| ||
D-Lib Magazine
|
|
|
Rachel Heery |
![]()
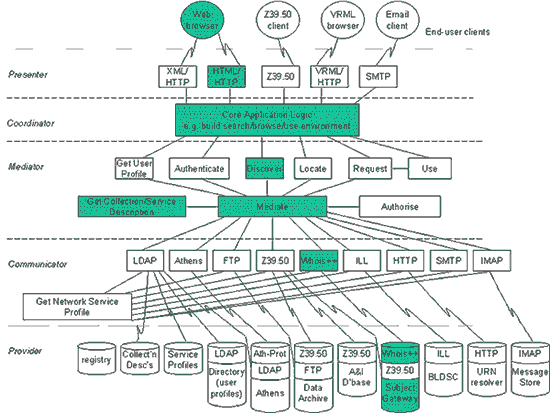
IntroductionFor those building digital library services, the organisational barriers are sometimes far more intractable than technological issues. This was firmly flagged in one of the first workshops focusing specifically on the digital library research agenda: Digital libraries are not simply technological constructs; they exist within a rich legal, social, and economic context, and will succeed only to the extent that they meet these broader needs (Lynch and Garcia-Molina [1]). The innovatory drive within the development of digital library services thrives on the tension between meeting both technical and social imperatives. The Renardus project partners have previously taken parts in projects establishing the technical basis for subject gateways (e.g., ROADS [2], DESIRE [3], EELS [4]) and are aware that technical barriers to interoperability are outweighed by challenges relating to the organisational and business models used. Within the Renardus project there has been a determination to address these organisational and business issues from the beginning. Renardus intends initially to create a pilot service, targeting the European scholar with a single point of access to quality selected Web resources. Looking ahead beyond current project funding, it aims to create the organisational and technological infrastructure for a sustainable service. This means the project is concerned with the range of processes required to establish a viable service, and is explicitly addressing business issues as well as providing a technical infrastructure. The overall aim of Renardus [5] is to establish a collaborative framework for European subject gateways that will benefit both users in terms of enhanced services, and the gateways themselves in terms of shared solutions. In order to achieve this aim, Renardus will provide firstly a pilot service for the European academic and research communities brokering access to those European-based information gateways that currently participate in the project; in other words, brokering to gateways that are already in existence. Secondly the project will explore ways to establish the organisational basis for co-operative efforts such as metadata sharing, joint technical solutions and agreement on standardisation. It is intended that this exploration will feed back valuable experience to the individual participating gateways to suggest ways their services can be enhanced. Funding from the UK Electronic Libraries (eLib) programme and the European Community's Fourth Framework programme assisted the initial emergence of information gateways (e.g., SOSIG [6], EEVL [7], OMNI [8] in the UK, and EELS in Sweden). Other gateways have been developed by initiatives co-ordinated by national libraries (such as DutchESS [9] in the Netherlands, and AVEL [10] and EdNA [11] in Australia) and by universities and research funding bodies (e.g., GEM [12] in the US, the Finnish Virtual Library [13], and the German SSG-FI services [14]). An account of the emergence of subject gateways since the mid-1990s by Dempsey [15] gives an historical perspective -- informed by UK experience in particular -- and also considers the future development of subject gateways in relation to other services. When considering the development and future of gateways, it would be helpful to have a clear definition of the service offered by a so-called 'subject gateway'. Precise definitions of 'information gateways', 'subject gateways' and 'quality controlled subject gateways' have been debated elsewhere. Koch [16] has reviewed definitions and suggested typologies that are useful, not least in showing the differences that exist between broadly similar services. Working definitions that we will use in this article are that a subject gateway provides a search service to high quality Web resources selected from a particular subject area, whereas information gateways have a wider criteria for selection of resources, e.g., a national approach. Inevitably in a rapidly changing international environment different people perceive different emphases in attempts to label services, the significant issue is that users, developers and designers can recognise and benefit from commonalties in approach. The Renardus project has brought together gateways that are 'large-scale national initiatives'. Within the European context this immediately introduces a diversity of organisations, as responsibility for national gateway initiatives is located differently, for example, in national libraries, national agencies with responsibility for educational technology infrastructure, and within universities or consortia of universities. Within the project, gateways are in some cases represented directly by their own personnel, in some cases by other departments or research centres, but not always by the people responsible for providing the gateway service. For example, the UK Resource Discovery Network (RDN) [17] is represented in the project by UKOLN (formerly part of the Resource Discovery Network Centre) and the Institute of Learning and Research Technology (ILRT), University of Bristol -- an RDN 'hub' service provider -- who are primarily responsible