|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Robert Tansley |
![]()
1 AbstractThis article presents the architecture developed for the China Digital Museum Project, a collaborative project involving the Chinese Ministry of Education, Hewlett-Packard Company and several Chinese universities, with Beihang University as the main technical partner. Repositories (such as DSpace) in a federation can replicate metadata and content from others by harvesting METS Dissemination Information Packages via OAI-PMH. The CNRI Handle System® is used to uniquely identify objects in the federation and to keep track of their multiple locations. A central registry of repositories in the federation allows participating repositories to discover new repositories and changes to existing ones. The central registry also features an "available mirrors" user interface, which enables users to select which physical copy of an object to access. Various use cases for the architecture are described, including the China Digital Museum Project use case. This article also describes a federation of Institutional Repositories sharing content and metadata for preservation purposes. 2 IntroductionMany universities in China maintain one or more museums. In order to improve access for research communities, students, teachers and the general public to the artefacts in the university museums, these universities are undertaking the digitisation of those artefacts. The principal aim of the China Digital Museum Project is to enable these universities to provide infrastructure based on DSpace1 to store, manage, preserve and disseminate the digitised versions of the artefacts. In the final phase of the project, there will be approximately 100 university museums with digital artefacts stored in federated DSpace installations. The target solution is a large-scale, federated deployment of DSpace to serve the Chinese universities' digital museums and end users:
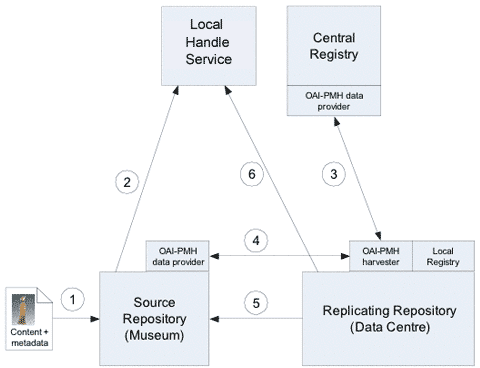
This article focuses on the technical means by which federating these DSpace instances are achieved. The enhancements made to the DSpace system have been implemented in such a way as to be generally applicable to building large, distributed, federated digital library systems. Further, since all of the interactions in the system are standards-based, there is no reason why every repository in the system has to be a DSpace instance; repositories using other tools can also participate. The project resulted in development of an architecture that can be deployed in a number of ways to address a number of use cases in addition to the China Digital Museum Project – for example, federations of Institutional Repositories for preservation purposes. The approaches described here are similar to those used in the aDORe repository architecture developed at the Los Alamos National Laboratory [1]. This article builds on that work by introducing elements to manage a more complex information lifecycle, and to address use cases where many different, distributed organisations are involved in an overall federation. It also addresses data models that have the notion of containership (for example, Communities and Collections in the DSpace data model). There is other strongly related work on CORDRA [2] and FeDCOR [3], both of which take a similar registry-based approach to define federations and track objects. The focus of the architecture presented in this article is primarily for content replication for preservation and efficient access purposes, whereas CORDRA and FeDCOR are focussed mainly on federations for search and discovery; however, there is much scope for aligning these efforts. Finally, a note on terminology used in this article: numerous potential terms exist to describe the various kinds of digital content in the system. Where the term Object is used capitalised, it refers to a complex digital object as in the Kahn/Wilensky framework [4], consisting of some metadata and one or more bitstreams. Bitstream is used to describe an individual file or datastream, and to be consistent with the DSpace data model (although the DSpace data model is not intrinsic to this work). 3 Solution ArchitectureThe overall architecture described in this article (sometimes referred to here as the solution architecture) consists of a number of repository nodes, each of which may provide an OAI-PMH data provider interface to enable authorised repositories to harvest METS2 Dissemination Information Packages (DIPS). These METS DIPs are essentially manifests, containing the complete descriptive and technical metadata for an Object, and including constituent bitstreams by reference. This enables a harvesting repository to completely replicate the underlying digital Object. A set of repositories participating in this architecture is referred to as a "federation". A central registry of repositories maintains various data about the repositories in the federation. Additionally, in a similar manner to the "Repository Index" in the aDORe architecture, the central registry provides an OAI-PMH data provider interface, which enables automated discovery over time of new repositories as they are added to the federation. When a digital Object is introduced into a repository in the system, it is given a CNRI3 Handle4, with the Handle Record stored in the federation's Local Handle Service. When another repository in the federation replicates the Object, information about the new copy of the Object is added to the Handle Record. This enables the locations of copies of an Object to be tracked, and it also provides users and services with the added resilience of there being multiple locations from which to access the Object.
