D-Lib Magazine
September 1998
ISSN 1082-9873
Access Management of Web-based Services
An Incremental Approach to Cross-organizational Authentication and Authorization

Ariel Glenn and David Millman
Columbia University
New York, New York
[email protected]
[email protected]

Abstract
We describe the construction of access management "broker" software for web-based services in a university setting. The broker works with an existing institutional ID and directory infrastructure, permits delivery of complex remote services from providers outside of the home organization, and provides user attributes to remote service providers. We discuss ways in which the broker might be used to develop a cross-organizational access management system.
1.0 Introduction
Cross-organizational access management for web-based resources has emerged as a topic of great interest among many information consuming institutions and information resource providers. These organizations wish, as precisely and as flexibly as possible, to enable access to particular networked resources to particular members of institutional consumer communities. Access should be simple for the user, should guarantee a large measure of privacy to the user, should not depend entirely on the user's location or network address but rather on the user's membership in appropriate communities, and should provide necessary management and demographic information to institutional consumer administrators and to resource providers. Here, we will describe several architectural models for such cross-organizational access management services now under development at Columbia University.
A flexible and robust access management service is more than a technical architecture; it must also address a number of other difficult issues, including policy and infrastructure considerations, deployment of technology in an uncertain market and broad consensus and development of standards among key players. Clifford Lynch [Lynch98] has recently provided an excellent summary and discussion of the issues and the state of the art in cross-organizational authentication and access management. While we will touch on many of these issues as they pertain to our motivation and our work, we refer the interested reader to Lynch's comprehensive and thoughtful document for additional context.
Below, we will discuss the history of our institutional access management systems and our motivation for our current work; we will describe our proposed architecture models; we will discuss some outstanding issues out of the scope of our proposal; and we will indicate the directions we feel are appropriate next steps or areas requiring new research.
2.0 History and Motivation
Two technical infrastructure components are minimally required for an institutional access management system: the ability of a user to obtain an identity on the network, known as authentication; and the ability to correlate a user's identity with rights and permissions to use various services, called authorization.
Often these two services are combined in simple ways which blur their distinction, such as the UNIX implementation of file permission policy through group membership, "uids" and "gids." More robust and scalable authentication and authorization services may instead arise independently and be supported by special purpose systems rather than as side-effects of particular operating systems or other technologies.
Management systems for computer identities at Columbia University began in 1983, by deploying a simple database to consolidate and manage e-mail accounts for a quickly growing population. Over the next several years, the process became increasingly automated and complex, with data feeds of potential e-mail users arriving from the personnel and student administrative systems, from affiliate institutions, and from the libraries. By 1990, we found our database to be the most authoritative directory of individuals on campus, so we initiated an on-line "phone book" lookup service. Soon after, we participated in the NYSERnet X.500 directory pilot. We also began an experiment with the Kerberos authentication software [Col92]. Kerberos does not require a directory entry, only a unique identifier for an individual and the person's password. In "pure" Kerberos environments, a "Kerberos login" enables secure network communication within a local jurisdiction, and can be logically decoupled from e-mail accounts or particular timesharing systems. But we did not have such an environment and had no immediate practical use for our Kerberos service.
Meanwhile, Columbia had developed a terminal-based "Campus-Wide Information System," called ColumbiaNet, in 1988. At the time, it was one of a number of such systems underway at several universities, offering anonymous online public access to such things as class, shuttle bus and gym schedules, campus events, and, of course for us, the phone book directory. When the "Gopher" protocol emerged as a standard for exchange of public information over the Internet, ColumbiaNet embraced it and extended it. ColumbiaNet became our transition software to offer multiple library catalogs in a single interface; and we began plans to develop it into a gateway to remote licensed online resources, such as the RLG and OCLC catalogs (RLIN, FirstSearch) and full-text reference books from our university press.
For licensed services, totally anonymous access was no longer possible. We had the Kerberos infrastructure available to identify, with id and password, any of the now 60,000 individuals known to us from our many directory feeds -- our extended community in some sense. But only a subset, the students and employees of Columbia, were covered by our licenses. We began to employ our directory service in order to screen individuals for access. In 1992, the ColumbiaNet application became the first "customer" of combined authentication and authorization services. Kerberos authenticates individuals, but for services only as deemed appropriate through the screening process. And ColumbiaNet, a terminal-based gateway, was able to invisibly "script" the login negotiation with remote service providers, thus acting as both an institutional filter for incoming users and as a trusted institutional "representative" to remote services.
