| ||
D-Lib Magazine | |
| Amy Friedlander, Ph.D. 1 |
![]()
|
In December 2000, Congress passed legislation establishing the National Digital Information Infrastructure and Preservation Program (NDIIPP) in the Library of Congress (LC) (PL 106-554). The legislation calls for LC to lead a national planning effort for the long-term preservation of digital content and to work collaboratively with representatives of other federal, research, library, and business organizations. The legislation allocates $100 million for the program, to be released in stages: $5 million to be immediately authorized, $20 million to be made available after Congressional approval of an NDIIPP plan, and the final $75 million to be contingent upon raising $75 million in matching funds. It is a challenging mandate, requiring LC to mediate among many technical, organizational and management concerns:
The challenge of digitizing rare and unique materials is immense and important. According to Martha Anderson, one of the program coordinators, as a result of the National Digital Library Program LC accumulated substantial experience in the operational details of building digital collections that represent both robust systems for today and archives for tomorrow. But conversion of works largely in the public domain pales in comparison with the challenge of dealing with "born digital" — those items that have been created in digital form, which can range from Web sites to databases of scientific data, to streaming content from one of the record labels. These are rife with hardware and software issues as well as intellectual property concerns and there may be no analog version in reserve should the archiving system fail [2]. Some people believe that the only collection policy for digital preservation is "everything", and they bewail the thought that Web pages are routinely removed or somehow lost. Others, librarians and archivists among them, who are familiar with collection development and management, acknowledge that selection is necessary. Even if it is theoretically possible to save "everything," it may be very expensive to make that material valuable to potential users. Collection development is but one example of the possible choices and trade-offs to be considered. Planning is about evaluating alternatives and finding the middle ground among extremes. Getting Started: Developing the Plan.In early 2001, LC began its planning process under the leadership of Laura E. Campbell, the Associate Librarian for Strategic Initiatives. Its overriding goals are to encourage shared responsibility and to seek national solutions for:
A broad-based Advisory Board, consisting of representatives from other federal agencies, research libraries, private foundations, and industry, was organized; the membership and a description of its activities will eventually be posted at the program's Web site [3]. Based on a series of formal and informal discussions, LC made an initial set of scoping decisions:
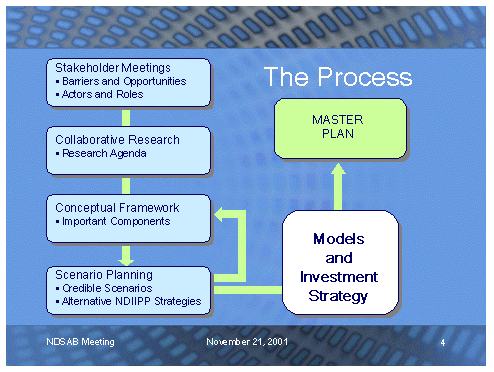
Figure 1 The image in Figure 1 is courtesy of the Library of Congress. Used with permission. An important milestone in the planning process will be submission of a formal plan to Congress later this year, which will include recommendations for future investments. As of this writing in February 2002, the stakeholder meetings have been held; work has begun on an approach to developing a collaborative research agenda; a conceptual framework has been drafted, and three scenario workshops have been scheduled. The remainder of this paper discusses progress so far, issues that have surfaced and areas of consensus. Stakeholder Meetings: Listening to Many ViewsThe Conference Report accompanying the legislation (H. Report 106-1033) [4] noted that in developing the plan, LC should be "mindful" of a recent National Research Council Computer Science and Telecommunications Board study that found that LC was becoming isolated from its clients and peers in the development of digital content [5]. Moreover, the Conference Report also requires LC to partner with the information and technology industries. Finally, much of the digital content itself — especially the visual, sound, and broadcast media in which so much late twentieth century history is embodied — is subject to copyright and royalty agreements and is generally not sold but is licensed for use for a period of time and subject to specified conditions. Therefore, LC has sought to involve different groups, to tap their experience and to understand their perspectives, recognizing that long-term preservation of digital content will require a range of partnerships and collaborations. Many of these interests are reflected in the membership of the advisory board. Reaching out to stakeholder communities also involved organizing three sessions in Washington, D.C., in November 2001. Given the events post 9-11, constraints on long distance travel and the anthrax scares, which temporarily closed LC along with other federal buildings, about 70 people from