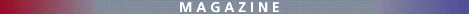
Lawrence D. Bergman, Vittorio Castelli, and Chung-Sheng
Li
Networked Data Systems Department
IBM T. J. Watson Research Center
Yorktown Heights, New York
{bergman,vittorio,csli}@watson.ibm.com

Over the last forty years, satellite imagery has been used for a wide variety of applications. Automatically locating and recognizing objects such as missiles, tanks, and ships from images taken by spy satellites and reconnaissance aircraft dates back to the late 50's and early 60's. Civilian and scientific use of the satellites began to emerge during late 60's and early 70's in a variety of space and earth science programs. Recently, there has been a significant increase in application areas for satellite imagery. For example, Landsat images have been used in global change studies, such as the analysis of deforestation in the Amazon River Basin over the past three decades. Other satellites (such as ERS-1 and Radarsat) equipped with Synthetic Aperture Radar (SAR) instruments have been used to determine the ice coverage of the Arctic and Antarctic Circles to monitor global warming. Weather satellites, such as Geostationary Operational Environmental Satellites (GOES), have been tracking the movement of hurricanes and storms. In the coming months, several new satellites with much better spatial and spectral resolution will be launched into orbit. Their potential applications in the area of agriculture, local government, environmental monitoring, utilities and transportation, disaster management and real estate are almost unlimited.
As the volume of satellite imagery continues to grow exponentially, the efficient management of large collections of such data is becoming a serious challenge. In particular, the successful deployment of automated repositories depends crucially on efficient indexing and retrieval of the desired portion of an image using a simultaneous combination of low-level image features, semantics, and metadata. This is exemplified in the following emergency management scenario, which involves satellite imagery. Upon detection of a forest fire, (either through satellite imagery or human observation), a fire manager from the forest service identifies bodies of waters in the proximity of the fire, from which helicopters or planes can draw water to contain the flames. The same manager assesses the threat to neighboring towns, power lines, and other natural or artificial structures, using a fire model that relies on the most recent weather information, fuel status (that is, type and condition of the forest, soil moisture etc.), and terrain data (usually in the form of digital elevation models). The fire manager then chooses the appropriate course of action. Here, efficient indexing mechanisms are required to locate fires, water, escape routes for field personnel, and values at risk (such as houses) from satellite images, as well as additional information such as the fuel types, the fuel status and the soil moisture.
In another scenario, a global change study analyzes the sea ice of the Arctic region. Different types of sea ice are identified by means of texture features extracted from SAR images. Here, efficient feature-space indexing is used to search through 10 years worth of imagery to analyze the changes in the distribution of particular classes of sea ice.
Other forms of scientific data, including time series, medical images (such as MRI, CT, and PET), and seismic data, have archiving and search requirements similar to those for satellite imagery.
In this paper, we describe an architecture and initial implementation of a progressive framework for storage and retrieval of image and video data from a collection of heterogeneous archives. The extensibility of this framework is achieved by allowing search constraints to be specified at one or more abstraction levels. The scalability of the proposed architecture is achieved by adopting a progressive framework, in which a hierarchical scheme is used to decorrelate and reorganize the information contained in the images at all of the abstraction levels. Consequently, the search operators can be efficiently applied on a small portions of the data and use to progressively refine the search results. This technique achieves a significant speedup as compared to more conventional implementations.
Several image and video database systems supporting content-based queries have been recently developed. These systems allow image or video indexing through the use of low-level image features such as shape, color histogram, and texture. Prominent examples for photographic images include the MIT PhotoBook [1], IBM QBIC [23], VisualSeek and SaFe from Columbia University [2], and the Multimedia Datablade from Infomix/Virage [3 ]. Content-based search techniques have also been applied to medical images [4, 21], art work[20] and video clips [15, 5, 6, 7, 17]. Despite the tremendous progress in this area, there still exist a number of outstanding issues. In particular, we identify the need for: (1) A replicable data model which is applicable to both photographic images and domain specific images such as satellite images, medical images, stock sequence, and seismic data. (2) An extensible framework which allows content-based queries using pre-extracted low-level features as well as user-defined features and semantics; (3) A storage and retrieval system that is scalable with both the amount of data and the number of users; (4) A query interface which is both intuitive and expressive to specify constraints for multimedia objects. The most challenging task is to establish a framework which is both extensible and scalable. Existing systems can be scalable if the retrieval is based only on the pre-extracted features. However, these approaches do not usefully extend across different image types and domains.