for dissemination. Since the start of the project there have been changes within the organisational structures providing gateways and within the service ambitions of gateways themselves. Such lack of stability is inherent within the Internet service environment, and this presents challenges to Renardus activity that has to be planned for a three-year period. For example, within the gateway's funding environment there is now an exploration of 'subject portals' offering more extended services than gateways. There is also potential commercial interest for including gateways as a value-added component to existing commercial services, and new offerings from possible competitors such as Google's Web Directory and country based services. This short update on the Renardus project intends to inform the reader of progress within the project and to give some wider context to its main themes by locating the project within the broader arena of digital library activity. There are twelve partners in the project from Denmark, Finland, France, Germany, the Netherlands and Sweden, as well as the UK. In particular we will focus on the specific activity in which UKOLN is involved: the architectural design, the specification of functional requirements, reaching consensus on a collaborative business model, etc. We will also consider issues of metadata management where all partners have interests. We will highlight implementation issues that connect to areas of debate elsewhere. In particular we see connections with activity related to establishing architectural models for digital library services, connections to the services that may emerge from metadata sharing using the Open Archives Initiative metadata sharing protocol, and links with work elsewhere on navigation of digital information spaces by means of controlled vocabularies. The Renardus architectural modelThe Renardus functional model is being developed through an iterative and collaborative process, from the initial investigations of user requirements [18, 19] and the technology currently available to meet those requirements [20], via elaboration in a specification of functional requirements [21] and culminating in the model of an architecture for the broker system [22]. The emphasis here is on functions required by users to support their information-seeking and resource-discovery goals, and by service providers to ensure the quality of the resource-discovery services provided collaboratively and individually in the context of organisational frameworks and business concerns. This work was informed by earlier modelling work that was carried out within the context of MODELS (Moving to Distributed Environments for Library Services), a UKOLN initiative supported by the eLib Programme and the British Library [23]. The MODELS Information Architecture (MIA), a generic, layered logical architecture [24], provided a structure for a review of existing broker models. Eighteen examples of existing resource discovery broker architectures were analysed and compared by mapping them onto the MIA (see Figure 1 for an example). In addition the evolving MIA Functional Model influenced the choice of Use Cases for modelling the Renardus functional requirements. It is hoped that results of the Renardus work will feed back to the ongoing development of the MODELS application framework, and also to the IMesh Toolkit project [25]. The IMesh Toolkit project is providing subject gateway developers with a systems framework for an extendable set of interoperable tools and components.
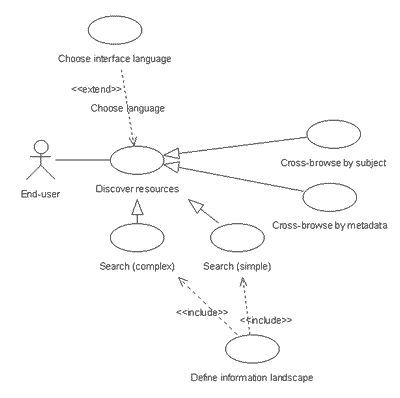
The functional requirements represent a shared understanding of what is needed from the Renardus Broker System. The initial survey of user requirements, and the business requirements of the participating gateways have now been expressed as Use Cases, using the Unified Modeling Language (UML) [26, 27]. UML provides a set of graphic representations to co-ordinate the software development process. The product of a major standardisation effort among those devising and using methods of object-oriented systems analysis, design, and development, UML was adopted as a standard by the OMG (Object Management Group) in 1997. Since its adoption as a standard, UML has emerged as the notation of choice for expressing designs across a variety of design methods. Architectural modelling in UML documents the significant decisions about the structure and behaviour of a system. Use Cases form the core of the developing Renardus system architecture, and drive the design and development of the Renardus system. Figure 2 shows the relationships between the Renardus end-user Use Cases for the pilot broker system. An Actor represents a role played by a user, and a Use Case expresses a functional requirement as a set of system behaviour that meets a user goal. Each Use Case is documented using a modified version of the template made available by Cockburn on his Web site [28]. This includes identification of the primary Actor, the Actor's goal, a main scenario (and where appropriate, alternative or extended scenarios), pre-conditions for the Use Case to start, and end conditions when the goal is achieved or abandoned, as well as related information such as performance requirements.
