|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Ioannis Papadakis Konstantinos Kyprianos and Rosa Mavropodi Michalis Stefanidakis |
![]()
AbstractIn this article, an effort is made to take advantage of the inherent semantic wealth existing within Library of Congress Subject Headings (LCSHs) in order to provide more efficient subject-based information retrieval in digital libraries. To formally express such wealth, an ontology schema is presented that is capable of modeling the semantics of LCSHs into adequate ontologies. Finally, in order to show the way towards exploiting such ontologies in favor of the development of more effective subject-based information retrieval in digital libraries, a prototype system is presented. The system contains an ontology modeling the LCSHs that are employed within a digital library of theses and dissertations. Serving as a proof of concept, the prototype describes a system capable of making the expressiveness of the underlying ontology readily available to end users while at the same time retaining simplicity and ease-of-use. 1 IntroductionAs compared to traditional libraries, digital libraries are available through the web to numerous users who, quite often, have only vague notions about what the object of their search is (Guarino, [12]). Many times, an informal description of the subject of their information seeking goal is the only input they can provide to the digital library. Consequently, keeping in mind that physical access to the underlying digital collection is not an option, efficient subject-based information retrieval is crucial for a successful digital library. The goal of this article is to semantically exploit the explicit and implicit relations between Library of Congress Subject Headings (LCSHs)1 in order to provide more effective subject-based, information retrieval within digital libraries. Explicit relations refer to the well-known 'syndetic structure' (i.e., Broader Term - BT, Narrower Term - NT, Related Term -RT) between LCSHs, while implicit relations refer to LCSHs that share common subdivisions. LCSHs that are related to each other through their subdivisions define the 'extended syndetic structure'. In this context, it is argued that current trends in the evolution of the semantic web such as ontologies (Web Ontology Language - Description Logics - OWL-DL2) provide the necessary infrastructure to develop such systems. A proof of concept is also provided in this article in order to demonstrate the applicability of the proposed research to current and yet-to-come subject-based, information retrieval systems within digital libraries. The rest of this article is structured as follows: The next section describes the semantic richness of information that is encapsulated within LCSHs. Then, current trends in LCSH-based information retrieval within digital libraries are presented. In addition, an effort is made to explain why subject-based searching does not seem to be a popular way of querying a digital library. The role of thesauri in subject-based information retrieval is explored in Section 4. Section 5 presents the proposed approach. Initially, a definition of the extended syndetic structure between LCSHs is provided. Then, an ontology schema is proposed, capable of modeling the extended syndetic structure. As a proof of concept, the section concludes by demonstrating and accordingly evaluating a system capable of exploiting the provided ontology in the context of a subject-based information retrieval system. Finally, this article draws conclusions concerning the proposed work and points to directions for future work. 2 The role of LCSHs in subject-based information retrievalSubject-based information retrieval in the context of digital libraries requires that an adequate number of subject descriptors of sufficient quality should be applied to the underlying information resources. Quantity, together with quality of subject-based indexing, can have an enormous influence on the quality and power of results at the point of actual searching. After all, that which is not indexed cannot be retrieved [2]. With this in mind, traditional libraries usually employ LCSHs as a controlled vocabulary that is capable of providing meaningful descriptors for the subjects of their underlying collections. Despite the debate (see Calhoun [8] and Mann [16]) concerning the 'cost-benefit analysis' of creating LCSHs for subject-based indexing of information resources, as stated in Schwartz [15], 'the application of LCSHs by catalogers has not changed substantially and even some newly-created digital libraries use LCSHs'. By taking a closer look at LCSHs, a number of significant advantages can be seen that potentially could explain the wide dissemination of LCSHs within OPACs and digital libraries. Thus, as stated in Dean [10], LCSHs constitute an extensively employed (thus promoting interoperability between library and/or digital library systems), rich vocabulary that covers all subject areas and enjoys strong institutional support from the Library of Congress. Moreover, LCSHs impose synonym and homograph control, as well as have a long and well-documented history. The semantic quality of LCSHs can be further witnessed when taking into consideration the theory that underpins their application to information resources. Thus, as stated in Bates [2], proper employment of LCSHs dictates that they are not meant to be single-concept terms. On the contrary, the resulting subject heading string (being comprised of the main heading plus its subdivisions) is meant to describe all by itself the whole information resource. Consequently, the expressivity of the resulting subject heading string is generally quite broad, often much broader than individual concept index terms. Instead of a few tenths of keywords per information resource used with concept indexing languages, just one or two subject headings are typically applied to an information resource. The types of subdivisions allowed are strictly controlled, as is their order of appearance in the subject heading. 