Content-based retrieval of image and video databases usually involves comparing a query object with the objects stored in the data repository. The search is usually based on similarity rather than on exact match, and the retrieved results are then ranked according to a similarity index. Objects can be extracted from an image at ingestion time, composed at query time, or retrieved using a combination of the above strategies. In most cases, compromises have to be made between generality and efficiency. Objects extracted at image ingestion time can be indexed much more efficiently. However, it is usually very difficult to anticipate all the types of objects in which a user might be, and thus systems allowing only search based on pre-extracted objects are severely limiting. On the other hand, recognizing objects entirely at query time will limit the scalability of a system, due to the high expense of such computing.
To alleviate both problems, we propose a object-oriented framework which allows flexible composition of queries relying on both types of objects. Within this frameworks, objects can be specified at multiple abstraction levels (Figure 1), namely, the raw data level, the feature level, and the semantic level:
We distinguish between simple (or atomic) objects and composite objects. The definition of a simple object reflects the three levels of abstraction defined above: a simple object is a connected region
A composite object consists of a set of simple objects and a set of
spatial or temporal constraints. For example, given the simple objects ![]() ,
, ![]() , and
, and ![]() ,
then the composite object
,
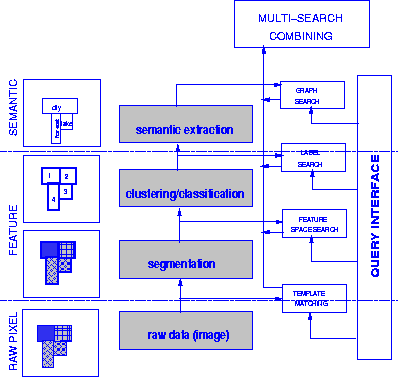
then the composite object ![]() , shown in Figure 2, consists of
, shown in Figure 2, consists of ![]() and of the
three spatial rules:
and of the
three spatial rules:
An example of a composite object is a bridge, which consists of a segment of road with water on both sides. Similarly, airports can be defined as regions containing parallel or perpendicular intersecting runways.
In order to maintain extensibility and flexibility in a content-based image search facility, semantics and features must often be extracted from images in the archive at query time. These are computationally expensive operations, however, causing difficulty in designing a scalable archive search scheme. To address this issue, we propose a progressive framework which involves reorganizing the data representation and designing search schedules.
The data in the archive is transformed into a progressive representation with multiple resolutions. Although a wavelet-based transformation is adopted in the current system, this principle can be applied to other transformations such as the Discrete Cosine Transformation. The purpose of data reorganization is to concentrate the information contained in the original image data. Consequently, search algorithms such as template matching, histogram computation, texture matching, and classification can be adapted to search the archive hierarchically, resulting in a significant reduction in the amount of data that needs to be processed.
We schedule query processing based on the estimated ability of each search operator to restrict the search space. Our initial implementation uses a simple heuristic -- we estimate the number of objects to be returned from each operator in a query, and at each stage invoke the operator that returns the smallest number. We are currently exploring more sophisticated scheduling schemes, including one that incorporates fuzzy logic.
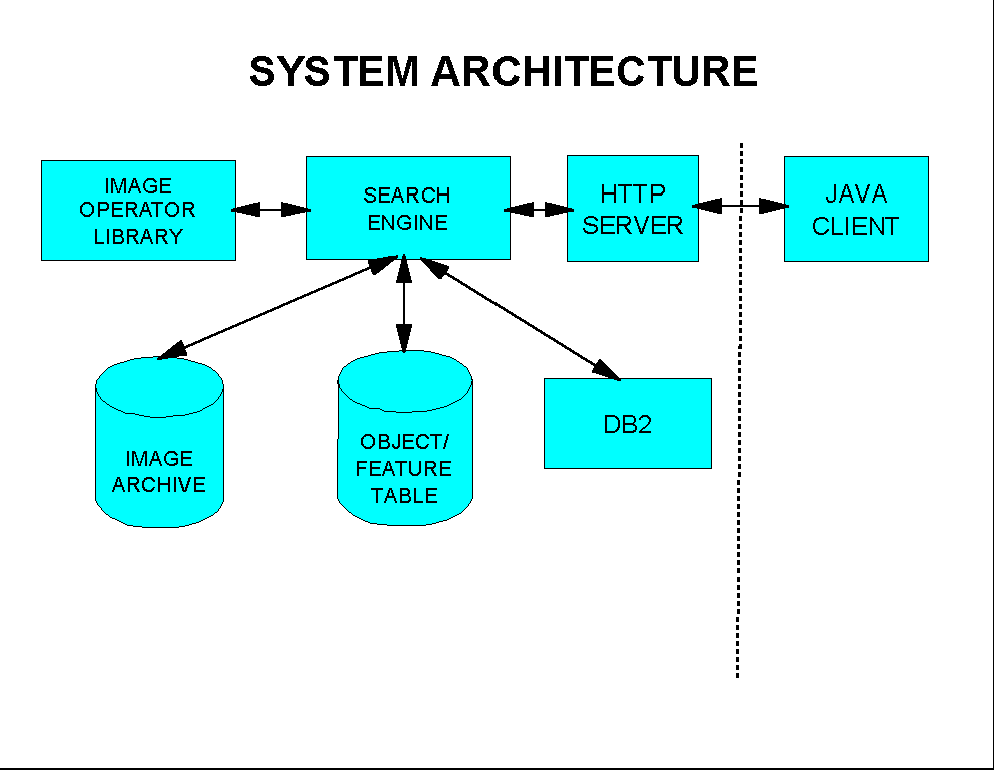
The architecture of the initial implementation of the proposed progressive framework, shown in Figure 3, consists of Java clients, an HTTP server, the search engine, a database management system (IBM DB2), an index and image archive, and a library contains various feature extraction, template matching, clustering and classification modules.