Figure 1 depicts the overall solution architecture, and the data flows involved in a simple replication operation. More detail about the various components, their interactions and Object lifecycles are given in later sections of this article.
3.1 Simplifying Assumptions and PropertiesAs will be seen later, this basic architecture can be deployed in a number of topologies to address a variety of use cases. In some of these topologies, repositories may be both Source Repositories and Replicating Repositories. Thus, some Objects in a Source Repository may originate in another Source Repository. Such scenarios introduce various potential problems, such as unnecessarily harvesting the same Object from several Source Repositories, or two different versions of an Object being present in the federation. To address this, the following property is required: Each Object with a unique identifier in the system has a single "owning" repository. Only this repository may change the Object; other repositories may only mirror it. Any modifications or additions made by non-owning Repositories are considered annotations and are not further replicated, unless of course they are made separate Objects in their own right, referring to the original via its identifier. This maps well to what is usually the case in the real world, in that a single organisation has primary responsibility for the stewardship of an Object, and others agree to assist in some manner due to some informal or service-level agreement. Further, in this architecture, we require the property that "ownership" of Objects is managed at the level of Handle prefix (or sub-prefix). For example, Source Repository X might "own" all Objects with prefixes 1702.5 and 1702.12. This greatly simplifies certain processes described later on, and should cover most use cases. An alternative would be to individually track the ownership of each Object in the Federation; however, it would become increasingly problematic to inform individual Replicating Repositories of these changes as the total number of Objects grows. In most topologies, to avoid the unnecessary replication problem, it is adequate to assert that a Source Repository will only return METS DIPs for Objects it owns when being harvested. This assumption avoids various problems described later. Alternatively, OAI-PMH sets may be used; however, this would require some modification of the processes described below. One further assumption in this work is that a Replicating Repository is simply attempting to replicate all Objects in a Source Repository. Various methods could be employed to implement more granular selection of Objects to be replicated; this is mentioned in later sections, but is largely outside the scope of this article. 3.2 The Replication ProcessIn order to robustly replicate new and modified Objects from a Source Repository, a Replicating Repository employs the following methodology for harvesting Objects. In general, after an initial "complete" harvest, a Replicating Repository will periodically harvest a Source Repository; say once a day or once a week. However, this process must be robust to deal with a variety of problems, such as:
In cases like these, it is important that invalid or incomplete Objects are not replicated and that means will be available to address the problem. As noted by van de Sompel et al. [5], this "resource harvesting" works well if the OAI identifier of each OAI-PMH record is the identifier of the resource itself (a Handle in this case) and the date stamp is the date the resource was last modified. For each Source Repository in its local registry, it will also store:
The basic algorithm employed by the Replicating Repository is as follows.