3 Current trends in LCSH-based information retrieval within digital librariesThe semantic richness encapsulated within LCSHs together with their wide dissemination could lead to the conclusion that end users prefer searching by subject within digital libraries. This is, however, far from reality. Subject-based searching does not seem to be a popular way of querying a digital library. This could be attributed to a number of reasons. According to common practice in subject-based information retrieval within digital libraries, searchers cherry-pick words and phrases that are semantically closer to their information needs and then combine them with Boolean logic, hoping to have a successful match within the underlying index. However, such a scenario can only lead to a successful result if the terminology of the searcher matches the terminology of the underlying subject headings [5]. Moreover, even in the case where a keyword matches part of the underlying subject heading string, the information retrieval system does not take advantage of the inherent ability of LCSHs to shift from one subject heading to another, based on their defined semantic relations. The end user's only option, then, is to browse through an alphabetical index prior to initiating the information retrieval process. However, this type of searching diminishes the semantic expressiveness of the underlying LCSHs. To make things worse, linguistic problems further affect the quality of the information retrieval process. More specifically, search queries expressed as consecutive terms suffer from the possible polysemy and/or synonymy of the words that constitute the search query. Polysemy occurs when one word has more than one meaning, and synonymy occurs when two or more words share the same meaning [9]. Such problems derive from the overall system design, not the employed vocabulary: LCSHs are usually comprised of several terms that describe a certain semantic context. Consequently, when it comes to assessing the effectiveness of employing LCSHs within subject-based information retrieval services, opinions are rather discouraging [8]. The most important cause of this effect could be attributed to the fact that, since LCSHs were designed for a different environment, they have not worked well together with the Boolean searching functionality provided by the majority of current keyword-based information retrieval systems in OPACs and/or digital libraries. 4 Thesauri-based information retrievalIn order to avoid some of the aforementioned drawbacks concerning subject-based information retrieval, thesauri have been employed ([1], [11]). When used during retrieval and searching, thesauri are useful in bridging the gap that exists between the metadata provided by the indexer and the concepts presented by a searcher [3]. Moreover, thesauri can be employed to promote guided and/or faceted navigation by exploiting the semantic structure between their underlying terms [4]. Such navigation ultimately results in query construction for queries addressed to the underlying search engine. Despite their inherent drawbacks (addressed in Bechhofer and Goble [4]), thesauri have proved to be quite effective for information discovery using print tools. However, due to the fact that their semantic structure is less well deployed for users in online settings, the impact of thesauri in subject-based information retrieval is less than expected in those settings. Schwartz [13] provides an extensive, annotated overview of recent research in thesauri-based information retrieval. Following this research, it could be stated that ontology-based systems seem capable of addressing many of the problems concerning the modeling of the semantic structure within thesauri, thus leading to the development of more effective subject-based information retrieval systems. Thinking along this line, a thesauri-related system that could potentially be applied to serve LCSHs is ONKI-SKOS [6]. The ONKI-SKOS server provides a uniform way of accessing thesauri represented as Simple Knowledge Organization System - SKOS3 vocabularies. As far as the user interface is concerned, the ONKI-SKOS server provides an auto-suggest function that acts as an entry point for the entire thesauri-based information retrieval process. Then, users are provided with a hyperlink-based interface to traverse the thesaurus, which is encoded in OWL format. ONKI-SKOS can be used to browse, search and visualize any vocabulary that conforms to the SKOS specification. ONKI-SKOS thesauri are capable of representing basic SKOS relations between concepts such as hierarchical relations and synonyms. 5 Proposed approachIn this article, an effort is made to take advantage of the inherent semantic expressiveness existing within LCSHs, in order to provide more efficient subject-based information retrieval in digital libraries. The first step towards this goal is to extend the syndetic structure (i.e., BT/NT/RT) running through LCSHs, with subdivision-based relations. As will be demonstrated later in this article, the provision of greater connectivity between LCSHs results in the emergence of more effective, subject-based information retrieval modules within digital libraries. After extending the syndetic structure, the derived extended structure is mapped to an accordingly designed ontology schema. Such schema can be applied to any digital library containing subject descriptors according to the LCSH guidelines. Finally, in order to exploit the semantic richness of the underlying ontology, an adequate user interface is presented. The interface enables users to familiarize themselves with the terminology employed within LCSHs and guides them to select the subject that best matches their information needs. The guided navigation is based on the relations between subject headings that were derived from the aforementioned extended syndetic structure. 5.1 Extending the syndetic structure between LCSHs with subdivision-based relationsThe syndetic structure is comprised of three relations, namely 'broader', 'narrower' (i.e., hierarchical relations) and 'related' (i.e., associative relation) [18]. Apart from the syndetic structure, LCSHs are indirectly associated through their (possibly) common subdivisions. There are four types of subdivisions according to the LCSH guidelines4; topical subdivisions, form subdivisions, geographical subdivisions, and chronological subdivisions.