The Renardus architecture consists of two views of the system: a functional Use Case view (focussed on the system behaviour) and an implementation view (focussed on the system structure). Each element in the implementation view should be traceable to the requirements expressed in the functional view. Each requirement in the functional view should be traceable to a component or components in the implementation view facilitating it. In this way it can be verified that the system as planned and built meets the agreed requirements, and that development effort is not allocated to components which are not required. New requirements may be discovered during the course of development, and within a sound change-management framework new requirements must be agreed and documented. Information-seeking task analysisThe initial elaboration of functional requirements with Use Cases formed a basis upon which to begin system design for the Renardus pilot but at this stage, due to time constraints, it was only possible for project partners to validate the Use Cases. For a truly participatory design approach, directly involving end users would improve the validity of the requirements modelling phase. The opportunity to work with the Human-Computer Interaction (HCI) Group at the University of Bath on a task analysis [29] of information-seeking behaviour was therefore welcomed. Some work has now been carried out directly with users to investigate how they act within different resource discovery contexts, involving different search services. The resulting task models, expressed as UML Activity Diagrams, can then be compared with the original Use Cases to validate them against real user experience. Although this process will not be completed for the pilot implementation, it will contribute to further work within Renardus developing an architectural model for information gateways. It is hoped that the task models being developed will also contribute to the evaluation of Renardus usability. The usability evaluation will be carried out by Jyväskylä University Library, Finland, with the assistance of other project partners not directly involved in system development, once the prototype pilot is made available in a test-bed environment. It will be based on user tests followed up with questionnaires designed to document user successes and problems, and some of the testers will be directly observed. These tests could be based on the task scenarios that were an intermediate step in devising the task models, with the task models themselves providing a structure for relating the test results to usability goals. Issues in relation to the use of task models for usability evaluation include:
If these issues can be satisfactorily addressed, the task models developed here might have wider applicability for design and evaluation of subject-based gateways and brokers. The models and the experience of using them could form the basis for a usability evaluation methodology adapted to this context, and to the broader digital library context. Classification mappingLooking back to the 1995 workshop mentioned above, Lynch and Garcia-Molina identified a spectrum of interoperability from 'use of common tools' to 'deep semantic interoperability' and projects are still grappling to locate themselves along this continuum. Renardus, along with other initiatives, has to achieve a balance in terms of cost (stakeholder resources) and feasibility (stakeholder commitment). Each gateway participating in Renardus will continue to provide its own distinctive service within its own business environment. Therefore, from the individual gateway perspective, Renardus is just another 'delivery channel'. This constraint has led to realistic options for the data model and functional requirements. However, there are opportunities built into the project for research into features to provide 'added value', such as cross browsing of subject hierarchies across gateways, and metadata sharing. Enhanced subject access is considered a key differential offered by subject gateways, and an important part of the Renardus service will be its attempt to provide some kind of subject directory browsing service across the participating gateways. At present partners are investigating means to enable the user to browse a single subject hierarchy covering the content of all participating gateways. In order to achieve this, a classification scheme has been chosen to act as an 'interlingua' within the Renardus pilot. The scheme chosen is the Dewey Decimal Classification (DDC) which is a well-established general classification scheme currently in its 21st edition, published and maintained by OCLC Forest Press [30]. Gateways participating in the Renardus system will be invited to map DDC terms to the subject terms used in their own browse hierarchies. In order to facilitate this process, the project established a small working group to prepare guidelines for this work. In addition, a software tool developed as part of the German CARMEN project [31] has been adapted