Initial tests demonstrate that this algorithm is robust enough to deal with network problems occurring at any time before or during a harvest, not missing any Object creations or modifications. The main problem that may occur is that, if the number of failed records gets high and problems occur repeatedly with the same records, step 8 starts to take a long time; the cause is likely to be systemic, and thus step 8 can be suspended until the underlying problem is resolved. If a harvest fails late in the process and the "last successful harvest date" of a Source Repository is not updated, then later the METS DIPs of already replicated Objects will be re-harvested. However, since the algorithm can determine whether underlying bitstreams are new or changed, the overhead for this is relatively small, and it is a reasonable trade-off for the robustness. During the China Digital Museum Project prototyping and testing, it emerged that managing validation failures of various kinds over time represents the largest administrative burden for running this distributed system. When problems occur, the Source Repository needs to be informed, and the Repository needs to be able to fix the problem if it does indeed lie at their end. Determining whether the problem is with the underlying data, the repository software stack or the network itself is very difficult, and in some cases tracking a problem down is difficult. However, realising such problems exist is essential to running any preservation-related system, and further, the algorithm above will automatically and correctly replicate Objects once any underlying problem, regardless of cause, is resolved. 3.3 Use of CNRI HandlesThe CNRI Handle System is used not only to ensure globally unique, persistent identifiers for Objects but also to keep track of the locations of those Objects. At this point, this is achieved in a rather simple fashion; more robust strategies are the subject of future work. In general, each Source Repository in which new Objects are created has a unique Handle prefix or sub-prefix. These must be one of the Handle prefixes that the Source Repository "owns". This means that the Source Repository can safely generate new Handle suffixes without fear of clashing with other Source Repositories. (Note that generating suffixes is not a function of the core Handle System itself.) The federation Local Handle Service (which may be mirrored for performance and stability) stores all Handles for Objects in the federation. Each Source Repository has an administrative Handle that gives the Repository the rights to create Handles within its prefixed namespace. Additionally, there may be one or more general administrative Handles that enable Replicating Repositories to update those Handle Records with information about copies. Note that Replicating Repositories with access to these Admin Handles are "trusted", since they will be able to complete a rewrite of the Handle Record if they choose; a more sophisticated mechanism for updating Handle Records would be required to implement a more complex and secure mechanism. When an Object is created, a corresponding Handle Record is created with the following data:
When a Replicating Repository replicates an Object, it adds the URL of its Web UI "display page" for the object at higher indices (2, 3, ...). If an object is deleted, all URL data is removed with the exception of index 1, which will then point to an appropriate "tombstone" page (in the owning Source Repository). Note that the use of the URL of the Web UI display page is limiting in that it only allows direct resolution to that page. To enable further services, more information is needed; this is a focus for future work. Also note that if a Handle Record contains multiple URLs, the URL used for HTTP redirection is indeterminate, hence the need for a specialised Handle HTTP Proxy as described in the next section. To achieve this, Handles are displayed with the URL of the proxy for the federation, e.g.:
This represents a relatively simple use of the data in Handle Records; it is not sufficient, for example, to enable automated services to retrieve and work on the underlying bitstreams in the Object. The exact data that should be stored in the Handle Record to enable this is the subject of ongoing work, in close collaboration with CNRI. 3.4 The Central RegistryThe Central Registry has three main functions.
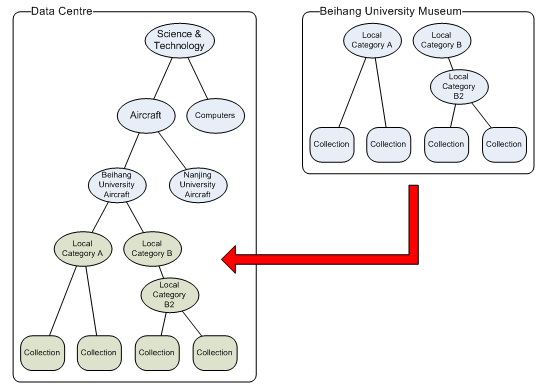