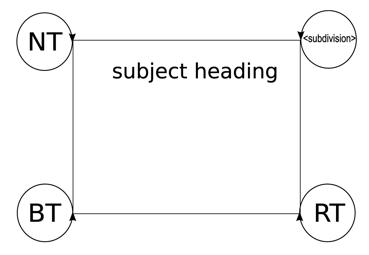
The LCSH guidelines impose certain restrictions concerning the order of subdivisions within a subject heading. More specifically, such order normally conforms to the pattern 'topic-place-time-form': [main heading] -- [topical subdivision] -- [geographical subdivision] The above pattern can be altered, particularly with regard to the position of the geographical subdivision, which may appear in any position after the main heading. One of the goals of this article is to exploit these four types of subdivisions in order to semantically extend the syndetic structure of LCSHs. Subdivision-based relations between subject headings are not exploited by modern, subject-based information retrieval systems within digital libraries, thus eliminating the possibility for providing searching capabilities based on common subdivisions between subject headings.5.2 Modeling relations between LCSHs in an ontology's schemaIn order to formally express the aforementioned extended syndetic structure of LCSHs, ontologies in OWL-DL could be employed. OWL-DL is based on Description Logics [19], which have attractive and well-understood computational expressiveness. OWL is considered one of the fundamental technologies underpinning the semantic web. Figure 1 illustrates the schema of the proposed ontology.
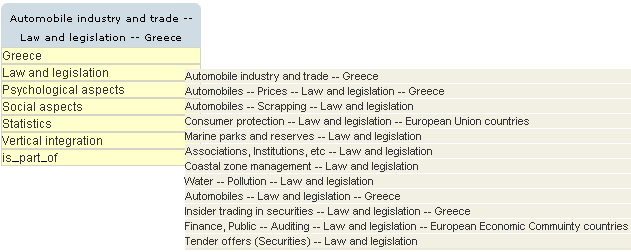
The above schema generates ontologies that contain a class hierarchy modeling subject headings as classes. According to the syndetic structure, a subject heading can be associated with another one through the employment of broader (BT), narrower (NT) or related (RT) associations. In particular, 'broader' and 'narrower' not always but quite often refer to the hierarchical structure of the subject headings, whereas 'related' brings together subject headings that share a similar concept [4]. Thus, the hierarchical structure of subject headings maps directly to the ontology's class hierarchy. The <subdivision> set of relations refers to relations that model the extended syndetic structure. Subdivisions are modeled as symmetric object properties between classes that correspond to subject headings related to each other through their subdivisions. For example, the subject headings:
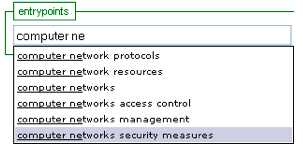
1. Automobile industry and trade - - Law and Legislation - - Greece share the subdivisions 'Law and Legislation' and 'Greece'. Thus, the ontology connects their corresponding classes with two additional object properties, namely 'Law and Legislation' and 'Greece'. 5.3 From theory to practice: semantic, LSCH-based information retrievalWhen serialized, stored and indexed in an efficient way, the proposed ontology can serve as the basis for the development of efficient, semantically rich information retrieval modules within digital libraries. Such modules would replace the traditional keyword-based indexing back-ends employed by many information retrieval modules within current digital library systems. For the ontology to be effective, a user interface capable of exposing the aforementioned semantic expressiveness is necessary. Current user interfaces in digital libraries for subject-based information retrieval fail to fulfill this requirement. They usually provide a search box that applies pattern-matching of