|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Tony Hammond, Timo Hannay, Ben Lund, and Joanna Scott |
![]()
IntroductionBecause, to paraphrase a pop music lyric from a certain rock and roll band of yesterday, "the Web is old, the Web is new, the Web is all, the Web is you", it seems like we might have to face up to some of these stark realities [n1]. With the introduction of new social software applications such as blogs, wikis, newsfeeds, social networks, and bookmarking tools (the subject of this paper), the claim that Shelley Powers makes in a Burningbird blog entry [1] seems apposite: "This is the user's web now, which means it's my web and I can make the rules." Reinvention is revolution – it brings us always back to beginnings. We are here going to remind you of hyperlinks in all their glory, sell you on the idea of bookmarking hyperlinks, point you at other folks who are doing the same, and tell you why this is a good thing. Just as long as those hyperlinks (or let's call them plain old links) are managed, tagged, commented upon, and published onto the Web, they represent a user's own personal library placed on public record, which – when aggregated with other personal libraries – allows for rich, social networking opportunities. Why spill any ink (digital or not) in rewriting what someone else has already written about instead of just pointing at the original story and adding the merest of titles, descriptions and tags for future reference? More importantly, why not make these personal 'link playlists' available to oneself and to others from whatever browser or computer one happens to be using at the time? This paper reviews some current initiatives, as of early 2005, in providing public link management applications on the Web – utilities that are often referred to under the general moniker of 'social bookmarking tools'. There are a couple of things going on here: 1) server-side software aimed specifically at managing links with, crucially, a strong, social networking flavour, and 2) an unabashedly open and unstructured approach to tagging, or user classification, of those links. A number of such utilities are presented here, together with an emergent new class of tools that caters more to the academic communities and that stores not only user-supplied tags, but also structured citation metadata terms wherever it is possible to glean this information from service providers. This provision of rich, structured metadata means that the user is provided with an accurate third-party identification of a document, which could be used to retrieve that document, but is also free to search on user-supplied terms so that documents of interest (or rather, references to documents) can be made discoverable and aggregated with other similar descriptions either recorded by the user or by other users.
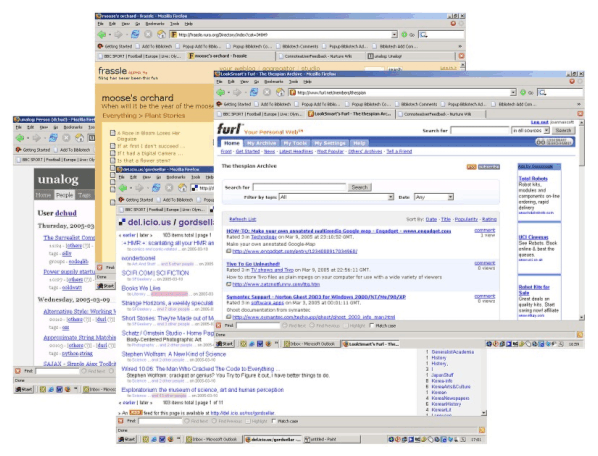
(For a larger view of Fig 1., click here.) Matt Biddulph in an XML.com article last year [2], in which he reviews one of the better known social bookmarking tools, del.icio.us [3], declares that the "del.icio.us-space has three major axes: users, tags, and URLs". We fully support that assessment but choose to present this deconstruction in a reverse order. This paper thus first recaps a brief history of bookmarks, then discusses the current interest in tagging, moves on to look at certain social issues, and finally considers some of the feature sets offered by the new bookmarking tools. A general review of a number of common social bookmarking tools is presented in the annex. A companion paper [4] describes a case study in more detail: the tool that Nature Publishing Group [5] has made available to the scientific community as an experimental entrée into this field – Connotea [6]; our reasons for endeavouring to provide such a utility; and experiences gained and lessons learned. Links – History & FormWhere do links begin? Links are as old as the Web itself [n2]. Indeed, links are the stuff of the Web [n3]. But the idea of organizing and managing links systematically rather than just listing them on a given web page seems to have emerged with the earliest graphical browsers, and, in particular, with the foremost browser of its time, Mosaic [n4], the granddaddy of all modern browsers. The simple discipline of presenting link directories arranged on a menu page in nested list form harks back to earlier, more rigid information systems such as Gopher [n5]. The Web, however, was supposed to be different with nodes of information connected in a truly open, free-form manner rather than being accessible only by navigating a strict, pre-determined path hierarchy within a single authority domain. Mosaic developed a feature called Hotlists, which, while still hierarchical and aping the common file system paradigm of folders and files, at least allowed for links to be easily recorded and for ready access to any recorded link from any page within the browser. By the time the initial development crew had decamped from NCSA [n6] to set up a commercial operation [n7] and built the new, line-in-the-sand Netscape browser, this feature had become reincarnated as Bookmarks. Meanwhile, Microsoft, finally catching the wave, was engineering a vigorous response to the new, upstart Netscape browser. This was to be called Internet Explorer and included a similar link manager that was dubbed Favorites. Bookmarks or Favorites had now become an integral part of users' everyday web experience and would remain so until powerful search engines such as Google and Yahoo! came knocking on the door. Because, while bookmarks allowed users to record sites of interest, they soon grew to become unwieldy in terms of needing to be managed within the confines of a simple, hierarchical structure. It became apparent with the growing power of the new search engines that it was easier just to search for a particular site afresh each time – in effect, search engines were now able to provide a dynamic bookmarking service, or bookmarks on demand. Taxonomies, however, were not done for. Early collaborative attempts to build out a shared taxonomy, rather than develop a personal hierarchy of links, resulted in such endeavours as the Open Directory Project [7] and Zeal [8], as well as commercial operations like Yahoo! [9]. But these web-based directories would soon struggle against the ever encroaching advance of the search engine. A striking development in bookmark technology was the so-called 'bookmarklet' [n8]. Bookmarklets appear as simple links and can be treated and stored as regular bookmarks but actually contain embedded JavaScript code that is executed when the link is activated. They have been pressed into multiple ingenious uses, from running a search on a piece of selected text to more sophisticated applications such as Jon Udell's 'Walking Tour of Keene' [10]. The possibilities are endless, and they provide an effective means of extending a browser's functionality while remaining simple to install and use. But even while search engines were becoming ever more prescient at second-guessing user goals and managing user expectations, another development was beginning to cook up in the background. These would become the social link managers, with links not randomly discovered or crawled by robots and spiders, but registered, tagged and rated by users for their own benefit, and made available to other users [n9]. Robot wisdom was increasingly being challenged by the 'buzz latency' [11] that such a shared personal recommendation system creates. Architectures of ParticipationOriginally elaborated in relation to open-source software development, but