In this paper, we assume that a database consists of those relational or object-relational tables that are semantically related.
The database schema of the proposed system is shown in Figure 4 and consists of the following:
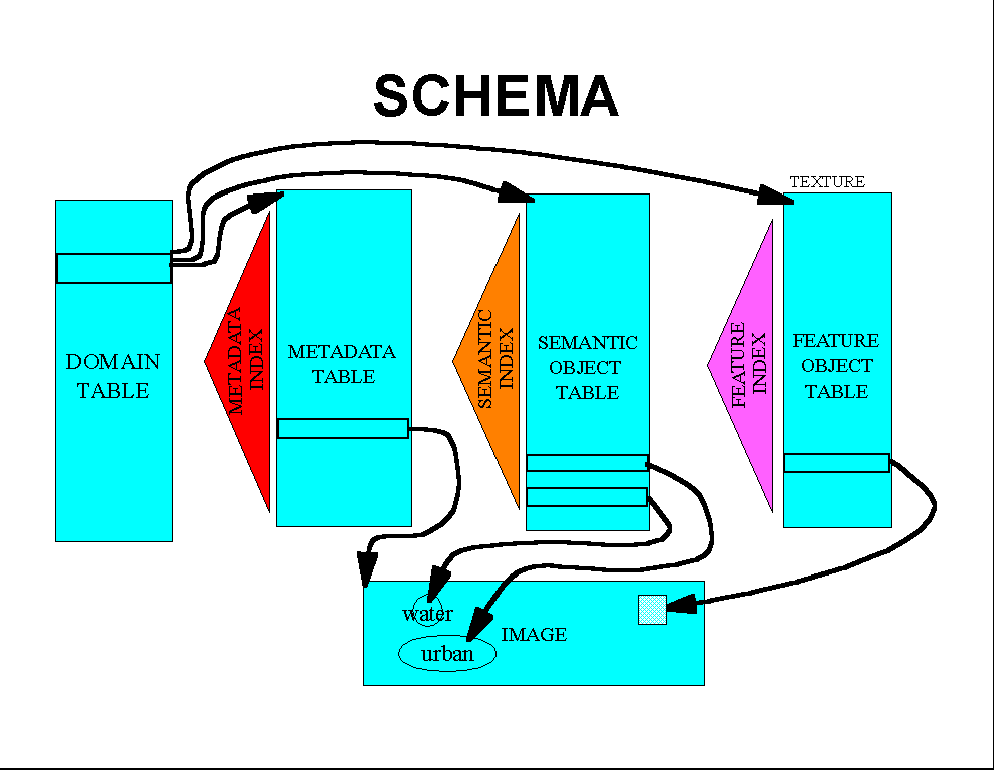
Queries are constructed and parsed syntactically at the client using a drag-and-drop interface. This interface also allows the definition of new objects and features. After being specified and syntactically analyzed, the query is then sent to the server. A query usually involves both metadata search and image content search. The server subsession parses the query string into a script consisting of a set of SQL statements and content-based search operators. Search on the metadata is performed by the database engine, while the image content search is performed by the content search operators. Usually the metadata search serves as a pruning mechanism, to achieve maximum reduction of the search space during the first stages of the query execution process. The content-based search engine can also access the feature descriptors as well as the raw pixels of an image region in order to compute the final results.
Search results are usually ranked based on a similarity measure. The user can specify the maximum number K of results to be rendered; the system ranks the results of the search process and returns the top K ones.