Note that currently, the data about Source Repositories (i.e., their name, OAI-PMH base URL and so forth) is entered manually via a Web UI rather than by any automated discovery-based technique. 4 Object LifecyclesThis architecture is intended to address the lifecycle of Objects, including creation, modification, and deletion. As previously described, a necessary property is that each Object must have a single "owning" repository, which is the only repository that may change the Object. 4.1 CreationAfter Objects are created, the corresponding METS DIPs will be harvested by interested Replicating Repositories because the OAI date stamp will be the moment of creation. 4.2 ModificationWhenever an Object is modified, the METS DIP will have changed, and the corresponding OAI date stamp will also change, which means that harvesting Replicating Repositories will see the updated Object. Additionally, as noted by Van de Sompel et al. [5], if any of the constituent bitstreams changes, this will necessarily cause the METS DIP and the OAI date stamp to be updated as well. 4.3 DeletionIf an Object is deleted, the date of deletion is recorded by the owning repository, and harvests will yield a status of "deleted" for that record, signalling Replicating Repositories to delete (or at least hide) their copies. Also the corresponding Handle Record is cleared of URL data, except for a single URL that points to a "tombstone" page in the owning Source Repository. 4.4 Transfer of Primary OwnershipFor a number of reasons, it may be necessary or desirable to change which repository owns a particular Object, i.e., has permission to modify it and possibly responsibility for exposing it for replication via OAI-PMH. As described in section 3.1 of this article, we require that ownership is managed at the Handle prefix level; i.e., it is only possible to transfer ownership of all Objects with a particular prefix, rather than transferring individual Objects. Ownership is transferred by modifying the repository data in the Central Registry such that the new owning repository is registered as the sole owner of the prefix. As the corresponding OAI date stamps are updated, Replicating Repositories learn of this change. When this happens, the Replicating Repositories need to update their local registry, including transferring identifiers in the lists of Objects that failed validation. Provided the new owning Source Repository maintains the OAI date stamps of individual Objects and the Replicating Repository harvests the new owning Source Repository, replication of the Object and updates will continue seamlessly. When more complex and/or selective replication policies are introduced, this situation also becomes more complex; this is the subject of future work. 4.5 ContainersThe DSpace data model has "container" and other relationships between Objects (as do many other models). In this architecture, containers are not treated differently than other Objects, which means they are also harvested as METS DIPs. Essentially, "containership" is a relationship between one Object and another. These relationships are specified in the METS DIPs. The METS DIP for each container Object (for example, Community or Collection in the DSpace data model) contains the identifiers of all contained Objects, as opposed to having the METS DIPs for each Object specifying the identifier of the container. Thus, when Objects are added to a container, the container itself changes and will be re-harvested by Replicating Repositories. If an Object is moved between containers, the container METS DIPs change, but the Object itself does not. This allows the container's lifecycle to be managed somewhat independently of the contained Objects. Therefore, it is possible to move large numbers of Objects between containers without needing the METS DIPs for all Objects to be re-harvested. In a system such as DSpace, this enables the entire data model to be replicated automatically in a Replicating Repository and updated over time. In the China Digital Museum Project, individual university museums may have a local community/collection structure; the central "virtual museums" can replicate this useful structure within a broader subject-based community/collection structure, as shown in Figure 2.
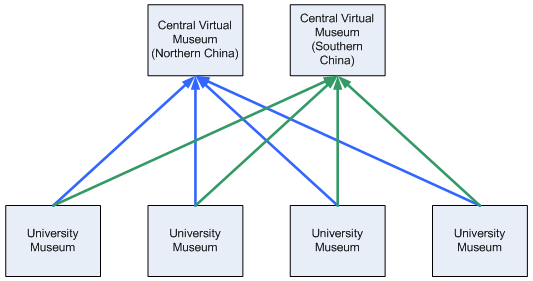