equally applicable to any online community, Tim O'Reilly has talked about an 'architecture of participation' [12] whereby a grassroots user base creates a self-regulating collaborative network. The result of this approach is that the best applications become more useful for all participants the more that people make use of them. The online auctioneer eBay [13] is a classic example of this 'network effect' of users coming together for the benefit of all, although there are many others. Wikipedia [14], the free encyclopedia, with user-generated content produced at a fraction of the cost of more established publishers and at an unparalleled speed of delivery (sometimes extending to almost real-time updates), is just such another successful, self-regulating system. Other examples would, of course, have to include Amazon.com [15], Slashdot [16], and craigslist [17]. Within the scholarly domain one can also point to the e-print repository arXiv [18] and the catalog of online learning materials MERLOT [19] as examples of architectures of participation. Social bookmarking tools also share this characteristic: the more they are used, the more value accrues to the system itself and thereby to all who participate in it. Tag SoupTraditional means of organizing information elements have generally relied on well-defined and pre-declared schemas ranging from simple controlled vocabularies to taxonomies to thesauri to full-blown ontologies [20]. This orderly approach to cataloguing allows for both the validation and quality control of known terms to be registered within an information system. By contrast, the new link managers tend to use dynamic categorization systems whereby the user annotates links with whatever terms seem most relevant. Links are generally annotated with 'tags', which are free-form labels assigned by the user and not drawn from any controlled vocabulary. This is very much a 'bottom-up' (or personal) approach compared with the traditional 'top-down' (or organizational) structured means of classification. This unstructured (or better, free structured) approach to classification with users assigning their own labels is variously referred to as a 'folksonomy' [n10], 'folk classification', 'ethnoclassification' [n11], 'distributed classification', or 'social classification'. Other terms that arise are 'open tagging', 'free tagging', and 'faceted hierarchy'. Following Adam Mathes in his paper 'Folksonomies – Cooperative Classification and Communication Through Shared Metadata' [21] we would generally incline to the term 'social classification', or even 'distributed classification', as this, to our minds, most closely describes the nature of the activity, although we must concede that the word 'folksonomy' has gained considerable currency and there is little getting away from it. There are various aspects to tagging that can be mentioned here although the reader is referred to some more considered pieces [n12]. Tags generally produce a flat namespace, rather than the hierarchical structures that a taxonomy or other formal classification system usually provides. This, of course, has its upsides and downsides. A formal classification system needs generally to be predictive both of the ordering of terms that are used within it, and of the terms that will be allowed (or tolerated) by it. By contrast, a free tagging approach to classification is a jumbled, hit-and-miss affair, and any system that it may throw up must be discovered, or learned, after the event. In many ways this approach to classification mimics the Web itself in microcosm, compared to earlier, more static, information systems like Gopher, which required some due diligence in arranging the nodes of information. Some proponents of tagging have been dismissive of formal classification systems, although we believe the two approaches to be complementary. As Clay Shirky has remarked [22]: "Ontology is a good way to organize objects, [...], but it is a terrible way to organize ideas, and in the period between the invention of the printing press and the invention of the symlink, we were forced to optimize for the storage and retrieval of objects, not ideas." We note there have been some attempts to introduce structure within tags. Some users have adopted private conventions to indicate hierarchy (or other structural relationships) within an otherwise flat namespace, but these indications are just intended for personal use and cannot as yet be leveraged to any common advantage. Another approach that has been discussed (and, in the case of del.icio.us even implemented as 'tag bundles') is the tagging of tags, which could result in the creation of hierarchical folksonomies. This is an area that is worth tracking – there are no rules as yet. Anecdotal evidence (see Jon Udell's screencast on del.icio.us [23]) supports the view that there is a natural tendency towards the convergence of tags. Strategies to facilitate this development are also possible. In a blog entry entitled 'Folksonomies: How we can improve the tags' [24], Lars Pind has suggested various possibilities including the following: a) 'suggest tags for me', b) 'find synonyms automatically', c) 'help me use the same tags others use', d) 'infer hierarchy from the tags', and e) 'make it easy to adjust tags on old content'. Currently only option e) appears to be in common use, presumably because it is the easiest to implement.
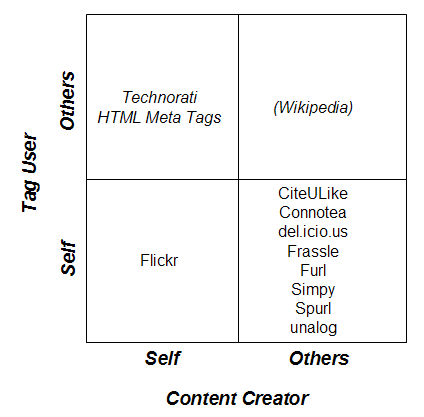
As can be seen in the screenshot shown in Fig. 2, it is noticeable that some systems (Flickr [25], especially) show a strong bias towards English language tags, although it should be noted that new regional bookmarking tools for French and Japanese users are already emerging [n13]. This is very much in the spirit of folk tagging, rather than requiring users to adopt terms from some master vocabulary defined in an alien language. What this means for tag reconciliation is hard to say, but even within a given language, tag reconciliation is always going to prove troublesome. To anyone familiar with top-down classification schemes, this approach could look like a fearful muddle. But this doesn't mean that it is without value – after all, the Web itself appears from the outside as a somewhat messy affair (almost its defining characteristic). Rather, this is an altogether different – and, we would argue, complementary – form of classification. Compared to the traditional top-down approach, folksonomy data is much noisier but also more flexible, more abundant and far cheaper. Bear in mind also that the terms used are, by definition, the very terms that real users might be expected to use in future when searching for this information. As Clay Shirky has pointed out [26], folksonomies move us from a 'binary' in-or-out classification system to an 'analogue' one in which items can exist in multiple categories, each weighted by relative popularity. When it comes to ranking by relevance (as opposed to merely identifying potentially relevant resources), this kind of data might actually be more useful than a much smaller number of tightly controlled keywords. Indeed, the whole social tagging approach bears more than a passing resemblance to Google's PageRank algorithm [27]. Reasons for TaggingThere are many reasons for tagging of content on the Web. Figure 3 aims to provide an overview of the motivators for tagging [n14]. There is a range from a 'selfish' tagging discipline, where the users are primarily tagging their own content for their own retrieval purposes, right through to a more 'altruistic' tagging discipline, where the user is tagging others' content for yet others to retrieve.
