components Linux, Apache, MySQL and Perl. It is, however, not confined to Linux alone and has been successfully ported to run on other Unix'es (Mac OS X, as well as the Windows Unix emulation layer Cygwin) and on Windows. Any webserver will do although Apache is required if mod_perl (the persistence mechanism for embedding a Perl interpreter within Apache) is to be used. There has been some consideration given to allowing for alternative database instances, e.g., Oracle, but no development work has yet taken place. The basic functionality of Urchin is to ingest information from a variety of data sources (including all flavours of RSS and Atom as well as screen-scraped HTML pages and even databases), to store that information internally and to emit on request a filtered information set expressed in a selected presentation format. Figure 5 shows a general overview of Urchin functionality. Urchin is primarily concerned with consuming any flavour of RSS or Atom that it normalizes to RSS 1.0 on data import, although metadata peculiar to other flavours, e.g., RSS 2.0, is also captured within its internal tables. It maintains an RDF triple store for storing arbitrary properties embedded within RSS 1.0 feeds. This demonstrates another benefit of the use of the RDF data model in RSS 1.0. The inherently relational structure of the open RDF data model means that any arbitrary metadata within an RSS 1.0 feed (including those that are from vocabularies that are unknown to the application or its developers) can be captured without loss in a simple triple store table structure. In contrast, it is not feasible to create a relational schema for capturing arbitrary metadata in proprietary XML.
The latest version of Urchin released to SourceForge supports filtering by channel aggregates, keywords, specific data fields and Boolean queries. It further supports full RDF queries using RCQL (the RDF::Core::Query [40] language). Internally, NPG uses Urchin to provide keyword-filtered RSS feeds for its staff, and to populate a science, technology and publishing news portal. In these cases, Urchin is used to generate RSS feeds that pick out stories mentioning a certain word from among its sources. It can, however, also be used to query on specific metadata fields, e.g., selecting stories that have a particular value for dc:creator, say, providing an author-specific RSS feed. The RDF capabilities of Urchin mean that the metadata fields that can be queried are unlimited. Certain common RDF properties, such as dc:creator, dc:date, dc:subject, are dealt with as special cases and querying is fast, but currently there is a noticeable performance degradation when querying on non-builtin RDF properties. More selective queries still can be built up using Boolean logic combinations. Urchin DeliverablesUrchin's first public outing has been to provide the My News features on the recently released News@Nature service that replaced the previous Nature Science Update (NSU) service. This demonstrates a 'hidden' use of RSS as an internal data transport mechanism that combined with the flexible filtering capabilities of Urchin allows users to customize their news pages by selecting keywords. New, Urchin-driven services in the pipeline are RSS feeds that deliver subject cross-cuts by selecting on subject rather than on product, as well as personalized RSS feeds. A simple but effective application of Urchin is Urchin Talk. We use this to query Urchin using a Bayesian filter (see below) and to write the output as entries to an internal blog. It is almost uncanny to see this work in practice. We have been surprised on at least two occasions when questions we have separately raised were found to have been already blogged by Urchin Talk. We have even joked that Urchin could steer its own future development. Urchin Next StepsNew directions for Urchin include Bayesian filtering, burst detection, and latent semantic indexing. Bayesian filtering is currently being experimented with in-house on subject-specific news areas with very satisfactory results. A Bayesian filter is trained by assigning items to subject categories. The filter then predicts the categories for newly encountered items using word frequencies and Bayesian statistics. Another experimental application—burst detection using an algorithm by Jon Kleinberg of Cornell University [41]—has also proved to return useful results. This takes advantage of the huge body of textual data in the Urchin data store and uses Kleinberg's algorithm to identify sudden bursts in the frequency of words or phrases. These can then be equated with hot topics. We have had some notable success here, but this is still an area very much under development. Looking further afield, an even more challenging application is latent semantic indexing, an approach that can be used to identify related items