user-supplied keywords against an index of subject strings. In the case of LCSH-based subject strings, all the benefits of controlling and standardizing such strings are lost, and searchers are left to rely on statistical algorithms in order to satisfy their information needs. Consequently, there is a need for a user interface capable of efficiently exposing the expressiveness of the LCSH-based strings to the end user. As stated earlier in this article, a fundamental requirement for such a user interface is the ability to bridge the gap between users' information needs and the terminology employed to develop the underlying LCSH-based subject strings. Moreover, the provided functionality should find its way towards the user interface while retaining basic usability features [14] that make the entire information retrieval system appealing to its users. After all, as stated in Bates [2], the ultimate performance measure will always be how people actually use a system, not how one expects them to use it. With this in mind, a user interface is presented that is capable of making the expressiveness of the underlying ontology readily available to the end user while retaining simplicity and ease-of-use. The proposed user interface builds upon previous work [7] on ontology visualization by providing an extension to the connectivity of subject headings as expressed through their subdivisions. It is comprised of an auto-suggest search box where the user is prompted to type the first letters of the words that best describe his/her information needs. The widget returns a list of subject headings that contain the string provided by the user. Then, the user can select the subject heading that best matches his/her information needs (see Figure 2).
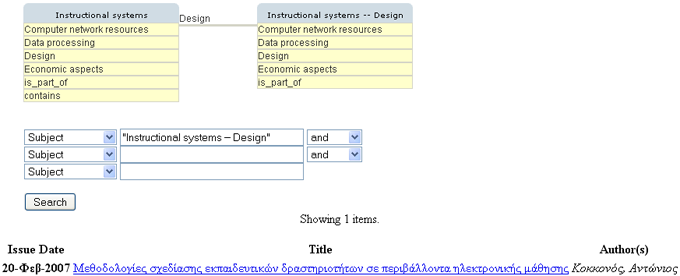
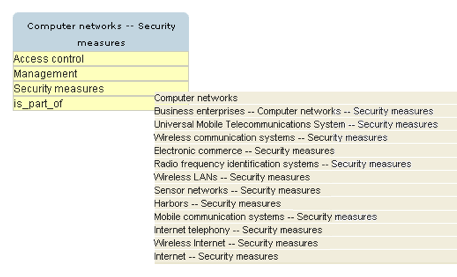
This way, users perform an initial pattern-matching search to the LCSH-based subject headings employed to describe the subject of the underlying information resources. However, the ontology could contain subject headings that are semantically close to the information needs of the user without containing the specific string. As stated previously in this article, such proximity to the user's information needs cannot be implemented by current, automated pattern-matching systems. Thus, in order to help users find such headings, the proposed approach provides a browsing process that takes advantage of the extended syndetic structure of the underlying ontology, as defined previously in this article. More specifically, upon selecting a subject heading through the auto-suggest search box, a box representing the subject heading is sketched. The box contains the title of the heading, followed by the possible relations it may have with other headings within the ontology, as illustrated in Figure 3a. By clicking on a relation, the user is presented a list of subject headings that are associated with the sketched one through the selected relation (see Figure 3a). Then, by clicking on one of the subject headings, another box is sketched next to the first one. The two boxes are connected with a labeled line containing the description of the selected relation (see Figure 3b). Such a process can be repeated until the user locates a subject heading that satisfies his/her information needs.