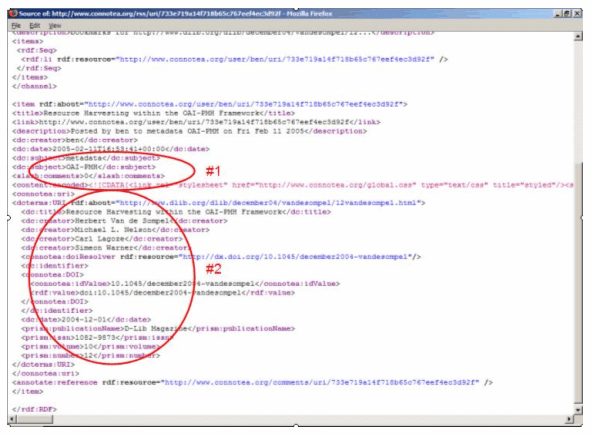
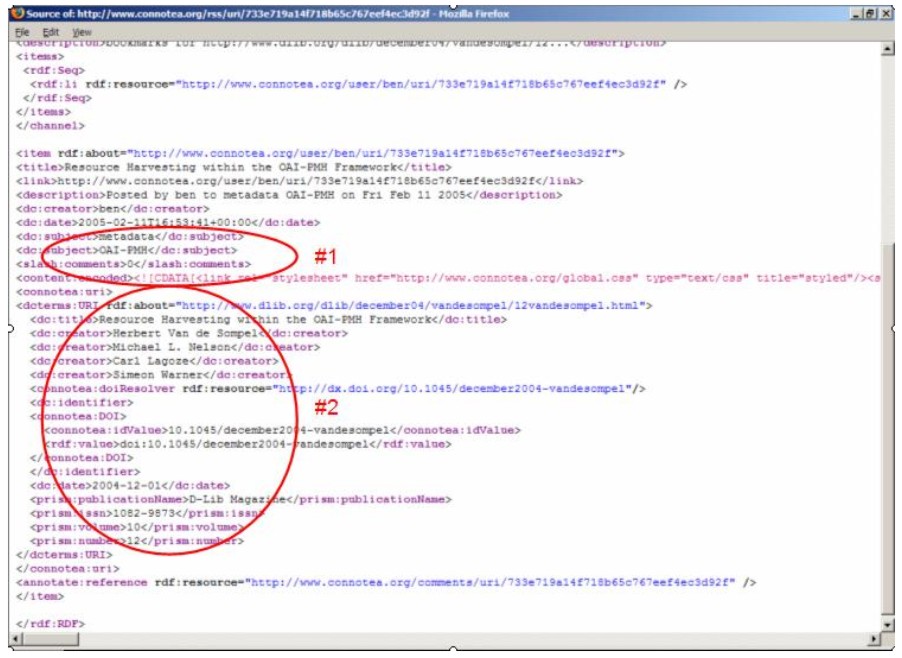
The nature of the application is largely responsible for driving a particular tagging practice. For example, Flickr users are generally managing personal collections of their own digital photos for private use or for sharing with friends and family, while the blog aggregator Technorati [28] uses tags supplied by the user (either presented within an RSS feed or linked to from the HTML page) to describe their blogs so that others may discover them. The majority of the social bookmarking tools reviewed in this paper fall into the category of users tagging others' content mainly for their own benefit, although the bookmarks and tags are generally public, and users can establish social networking opportunities. Folk FuturesDespite all the current hype about tags – in the blogging world, especially – for the authors of this paper, tags are just one kind of metadata and are not a replacement for formal classification systems such as Dublin Core, MODS, etc. [n15]. Rather, they are a supplemental means to organize information and order search results. Figure 4 shows the raw XML for an RSS feed of an item in Connotea describing the paper 'Resource Harvesting within the OAI-PMH Framework' by Herbert Van de Sompel et al. [29] from the December '04 issue of D-Lib Magazine. Clearly present are user-supplied tags describing the content of the paper, along with citation metadata supplied by Connotea from an authoritative source (in this case the structured metadata made available by D-Lib Magazine).
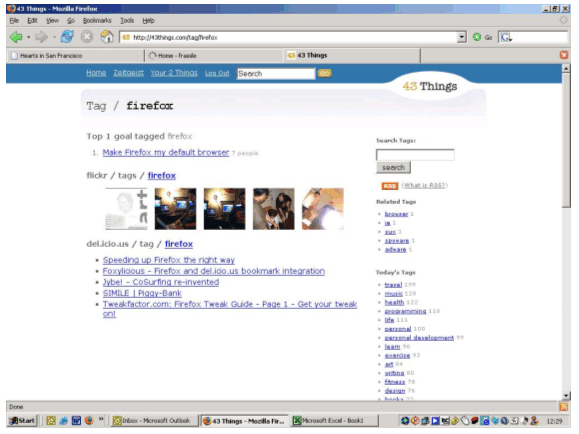
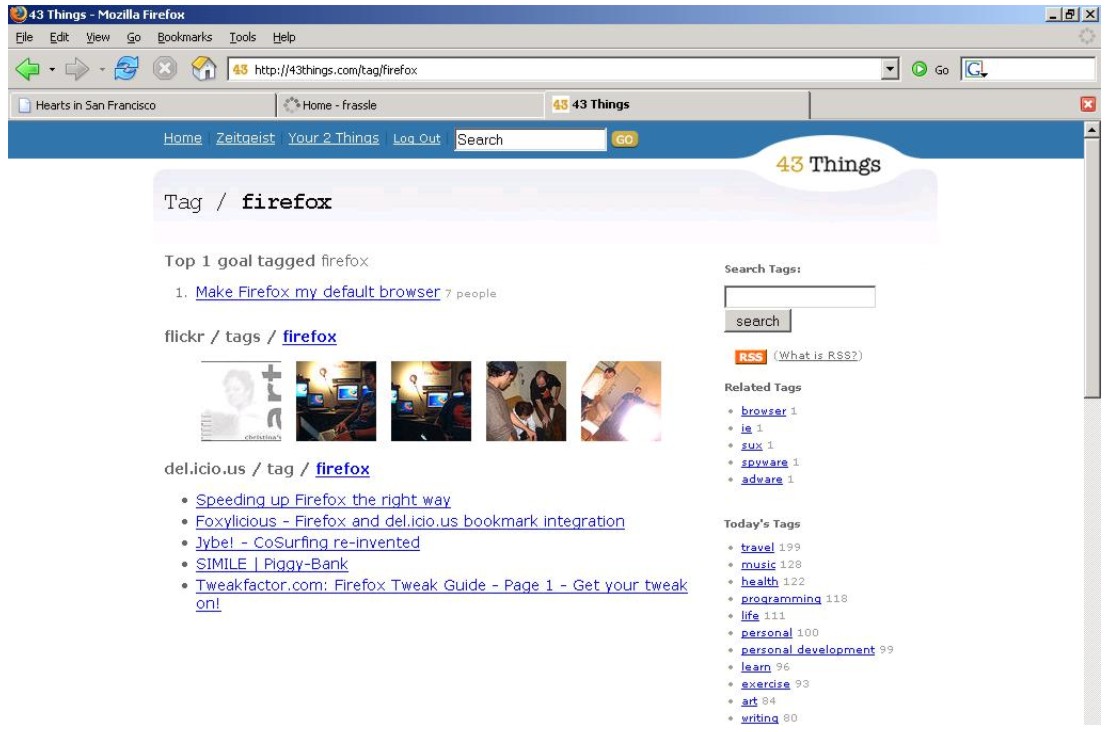
(For a larger view of Fig 4., click here.) One particularly creative tagging application is, 'Phonetags', a system created by the BBC and presented at the recent O'Reilly Emerging Technology Conference [30]. A listener hears a song on the radio, uses their cell phone to text back to a website with tags and star ratings. Later, returning to the website, the user can type in their phone number and see the songs they have bookmarked. Indeed, few are the things that cannot be tagged, at least in principle. These could include geographical locations, people and (as mentioned earlier) even tags themselves. The Social AxisThe third axis of Matt Biddulph's deconstruction (which was mentioned in the Introduction of this paper) is the user axis and how users can (and do) make use of these tools, which has both a local dimension and a global dimension. As Liz Lawley has blogged on Many 2 Many [31]: "Flickr and del.icio.us work so well for me not because they aggregate the world's tags, but because they allow me to aggregate my social network's tags, links, and photos. [...] I don't want to see "research" resources from a molecular biologist, but I do want to see them from a sociologist studying online social networks." This ability to sort out the wheat from the chaff is an important win over a web-based search engine. Search engines, at this point, tend to index and search a global space – not my local space. My space comprises the documents I am