|
||
D-Lib Magazine |
|
| Ian H. Witten, David Bainbridge, Stefan J. Boddie |
![]()
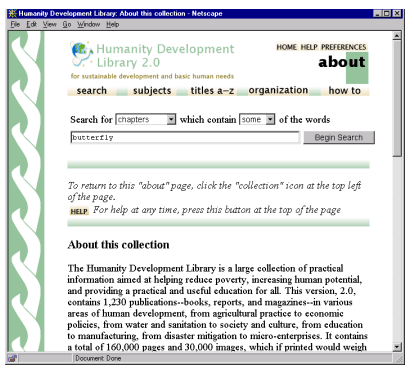
AbstractThe Greenstone digital library software is an open-source system for the construction and presentation of information collections. It builds collections with effective full-text searching and metadata-based browsing facilities that are attractive and easy to use. Moreover, they are easily maintained and can be augmented and rebuilt entirely automatically. The system is extensible: software "plugins" accommodate different document and metadata types. Greenstone incorporates an interface that makes it easy for people to create their own library collections. Collections may be built and served locally from the user's own web server, or (given appropriate permissions) remotely on a shared digital library host. End users can easily build new collections styled after existing ones from material on the Web or from their local files (or both), and collections can be updated and new ones brought on-line at any time. IntroductionThe Greenstone Digital Library Software from the New Zealand Digital Library project [1] provides a new way of organizing information and making it available over the Internet. Collections of information comprise large numbers of documents (typically several thousand to several million), and a uniform interface is provided to them. Libraries include many collections, individually organized -- though bearing a strong family resemblance. The structure of a collection is determined by a configuration file. Existing collections range from newspaper articles to technical documents, from educational journals to oral history, from visual art to videos, from MIDI pop music collections to ethnic folksongs. Making information available using Greenstone is far more than just "putting it on the Web." The information becomes searchable, browsable, and maintainable. Each collection, prior to presentation, undergoes a "building" process that, once established, is fully automatic. This creates all the structures used for access at run-time. Searching utilizes various indexes of text and/or metadata, while browsing utilizes metadata such as title and author. When new material appears, it is incorporated into the collection by rebuilding. To address the broad demands of digital libraries, the system is public and extensible. Issued under the Gnu public license, users are invited to contribute modifications and enhancements. Widely used internationally, Greenstone supports collections in many different languages. Greenstone CD-ROMs have been published by the United Nations and other humanitarian agencies for distribution in developing countries. Information collections built by Greenstone combine full-text search with browsing indexes based on different metadata types. There are several ways for users to find information, although they differ between collections depending on the metadata available and the collection design. In Figure 1, the Global Help Project's Humanity Development Library (HDL) is being searched for chapters matching the word butterfly [2]. (Also visible on this About page is information about how the collection is organized and the principles governing its use.) The default search interface is a simple one, suitable for casual users. Advanced searching -- which allows Boolean expressions, phrase searching, and case and stemming control -- can be enabled from a "Preferences" page [3]. This particular collection contains indexes of chapters, section titles, and entire books.
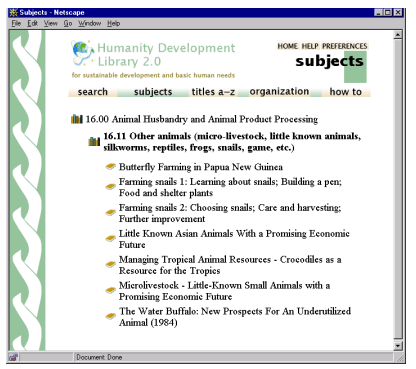
In Figure 2, the same collection is browsed by subject; by clicking the bookshelf icons, the user has discovered an item under Animal Husbandry [4].
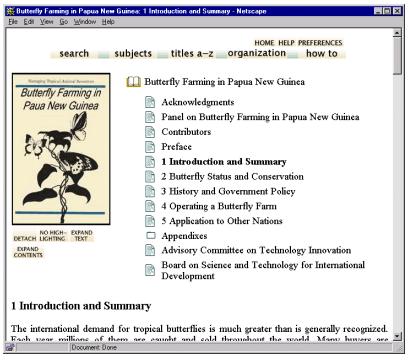
Clicking a book icon displays the front cover on the left of Figure 3, and the table of contents is automatically constructed at the start of the document [5]. The current focus, Introduction and Summary, is shown in bold: its text starts further down the page.