print publishing, entertainment, broadcasting, libraries, non-profit organizations, and foundations attended the one- and one-half-day program. In support of these meetings and as part of assessing what is already known, six environmental scans on the formats selected for the first phase of study (Web sites, electronic journals, electronic books, digitally recorded sound, digital television, and digital moving images) were commissioned from nationally recognized experts [6]. Also supporting the sessions was a series of confidential interviews. Names of people to interview were solicited from members of the advisory board, from preservation experts and by asking the interviewees themselves the simple question, "To whom should we be talking?" A summary piece on the scans and the interviews was prepared; it will be made available on the program's Web site, where a summary of the sessions and the scans themselves will also be posted. Some of the conclusions, summarized below, will not be surprising to the archival community, but the dominant finding, supported by both the interviews and the sessions — that there is widespread support for a national initiative in long-term preservation of digital content across a very broad range of stakeholder groups outside the traditional scholarly community — was unexpected. This is not to say there are not concerns and barriers, but rather that there are areas of common interest. Managing digital resources internally and externally is important to the content industries (e.g., publishing, entertainment). Their representatives are acutely aware that the threat is imminent (five to ten years for some storage media) and that organizational and technical challenges are substantial. Commented one of the entertainment industry representatives, "We have tremendous resources from people who are involved on the technology side and we would like to be a resource for the Library of Congress as this goes forward." What else was learned?
Collaborative Research Program: How many problems? How many solutions?The work in the summer and fall of 2001 surfaced legitimate, divergent concerns and interests across formats, industries, and groups as well as areas of common interest on which compromises might be explored. Margaret Hedstrom of the University of Michigan, a scholar of digital archives who is guiding the formulation of the research program associated with NDIIPP, has independently reached a similar conclusion. She believes that the first step is "to disaggregate the problem of digital archiving and to recognize that digital preservation spans issues in computer and information science research, development of technology and tools, evolving standards and practices, policy and economic models, and organizational change." She continues, "At the same time, we have to be cognizant of how the various approaches or solutions will work together." As a way of coordinating the research, LC has begun to develop a partnership with the National Science Foundation's program in digital government. According to the program manager, Lawrence Brandt, the program seeks to partner with other federal agencies to develop research in a domain of joint interest. A workshop to develop a research agenda is typically organized, which is then followed by a call for proposals. The key, from his point of view, is to deepen relationships among agencies that might not otherwise recognize a common interest in a body of research. Dr. Brandt has been pleased by the level of enthusiasm he has seen among leaders in key agencies, such as the National Agricultural Library, the National Library of Medicine, the National Archives, NIST, and so on. "So far," he says dryly, "all the dates have been nice dates." It is important, though, he cautions, to hold expectations in check. Systems that can result from research are not likely to be the robust systems an agency may eventually require. Thus, there will be a need beyond the research phase for work that converts a promising experiment into a reliable, operating system. A preliminary meeting with 15 concerned federal agencies was held in November 2001, and a formal, invitational workshop will be held on April 12-13, 2002. Its goal, according to Dr. Hedstrom, "is to have a combination of academic researchers and people from industry who are actually building things like storage management systems to develop a set of research challenges that will excite the community of people who actually do research in this area." The workshop will be followed by a Call for Proposals, which is anticipated for the summer of 2002. The size and duration of the projects funded will depend in part on the levels of commitment by the various agency partners as well as by the research agenda that comes out of the April meeting. This is not the first time that an attempt has been made to initiate a research agenda in digital archiving, and Stephen Griffin, the program manager for the federal interagency National Science Foundation Digital Libraries Initiative (NSF/DLI), believes that archiving is a topic that is "least worked on and most perplexing." The initial list of topics is not entirely surprising to those who have labored in this area:
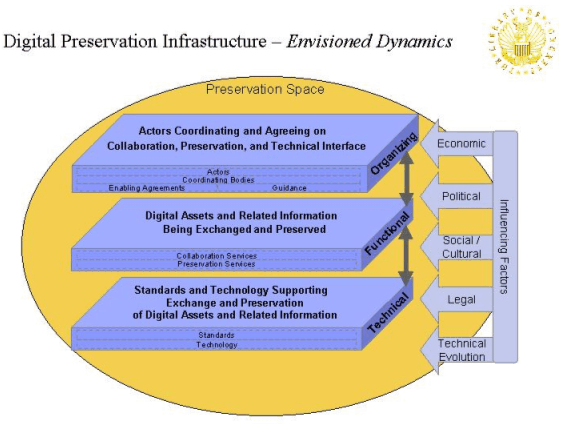
Unlike earlier efforts, there is a deeper base of experience with hands-on attempts to archive digital materials as well as widespread interest in archiving within the computer/information science research community. One reason, says SDSC's Reagan Moore, is that progress that has been made in a number of technologies "that makes it feasible to think of persistent infrastructure." Dr. Moore and his colleagues have discussed their model for persistent archiving in some detail in this magazine [8]. The basic point, he says, is that approaching persistent archiving from the perspective of infrastructure allows system designers to decouple the data storage from the various components that allow users to manage the data. Potentially, any component can be "swapped out" without affecting the rest of the system. Theoretically, many of the technical problems in archiving can be separated into their components, and as innovation occurs, those components can be updated so that the archive remains persistent in the context of rapid change. Similarly, as the storage media obsolesce, the data can be migrated without affecting the overall integrity of the system. The technological issues can also be situated in frameworks that arise from business and social concerns while recognizing that such systems, like libraries and archives themselves, function in the public interest. A set of technical challenges arises, says Donald Waters of the Andrew W. Mellon Foundation, when content is moved from "the cocoon of the publisher's system into an independently managed archive in a normalized form and in a way that is authentic to the publisher and the publisher's intention." Some efforts, such as those underway at the National Library of Medicine, are extremely labor intensive and, he says, an archiving system must be economical. It must also be trustworthy, which can have several meanings and expressions. Audit techniques can ensure that the content stored by the archive tracks the content stored by the publisher — or any owner. From a societal perspective, trust can be fostered when the archive is seen to operate in the public good. This means finding a balance between content that is subject to copyright and other forms of proprietorship and reasonable public access that does not erode the economic value to its owners. Finally, the archive must eventually be self-sustaining, which raises another set of challenges to the public good: Networked systems can tend toward centralization among a few players, which can be efficient yet risk the twin pitfalls of monopoly and exorbitant pricing on the one hand, and free riding by those beneficiaries who take more than they put in, on the other. Another unexplored issue, Dr. Waters points out, concerns the nature of the collection, not only what it contains in a conventional sense but whose definitions apply, particularly when one set of definitions arises among scholars and another, algorithmic definition arises among computer scientists where notions of "completeness" and "closure" may have a meaning that is formally correct but unsatisfying in practice. For example, if a Web crawler copies public files from a node through its hierarchy but stops when it encounters a proprietary sub-system, how complete is the "copy"? And to whom? There are questions, then, that arise among users, about whom less is simply known. "What aspects of things are most important to capture?" Dr. Lynch asks. Professor Kevin Kiernan of the University of Kentucky, known for his electronic edition of Beowulf and the National Science Foundation (NSF) DLI project with computer scientists to develop "New Techniques for Restoring, Searching, and Editing Humanities Collections," [9] offers one answer. "Basic collaborative tools," he says, "must be developed to let humanities and fine arts scholars work innovatively with differently generated digital images of manuscripts or works of art, to combine and manipulate ultraviolet or infrared or three-dimensional imagery, for instance, and to embed expert commentary on regions of interest." He believes that digital libraries, like traditional libraries, should not simply be repositories of primary sources, but also vast and ever-growing storehouses of analytical commentary and editions of those sources. In addition to collecting, preserving, and retrieving digital representations of artifacts, then, digital libraries with the right collaborative tools can and should become ever-growing collections of deeply encoded, searchable analyses, attached to the images by means of simple interfaces by successive generations of scholars for students and the general public. Conceptual Framework: A Way to Structure the LandscapeThe tensions implied by coordinating heterogeneous research projects also surface in efforts