interested in and the documents of other users that I want to follow. Another important aspect on the social axis is user privacy. By publicizing their bookmarks, users are opening up to other users on the Web their own sphere of interests. (Note that some tools already support, or plan to support, the option of keeping certain bookmarks private.) Regardless of the fact that tools usually allow one to set up an account under a self-selected (perhaps obscure) username, this provides little guarantee of anonymity. The short answer to this is that social bookmarking tools, as with the Web at large, usually pay users back many times over in utility for whatever privacy they may have surrendered. But if absolute privacy is important, then it's certainly best to stay away from these tools (and, indeed, possibly the Web as a whole). A further issue to consider is tag spamming. E-mail has been severely impacted by spamming. Blog comments and trackbacks are similarly vulnerable to attack. Adware and spyware are already corrupting users' browsing experiences. There is no question but that spamming of these new social tools can and will occur – it almost goes with the territory that social forums will foster such 'parasites' and some instances have been noted already. So far, however, it does not seem to have been a major problem, largely because spam has been drowned out by legitimate use. But obviously, continuing vigilance must play a part, and robust defences may need to be put in place should this start to become problematic.Glue in the WorksAlmost without exception these social bookmarking tools are feature-rich, providing search on both users and tags (with Boolean operators), comments (and comment trails), simple linking syntaxes, and APIs (application programming interfaces) for posting to and from these tools (and to other tools such as blogs). Invariably the 'glue' technology used is RSS. RSS allows these tools to be hooked up easily. Examples abound. 43 Things [n16] – a service that records (up to) 43 user goals and allows users to share and tag these goals – can also search the del.icio.us and Flickr tag sets as shown in Fig. 5.
(For a larger view of Fig 5., click here.)
Many of these tools have a very easy-to-use, linking syntax. Below, for example, we show some examples as presented in the del.icio.us '
Other bookmark managers employ similarly straightforward link syntaxes. Through the use of such linking syntaxes and more fully evolved APIs, along with RSS as a channel for syndicating rich metadata, some of these social bookmarking tools may be well suited to participate in the general service autodiscovery space described by Dan Chudnov and Jeremy Frumpkin in their informal paper 'Service Autodiscovery for Rapid Information Movement' [33]. Building CommunitiesAs a simple demonstration of the way in which social bookmarking tools might benefit academic research, we show here how Connotea can be used by readers of this paper, and of its companion [4], to access the reference lists, to share other relevant links, and to trade comments on them and on the papers themselves.