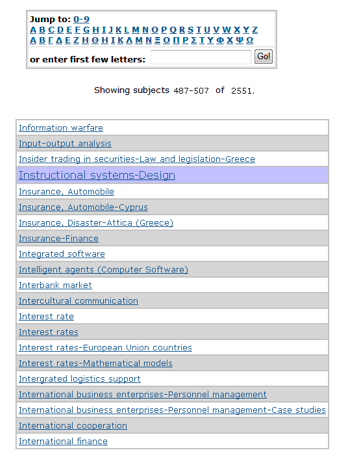
At the end of the process, the resulting subject heading can be addressed 'as-is' to the underlying search engine in order to retrieve information resources that are tagged with the specific heading. This final stage involves pattern-matching with a traditional subject index containing LCSHs. However, pattern-matching is not applied between user-supplied strings and strings contained within the system, as is the case with current information retrieval modules. According to the proposed approach, pattern matching is applied between strings suggested by the system (and selected by the user) and strings contained within the system. This way, end users get acquainted with the specific terminology employed to describe the subjects of the underlying resources and accordingly address targeted queries to the information retrieval system. To sum up, the proposed approach provides a subject-based information retrieval service building upon subjects that comply with the LCSH guidelines. It is comprised of a back- and a front-end that are seamlessly integrated to a unified information retrieval system. Such a system could be employed by numerous LCSH-based digital libraries that wish to provide subject-based information retrieval to their users. With trivial modifications to the design of the underlying ontology, the proposed methodology could be applied to virtually any kind of thesauri employed to model the subjects of the information resources within digital libraries, thus providing a universal tool for user-centered, interactive, subject-based information retrieval. 6 Case studyThe proposed approach has been applied to the digital library of theses and dissertations at the University of Piraeus in Greece. More specifically, a subject-based information retrieval module based on the findings of this research has been developed5 and integrated to the corresponding DSpace-based digital library6. The module utilizes an ontology modeling about 1,000 LCSHs existing within the digital library. According to the proposed approach, the syndetic structure is expressed through the definition of three relations (i.e., 'contains', 'is_part_of' and 'seeAlso'). In order to express the extended syndetic structure, a number of relations were defined, corresponding to the subdivisions of each and every LCSH within the digital library. Thus, subjects sharing a common subdivision were connected to each other through an accordingly defined relation. In the next section, a comparative evaluation of the proposed approach is presented, against the traditional subject-based searching process provided by the digital library of theses and dissertations at the University of Piraeus. 6.1 Comparative evaluationAccording to current practice, the user interacts with a form-based interface where he/she is prompted to select the subject the user has in mind from an alphabetical index or type the corresponding first letters in a search textbox. Then, the underlying system tries to match the user's input with subject strings that have the same prefix as the provided input. In case of a successful match, the alphabetical index scrolls to the subject that was successfully matched (see Figure 4a). Finally, the user may click on a subject within the index in order to retrieve information assets that are assigned to that subject (see Figure 4b). The only way a user can browse through relevant subjects is to click on an information asset and then click on another subject that is assigned to that asset.
Thus, browsing through information assets by subject is a rather tedious process that does not take advantage of the (extended) syndetic structure of the underlying LCSH-based subjects. In order to evaluate the search effectiveness of the proposed approach, three subject-based search scenarios are presented and assessed. Each scenario is applied both to the traditional system and to the proposed subject-based information retrieval module. Scenario 1: The user needs to find information assets about 'instructional systems'. According to the traditional approach, the user locates the subject 'Instructional systems - design' (see Figure 5a).
By clicking on the subject, there is only one information asset available (see Figure 5b).
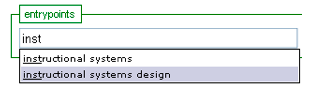
On the other hand, according to the proposed approach, the user types the first letters of the subject in mind into the auto-suggest text box (see Figure 6a).
Then, the user selects 'instructional systems' and by clicking on the relation 'Design' the user is presented the subject 'Instructional systems - design' with the corresponding result, which is obviously the same as it was with the traditional approach (see Figure 6b).