across time and channels. It can also identify commonly co-occurring words. This allows related stories to be identified even if they don't share common keywords. One aspect of Urchin that is currently being researched is the performance of its triple store. Jim Hendler's group at the University of Maryland [42] have been using the open-source triple store Kowari [43] as a replacement for Urchin's native MySQL-based store. Although they have not tested Kowari with any large amount of data, their opinion was that the MySQL version is faster for simple queries, but that Kowari is likely to be faster when querying triple-store data. There are a number of other candidate RDF stores that could also be used [n16]. And finally some preliminary work has been conducted to look at a more overreaching change to Urchin architecture in which arbitrary RDF, not just RSS, could be imported. This poses certain challenges. For example, one can aggregate RDF across multiple sources but it is currently unclear how to deal with the accumulation of RDF data that changes over time. ConclusionsRSS is increasingly being deployed within science publishing, and the reasons for this are manifold. RSS presents a very simple XML structure for packaging news titles and links, and delivering them down to user desktops and handhelds. Associated as it is with the burgeoning new technologies of blogs and wikis, RSS has received a significant impetus to growth. There is already a general public awareness of RSS, and it is being widely implemented. There is also growing support from browser vendors, and a number of the common browsers now have some degree of built-in RSS functionality. Indeed, it is becoming almost ubiquitous [n17]. It provides a ready B2C channel and can also be used in simpler B2B contexts. While several flavours of RSS exist, we believe that RSS 1.0 remains currently the most flexible and useful format. (It is too early to predict where the development of Atom will eventually lead.) As an RDF profile, it provides an open data model and can accommodate any RDF vocabulary. Moreover, terms from multiple vocabularies can be transported within a single RSS 1.0 feed, and that feed can be merged with other RSS 1.0 feeds and also with other arbitrary RDF descriptions. That in itself is a powerful inducement to choosing RSS 1.0. For our purposes, we make extensive use of the Dublin Core and PRISM vocabularies. We have also defined an early jobs vocabulary and are considering the use of other vocabularies such as FOAF. We note that OpenURL data structures can also be natively expressed within RSS 1.0 feeds. The server-side RSS aggregator Urchin, developed by NPG, has proved to be a useful building block for new applications. This is not just an academic research tool but has already been pressed into commercial use in NPG's News@Nature product, and is also being used for internal applications within NPG. Urchin is open-source code, deposited at SourceForge, and is freely available for others to make use of. Further development of Urchin aims to provide support for new and more sophisticated means of data mining such as Bayesian filtering, burst detection and latent semantic indexing. Notesn1. It is interesting to note that ten years ago on Oct. 13, 1994, a certain new browser was first announced—Netscape. And ten years on, we now have its latest successor that has just recently been released as a production tool—Firefox. n2. The term 'disruptive technology' was coined by Clayton Christensen [44]. n3. RSS has been variously interpreted over the years as 'Rich Site Summary', 'RDF Site Summary', 'Really Simple Syndication', and as a first-class name in its own right - 'RSS' with no expansion. The RSS 1.0 specification claims 'RDF Site Summary', while the RSS 2.0 specification opts for 'Really Simple Syndication'. The newcomer on the block has the distinction of not calling itself 'RSS', but rather 'Atom'. n4. A useful resource listing for RSS applications is the Open Directory page on RSS news readers [45]. Popular server-side aggregators include Bloglines [46], Feedster [47], PubSub [48], and Technorati [49]. n5. A new book Beginning RSS and Atom Programming by Danny Ayers and Andrew Watt [50] is currently in preparation and should be available in early 2005. n6. The term 'view source' relates to the ability of browsers to render the source HTML markup to users, which was a remarkable fillip to the early adoption of HTML in that one user could see how another had coded their markup to achieve a particular format layout. n7. Ben Hammersley has confirmed to us that a new (and much expanded) edition of his book Content Syndication with RSS and Atom, 2nd Ed. [9] is in preparation and should be available in early 2005. n8. Current figures from online services suggest that the total number of RSS feeds may be approaching