First, we have selected the simple Connotea tag ' http://www.connotea.org/tag/dlib-sb-tools or, perhaps more conveniently, by signing up for the corresponding RSS feeds: http://www.connotea.org/rss/tag/dlib-sb-tools
If anyone would just like to focus exclusively on the related links posted by a particular user, e.g., user ' http://www.connotea.org/user/joanna/tag/dlib-sb-tools
A similar approach can be used to provide communal access to a static list of resources. By way of demonstration, we have selected the tag ' http://www.connotea.org/tag/dlib-sb-tools-refs However, to ensure that the reference lists are properly 'closed' (and that no further bookmarks that happen to be tagged by other users with the same ' http://www.connotea.org/user/tony/tag/dlib-sb-tools-refs
i.e., return the bookmarks tagged '
Likewise, we have tagged and made available the lists of related links (' http://www.connotea.org/tag/dlib-role-rss
Readers are invited to contribute new references to the related link lists for any of these three papers that they deem to be subject compatible by using the appropriate paper-specific tag, i.e., ' http://www.dlib.org/dlib/december04/hammond/12hammond.html All bookmarking events for these papers, i.e., the separate bookmarks and tags entered by individual users, are listed on the following pages, respectively: http://www.connotea.org/uri/8eedc88e80ce8c8350e4236e89569138 Comments on the papers themselves can be added on the following pages, respectively: http://www.connotea.org/comments/uri/8eedc88e80ce8c8350e4236e89569138 These approaches create a series of shared spaces that have the potential to become 'living' resources that maintain and extend the relevance of each paper beyond its initial publication. We are intrigued to see how this experiment might be taken forward by D-Lib Magazine readers. ConclusionsDifferently from the simple link manager functionality built into a browser, the new breed of link manager is a server-side web application that enables links to be tagged for easy retrieval and is increasingly being opened up to manage public rather than (or sometimes in addition to) private sets of links. The following elements are usually present in varying degrees:
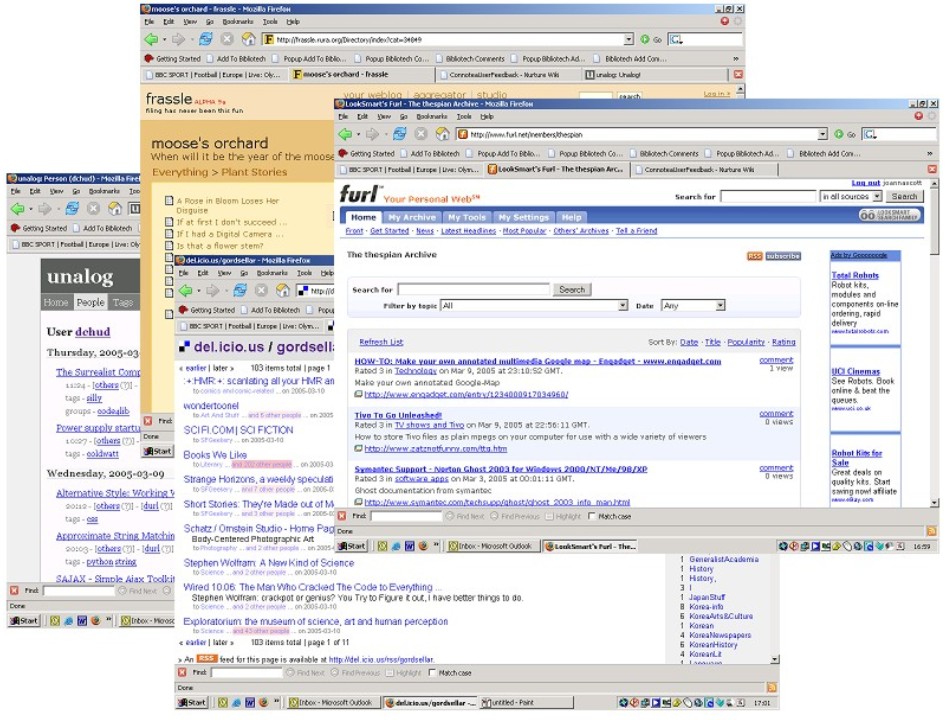
In many ways these new tools resemble blogs stripped down to the bare essentials. Here the essential unit of information is a link, not a story – but a link decorated with a title, a description, tags and perhaps even personal recommendation points. It is still uncertain whether tagging will take off in the way that blogging has. And even if it does, nobody yet knows exactly what it will achieve or where it will go – but the road ahead beckons. AcknowledgementsThe authors would like to thank Herbert Van de Sompel of the Los Alamos National Laboratory, Research Library and Tom Coates of BBC Radio and Music Interactive for reviewing this paper and for providing us with helpful insights and feedback. Annex – Review of ToolsThere are many open bookmarking tools available [35], a number of which fall loosely within the category of social bookmarking tools, by which we mean that they include some kind of a tagging or rating element. Some examples of this genre include Bag of URLs [36], BlogMarks.net [37], Dude, Check This Out! [38], Feed Me Links [39], Jots [40], Linkfilter [41], LiVEMARK [42], openBM [43], StumbleUpon [44], and Wists [45]. (Another new tool that is perhaps worth mentioning in passing is de.lirio.us [46], which is of interest on three counts: one, the code is open source; two, it sets bookmarked links up as blog templates; and three, content posted is covered by a Creative Commons license [47].) Here we choose to focus on a small number of social bookmarking tools that either have a strong public following (such as del.icio.us [3] and Flickr [25]), are known within the library community (such as Furl [48]) or have an academic focus (such as CiteULike [49], Connotea [6] and unalog [50]). We also add Frassle [51], Simpy [52] and Spurl.net [53] because these tools, while competing within the same space as the aforementioned, are also thriving examples. Figure 6 shows a lay-of-the-land overview of both the reviewed tools and some of the others with regard to a general or scholarly disposition, as well as with regard to whether links or web pages are being hosted.
Table 1 presents an overview of the tools that we have selected to review in this paper and provides a comparison of their public visibility, including history and usage, and business models. Table 2, by contrast, shows the feature sets for these same tools. We subsequently briefly discuss each tool in turn. (Note that Torsten Rox maintains a comparative chart [54] of more than a dozen social bookmarking tools, including may of those reviewed here. His chart has a much finer-grained feature comparison.) What is striking from Table 1 is that all these tools are of very recent public origin (almost all from 2004) although they may have had a longer private gestation. Also the tools we review here are equally split between academic, commercial and private sponsorships. All these tools are free to use but different business models are in place or under consideration to recoup or offset costs. These models range from offering advertising, paid-for premium accounts, donations, selling user data to ASPs, etc. Table 1. Reviewed Social Bookmarking Tools - Comparison
† Note that this column is intended to reflect the number of 'unique' tags. It is not always clear whether the numbers recorded here are for unique tags or total number of tags. For example, the number of tags quoted for del.icio.us is 2m, which may be rather high in view of the number of tags exceeding the number of links and also that the entire English vocabulary may only be around some 300k words – although note that tags are not limited either to 'words' or to a particular language such as English. (The figures quoted for del.icio.us were accessed from public sources with no corroboration as to meaning.) From Table 2 we can see that the academically inclined bookmarking tools offer RSS 1.0 with CiteULike and Connotea both providing rich Dublin Core and PRISM and unalog offering DC as per the recommendations we made in our earlier D-Lib Magazine paper The Role of RSS in Science Publishing [34]. It is also encouraging to see that one of the most popular bookmarking services – del.icio.us – is also offering RSS 1.0 with Dublin Core. Table 2. Reviewed Social Bookmarking Tools - Features
Tools
CiteULike Initially CiteULike allowed users to bookmark papers from specific websites that held academic content, and from which CiteULike was able to collect citation metadata. This restriction has since been lifted to allow bookmarking of any site, although the focus remains almost exclusively academic. CiteULike offers a number of features specifically for the academic community including importing references from desktop reference management software.