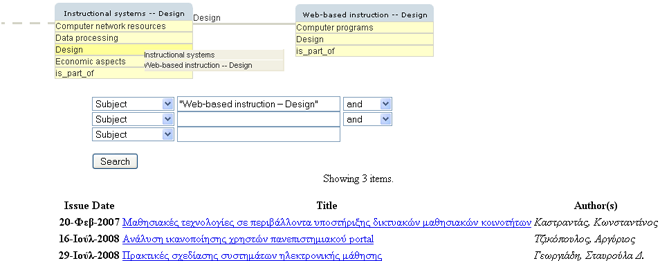
So far, the two approaches exhibit almost the same behavior, and consequently the user is presented the same results. However, the proposed approach provides more interactions, as further described. By clicking on a subdivision (represented as a yellow label beneath the title of the box), the user is presented the subjects that share the same subdivision with the current subject (i.e., 'Instructional systems - design'). If the user finds a suitable subject, he/she can select that subject and observe the corresponding information assets. In the described scenario, by clicking on 'Design', the user is presented the subject 'Web-based instruction - Design', which retrieves three information assets (see Figure 6c).
Scenario 2: The user needs to find information assets about 'Security measures in Computer networks'. According to the traditional approach, the user is presented the subject 'Computer networks -security measures' (see Figure 7a).
By clicking on the subject, the user sees that there are three information assets available (see Figure 7b).
On the other hand, according to the proposed approach, the user types the first letters of the subject in mind to the auto-suggest text box (see Figure 8a).
Then, the user selects 'Computer networks Security measures' and he/she is presented with a box corresponding to the selected subject together with the three information assets that were also provided by the traditional approach. Further interaction is provided by clicking on the 'security measures' subdivision (see Figure 8b).
Thus, if the user finds a suitable subject, he/she can select that subject and observe the corresponding information assets. Scenario 3: The user needs to find information assets about the general subject 'Accounting'. According to the traditional approach, the user is presented with three subjects related to 'Accounting', namely: 'Accounting-data processing', 'Accounting-Moral and ethical aspects' and 'Accounting-standards' (see Figure 9).
By clicking on each subject, the user will come up with a total of three relevant information assets. On the other hand, according to the proposed approach, upon selecting the subject 'Accounting', the user can discover various subjects that specialize (according to the corresponding LCSH syndetic structure) the original term 'Accounting', by clicking on the 'contains' relation (see Figure 10).
Thus, if the user finds a suitable subject, he/she can select that subject and observe the corresponding information assets. 7 Conclusions, discussion, future workIn this article, an effort is made to exploit the explicit and implicit semantic expressiveness of subject headings conforming to the LCSH guidelines, in favor of more efficient subject-based, information retrieval modules within digital libraries. It is the authors' belief that the wide employment of LCSHs within several digital libraries, worldwide, constitutes the findings of the conducted research applicable to a number of institutions maintaining digital library systems. Moreover, with trivial modifications to the design of the underlying ontology, the proposed methodology could be applied to virtually any kind of thesauri employed to model the subjects of information resources within digital libraries, thus providing a universal tool for user-centered, interactive, subject-based information retrieval. In order to provide a proof of concept for the proposed approach, a prototype system has been developed that is capable of delivering subject-based information retrieval functionality to the end users of a digital library employing LCSHs. Based on most recent trends in web development, the prototype promotes serendipitous or casual discovery of 'interesting' information connected to the interactive navigation process. During the process, users enhance their cognitive learning, since they are able to discover which subject headings correspond to their information needs. Future work is oriented towards the exploration of other semantically rich information structures produced by librarians. The ultimate goal of this research is to contribute to the development of next-generation digital libraries capable of exploiting the wealth of knowledge accumulated within traditional libraries. Notes1. LCSHs. Available at: <http://authorities.loc.gov>. 