5 Repository LifecyclesIn addition to individual Objects having lifecycles, repositories themselves have lifecycles. 5.1 CreationWhen a new Source Repository is created, its information is added to the Central Repository. Replicating Repositories will then learn of the new Source Repository's existence when harvesting the Central Registry and can choose to start replicating from it if appropriate to the Replicating Repository's policy. 5.2 MovingRepositories may move between organisations, or between hardware and software platforms, necessitating a change in URLs. If the repository is simply changing URLs, the relevant data can be updated in the Central Registry (along with the date stamp for the repository), and Replicating Repositories will automatically receive the updated information. 5.3 Merging and SplittingMerging repositories (for example, replacing a two Source Repositories with a single Source Repository), is also relatively simple. Ownership of all Objects is transferred to the new Source Repository as described in section 4.4. The redundant Source Repository or Repositories are tagged as "deleted" from the Central Registry, and Replicating Repositories will receive this information. Those Replicating Repositories should seamlessly start getting updates for those Objects from the new Source Repository. Within the constraints detailed in section 3.1, splitting a repository can only be achieved if that repository contains more than one Handle prefix. If ownership of Objects were tracked individually, further splitting would be possible; however, if the number of Objects is large, this could be a cumbersome task. 5.4 RemovalAt the simplest level, if a repository is removed from the federation, it is removed from the Central Registry, and Replicating Repositories soon learn about that removal via their OAI-PMH harvests. Whether this is a planned removal or simply the unintended, permanent loss of a repository (for example, as the result of a natural disaster), ownership of Objects can be transferred to from one repository to another – provided at least one other repository has a complete copy of all the Objects. Thus, if preservation is one of the intended uses of the architecture, it is very prudent to ensure that at least one Replicating Repository has a complete copy of the Objects held in a Source Repository! 6 Applications and TopologiesThe architecture described in this article has been developed primarily to address the needs of the China Digital Museum Project, but the architecture can be used to address a number of use cases. Three of these are described in the following sections. 6.1 The China University Museums and Data CentresIn the China Digital Museum project, each University Museum runs a local repository (DSpace), and ingests digitised content and metadata into it. Each University Museum is thus a Source Repository. Additionally, two large-scale "data centres", in the north and south of China, replicate the contents of all of those University Museums. These data centres are hence Replicating Repositories. These central DSpace instances can then be the focus of various preservation activities (for example, backups), which means that each University Museum does not need to have local expertise and resources for this activity. If a university museum DSpace repository fails, ownership of the corresponding Objects is transferred to the data centre. If desired, a new university museum DSpace repository can be created, which then treats one of the data centres as a Source Repository and replicates the relevant Objects. Ownership thus can then be transferred back to the original university museum DSpace repository, and operations can continue as before. In this use case, as well as allowing the centralisation of preservation activities, the central Data Centres can organise the complete contents of the federation into subject-based "virtual museums" where Objects are arranged by topic rather than by location. The availability of two Data Centres means that many users can be served concurrently. The deployment of the China Digital Museum architecture is shown in Figure 3.
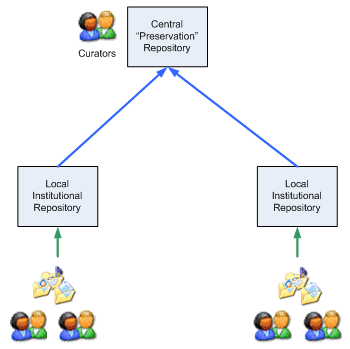
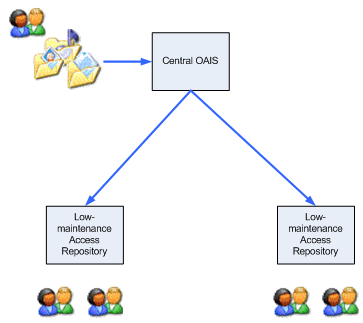
6.2 Centralised PreservationOther possible use cases enable centralisation of preservation, and potentially ingest operations, and allow lower-maintenance peripheral repositories to be used either as pure access points or pure ingest points. Two such scenarios are depicted in Figure 4 and Figure 5.
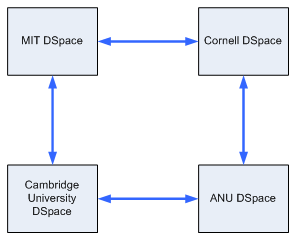
6.3 Peer-to-peer Institutional RepositoriesA set of institutions can agree, for preservation purposes, to replicate each other's content using the approaches outlined in this article. Each institutional repository has a unique Handle prefix and acts as a Source Repository. Additionally, if an institution has a replication agreement with another institution, each will replicate the Objects from that repository. This is shown in Figure 6.