to facilitate the relevant workflow. The mapping will be made from the DDC to the subject browse hierarchies used by participating gateways. This includes a wide range of different subject classification types including some general schemes (e.g., Universal Decimal Classification, Nederlandse Basisclassificatie, etc.), some subject specific schemes (e.g., Mathematics Subject Classification, Ei, etc.) and some schemes produced specifically for the gateway. Also some gateways have considerably modified the schemes that they use. The precise amount of mappings that will need to be produced will depend upon the complexity of the browse structures that have been implemented by gateways. It is not expected that all terms will have direct equivalents in the DDC. For this reason, a set of relevance levels has been defined. These can indicate, for example, where there are narrower or broader equivalents or things like major and minor overlaps. The cross-browse structures that can be created using this system are relatively limited. It is not possible, for example, to link directly to resource descriptions from multiple gateways in a single browse hierarchy without a greater level of centralisation than that offered by the Renardus pilot. Instead, the Renardus browse system will link directly into the subject hierarchies of individual gateways. For example, a user looking for information on violins or violas would first browse through the DDC-based structure on the Renardus system until they find a relevant match (e.g., Stringed Instruments) with its relevance level. If a part of an individual gateway's browse structure has been mapped to this DDC term, the gateway's name is visible and this becomes a hyperlink to the relevant part of the local browse structure. Once the user follows this link, they will leave the Renardus system and join the browse interface of the local gateway. The classification mapping work remains very experimental but promises to be an interesting method of joining the browse structures of distributed services and may be of interest in other contexts also. In particular, it relates to work currently taking place within the UK HILT project [32] which is studying the problem of cross-searching and browsing by subject across a range of communities, services, and service or resource types. HILT will assist with consensus building on best practice in the short to medium term perspective as regards working with existing or new subject schemes and thesauri. Work within Renardus may be able to contribute real implementation experience to this debate. Similarly, in the international context, Renardus will feed back experience to NKOS (Network Knowledge Organization Systems/Services) [33], a loose coalition of people and organisations concerned with the use of knowledge organisation systems such as classification systems, thesauri, gazetteers, and ontologies, to support description and retrieval of resources via the Web. Organisational and business issuesGateway services that were once funded as part of relatively short-term research and development projects are now attempting to develop into services with long-term sustainability. This means that individual gateway services are becoming more concerned with the organisational and business contexts in which they operate, as well as being interested in collaborating with other gateways or gateway initiatives. Very little research work has been done in this area [34]. In addition, ongoing collaborative ventures like Renardus need to set organisational and business goals in order to secure their own long-term sustainability. Over the course of the project lifetime, Renardus plans to investigate the best organisational structures for developing a sustainable service and any associated business and legal issues. The project has already produced a preliminary review of business models in use by existing gateways [35] and will develop this work further during the remainder of the project. It is worth noting that some of the business and legal issues that will need to be addressed in more detail later on have already been raised in the context of developing the Renardus pilot broker. Business issues have already influenced the technical implementation of the broker. Firstly, uncertainty about whether the existing funders of gateways would allow metadata records to be combined in a centralised database has meant that the Renardus broker is based on cross-searching principles only and that no data is held centrally. Secondly, the user interface of the Renardus broker clearly indicates the provenance of each record by means of a logo and a link to the same record description in the local gateway. The management of metadataWithin Renardus there have been, to date, three main approaches to the co-operative management of metadata, and further work is planned in this area. Firstly, and most significant in terms of time and resources, has been reaching consensus on a shared metadata schema. A draft Renardus 'application profile' has been