Lately, our nearly total migration to the web incorporated most of these same mechanisms, with end-to-end encryption on the network (SSL), updated to the current directory standards (LDAP) and with our institutional Kerberos identity infrastructure intact by local modification to our web server (Figure 1). But the web architecture, while providing tremendous new capabilities for so many -- and so many new users -- has largely disabled our institutional ability to act as a trusted mediator, to offer-up our pre-screened population to remote service providers.
The prevalent web architecture today relies on a more fundamental, and for us an older, method of access policy: by Internet address ("IP source address"). This method identifies the topological location of a user on the network. Many institutions have also deployed web proxy servers, which alleviate some of the access management difficulties of the basic IP source address method. The drawbacks and trade-offs of these methods have been discussed at length elsewhere, and most recently in the Lynch paper. But neither of these methods enable access management based on the characteristics of the user. They provide authentication and authorization in a single, imprecise step, based primarily on network location.
As remote service providers create increasingly sophisticated services which are customized to individual users, they find they must implement independent user "registration" infrastructures: essentially building duplicate id, password, and user-profile systems for populations that are already part of well established and carefully maintained institutional id systems and directories at their "home" institutions. This is an unfortunate duplication of effort for the provider and annoyance to the user (who must login to each such service independently). Its problems are compounded by its underlying security model: still largely by IP source address or proxy web server.
3.0 Architecture
Given these limitations in the existing approaches and the redundant efforts required, we have been investigating alternative architectures which can leverage the existing authentication and authorization databases at the local organization based on the following guidelines:
- It must be a real-world solution; that is, it must take into account the browsers and web servers currently in use, existing ID and directory systems and an average level of user expertise. Web server modifications must be as modular and as simple to maintain as possible.
- It should allow the retrieval of user information (user "attributes") when specifically needed for the business of a service (for example, a user's fax number for a document delivery service), while otherwise protecting user information from illegal or inappropriate use. For example, student information is strongly protected in the U.S. by the "FERPA" legislation [Col97]. The American Library Association has adopted a set of privacy guidelines as well, reflecting the public's heightened concerns that personal information will be collected and used without the individual's consent [ALA94].
- It should protect any user "secrets." In particular, a user's password may never travel across the network in the clear.
- It should restrict access to services with the desired granularity. For example, some services may be provided to the entire Columbia University student and alumni population; others might be provided to all registered students in a particular set of departments; still others might be restricted to department heads and department administrators.
- It should be reasonably efficient, both in terms of Web server processing and in terms of network traffic.
- It should be as painless to manage and to scale as current technology permits.
In the descriptions of architecture models below, we use a few terms in specialized ways:
- credentials,
refer to information needed to authenticate a user, most commonly a user id and a password; but other methods, such as a digital certificate or "smartcard" are possible. third-party, is a service provider outside of the local organization. attribute, is typically found in an institutional directory service. It is a characteristic of an individual user, which can be more precise (e.g., a name) or less precise (membership in an arbitrary group).
3.1 Initial Model
As described above, our web service includes a locally customized server module. In this model, both the user and the service provider are members of the same institution.
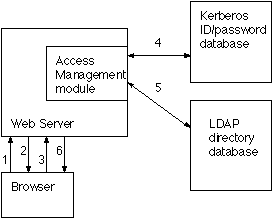
Figure 1. Simple Web Access Management and Messaging Flow
A single transaction in this scenario would proceed as follows:
- User requests a restricted service.
- Web server asks browser for user credentials.
- Browser prompts user for name and password, and resubmits the request with these user credentials.
- Web server's access management module passes user's credentials to institutional validation system to check if the credentials are valid (Kerberos in this example).
- Web server's access management module collects user attributes from institutional directory system (LDAP in this example). Based on the user's attributes it determines whether the user is permitted to access the requested service. For example, the user must be a member of a particular class.
- Web server delivers the service.
This is an improvement over the plain vanilla web authentication provided by a typical web server; it allows the server to leverage the existing infrastructure of the institutional ID system and directory. It assumes that there is a secure communication channel (SSL) between the browser and the web server.
The access management module maintains a cache of user credentials and attributes so that it need not contact the authentication and directory systems for every user request. A user might request a document containing 20 restricted images; the institutional validation and directory systems will be contacted only once.
Public facilities pose their traditional problems in this model. User credentials are kept in the browser until the browser is closed or until the user logs out (typically by requesting a URL which asks the user to explicitly erase the stored password). In this model, user credentials do not expire, and there is no provision in the web protocol for the server to demand fresh credentials. Therefore, if the user does not remember to log out or exit the browser, the next user who sits down at the same workstation will inherit their credentials and capabilities.