to provide an umbrella within which we can begin to see how the many entities and functions concerned with long-term preservation of digital content might interact. In parallel with identifying what interests outside of LC might be willing to cooperate in a national strategy, LC contracted with PricewaterhouseCoopers (PWC) to produce a draft conceptual framework. PWC also developed a preliminary list of critical technical issues [10]. The intent of the framework (Figure 2) is not to outline an architecture in a formal sense, but rather to come up with a way in which the range of organizations, functions and services might be organized. The work has been coordinated by Elizabeth Dulabahn, Senior Manager for Integration Management, Office of Strategic Initiatives. Figure 2 The image in Figure 2 is courtesy of the Library of Congress. Used with permission. PWC's initial framework shown in Figure 2 envisions a digital preservation environment that is influenced by a series of factors: economic, political, social/cultural, legal, and technological. Within the preservation space, there are three levels or dimensions: organizing, functional, and technical. The organizing dimension comprises actors (e.g., authors, publishers, libraries and museums, hardware and software companies, etc.), coordinating bodies (ISO, IFLA, professional associations, and so on), enabling agreements and guidance. The functional view comprises preservation and collaboration services and encompasses activities such as storage or rights clearance services. Finally, the technical layer embraces standards and technologies. Within this dimension fall de facto and de jure standards, components (e.g., Web servers), equipment, software, and so on. The principal value of a technical framework is that it allows different groups to begin to achieve more precision in their discussions by forcing questions. For example, Dr. Dulabahn points out that the notion of "trust" reoccurs in many conversations and contexts [11]. Does "trust" mean that Party A trusts Party B to send a copy of a document that is an exact replica of what a content creator considers the work to be? Or does "trust" mean that Party A trusts Party B to send a copy of a work that Party B has the legal right to send according to terms and conditions worked out with Party C, who trusts B to observe them? Thus, in this simple example there are at least three meanings of trust. When Party A asks for and receives a document from Party B, all three layers of the infrastructure (Figure 2) are invoked.
There are many cross-cutting interests, so that decisions by international standards setting bodies (top layer) that may affect metadata or identifiers (bottom layer), for example, potentially affect how Party A finds out about the work in the first place through a search engine (middle layer). How companies, non-profit organizations, libraries, museums, archives, colleges, and universities will fit into this framework remains to be worked out. Indeed, additional parts of the framework may need to be defined or existing components modified, as pilot projects uncover different dimensions of the problem. "There's nothing sacrosanct about the framework," Dr. Dulabahn says. "We're prepared to make adjustments as we learn more." Scenario planning: Now and future choicesIn the past, LC has been criticized for "not thinking far enough ahead to enable it to act strategically and coherently" [12]. Later this year, LC will undertake a novel exercise in scenario planning through several workshops. It is premature to discuss the outcomes of these sessions, but in the context of the larger planning process, the scenario workshops allow participants — and by extension LC — to think the unthinkable. And if a scenario is likely, how does it compare with the conceptual framework? Are there interests, functions or roles that have not yet surfaced? Perhaps even more important than the outcomes is the process of reaching those outcomes. As Dr. Lynch observes, archiving is fraught with assumptions and "baggage." The scenario planning exercise can expose unexamined assumptions that might prove limiting in the long run, and, he says, "That is useful." A decade ago, it might have been hard to imagine a world in which more than three-fourths of the nation's K-12 instructional rooms have Internet connectivity [13] and in which the Library of Congress' collections, long thought of as shut away in a grand building on Capitol Hill, could become a "local" educational resource, courtesy of American Memory, the National Digital Library Program, and the World Wide Web. Many interests converge in long-term preservation of digital content. It is unlikely that they will be "sorted out" in any permanent sense when LC and its partners emerge from this planning process. We can all expect to have learned a lot and to have begun to build operational systems, however flawed they may prove to be. Archiving of digital information can be conceptualized in many ways; it can be set up, says