agreed that will form the basic metadata specification for participating gateways. The concept of 'application profile' -- introduced by Heery and Patel [36] -- typifies the process by which an implementation defines a metadata schema optimised for its particular requirements by mixing and matching standard element sets and, where necessary, locally defined additional elements. The Renardus application profile defines the metadata elements required for the Renardus service and has its origins in two processes. The process for reaching consensus on the metadata schema began with debate about what particular metadata elements would be useful for developing a cross-searching service. From this theoretical start, the model was further developed by a detailed review of all the subject gateways involved in the project. Each gateway provided information about its service; most importantly about the metadata formats that it uses and its application of subject terms and controlled vocabularies. From this information, the project proposed a core set of metadata elements that could be used in the broker system. Definitions of the semantics of these elements are based, where possible, on the Dublin Core Metadata Element Set, of which the Renardus data model forms what might now be known as an 'application profile.' The Renardus application profile is still under development, but includes the Dublin Core elements for Title, Creator, Description, Identifier, Subject, Publisher, Language and Type as well as some Renardus-specific elements [37]. Because the Renardus service is based on a distributed architecture with no centralisation of data, those gateways that want to get involved with the Renardus broker would need to support all of the mandatory elements identified by the data model. The metadata elements defined in the data model can either be used directly for cross searching, for helping to refine advanced searches or for ranking result sets. Cross-searching functionality can then be applied across, for example, the title, description and subject elements, while the elements for language, document type and publisher country could be used for helping to filter searches. Secondly there has been discussion, mainly at the beginning of the project, regarding the possibilities of building a physical 'union catalogue' of metadata drawn from different gateways into one database. There has been resistance to gathering metadata from all partners into a central database, influenced by IPR (intellectual property rights) issues relating to gateways' metadata itself but also by the business model individual services have been pursuing. There has been a more favourable reaction to sharing metadata with 'allied services' (whether these are allies of the gateway's own choosing, or where the choice has been that of a joint funder). Sharing in this context has taken the form of either 'swapping metadata' between consenting gateways on a bilateral basis, or contributing to a 'shared database' held by a broker service. Issues concerned with building 'union catalogues' have particular relevance to current interest in the Open Archive Initiative (OAI) metadata sharing protocol [38]. Service providers who are gathering metadata using the OAI metadata harvesting protocol will face similar concerns over IPR and service branding issues. At least within the European context we can expect to see parallel business and organisational concerns arising for OAI service providers to those now occurring for Renardus participating gateways. Thirdly there is the possibility of expanding the scope of the Renardus search service to the end-user. An innovative proposal from the Institute for Learning Research and Technology at the University of Bristol (a Renardus partner) suggests that it would be possible to combine a brokered gateway service with Web indexes based on harvesting techniques [39]. This would expand the range of searchable indexes so the user could simultaneously search existing gateway metadata alongside the full text of selected (and linked) gateway resources. If time and effort were available, it would be extremely useful to develop and evaluate such a service within the context of Renardus, perhaps using the HCI techniques previously mentioned. Such an evaluation would also relate to other investigations of user interaction with complex digital information spaces, such as the 'information landscape' case studies currently being undertaken as part of the Agora project [40]. It remains to be seen whether business and branding issues can be resolved to enable further development of this service, which potentially would add value to Renardus and to individual gateway services as well. Options for metadata sharingOne example of an area where technical and business issues interact is that of collaborative metadata creation [41]. Creation of metadata is one of the most costly aspects of the running a gateway. Within the world of traditional cataloguing (e.g., in libraries) it has long been accepted that economies