The results of the search are rendered by the visualization engine. If necessary (i.e., if database entries have been used for search but not the raw imagery), images associated with the search results are retrieved and rendered appropriately. The system supports both monochrome and RGB composite renderings of images. Object descriptions are packaged with each image for display by the client, allowing for interactive display and manipulation of query results.
In this section we present several scenarios of content-based query at multiple abstraction levels and of query refinement using our system. The first scenario involves search on semantic-level objects. For this example and the two following, we are searching on a single band (band 1) of a Landsat Multi-spectral Scanner (MSS) image of a portion of southern Montana. The query for the first scenario, composed using our Java-based drag-and-drop interface, is shown in Figure 5;

The query is translated into a set of nested function calls by the client and transmitted to the server where it parsed into a script consisting of both database calls and search operators. Objects that meet the search criteria are packaged with their associated images for transmittal to the client.
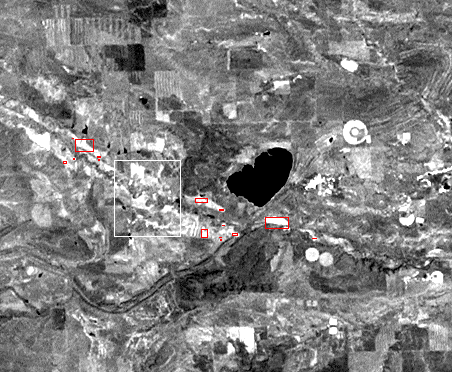
The results from this sample query, which searches based on predefined, semantic objects (agricultural areas, water bodies) and predefined relationships, is shown in Figure 6; agricultural areas that lie within 2 kilometers of water bodies are displayed by the client as red boxes.
The second example demonstrates feature-based search. A region of the
image has been specified via a rubber band box (the selected region is shown
as a white rectangle in Figure 7) and
supplied as an example for a texture-matching operator. The specification
of the match is shown in Figure 8
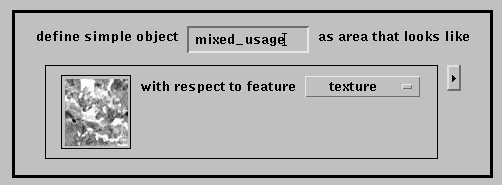
Figure 7 shows the results of the simple query
"Find all mixed_usage within the currently defined search region".
Feature-based objects are stored as square regions of fixed size (in this
case 32x32 pixels), which have been pre-extracted from the image. The
results represents the best matches to the user-specified example.

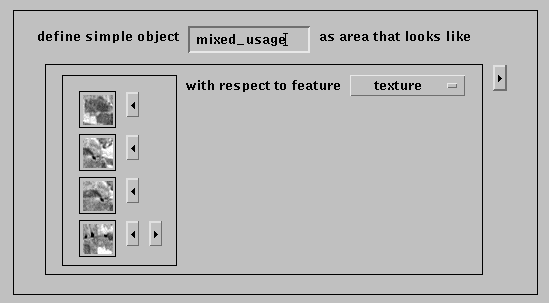
Figure 9 shows how the results of the
previous query can be used to refine the specification. Several of the
regions from the query were selected and used to modify the object
specification. Submitting this new specification to the search engine will
result in a modified set of results.
The next example demonstrates construction of a composite object definition. The definition, shown in Figure 10 is comprised of two objects, one of which is a semantic object, the other the feature-based object constructed in the last example. Two constraints are specified that define the object, one a distance-based constraint, the other a directional constraint. Figure 11 shows the single result object which satisfied all constraints for the given region. The displayed bounding rectangle encompasses all components that comprise the composite.


The final example demonstrates the use of a pixel-based matching operator.
Figure 12 shows the object definition based on
an image example and the "Find" query that that is submitted to the search
engine. Note that in this example we are searching on a set of images
(specified by the "all images in instrument") clause, rather than a single
image. Figure 13 shows the set of results
returned from this query. Note that a number of images were returned with
the best match displayed for each.

In this paper, we have presented a scalable architecture to perform progressive content-based search from large satellite image archives. Objects at both the semantic and the feature levels are extracted to facilitate efficient and flexible retrieval. In addition, a hierarchical representation is constructed for each image. Consequently, content-based search operations can be applied hierarchically, resulting in a significant speedup.
This project is supported in part by NASA grant CAN NCC5-101. The authors would like to acknowledge Dr. Harold S. Stone for making the initial proposal, and Dr. John J. Turek for leading the project between January 1995 and June 1996.



hdl:cnri.dlib/october97-li