Connotea Connotea is also equipped to function as a citation manager and currently supports retrieval of metadata elements from a number of sites including PubMed, HubMed, Amazon.com, Nature.com, and D-Lib Magazine. Further development in this area is planned. A companion paper [4] reports in detail on Connotea as a case study in implementing a social bookmarking tool.
del.icio.us del.icio.us has attracted a great deal of interest from external developers: Foxylicious [55], a Firefox extension, and Cocoal.icio.us [56], a Cocoa del.icio.us client for Mac OS X, are typical of the many extensions to be found for del.icio.us.
Flickr Flickr has the widest user base of all these tools. This, perhaps, is not so surprising because it is built around photos – digital cameras and camera phones being prevalent these days – and there are very strong emotional drivers for sharing images. Flickr hosts users' photos on its own servers so that they are retrievable (in various size samplings) from anywhere over the Web. Flickr provides free user accounts, albeit bandwidth-capped for uploading, and premium paid-for accounts that limit the restrictions that are placed upon users. Photos can be aggregated into photosets and can be made public or private as desired. Applications built on top of Flickr include Mappr [57] and Organizr [58].
Frassle Frassle has a slightly different focus to many of the other tools reviewed here: it is an integrative blog environment, allowing users to publish both links and original text in their own blog, and offering a number of features including an RSS aggregator. Links can be saved in Frassle as blog entries, and tagged freely. The tags applied are known as categories. Similarly to the other tools reviewed here, Frassle provides a social bookmarking environment: it allows users to see related content, based on what they have posted. The novelty of Frassle is the method by which 'related content' is defined. Crucially, Frassle does not assume that tags are necessarily related: two users' tags are determined to be related if they have been used to describe common links. The strength of the correlation between two tags therefore depends solely on the content they have been used to describe, not on the tags themselves. This reduces the problems of tag collision or divergence, which have been a primary criticism of tag vocabularies.
Furl An interesting problem with hosting local copies of bookmarked pages is the potential for copyright infringement, if, for example, pages that require subscription access to view are being saved in their entirety on a third-party service. Furl has bypassed this problem by limiting access to the hosted copy to the original user who bookmarked it, and hence presumably has legitimate access to the content. Other users are simply directed to the original URL. Since its launch, Furl has been acquired by Looksmart, a company with a number of interests including advertising networks and search facilities. The original developer Mike Giles remains on the Furl project.
Simpy Simpy has also released a REST-based API to facilitate integrating Simpy with other applications and services, and there is a discussion list for developers. Spurl.net Spurl.net, similarly to Furl, allows hosting of local copies of pages that have been bookmarked, the full text of which can then be searched. Spurl.net allows users to define their bookmarks as public (the default) or private, the latter being the most commonly selected setting. Spurl.net supports both multi-level categories, as well as user-assigned tags, and runs a special search engine Zniff that uses human information for ranking and indexing.
unalog unalog has a few hundred active users, many of whom are acquaintances of the author, and the social side of the software is emphasized. Unlike Furl, the primary aim of many users is to make their bookmarks available to others. One interesting aspect of unalog is the ability to slice and dice further queries using either time or 'width' arguments. Also of interest is unalog's support for private users, private entries, and public or private groups. Notesn1. It may be worth remembering that the Web is, after all, still a teenager and subject to all the angst, vagaries, and contrariness of growing pains. n2. Of course, links predate the Web and are as old as consciousness itself. In literary terms any gloss, footnote, or endnote in a book or other kind of publication is a 'link'. What is utterly captivating about the Web, however, is that this is a distributed hypermedia application and these links are therefore 'actionable' – one can simply 'click' on a link and be transported instantaneously to the relevant endpoint without having to turn pages or consult another publication. n3. In the film Gone With The Wind we are presented with the phrase "Do not squander time. That is the stuff life is made of." which is engraved on a sundial. And now compare this, from David Weinberger's book Small Pieces Loosely Joined [60], "The Web, a world of pure connection, free of the arbitrary constraints of matter, distance and time, is showing us who we are – and is undoing some of our deepest misunderstandings about what it means to be human in the real world." n4. Mosaic [61] – the 'killer app' that first accelerated the Web to real attention in public mindshare (because of its support for, among other features, graphics in particular) – was first released in beta form in September 1993. Bookmarks – or Hotlists as Mosaic referred to them – were another novelty, like the History feature, the former a user-compiled directory of jumping-off points, the latter a record or trail of recent pages visited. n5. Gopher [62] – an Internet information service that vied for prominence in the early day of the World Wide Web and which allowed for content nodes to be organized in a hierarchical structure – was developed at the University of Minnesota and named after the school's mascot. There are still a few Gopher servers roaming out in the wild as Liz Lawley has pointed out on the del.icio.us mailing list – see e.g. <gopher://seanm.ca/>. (You will probably need to use the Firefox browser.) n6. NCSA is the National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign. n7. The commercial operation was called Netscape Communications, Inc. n8. Brendan Eich, who developed JavaScript in 1995 at Netscape, also invented the 'javascript:' URL and intended that 'javascript:' URLs could be used as any other kind of URL, including being bookmark-able. (Unfortunately, besides being an unregistered URI scheme, this self-declared URI scheme does not adhere to the generic URI syntax [63]. Instead it just mimics the URI prefix notation – a simple token plus colon that has proved an irresistible lure for so many.) n9. The history of social bookmarking can also be seen to have another dimension as a move away from regular bookmarks to public (and permalinked), date-organized bookmarks expressed as blogs which then generate social value through aggregators and the like (e.g., Technorati [28], blogdex [64], Daypop [65], popdex [66]) before being refigured and recontextualized as centralized services. And from the blogging world new features are arising such as Technorati tags along with bookmarking tool APIs which enable post-to-blog functionality which seek to recontextualise blogging within this new social framework. n10. The term 'folksonomy' was coined by Thomas Vander Wal, according to Gene Smith [67], and is a blending of the terms 'folk' and 'taxonomy'. While suitably folksy, and enjoying a certain cachet at the present time, it leans too much on the notion of taxonomy, which is not obviously present in social (or distributed) classification systems although may yet be derivable from them. n11. The term 'ethnoclassification' seems to have been coined by Susan Leigh Star, according to Peter Merholz [68]. n12. Only the merest taste of some of the writings on tagging can be presented here. Besides the blog entry by Shelley Powers referenced earlier in the paper [1], a follow-on entry [69] makes for a stimulating read. David Weinberger's 'Tags vs Leaves' blog entry [70] is a great rehearsal for his introduction to the February issue of Release 1.0, entitled 'Taxonomies and Tags: From Trees to Piles of Leaves' [71]. The essay by Jakob Lodwick 'Tagwebs, Flickr, and the Human Brain' [72] is also rewarding. Lastly, the group blog on social software Many 2 Many [73] is a definite 'must read' for anyone interested in following the latest developments in social networking applications. n13. Regional bookmarking tools include BlogMarks.net [37] for a predominantly French subscriber base, and LiVEMARK [42] for a predominantly Japanese subscriber base. n14. Remarkably similar diagrams have also been devised by Gene Smith in his presentation 'Sorting Out Social Classification' to the Information Architecture Summit [74] (see slide 15) and Pito Salas [75] in a blog entry entitled '[ETECH] Taxonomy of Folksonomies'. Also of particular interest, and on a strongly related theme, is Thomas Vander Wal's writings explaining the difference between broad and narrow folksonomies, see e.g., [76].