This model does not scale well. If more than one such web server exists at the institution, each must be modified to communicate with the institutional authentication and directory systems. Any change to institutional authentication or directory systems requires a change to all modified servers. If there is more than one institutional authentication or directory system in use, the server has no means of choosing which one to use. And this method cannot be scaled to access management between an institution and a remote service provider. Each web server providing restricted services would need to support the authentication and directory systems of all subscribers to its services; this would rapidly become unmanageable.
3.2 Broker Model
Almost immediately, we required more than a single directory system: the alumni offices and certain financial centers at our institution already maintained independent directory systems, wished to continue using them, but also wished to incorporate these existing systems into our access management process. Therefore, we attempted a more scalable architecture by introducing a "broker" service to consolidate and generalize access management. This service includes a new Access Management Broker server and a new plug-in module for web servers.
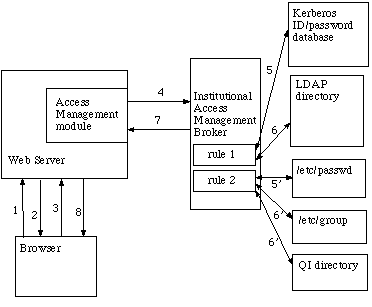
Figure 2. Access Management via a Broker
In this model, requirements for granting service are encoded, in advance, in sets of "rules." The new Access Management Broker server uses a particular rule to decide which authentication and authorization components to use (perhaps several) and how to combine and interpret the information retrieved from them. The protocol between web server and broker server permits the web server to suggest a preferred rule.
A single transaction would thus be:
- User requests a restricted service.
- Web server asks browser for user credentials.
- Browser prompts user for name and password, and resubmits the request with user credentials.
- Web server's access management module sends to the broker: the user's credentials, the service desired by the user, and any user attributes it wishes sent back.
- Broker determines which authentication and authorization rule to use based on the requesting host and the requested service. Broker passes user's credentials to the appropriate authentication system to check the credentials.
- Broker uses the same rule to collect user attributes from the appropriate institutional directory system(s). It then determines, based on the user's attributes, whether the user is permitted to access the requested service.
- Broker notifies the web server whether user is permitted to access to the service and also returns any permissible user attributes which may have been requested by the web server.
- Web server provides access to the service.
This model has some nice properties. Maintenance is much easier: web servers need only to talk to the broker through a single protocol; changes made to institutional ID or directory systems are reflected by changes in the broker software and nowhere else. The broker maintains a cache of credentials and attributes, preserving the performance of the previous model. A web server may request that a cache entry be considered stale beyond some interval, or it might request live verification every time for increased security at the expense of performance.
User privacy is also better protected in this model. The entire directory (names, demographics, all user attributes) is no longer known to the web server by default. A web server must explicitly request any user attributes it requires for business (e.g., a fax number if the service to be performed requires fax to the user, or a cost center identification). Broker server rules can therefore implement useful access management policies in a manner similar to that suggested by Arms [Arms98]. (It is conceivable that a rogue web server could make multiple broker requests and derive considerable user demographics by statistical methods, but this is detectable by auditing broker transactions and is, in any case, unlikely within an institution.)
3.3 Cross-Organizational Access Management by Proxy -- an Interim Approach?
The above methods cannot be extended out of an institution because the user name and password still move through the web server unencrypted. In a cross-organizational setting, that web server would be operated by a remote, or "third-party" service provider, i.e., a provider at another institution, commercial or otherwise. It was not acceptable to permit our user names and passwords to travel either across the Internet unencrypted or through a remote server managed by an outside organization. As a first attempt to solve this, we proposed to channel all requests for such third-party services through a proxy.
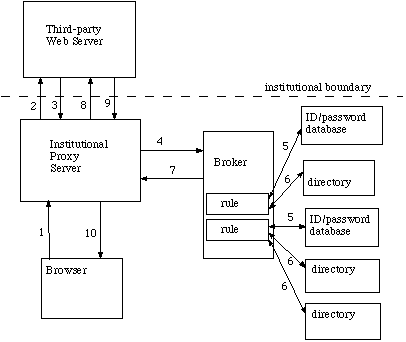
Figure 3. Cross-Organizational Access Management through Institutional Proxy
This interaction might work like this:
(Note step 0: the user must have previously authenticated with the proxy in order to use it. These credentials are present in every request the user sends to the proxy and are kept in the proxy's cache.)
- User requests a restricted service through proxy.
- Proxy forwards request for restricted service to third-party server.