2. OWL Web Ontology Language. Available at: <http://www.w3.org/TR/owl-ref/>. 3. SKOS, available at: <http://www.w3.org/2004/02/skos>. 4. Library of Congress Subject Headings, 30th edition (2007). 5. Available online at: <http://neel.cs.unipi.gr:8087/entry/index.html>. 6. Available online at: <http://www.lib.unipi.gr/dspace>. References1. Asghar, A. Revie, C., Ghowdhury, G. Thesaurus-enhanced search interfaces. Journal of information Science, 28(2), pp. 111-122. (2002), <doi:10.1177/016555150202800203>. 2. Bates, M. The cascade of interactions in the digital library interface. Information processing and management, 38, pp. 381-400. (2002), <doi:10.1016/S0306-4573(01)00041-3>. 3. Bates, M. Indexing and access for digital libraries and the internet: human database and domain factors. Journal of the American Society for Information Science, 49(13), pp. 1186-1205. (1998). <doi:10.1002/(SICI)1097-4571(1998110)49:13<1185::AID-ASI6>3.3.CO;2-M>. 4. Bechhofer, S., Goble, C. Thesaurus construction through knowledge representation. Data & Knowledge Engineering, 37, pp. 25-45. (2001), < doi:10.1016/S0169-023X(00)00052-5>. 5. Bennett, D. E. Immaculate Catalogues, Indexes and Monsters Too.... Ariadne, 49, (October 2006). Available at: <http://www.ariadne.ac.uk/issue49/cig-2006-rpt/>. 6. Tuominen, J., Frosterus, M., Viljanen, K.,Hyvonen, E. ONKI-SKOS - Publishing and Utilizing Thesauri in the Semantic Web. AI and Machine consciousness - Proceedings of the 13th Finnish Artificial Intelligence Conference STeP 2008. Finland: Semantic Computing Research Group (SeCo). (2008). 7. Papadakis, I., Stefanidakis, M., Tzali, A. Semantic Navigation in a Library Catalogue, Proceedings of Metadata and Semantics Research Conference - MTSR '07, pp. 130-134, Corfu, (2007). 8. Calhoun, K. The Changing Nature of the Catalog and its Integration with Other Discovery Tools. Ithaca, NY: Cornell University Library. (2006), <http://www.loc.gov/catdir/calhoun-report-final.pdf>. 9. Miller, G. A. WordNet: a lexical database for English. Communications of the ACM, 38(11), pp. 39-41. (1995), <doi:10.1145/219717.219748>. 10. Dean, R. J. FAST: Development of Simplified Headings for Metadata. International Conference on Authority Control. Florence, Italy: University of Florence. (2003). Available at: <http://www.unifi.it/universita/biblioteche/ac/relazioni/dean_eng.pdf>. 11. Gordon, A. S., Domeshek, E. A. Déjà vu: A Knowledge-Rich Interface for Retrieval in Digital Libraries. Proceedings of the 1998 International Conference on Intelligent User Interfaces, pp. 127-134. San Francisco, California: ACM Press. (1998), <doi:10.1145/268389.268412>. 12. Guarino, N. 1998. Some Ontological Principles for Designing Upper Level Lexical Resources. Proceedings of LREC-98. 13. Schwartz, C. Thesauri and Facets and Tags, Oh My! A Look at Three Decades in Subject Analysis. Library Trends, 56(4), pp. 830-839. (2008). 14. Krug, S. Don't Make Me Think!: a Common Sense Approach to Web Usability. Indianapolis, USA: New Riders. (2000). 15. Schatz, B. R., Johnson, E. H., Cochrane, P. A., Chen, H. Interactive Term Suggestion for Users of Digital Libraries: Using Subject Thesauri and Co-occurrence Lists for Information Retrieval. Proceedings of the first ACM International Conference on Digital Libraries, pp. 126-133. United States: ACM Press. (1996). 16. Mann T. The changing nature of the catalog and its integration with other discovery tools. Final report. March 17, 2006. Prepared for the Library of Congress by Karen Calhoun: A. Critical Review. April 3, 2006. Washington, DC: Library of Congress. Available at: <http://www.guild2910.org/AFSCMECalhounReviewREV.pdf (2006). 17. Markey, K. The online library catalog: Paradise lost or paradise regained? D-Lib Magazine, 13(1/2). Available at: <doi:10.1045/january2007-markey> (2007). 18. Marshall, L. Specific and generic subject headings: Increasing subject access to library materials. Cataloging & Classification Quarterly, 36(2), pp. 59-87. (2003), <doi:10.1300/J104v36n02_07>. 19. Baader, F., Calvanese, D. McGuinness, D. Nardi, D., Patel-Schneider, P. The Description Logic Handbook: Theory, Implementation and Applications. Second edition, CUP, ISBN-13: 9780521876254, (2007). Copyright © 2009 Ioannis Papadakis, Konstantinos Kyprianos, Michalis Stefanidakis and Rosa Mavropodi |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/september2009-papadakis
|