Dr. Lynch, "as an absolutely impossible problem." At some point, Dr. Dulabahn says, "Give it your best shot and then cycle back to it." Notes1. This article has been developed with the assistance of many people inside and outside of the Library of Congress. I am indebted to Martha Anderson, Marjory Blumenthal, Lawrence Brandt, Samuel Brylawski, Laura Campbell, Robert Dizard, Elizabeth Dulabahn, Peter Gordon, Stephen Griffin, Marin Hagen, Margaret Hedstrom, Molly Ho Hughes Johnson, Kevin Kiernan, Guy Lamolinara, Clifford Lynch, Deanna Marcum, Reagan Moore, and Donald Waters. I am responsible for any remaining errors. The views and opinions expressed herein are those of the Author and do not necessarily reflect those of the Council on Library and Information Resources (CLIR), the Library of Congress (LC), or the Government. Images that appear as Figures 1 and 2 in this article are provided courtesy of the Library of Congress and are used with permission. 2. For example, information on early motion pictures exists because a paper version of the films was created for purposes of Copyright deposit. The Copyright law initially did not acknowledge motion pictures as copyrightable. To get around this, producers printed the films on paper (like contact sheets) and deposited them as sets of photographs (which could be given copyright protection). Beginning in the 1950s, LC re-photographed the "paper prints," thus converting them back to motion pictures. Some producers only printed excerpts from films (such as one frame per scene). These deposits could not be made back into movies, of course, but they do provide us with documentation of the film's content. I am indebted to Samuel Brylawski for this information. 3. As of this writing in mid-March 2002, the program's Web site is under construction; launch is expected later this spring. 4. U.S., House of Representatives, Report 106-1033: Making Omnibus Consolidated And Emergency Supplemental Appropriations For Fiscal Year 2001, Conference Report to accompany H.R. 457, December 15, 2000. <ftp://ftp.loc.gov/pub/thomas/cp106/hr1033.txt>. 5. See National Research Council Computer Science and Telecommunications Board, LC21: A Digital Strategy for the Library of Congress (Washington, D.C.: National Academy Press, 2000). 6. Samuel Brylawski, Preservation of Digitally Recorded Sound; Dale Flecker, Preserving Digital Periodicals; Peter Lyman, Archiving the World Wide Web; Mary Ide, Dave MacCarn, Thom Shephard, and Leah Weisse, Understanding the Preservation Challenge of Digital Television; Frank Romano, E-Books and the Challenge of Preservation; Howard D. Wactlar and Michael G. Christel, Digital Video Archives: Managing through Metadata. It is expected that the scans will be posted to the program's Web site. 7. Flecker, Preserving Digital Periodicals. 8. Reagan Moore, Chaitan Baru, Arcot Rajasekar, Bertram Ludaescher, Richard Marciano, Michael Wan, Wayne Schroeder, and Amarnath Gupta, Collection-Based Persistent Digital Archives - Part 1, D-Lib Magazine 6 (March 2000), <http://www.dlib.org/dlib/march00/moore/03moore-pt1.html>; Collection-Based Persistent Digital Archives - Part 2, D-Lib Magazine 6 (April 2000), <http://www.dlib.org/dlib/april00/moore/04moore-pt2.html>. 9. See Electronic Beowulf, <http://www.uky.edu/~kiernan/eBeowulf/guide.htm> and the Digital Atheneum Project, <http://www.digitalatheneum.org> 10. PWC has identified six categories of technical issues: selection; digital rights management (DRM); technical architecture; standards; access and security; and evolving technology. See Planning for the National Digital Information Infrastructure and Preservation Program, Conceptual Framework and Critical Technical Issues (January 2002) [draft report], p. 36. These are not inconsistent with the issues raised at the November sessions, although the way in which the issues are grouped is somewhat different. 11. "Trust" in the digital environment has been extensively discussed in preservation, information technology and information policy circles. See, for example, Authenticity in a Digital Environment (Washington, DC: Council on Library and Information Resources, 2000); Jeffrey R. Cooper and Amy Friedlander, Trust, a Baseline for Future Governance, pp. 428-38, in Select Committee on the European Union, E-Commerce: Policy Development and Coordination in the EU (London: The Stationery Office, 25 July 2000). On the notion of trusted systems, see Mark Stefik, The Internet Edge: Social, Legal, and Technological Challenges for a Networked World (Cambridge, MA: MIT Press, 1999). 12. National Research Council Computer Science and Telecommunications Board, LC21: A Digital Strategy for the Library of Congress, 2. 13. Anne Cattagni and Elizabeth Farris. Statistics in Brief: Internet Access in U.S. Public Schools and Classrooms, 1994-2000. May 2001. National Center for Education Statistics. <http://nces.ed.gov/pubs2001/2001071.pdf>, p. 3. Copyright 2002 Amy Friedlander, Ph.D. | |
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2002-friedlander
|