the region of some 10 million, around half of which are active. Bob Wyman provides some rough numbers on a recent post to the rss-dev mailing list [51]. n9. RSS 1.0 modules are commonly referred to using a mod_* nomenclature, e.g., mod_dc for the Dublin Core module, mod_prism for the PRISM module, etc., although these terms have no official status. n10. A PURL is a Persistent Uniform Resource Locator [52]. Functionally, a PURL is a URL. However, instead of pointing directly to the location of an Internet resource, a PURL points to an intermediate resolution service. The PURL resolution service associates the PURL with the actual URL and returns that URL to the client. n11. Leigh Dodds has posited that FOAF provides a mechanism to tie together people, projects, and papers. It therefore has potential within an information discovery tool, allowing related researchers, papers, etc. to be explored. FOAF provides a means to capture, in an extensible manner, a person's research output (who authored which documents) and can also help in the creation and maintenance of research communities, e.g., conferences. n12. The simple term RSS 'feed' may be superior to the term RSS 'newsfeed' with its particular emphasis on timeliness, as news stories are by no means the only use for RSS. We note also that the term 'webfeed' is gaining some currency. n13. The Digital Object Identifier (DOI) is a system for managing intellectual property resources in the digital environment [53]. It is based on the Handle System® developed at the Corporation for National Research Initiatives. DOIs are persistent identifiers assigned to entitities and are used to provide service-level information, including where they (or information about them) can be located on the Internet. n14. Several initiatives are currently underway to provide ads in RSS. These include BlogAds [54]—a network of bloggers accepting advertising, RssAds [55]—an ad network that describes itself as a provider for a full-service outsourced ad bureau that makes buying and selling ads in RSS feeds easier, Pheedo [56]—with a focus on monetizing the content of micro-publishers, and FeedBurner [57]—with a new pilot program that embeds ads in the feeds of some of the company's content-publishing partners. n15. By 'RSS approach' we intend a simple, REST-based means of disclosing metadata within XML documents that aggregators can get on demand with no restrictions on URI naming and a flexible attitude as to which elements are included in the documents and which schemas are followed. n16. Other common RDF data stores or frameworks that support persistence include 3store [58], Jena [59], RDFStore [60], Redland [61], and Sesame [62]. n17. The next version of Microsoft Windows, codenamed Longhorn, expected in 2006 is rumoured to have RSS functionality, while the next version of Mac OS X, codenamed Tiger, includes Safari RSS and is due to be shipped in the first half of 2005. References1. del.icio.us. <http://del.icio.us/>. 2. Flickr. <http://www.flickr.com/>. 3. Furl. <http://www.furl.net/>. 4. JotSpot. <http://www.jotspot.com/>. 5. Berners-Lee, T., Information Management: A Proposal. CERN document, March 1989, May 1990. <http://www.w3.org/History/1989/proposal.html>. 6. Nature Publishing Group, Macmillan Publishers Ltd. <http://npg.nature.com/>. 7. Beged-Dov, G., Brickley, D., Dornfest, R., Davis, I., Dodds, L., Eisenzopf, J., Galbraith, D., Guha, R.V., MacLeod, K., Miller, E., Swartz, A. and van der Vlist, E., RSS 1.0 specification. <http://purl.org/rss/1.0/spec>. 8. RDF Site Summary 1.0 proposed modules. <http://purl.org/rss/1.0/modules/proposed.html>. 9. Hammersley, B., Content Syndication with RSS, 1st ed., O'Reilly & Associates, 2003. 10. Hammond, T., Why choose RSS 1.0?, XML.com, July 2003. <http://www.xml.com/pub/a/2003/07/23/rssone.html>. 11. Ayers, D., Extending RSS, XML.com, July 2003. <http://www.xml.com/pub/a/2003/07/23/extendingrss.html>. 12. The Atom Project. <http://www.intertwingly.net/wiki/pie/FrontPage>. 13. Winer, D., RSS 2.0 Specification, Berkman Center for Internet & Society at Harvard Law School. <http://blogs.law.harvard.edu/tech/rss/>. 14. Dublin Core Metadata Initiative. <http://dublincore.org/>. 15. Beged-Dov, G., Brickley, D., Dornfest, R., Davis, I., Dodds, L., Eisenzopf, J., Galbraith, D., Guha, R.V., MacLeod, K., Miller, E., Swartz, A. and van der Vlist, E., RDF Site Summary 1.0 Modules: Dublin Core. <http://purl.org/rss/1.0/modules/dc/>. 16. Croome, C., RDF Site Summary 1.0 Modules: Qualified Dublin Core. <http://purl.org/rss/1.0/modules/dcterms/>. 17. IDEAlliance (International Digital Enterprise Alliance). <http://www.idealliance.org/>. 18. PRISM. <http://www.prismstandard.org/>. 19. Hammond, T., Hannay, T. and Lund, B. RDF Site Summary 1.0 Modules: PRISM. <http://purl.org/rss/1.0/modules/prism/>. 