n15. We note that traditional classification schemes incline to the universal, whereas user classification schemes incline to the contextual, i.e., they tend to be user-centric, time-centric, or even action-centric (cf. the tags ' n16. The Robot Co-op (the collective behind 43 Things [77]) announced [78] on February 7, 2005, that Amazon.com had invested in the company, which is an early indicator of a big Internet trader becoming interested in social software. n17. We have had some internal discussions about the relative merits of using the Digital Object Identifier (DOI) as a tag. There are, at this point in time, some practical problems in dealing with the DOI syntax (because some of the characters allowed in DOIs, such as the forward slash, have special meanings in Connotea and other social bookmarking systems). Nonetheless this could be an interesting avenue to explore and we would invite reader feedback as to the relative merits of using such identifiers as tags. n18. An intriguing example of a super bookmarklet is Alan Levine's 'Multipost Bookmarklet Tool' [79], which at the time of writing can be configured to post to a dozen social bookmarking tools with one click. Many of the tools on his list are reviewed here in the annex. n19. Schachter announced [80] on March 29, 2005, that he is to take on outside funding to work on the del.icio.us project full time. n20. On March 20, 2005, Flickr confirmed [81] that they were to be acquired by Yahoo! [9]. This investment in a folksonomy-driven site is particularly interesting since Yahoo! was the first to attempt a top-down classification of the Web. References1. Powers, S., Cheap Eats at the Semantic Web Café, Burningbird, January 27, 2005. <http://weblog.burningbird.net/archives/2005/01/27/cheap-eats-at-the-semantic-web-cafe/>. 2. Biddulph, M., Introducing del.icio.us, XML.com, November 10, 2004, <http://www.xml.com/pub/a/2004/11/10/delicious.html>. 3. del.icio.us. <http://del.icio.us/>. 4. Lund, B., Hammond, T., Flack, M., and Hannay, T., Social Bookmarking Tools (II): A Case Study – Connotea, D-Lib Magazine 11(4), April 2005. <http://www.dlib.org/dlib/april05/lund/04lund.html>. 5. Nature Publishing Group. <http://npg.nature.com/>. 6. Connotea. <http://www.connotea.org/>. 7. Open Directory Project. <http://www.dmoz.org/>. 8. Zeal. <http://www.zeal.com/>. 9. Yahoo! <http://dir.yahoo.com/>. 10. Udell, J., Walking tour of Keene: followup, Jon Udell's Weblog, Monday, February 28, 2005, <http://weblog.infoworld.com/udell/2005/02/28.html#a1186>. 11. Rands, A Del.icio.us Interview, Rands In Repose, December 3, 2004. <http://www.randsinrepose.com/archives/2004/12/03/a_delicious_interview.html>. 12. O'Reilly, T., The Architecture of Participation. O'Reilly Developer Weblogs, April 6, 2003. <http://www.oreillynet.com/pub/wlg/3017>. 13. eBay. <http://www.ebay.com/>. 14. Wikipedia. <http://en.wikipedia.org/>. 15. Amazon.com. <http://www.amazon.com/>. 16. Slashdot. <http://slashdot.org/>. 17. craigslist. <http://www.craigslist.org/>. 18. arXiv. <http://arxiv.org/>. 19. MERLOT – Multimedia Educational Resource for Learning and Online Teaching. <http://www.merlot.org/Home.po>. 20. Ernst, J., What are the differences between a vocabulary, a taxonomy, a thesaurus, an ontology, and a meta-model? metamodel.com, January 15, 2003. <http://www.metamodel.com/article.php?story=20030115211223271>. 21. Mathes, A., Folksonomies – Cooperative Classification and Communication Through Shared Metadata. Computer Mediated Communication – LIS590CMC, Graduate School of Library and Information Science, University of Illinois Urbana-Champaign, December 2004. <http://www.adammathes.com/academic/computer-mediated-communication/folksonomies.html>. 22. Shirky, C., Tags != folksonomies && Tags != Flat name spaces, Many 2 Many, January 24, 2005. <http://www.corante.com/many/archives/2005/01/24/tags_folksonomies_tags_flat_name_spaces.php>. 23. Udell, J., del.icio.us: the screencast, Jon Udell's Weblog, March 14, 2005. <http://weblog.infoworld.com/udell/2005/03/14.html>. 24. Pind, L., Folksonomies: How we can improve the tags, Pind's dot-com, January 23, 2005. <http://www.pinds.com/blog/one-entry?entry_id=21678>. 25. Flickr. <http://www.flickr.com/>. 26. Shirky, C., Ontology is Overrated: Links, Tags, and Post-hoc Metadata, presented at the O'Reilly Emerging Technology Conference, March 16, 2005. <http://conferences.oreillynet.com/cs/et2005/view/e_sess/6117>. 27. Brin, S., and Page, L., The Anatomy of a Large-Scale Hypertextual Web Search Engine, Computer Science Department, Stanford University, Stanford, CA 94305. <http://www-db.stanford.edu/~backrub/google.html>. 28. Technorati. <http://www.technorati.com/>. 29. Van de Sompel, H., Nelson, M.L., Lagoze, C., and Warner, S., Resource Harvesting within the OAI-PMH Framework, D-Lib Magazine, December 2004, 10(12). <http://www.dlib.org/dlib/december04/vandesompel/12vandesompel.html>. 30. Coates, T., Biddulph, M., Hammond, P., and Webb, M., Reinventing Radio: Enriching Broadcast with Social Software. <http://conferences.oreillynet.com/cs/et2005/view/e_sess/5981>. 