- Third-party server asks proxy for user credentials.
- Proxy checks user credentials from cache with broker, including an identifier for the third-party and the name of the restricted service as additional parameters.
- Broker validates user credentials as before.
- Broker does authorization check as before.
- Broker sends result back to proxy.
- Proxy sends an institutional credential previously agreed upon with the service provider back to the third-party server along with the user's request for service.
- Third-party server checks the institutional credential against a local table, verifies it, and allows proxy access to the service.
- Proxy forwards service to user.
Future requests from the user for the same service must be intercepted by the proxy so that the institutional credential can be passed along to the third-party service provider with the request.
This setup is relatively easy to roll out quickly, as it requires modifications only to the institutional proxy server. But it has the usual drawbacks associated with proxies: if the proxy does not handle all requests, the user is initially directed to the proxy through another resource at the user's institution. In this case, absolute URLs in documents returned from the third-party through the proxy must be rewritten to point back to the proxy; and relative URLs must be rewritten so that the proxy recognizes them as requests to forward. If the proxy handles all traffic, it may become a bottleneck.
There is no mechanism in this method for the third-party service provider to retrieve user attributes when required. We considered this a big disadvantage. And this method encourages service providers to allow access based on a fixed password, the institutional credential. While that seems to be the state of the art today, we prefer not to encourage its continued use. Fixed institutional passwords should be carefully guarded because they enable transactions to be performed on behalf of an entire institution; but the prevalent procedures for establishing and maintaining them with service providers is subject to many kinds of compromise.
Since many institutions are moving towards the use of proxies as gateways to third-party services, this model may be a natural first step for them. However, we continued our investigation in search of a model better suited to our needs.
3.4 Cross-Organizational Access Management via Cryptographic Module
This model is still in development but appears to have the best long-term promise. As of the Spring of 1998, both the Netscape and the Microsoft Explorer browsers are able to incorporate cryptographic plug-in modules.
We are now developing a PKCS#11 module [RSA1] for the Netscape browser in Unix. Once this has been tested, we will look into moving it to other platforms and browsers.
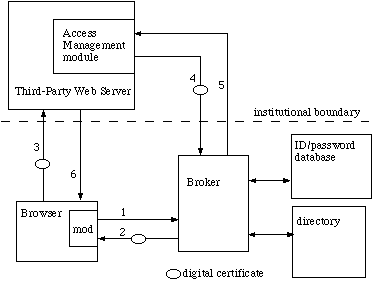
Figure 4. Access Management with CertificateBefore any services are requested, the user must activate the browser module. This is currently done in Netscape by choosing the module and selecting "login." The user will be prompted for a "PIN" and responds with an id, password and an identification of the local institutional access management broker.
- The browser module, acting over a secure channel, contacts the broker and presents the user's credentials (id and password) and the preferred processing rule for the broker.
- The broker validates the user, as described above, and then obtains or generates a temporary private key and a temporary digital certificate, which are returned back to the module. The certificate contains the address of the broker and an opaque identifier of the user, again temporary, and known only to the broker. This new certificate is then available within the browser for subsequent use with third-party services. In current browsers, the user must then explicitly select it, indicating a desire to be "known" by this identity.
- Again, we have provided a server plug-in which handles the broker communication at remote, third-party providers. Third-party service providers use this server plug-in and use SSL (secure channel). The user's new certificate is sent to the third-party server during initialization of the SSL channel. The plug-in will use the certificate as the user's credentials rather than id and password.
- Because the certificate contains the address of the broker, the third-party server can establish contact with that broker, send it the user's certificate, the class of service it plans to provide, and any further user attributes to be retrieved back for business purposes.
- The broker can perform authentications as above and return authentication and any requested (and permitted) attributes back to the third-party.
- The service is delivered to the user.
This model appears the most secure and most flexible of any. Because the certificates are temporary, we avoid several administrative problems usually associated with certificates: we do not need to establish a complex distribution system or invent special methods to accommodate people using more than one workstation; we do not need long-term revocation lists; and we do not need escrow and key recovery infrastructures. Because a single certificate is installed by the browser module for all transactions, users do not require extensive training in certificate handling (installation, update, etc.) although they do need to be educated about the use of the browser module itself.
We continue to refine the protocol and the requirements for third-parties.
We also need to further refine our definition of "temporary". When a certificate expires, the user must explicitly obtain a new one. If certificates expire very quickly, it can be inconvenient for users and may also create a significant computational strain for the system which is generating them. If they expire too slowly, they are no longer useful on public or shared workstations and, ultimately, lose the benefits described above.