of scale can be realised by collaborative cataloguing. On the one hand there are several well-established commercial businesses based on the sale and re-sale of catalogue records. The long tradition within libraries of collaboration complements this commercial activity, with libraries co-ordinating their cataloguing effort within this commercial framework, contributing their intellectual effort to enhance existing records and to fill the gaps in record provision. Over time complex algorithms have been developed within traditional online cataloguing systems to ensure the 'best record' is stored, to de-duplicate databases, to allow for efficient searching and download options. Within Renardus we intend to explore possible benefits of collaborative cataloguing for creating metadata about Web resources. We will be informed by the business models for collaborative cataloguing in the traditional library world and re-interpret them for the changed context of creation of metadata for digital resources. Several interesting possibilities are emerging and within Renardus we will choose some of these options for further investigation. For example, we could load a test-bed 'union catalogue' of existing Renardus records to investigate the possible benefits of sharing intellectual effort in cataloguing, as well as to explore automated services to assist the cataloguer. Topics for investigation might include:
By contrast we could also investigate the creation and management of 'distributed metadata' that describes a single resource. One major consequence of the Internet is that there is no longer a need to store digital resources at every single point of access. Digital resources can be stored in a very limited number of places governed by issues of bandwidth load, telecommunication charges, back-up redundancy, and digital preservation rather than any overriding logical necessity to store multiple copies. However, the same practice does not seem to be followed for metadata at the present time. This is perhaps due to the unstructured nature of the services producing, managing and using metadata. As the metadata business matures it seems likely that there will be some rationalisation regarding the creation and sharing of metadata. There may no longer be a need to duplicate metadata describing the same resource in so many locations, rather original metadata will be created and further enhancements to that metadata will be linked to an original authoritative metadata instance. One possible methodology to achieve this is to use XML/RDF annotations. Within Renardus we might explore linking local metadata enhancements to metadata residing in a central 'union catalogue'. The local metadata might enhance centrally stored metadata in terms of:
In order to facilitate any of these more sophisticated approaches to the creation and management of metadata it would seem essential for parallel activity regarding the standardisation of identifiers for metadata records. This is starting to be addressed within the Open Archives Initiative (OAI), which will rely on record identifiers to facilitate harvesting and exchange of metadata. ConclusionIn conclusion, we hope this short account illustrates that the Renardus project is addressing issues of significant relevance to subject gateways and the wider digital library world. The project aims to benefit participating gateways by investigation of new service options, as well as building a new delivery channel for those gateways. For the wider community, there may be lessons learned here that can be applied in the area of technical models and tools, and, perhaps more significantly, in the area of business models and inter-organisational co-operation to support the services to digital library users. AcknowledgmentsRenardus is funded under the European Union's Information Society Technologies (IST) Programme [42]. The project is a joint activity involving contributions from all project partners listed on the Renardus Web site [43] and the authors wish to acknowledge the partners' input to all of the work described in this review. UKOLN is involved with the Renardus project due to our historical position as part of the Resource Discovery Network Centre (RDNC). The authors would like to acknowledge the contributions from both the RDNC and RDN gateways to Renardus activities. The authors would also like to thank David Golightly and the University of Bath HCI Group for participation in and support for the information-seeking task analysis. The authors are responsible for any errors or mistaken perspectives. References[1] Clifford A. Lynch and Hector Garcia-Molina. Interoperability, Scaling, and the Digital Libraries Research Agenda: Report on the May 18-19, 1995 IITA Libraries Workshop, Microcomputers for Information Management: Global Internetworking for Libraries 13 (2), 1996, 85-98: <http://www-diglib.stanford.edu/diglib/pub/reports/iita-dlw/main.html> [2] ROADS (Resource Organisation and Discovery in Subject-based Services) project: <http://www.ilrt.bris.ac.uk/roads/> [3] DESIRE (Development of a European Service for Information on Research and Education) project: <http://www.desire.org/> [4] EELS (Engineering Electronic Library, Sweden): <http://eels.lub.lu.se/> [5] Renardus project: <http://www.renardus.org> [6] SOSIG (Social Science Information Gateway): <http://www.sosig.ac.uk/> [7] EEVL (Edinburgh Engineering Virtual Library): <http://www.eevl.ac.uk/> [8] OMNI (Organising Medical Networked Information): <http://omni.ac.uk/> [9] DutchESS (Dutch Electronic Subject Service): <http://www.kb.nl/dutchess/> [10] AVEL (Australian Virtual Engineering Library): <http://avel.edu.au/> [11] EdNA (Education Network Australia):< http://www.edna.edu.au/> [12] GEM (Gateway to Educational Materials): <http://www.geminfo.org/> [13] FVL (Finnish Virtual Library): <http://www.jyu.fi/library/virtuaalikirjasto/> [14] SSG-FI (Special Subject Guides-Fachinformation): <http://www.sub.uni-goettingen.de/ssgfi/> [15] Lorcan Dempsey, The subject gateway: experiences and issues based on the emergence of the Resource Discovery Network. Online Information Review, 24 (1), 2000, 8-23: <http://www.rdn.ac.uk/publications/ior-2000-02-dempsey/> [16] Traugott Koch, Quality-controlled subject gateways: definitions, typologies, empirical overview. Online Information Review, 24 (1), 2000, 24-34. [17] RDN (Resource Discovery Network): <http://www.rdn.ac.uk/> [18] Kimmo Tuominen, et al., User requirements for the broker system, Renardus project deliverable D1.2, 2000: <http://www.renardus.org/deliverables/> [19] Hans Jürgen Becker, Frank Klaproth and Petra Lepschy, Survey of end user surveys, Renardus project deliverable D6.6, 2000: <http://www.renardus.org/deliverables/> [20] Michael Day, et al., Evaluation report of existing broker models in related projects, Renardus project deliverable D8.1, 2000: <http://www.renardus.org/deliverables> [21] Leona Carpenter, et al., Specification of functional requirements for the broker system, Renardus project deliverable D1.3, 2000: <http://www.renardus.org/deliverables/> [22] Leona Carpenter, et al., Architectural model for the broker system, Renardus project deliverable D1.5, 2001 (forthcoming). [23] MODELS (MOving to Distributed Environments for Library Services): <http://www.ukoln.ac.uk/dlis/models/> [24] MIA (Models Information Architecture): <http://www.ukoln.ac.uk/dlis/models/requirements/arch/> [25] IMesh Toolkit project: <http://www.imesh.org/toolkit/> [26] Grady Booch, James Rumbaugh and Ivar Jacobson, The Unified Modeling Language user guide, Reading, Mass: Addison Wesley, 1999. [27] Martin Fowler, UML distilled: a brief guide to the standard object modeling language, 2nd ed., Reading, Mass.: Addison Wesley, 2000. [28] Alistair Cockburn, UseCases.org: <http://www.imesh.org/toolkit/> [29] Peter Johnson, Hilary Johnson and Stephanie Wilson, Rapid prototyping of user interfaces driven by task analysis. In: John M. Carroll, (ed.), Scenario-based design: envisioning work and technology in system development. New York: Wiley, 1995, 209-246. [30] Joan Mitchell, et al., (eds.), Dewey decimal classification and relative index: devised by Melvil Dewey, 21st ed., Albany, N.Y.: Forest Press, 1996. [31] CARMEN (Content Analysis, Retrieval and MetaData: Effective Networking) project WP12: <http://www.bibliothek.uni-regensburg.de/projects/carmen12/> [32] HILT (High-Level Thesaurus) project: <http://hilt.cdlr.strath.ac.uk/> [33] Networked Knowledge Organization Systems/Services (NKOS) home page: <http://alexandria.sdc.ucsb.edu/~lhill/nkos/> [34] Leah Halliday and Charles Oppenheim, Economic aspects of a resource discovery network, Journal of Documentation, 57 (2), 2001, 296-302. [35] Michael Day, et al., Business issues which impact the functional model, Renardus project deliverable D8.1, 2000: <http://www.renardus.org/deliverables/> [36] Rachel Heery and Manjula Patel, Application profiles: mixing and matching metadata schemas, Ariadne, 25, September 2000: <http://www.ariadne.ac.uk/issue25/app-profiles/> [37] Lesly Huxley, Follow the fox to Renardus: an academic subject gateway service for Europe. In: José Borbinha and Thomas Baker, (eds.), Research and advanced technology for digital libraries: 4th European Conference, ECDL 2000, Lisbon, Portugal, Lecture Notes in Computer Science, 1923, Berlin: Springer-Verlag, 2000, 395-398. [38] OAI (Open Archives Initiative): <http://www.openarchives.org/> [39] WSE (Web Search Environments) project: <http://wse.search.ac.uk/> [40] Agora project: <http://hosted.ukoln.ac.uk/agora/> [41] Rachel Heery, Information gateways: collaboration on content, Online Information Review, 24 (1), 2000, 40-45: <http://www.ukoln.ac.uk/metadata/publications/oir-2000-02-heery/> [42] Information Society Technologies Programme: <http://www.cordis.lu/ist/> [43] Renardus project partners: <http://www.renardus.org/about/partners.html> All links checked on March 26, 2001. Copyright 2001 Rachel Heery, Leona Carpenter and Michael Day |
|
| |
|
|
Top
| Contents |
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2001-heery
|