31. Lawley, L., it's the social network, stupid!, Many 2 Many, January 20, 2005. <http://www.corante.com/many/archives/2005/01/20/its_the_social_network_stupid.php>. 32. del.icio.us 'about' page. <http://del.icio.us/doc/about/>. 33. Chudnov, D., and Frumkin, J., Service Autodiscovery for Rapid Information Movement. <http://curtis.med.yale.edu/dchud/writings/sa4rim.html>. 34. Hammond, T., Hannay, T., and Lund, B., The Role of RSS in Science Publishing: Syndication and Annotation on the Web, D-Lib Magazine, 10(12), December 2004. <http://www.dlib.org/dlib/december04/hammond/12hammond.html>. 35. Free Bookmark Managers. <http://www.lights.com/pickalink/bookmarks/>. 36. Bag of URLs. <http://www.mcli.dist.maricopa.edu/eye/bag/drop.html>. 37. BlogMarks.net. <http://www.blogmarks.net/>. 38. Dude, Check This Out! <http://www.dudecheckthisout.com/>. 39. Feed Me Links. <http://feedmelinks.com/portal/>. 40. Jots. <http://jots.com/>. 41. Linkfilter. <http://www.linkfilter.net/>. 42. LiVEMARK. <http://livemark.jp/>. 43. openBM. <http://www.openbm.de/>. 44. StumbleUpon. <http://www.stumbleupon.com/>. 45. Wists. <http://www.wists.com/>. 46. de.lirio.us. <http://de.lirio.us/>. 47. Creative Commons. <http://creativecommons.org/licenses/by-nc-sa/2.0/>. 48. Furl. <http://www.furl.net/>. 49. CiteULike. <http://www.citeulike.org/>. 50. unalog. <http://unalog.com/>. 51. Frassle. <http://frassle.rura.org/>. 52. Simpy. <http://www.simpy.com/simpy/Splash.do>. 53. Spurl.net. <http://www.spurl.net/>. 54. Rox, T., Social bookmarks' charts version 2.0, March 22, 2005 <http://www.irox.de/stat-pdf/socialbookmarks.pdf>.
55. Foxylicious. <https://addons.update.mozilla.org/extensions/moreinfo.php?application=firefox 56. Cocoalicious. <http://www.scifihifi.com/cocoalicious/>. 57. Mappr. <http://www.mappr.com/>. 58. Organizr. <http://www.flickr.com/tools/organizr.gne>. 59. The Wayback Machine. <http://www.archive.org/>. 60. Weinberger, D., Small Pieces Loosely Joined: A Unified Theory of the Web, Perseus Books Group, May, 2003. 61. NCSA Mosaic home page, National Center for Supercomputing, University of Illinois in Urbana-Champaign. <http://archive.ncsa.uiuc.edu/SDG/Software/Mosaic/NCSAMosaicHome.html>. 62. Anklesaria, F., McCahill, M., Lindner, P., Johnson, D., Torrey, D., and Alberti, B., The Internet Gopher Protocol (a distributed document search and retrieval protocol), RFC 1436, March 1993. <http://www.ietf.org/rfc/rfc1436.txt>. 63. Berners-Lee, T., Fielding, F., and Masinter, L., Uniform Resource Identifier (URI): Generic Syntax, RFC 3986, January 2005. <http://www.ietf.org/rfc/rfc3986.txt>. 64. blogdex. <http://blogdex.net/>. 65. Daypop. <http://www.daypop.com/>. 66. popdex. <http://www.popdex.com/>. 67. Smith, G., Folksonomy: social classification, atomiq, August 3, 2004. <http://atomiq.org/archives/2004/08/folksonomy_social_classification.html>. 68. Merholz, P., Metadata for the Masses, adaptive path, October 19, 2004. <http://www.adaptivepath.com/publications/essays/archives/000361.php>. 69. Powers, S., Accidental Smarts à la mode (a response to just about any body who is interested), Burningbird, February 10, 2005. <http://weblog.burningbird.net/archives/2005/02/10/accidentalsmarts/>. 70. Weinberger, D., Trees vs. Leaves, Journal of the Hyperlinked Organization, January 28, 2005. <http://www.hyperorg.com/backissues/joho-jan28-05.html#leaves>. 71. Weinberger, D. Taxonomies and Tags: From Trees to Piles of Leaves. <http://hyperorg.com/blogger/misc/taxonomies_and_tags.html>. 72. Lodwick, J., Tagwebs, Flickr, and the Human Brain, February 1, 2005. <http://blumpy.org/tagwebs/>. 73. Many 2 Many. <http://www.corante.com/many/>. 74. Smith, G., Sorting Out Social Classification, presented at the Information Architecture Summit, March 4, 2005. <http://atomiq.org/etc/folksonomies_smith_ia_summit_2005.pdf>. 75. Salas, P., [ETECH] Taxonomy of Folksonomies, Pito's Blog, March 22, 2005. <http://www.salas.com/weblogs/archives/000608.html>. 76. Vander Wal, T., Explaining and Showing Broad and Narrow Folksonomies, vanderwal.net, February 21, 2005. <http://www.vanderwal.net/random/entrysel.php?blog=1635>. 77. 43 Things. <http://www.43things.com/>. 78. Petersen, J., Word on Investment, The Robot Co-op, February 7, 2005. <http://robotcoop.com/weblog/51/word-on-investment>. 79. Levine, A., Multipost Bookmarklet Tool. <http://jade.mcli.dist.maricopa.edu/alan/marklet_maker.php>. 80. Schachter, J., big news, delicious-discuss, March 29, 2005. <http://lists.del.icio.us/pipermail/discuss/2005-March/002554.html>. 81. Fake, C., Yahoo actually does acquire Flickr, Flickr Blog, March 20, 2005. <http://blog.flickr.com/flickrblog/2005/03/yahoo_actually_.html>. (A misspelling of the name Pito Salas in note 14 was corrected on May 23, 2005.) Copyright © 2005 Tony Hammond, Timo Hannay, Ben Lund and Joanna Scott |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/april2005-hammond
|



{kind=link}
{kind=link}
{kind=link}