7 Conclusions and Future WorkWe have presented an architecture and set of processes for deploying a federated set of repositories, in which multiple copies of Objects can exist for preservation and efficient access, and in which Objects are centrally tracked. The architecture can handle the lifecycle of individual Objects and the lifecycles of repositories themselves. The architecture can be deployed in a number of use cases. The architecture also brings us a step closer to realising one of the original DSpace visions that informed its name – a federation of repositories that together form a single, distributed "digital space" of digital content, in which a group of institutions can share responsibility for the long-term stewardship of that content. However, there is much scope for future work. 7.1 SecuritySecurity and access control issues in various dimensions need to be addressed further. Firstly there is security in the replication process. In the architecture presented here, in general members of a federation are "trusted"; each Source Repository can use IP-level security to ensure that only authorised Replicating Repositories can replicate data. More finely grained access control is hard to achieve with OAI-PMH, which does not have a security model. Related to this, in addition to controlling who can replicate Objects, there is the issue of who has the right to "advertise" that they have a copy of the Object by adding it to the Handle Record. In the current implementation, all repositories in a federation are trusted; finer-grained control of this aspect may require additional services not present in the native Handle System that must be implemented on top. Thirdly, authenticity of the Objects themselves is an issue. Digital Signatures can be used to guarantee reliable transport of the METS DIPs as described in [6]. Finally, there is the issue of rights management of the individual Objects. If a user does not have the right to access a particular Object or bitstream at repository A, can we ensure that they cannot access it at repository B? Various technologies are emerging to manage this kind of distributed security problem. The China Digital Museum Project is taking a relatively simple approach: Each bitstream may have an "access level" of "public", "registered user" and "administrator", which can easily be specified in the METS DIPs. Users of each repository are correspondingly given one of those access levels (essentially a role). As in the replication-level security, there is a trust relationship between the repositories that each repository will enforce these access controls. Technologies such as Shibboleth [7] may provide more sophisticated mechanisms. 7.2 ScalabilityScalability also has various dimensions. The architecture scales to large numbers of users very well, because there may be numerous access points for each Object. Scalability in terms of the number of Objects replicated depends on the topology (who replicates from whom) and on the associated network capacity. This will probably require careful orchestration moving forward, as it clearly will become unviable for every repository to replicate everything from every other repository if the number of repositories and Objects grows large. In general, OAI-PMH-based transfer of METS DIPs should scale to most needs. The biggest obvious bottleneck is the use of HTTP GET to replicate the underlying content; if there are huge bitstreams, this will cause problems. A variety of approaches can be taken. If distributed Grid storage is underlying each repository, such as the Storage Resource Broker [8] or ChinaGrid [9], transfers can be taken care of at that level. Essentially, during the replication process, instead of GETting a bitstream, the Replicating Repository can "register" the bitstream, essentially issuing a hint or request to the storage system that a copy should be retrieved. Since this might not occur in serial with the replication process, the validation of checksums will not occur as part of that process, but Grid storage systems are designed to take care of that aspect. This presents an interesting architecture, where essentially the repositories are each exchanging and managing Object metadata and access control at the application level, but are essentially "sharing" distributed virtual Grid storage. One further dimension of scalability is in terms of administration or management. The architecture presented raises the bar relatively high for successful replication of Objects; the METS DIP must be fully XML Schema validated, and the files must be fully and accurately