20. PRISM: Publishing Requirements for Industry Standard Metadata, Version 1.2. <http://www.prismstandard.org/specifications/Prism1[1].2RFC.pdf>. 21. AdsML Consortium. <http://www.adsml.org/>. 22. Downes, S. RDF Site Summary 1.0 Modules: Learning Object Metadata. <http://www.downes.ca/xml/RSS_LOM.htm>. 23. IEEE 1484.12.1-2002, Draft Standard for Learning Object Metadata, 15 July 2002. <http://ltsc.ieee.org/wg12/files/LOM_1484_12_1_v1_Final_Draft.pdf>. 24. Hammond, T., Hannay, T., Neylon, E. and Van de Sompel, H. RDF Site Summary 1.0 Modules: Context. <http://purl.org/rss/1.0/modules/context/>. 25. National Information Standards Organization, The OpenURL Framework for Context-Sensitive Services, ANSI/NISO Standard Z39.88-2004, NISO Press, Bethesda, Maryland, USA (to be published). 26. Brickley, D. and Miller, L. FOAF Vocabulary Specification, Namespace Document 2 Sept 2004, FOAF Galway Edition. <http://xmlns.com/foaf/0.1/>. 27. Murray-Rust, P., Rzepa, H. S., Williamson, M. J. and Willighagen, E. L., Chemical Markup, XML and the Worldwide Web. Part 5. Applications of Chemical Metadata in RSS Aggregators. J. Chem. Inf. Comp. Sci., 2004, 44, 462-469. 28. WormBase Release WS134. <http://www.wormbase.org/>. 29. Reactome—a Knowledgebase of Biological Processes. <http://www.reactome.org/>. 30. Podcasting, (definition of). <http://en.wikipedia.org/wiki/Podcasting>. 31. ICE 2.0 Specification. <http://www.idealliance.org/ice/>. 32. Lagoze, C., Van de Sompel, H., Nelson, M. and Warner, S., The Open Archives Initiative Protocol for Metadata Harvesting, Protocol Version 2.0 of 2002-06-14, Document Version 2004/10/12T15:31:00Z. <http://www.openarchives.org/OAI/2.0/openarchivesprotocol.htm>. 33. Lagoze, C., Van de Sompel, H., Nelson, M., Warner, S., Hochstenbach, P. and Jerez, H., Specification for an OAI Static Repository and an OAI Static Repository Gateway, Protocol Version 2.0 of 2002-06-14, Document Version 2004/04/23T15:17:00. <http://www.openarchives.org/OAI/2.0/guidelines-static-repository.htm>. 34. Duke, M., Delivering OAI Records as RSS: An IMesh Toolkit module for facilitating resource sharing, Ariadne, October 2003. <http://www.ariadne.ac.uk/issue37/duke/>. 35. Urchin RSS Aggregator. <http://urchin.sf.net/>. 36. Publishers and Library/Learning Solutions (PALS) Metadata and Interoperability Group, The Joint Information Systems Committee. <http://www.jisc.ac.uk/index.cfm?name=programme_pals>. 37. ROSA: An Open Source, Customisable RSS Aggregator and Filter, The Joint Information Systems Committee. <http://www.jisc.ac.uk/index.cfm?name=project_rosa>. 38. NeoReality. <http://www.neoreality.com/>. 39. SourceForge.net. <http://www.sourceforge.net/>. 40. Ginger Alliance, RDF::Core::Query. <http://search.cpan.org/~dpokorny/RDF-Core/lib/RDF/Core/Query.pm>. 41. Kleinberg, J. Bursty and Hierarchical Structure in Streams. Proc. 8th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining, 2002. <http://www.cs.cornell.edu/home/kleinber/bhs.pdf>. 42. MINDSWAP—The Semantic Web Research Group, MIND Lab, University of Maryland Institute for Advanced Computer Studies. <http://www.mindswap.org/>. 43. Kowari Metastore. <http://www.kowari.org/>. 44. Christensen, C. The Innovator's Dilemma, When New Technologies Cause Great Firms to Fail. Harvard Business School Press, 1997.
45. Open Directory Project, RSS News Readers. <http://dmoz.org/Reference/Libraries/Library_and_Information_Science/ 46. Bloglines. <http://www.bloglines.com/>. 47. Feedster. <http://www.feedster.com/>. 48. PubSub. <http://www.pubsub.com/>. 49. Technorati. <http://www.technorati.com/>. 50. Ayers, D. and Watt, A., Beginning RSS and Atom Programming, Wrox, (to be published). 51. Wyman, B. <http://groups.yahoo.com/group/rss-dev/message/6720>. 52. The PURL Project. <http://purl.oclc.org/>. 53. The Digital Object Identifier System. <http://www.doi.org/>. 54. BlogAds. <http://www.blogads.com/advertiser_html>. 55. RssAds. <http://www.rssads.com/default.htm>. 56. Pheedo. <http://pheedo.com/publishers/>. 57. FeedBurner. <http://www.feedburner.com/>. 58. 3store. <http://www.aktors.org/technologies/3store/>. 59. Jena. <http://jena.sourceforge.net/index.html>. 60. RDFStore. <http://rdfstore.sourceforge.net/>. 61. Redland. <http://librdf.org/>. 62. Sesame. <http://www.openrdf.org/>. (On December 20, 2004, at the authors' request, the spelling of Stephen Downes name was corrected and the date of publication in reference 25 was removed. On January 17, 2005, the meaning of the acronymn PRISM was changed from 'Publisher Requirements for Industry Standard Metadata' to 'Publishing Requirements for Industry Standard Metadata') (The URL for reference 31 (the ICE Standard) was corrected on June 4, 2008.) Copyright © 2004 Tony Hammond, Timo Hannay, and Ben Lund |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/december2004-hammond
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||