4. Related Issues and Future Work
Much work is being done in this area as other large research institutions face similar problems. Several web access management systems leverage pre-existing Kerberos ID infrastructures, either by using a callback to the user's workstation, invoked by the web server, as Stanford's WebAuth does [STANFORD1] or by using a browser plug-in, invoked by a document with a special MIME type, as in CMU's Minotaur [CMU1]. Others, such as North Carolina State's Web Realm Authentication Protocol ("WRAP") [NC1], use HTTP's basic authentication to retrieve a user id and password and then, by a combination of setting "cookies" and redirecting from one server to another, enable the user to authenticate with the user's institutional "Web Authorization Server" and then return to the original resource.
None of these approaches quite met our needs; they were designed to solve somewhat different problems. None was explicitly designed for general inter-organizational access management. WRAP permits a limited form of inter-organizational management, but without the ability to use arbitrary user attributes (it employs only the user's name and institutional affiliation). We wanted to enable any subset of a user community to access a service. Additionally, we were reluctant to rely on cookies as part of our access management mechanism: cookies were designed explicitly for user tracking and so may not be shared across Internet DNS domains, which limits their utility for our purposes, and their use in user tracking has raised legitimate privacy concerns [EPIC1].
Several areas remain to be explored as we continue work on this project.
While our use of digital certificates is temporary for end users, the broker and the web servers do require a public key infrastructure to manage their own certificates and their associated keys. A first step might be the establishment of a trusted directory from which broker certificates could be retrieved and where revocation lists might be posted. Real-time modifications of entries in this directory must be supported while maintaining data integrity.
We need to think about ways to link disjoint ID and directory systems that operate within the same institution, for purposes of attribute retrieval. Attributes must be associated with the same user entity no matter which of several different disjoint ID systems may have been used to validate the user's credentials. Attributes must be marked by their source directory.
While attribute names and values may differ from one institution to another (and even within institutions), we should standardize the names of user attributes that might be requested from a broker. X.500 may be a useful starting point for this [X.500]. Translating standard attribute names into the varying names used within an institution is yet another task. We might also consider standardizing the format of service names that are reported to brokers, depending on the type of service provided.
A user's attributes may be distributed across more than one institution, i.e., the user is a member of more than one community. In this case, one organization's broker may need to consult another broker, at another organization, to retrieve certain user attributes.
Generally, we see a need for a better understanding of user identity and communities in the networked environment. Membership in networked communities is increasingly important, and many areas of research, including legal and public policy, play as critical a role as the technology work we have described here.
References
[ALA94] OITP, American Library Association. Principles for the Development of the National Information Infrastructure. June 29, 1994. http://www.ala.org/oitp/principles.html
[Arms98] W. Arms. Implementing Policies for Access Management. D-Lib Magazine. February 1998. http://www.dlib.org/dlib/february98/arms/02arms.html
[CMU1] Computing Services, Carnegie Mellon University. Project Minotaur. http://andrew2.andrew.cmu.edu/minotaur/
[Col92] Columbia University - Presbyterian Hospital Committee on Data Security. Network User Authorization and Authorization Architecture. June 16, 1992. ftp://ftp.columbia.edu/cpsec/nua.ps
[Col97] Student Services Office, Columbia University. "Appendix A: Policy on Access to Student Records under the Federal Family Educational Rights and Privacy Act (FERPA) of 1974." Facets -- Facts About Columbia Essential to Students. 1997. http://www.columbia.edu/cu/facets/50.html
[EPIC1] Electronic Privacy Information Center. The Cookies Page. http://www.epic.org/privacy/internet/cookies/
[Lynch98] C. Lynch, ed. A White Paper on Authentication and Access Management Issues in Cross-organizational Use of Networked Information Resources. Coalition for Networked Information. Revised Discussion Draft of April 14, 1998. http://www.cni.org/projects/authentication/authentication-wp.html
[NC1] Web Services, NC State University. Welcome 2 WRAP. http://www.ncsu.edu/wrap/
[RSA1] RSA Laboratories. PKCS-11: Cryptographic Token Interface Standard. April 15, 1997. http://www.rsa.com/rsalabs/pubs/PKCS/html/pkcs-11.html
[STANFORD1] Stanford University Web Authentication. http://www.stanford.edu/group/dcg/webauth
[X.500] ISO/IEC 9594-1/ITU-T Recommendation X.500. "Information Techonology - Open Systems Interconnection -- The Directory: Overview of Concepts, Models and Services". 1997 edition.
![]()