transferred. In any system with preservation as a goal, these are fairly fundamental requirements. However, as the number of Objects and repositories increases, the burden of management of the overall system (such as identifying causes of failures) also increases. The proposed replication algorithm is effective at recovering from problems, but reducing the work involved in identifying and resolving problems may be an important future step. 7.3 ProvenanceA key issue that is not addressed at the architectural level in this article is provenance. In the presented architecture, each Replicating Repository is responsible for storing provenance information when an Object is replicated. This may mean that when ownership of an Object is transferred, the Object itself is changed in that this provenance information becomes part of the "authoritative" copy of the Object in the federation. 7.4 A More Complex WorldThe architecture described here requires various simplifying properties. Federations are in general closed communities, and participating repositories trust each other. Although the Handles in the system can keep track of the location of individual Objects, ownership is managed at the broad collection level (Handle prefix). The architecture does not currently speak to selective replication agreements, for example if one institution agrees to replicate a certain quantity of content from another as opposed to "everything". It was felt that these properties were necessary to make implementing the architecture tractable in the first instance. There is much scope for pushing this forward to a more open world; however, things rapidly get much more complicated. Nevertheless, we feel this work has made a significant step in the right direction. 8 Acknowledgments(Chinese names are given family name first.) The author would like to thank Mr. Aaron Ma and Dr. Liu Wei of Hewlett-Packard, and Professor Shen Xukun and Professor Qi Yue of Beihang University for setting up, supporting and managing the China Digital Museum Project. The author would like to especially thank Ms. Chen Bailing (Michelle), Mr. Huang WeiHua, Ms. Li Xiaoyu (Rita) and Ms. Wang Shu (Sandy) of Beihang University for their hard work in building and testing the initial prototypes of the architecture described in this article. 9 Notes1. DSpace <http://www.dspace.org>. 2. Metadata Encoding and Transmission Standard (METS) <http://www.loc.gov/standards/mets/>. 3. Corporation for National Research Initiatives (CNRI) home page, <http://www.cnri.reston.va.us/>. 4. The Handle System®, <http://www.handle.net>.10 References[1] Van de Sompel, Herbert, Jeroen Bekaert, Xiaoming Liu, Lyudmila Balakireva, Thorsten Schwander. aDORe: a modular, standards-based Digital Object Repository. The Computer Journal, 2005, 48(5):514-535; <doi:10.1093/comjnl/bxh114>. [2] Jerez, Henry, Manepalli, Giridhar, Blanchi, Christophe and Lannom, Lawrence. ADL-R: The First Instance of a CORDRA Registry. D-Lib Magazine, 12(2); <doi:10.1045/february2006-jerez>. [3] Manepalli, Giridhar, Jerez, Henry, and Nelson, Michael. FeDCOR: An Institutional CORDRA Registry. D-Lib Magazine, 12(2); <doi:10.1045/february2006-manepalli>. [4] Robert Kahn and Robert Wilensky. A Framework for Distributed Digital Object Services. (This paper was written by the authors May 13, 1995, and made available via the Internet, <hdl:4263537/5001>. A version that includes a preface by the authors was recently published by Springer-Verlag in the International Journal on Digital Libraries, (2006) 6(2): 115-123; <doi:10.1007/s00799-005-0128-x>.) [5] Van de Sompel, Herbert, Michael L. Nelson, Carl Lagoze, Simeon Warner. Resource Harvesting within the OAI-PMH Framework. 2004. D-Lib Magazine 10(12); <doi:10.1045/december2004-vandesompel>. [6] Bekaert, Jeroen and Van de Sompel, Herbert. A Standards-based Solution for the Accurate Transfer of Digital Assets. 2005. D-Lib Magazine 11(6); <doi:10.1045/june2005-bekaert>. [7] Shibboleth. <http://shibboleth.internet2.edu/>. [8] Storage Resource Broker - Managing Distributed Data in a Grid, Arcot Rajasekar, Michael Wan, Reagan Moore, Wayne Schroeder, George Kremenek, Arun Jagatheesan, Charles Cowart, Bing Zhu, Sheau-Yen Chen, Roman Olschanowsky, Computer Society of India Journal, Special Issue on SAN, Vol. 33, No. 4, pp. 42-54, October 2003. [9] Guangwen Yang, Hai Jin, Minglu Li, Nong Xiao, Wei Li, Zhaohui Wu, Yongwei Wu, Feilong Tang, "Grid Computing in China", Journal of Grid Computing, Vol.2, No.2, pp.193-206, June 2004. Copyright © 2006 Robert Tansley |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/july2006-tansley
|