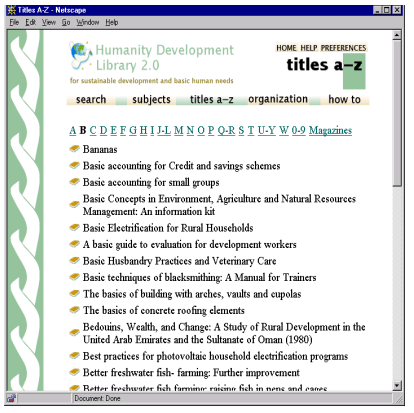
Searching is full-text, and -- depending on the collection -- users select indexes built from different parts of the full text or the metadata. Some collections have separate indexes of full documents, sections, paragraphs, titles, and section headings, each of which can be searched for particular words or phrases. When browsing, users examine data structures created from metadata: lists of authors, titles, dates; hierarchical classifications; and so on. Structures for both searching and browsing are specified by instructions in the configuration file, and can be rebuilt entirely automatically. No information is inserted by hand. Each document may be hierarchically organized into logical sections, each of which comprises paragraphs. Metadata such as author, title, date, keywords, may be associated with documents, or with individual sections. This is the raw material for indexes. It must either be provided explicitly (for example, in an accompanying spreadsheet) or be derived automatically from the source documents. Metadata is stored with the document for internal use. The software is organized so that "plugins" import documents and transform them into a standard XML form with metadata included. There are plugins for plain text documents; HTML, Word, PostScript and PDF files; email; and common bibliographic formats. New plugins can easily be written -- several have been specially produced for proprietary formats. If the collection contains source documents in different forms, it is just a matter of specifying the necessary plugins. Plugins also perform metadata conversion, whether from internal sources such as HTML's <title> and <meta> tags or Word's "summary" properties, or from externally-specified XML or spreadsheet files. Many collections express metadata in ad hoc ways: these require bespoke plugins. Some plugins also extract metadata from documents using text mining techniques. There are plugins that identify languages [6] and extract acronyms [7], historical dates, email addresses, keyphrases, etc. Modules called "classifiers" build browsing structures from metadata -- alphabetic lists, dates, hierarchical classifications, etc. The Humanity Development Library collection shown in the example above has four metadata indexes. You can access publications through a subject hierarchy using the subjects button (Figure 2) [4]; by title, which displays a list of books in alphabetic order (Figure 4) [8]; by organization (i.e., Dublin Core "publisher"); or by a list of hints defined by the collection's editors (how to) [9]. Dublin Core forms a base that is extended to accommodate idiosyncratic requirements of collection designers.
The Unicode character set is used throughout, so documents -- and interfaces -- can be in any language. Collections have been produced in English, French [10], Spanish [11], German, Maori [12], Chinese [13], Russian [14], and Arabic [15], and Greenstone has interfaces in all these languages and more [16] -- including a text-only version for visually impaired users [17]. Collections can contain text, pictures, audio and video clips [18], and music [19]. Most non-textual material is linked to textual documents or accompanied by textual captions to support searching and browsing. Compression technology is used throughout to ensure best use of storage [20]. The system includes an "administrative" function whereby specified users can examine the composition of all collections, protect documents so that they can only be accessed by registered users on presentation of a password, and so on. User activity logs record all queries made to every Greenstone collection (though this facility can be disabled). Although primarily designed for web access, collections can be printed on self-installing Windows CD-ROMs with a built-in webserver and the same web interface. These operate standalone on all Windows versions -- a requirement that complicates the software design but is crucial for users in underdeveloped countries seeking access to humanitarian aid collections [21]. The system operates under Unix, Windows, and Mac OS/X, and works with standard Web servers. A flexible process structure allows different collections to be served by different computers and yet presented to the user as part of the same digital library -- and even, seamlessly, as part of the same collection [22]. Existing collections can be updated and new ones brought on-line at any time, without bringing the system down -- the interface process checks periodically and automatically adds new collections to the list presented to the user. The CollectorThe structure of each collection is determined at set up. This includes specifying the format (or formats) of source documents, deciding how to display the documents on the screen, determining what the source of metadata will be, choosing what full-text searching and browsing facilities should be provided, and outlining how the search and browsing results should be displayed. Once a collection is in place, new documents in the same format can be added automatically. The Greenstone "Collector" is an interactive subsystem for managing and accessing collections [23]. The Collector can be used to:
Imagine you are using the Collector to create a new collection from (let us say) a set of html files stored locally. First, an explanatory Web page appears asking you whether you want to work with an existing collection (see the first two options above) or build a new one (see the remaining options). Either way you must log in before proceeding. Collections are built on a Greenstone server which is, in general, accessed remotely. Because arbitrary users cannot be allowed to build collections, access authorization is required. Thus a central library can, if desired, offer a service to people wishing to build information collections on it. Users who run Greenstone on their own computer may build collections locally, but must still log in to prevent arbitrary users of their library from building collections. Dialog structureUpon completion of login, a new page appears that shows the sequence of steps involved in collection building:
The first step specifies the collection's name and associated information -- Figure 5 provides an example of how this interaction might appear. The second step defines where the source data will come from. The third step tailors the configuration options, which requires considerable understanding of what is going on -- this step is really for advanced users. In the fourth step, all the (computer's) work is done -- the system makes all the indexes and gathers together all information required to make the collection operate. Finally, the new collection can be viewed. These steps appear as a linear sequence of buttons at the bottom of each Collector page so that users can keep track of where they are. Buttons change color to reflect the current stage. The display is modeled after the "wizards" that are widely used to guide users through the installation of new commercial software. Collection informationThe first step, collection information (shown in Figure 5), is to enter some information about the new collection. The title is a short phrase used to identify the collection. The email address is used for diagnostic reports in case any problems arise with the collection. The user also enters the text that appears under About this collection (e.g., Figure 1). An arrow appears at the bottom of the screen to indicate the user's position in the collection-building sequence -- in this case the collection information stage. The user proceeds by clicking the green button, labeled source data.
Source dataNext the user specifies the source text that comprises the collection. The collection is either completely new or a "clone" of an existing one. Creating a new collection with totally novel structure is a major undertaking, and most new collections are clones of existing ones. The user chooses which collection to clone from a pull-down menu. Most Greenstone installations have several different collections. The document file types in the new collection should be amongst those in the one being cloned, the same metadata should be available, and the metadata should be specified in the same way. However, Greenstone is equipped with sensible defaults. If document files with an unexpected format are encountered, they are simply omitted from the collection (with a warning message). If the metadata needed for a particular browser is unavailable for a particular document, that document will be omitted from the browser. When creating a completely new collection, a bland collection configuration file is provided that accepts most document types and generates a searchable index of the full text and a title browser since this metadata is normally available. Boxes are provided to indicate where the source documents are located. Any number of input sources can be specified. Specifications can be
In each case of "file://" or "ftp://" the collection will include all files in the specified directory, any directories it contains, any files and directories they contain, and so on. If a filename is specified, that file alone is included. For "http://" the collection will mirror the specified Web site. Configuring and building the collectionThe construction and presentation of all collections is controlled by specifications in a configuration file (see below). Advanced users may use the next page to alter the settings in this file. Most, however, will proceed directly to the final stage where the computer "builds" the new collection. Up to this point, the responses to the dialog have merely been recorded in a temporary file. The building stage is where the action takes place. First, an internal name is chosen for the collection, based on the title that has been supplied. Then a directory structure is created that includes subdirectories to receive, index and present the source documents. A recursive file system copy command is issued to retrieve source documents already on the file system; for offsite files a web mirroring package is used to copy the specified site along with any related image files. Next, the documents are converted into a standard XML form. Appropriate plugins to perform this operation must be specified in the collection configuration file. This done, the copied files are deleted: the collection can always be rebuilt from the information stored in the XML files. Then the full-text searching indexes and browsing structures specified in the collection configuration file are created. Finally, the result of the building process is moved to the area for active collections. This precaution ensures that if a version of this collection already exists, it continues to be served right up until the new one is ready. The software assigns a global, persistent identifier to each document to ensure that the changeover is almost always invisible to users. The building stage is potentially time-consuming. Small collections take a minute or so but large ones can take a day or more. The Web is not a supportive environment for lengthy activities. A button is provided that allows the user to stop the building process immediately, but users cannot be prevented from leaving the building page. If they do, the Collector continues regardless. Progress is displayed in a status area at the bottom of the building screen, updated every few seconds. Warnings are issued if any of the following occur:
Users should monitor progress by keeping this window open in their browser. If any errors terminate the process, they appear here. Viewing the collectionWhen the collection is built and installed, a View collection button becomes active. Clicking this button takes the user directly to the newly built collection. Also, email is sent to the collection's contact email address and to the digital library administrator whenever a collection is created (or modified). This allows those responsible to monitor what is happening on the system. Working with existing collectionsFour additional facilities are provided when working with existing collections: adding new material, modifying the collection structure, deleting the collection, and printing it on a CD-ROM. The same dialog structure is used to add new material to an existing collection, but entry is at the "source data" stage. New data is copied as before and converted to XML, joining any existing imported material. Revisions of old documents should perhaps replace existing ones rather than being treated as entirely new. However, this is so difficult to determine that all new documents are added to the collection unless they are textually identical to existing ones. While an imperfect process, in practice the browsing structures are sufficiently clear to make it easy to ignore near-duplicates. The aim of the Collector is to support the most common collection-building tasks in a straightforward manner. If greater control is necessary, it can be achieved by using a suite of command-line scripts instead of the Collector interface. The structure of existing collections is modified by editing their configuration file. Here, the dialog is entered at the "configuring the collection" stage. To delete a collection, select it from a list and confirm its deletion. Only collections built by the Collector can actually be removed -- others (typically built by advanced users working from the command line) are not shown in the list. It would be nice to be able to selectively delete material from a collection through the Collector, but this functionality does not yet exist. At present this must be done from the command line by inspecting the file system. Finally, to write an existing collection to a CD-ROM, select the collection and it is automatically massaged into a disk image in a standard directory. The Collection Configuration FileFigure 6 shows a collection configuration file. Some of the information in it was gathered from the user during the Collector dialog. The indexes line builds a single index comprising the text of all the documents. The classify line builds an alphabetic classifier of the title metadata.
A permissive list of plugins is included. ZIPPlug uncompresses any Zipped files, and makes them available to the other plugins. "GML" is the name of the internal XML document format, and GMLPlug processes previously imported documents. TEXTPlug, HTMLPlug and EMAILPlug process documents of the appropriate types, identified by their file extension. RecPlug (for "recursive") expands subdirectories and pours their contents into the plugin list, thereby traversing arbitrary directory hierarchies. More indicative of Greenstone's power than the generic structure shown in Figure 6 is the ease with which other facilities can be added. To choose just a few examples:
Skilled users could add any of these features to the collection by making a small change to the information presented during the "Configuring the collection" stage. However, we do not anticipate that many casual users will operate at this level. More likely, someone who wants to build new collections of a certain type will arrange for an expert to construct a prototype collection with the desired structure, and proceed to clone that into further collections with the same structure but different material. SummaryWe close with a brief summary of Greenstone facilities. Greenstone is:
Greenstone provides:
Greenstone enables:
And last but not least, because Greenstone is open-source software, it is easily modified! What you see -- you can get! Greenstone is available from the New Zealand Digital Library (http://www.nzdl.org) under the terms of the Gnu General Public License. It is easy to install on Windows and Unix. AcknowledgementsWe gratefully acknowledge all members of the New Zealand Digital Library project for their enthusiasm, ideas and commitment. References[1] New Zealand Digital Library project (http://www.nzdl.org). [2] Humanity Development Library: home page (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=hdl). [3] Humanity Development Library: preferences page (http://www.nzdl.org/cgi-bin/library?a=p&p=preferences&c=hdl). [4] Humanity Development Library: Subject hierarchy example (http://www.nzdl.org/cgi-bin/library?a=d&c=hdl&cl=CL1.16.9).
[5] Butterfly Farming in Papua New Guinea (http://www.nzdl.org/cgi-bin/library?a=d&c=hdl&cl=CL1.16.9 [6] Language extraction demo (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=folktale). [7] Acronym extraction demo (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=acrodemo). [8] Humanity Development Library: browsing by title ( http://www.nzdl.org/cgi-bin/library?a=d&cl=CL2&c=hdl). [9] Humanity Development Library: browsing by "how to" (http://www.nzdl.org/cgi-bin/library?a=d&cl=CL4&c=hdl). [10] UNESCO (1999) SAHEL point DOC. (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=unesco). [11] PAHO/OPS (1999) Virtual Disaster Library. (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=paho). [12] Niupepa: Maori newspapers (http://www.nzdl.org/niupepa).
[13] Chinese demo collection (http://www.nzdl.org/cgi-bin/library? [14] Mari El Republic (http://gov.mari.ru/gsdl/cgi/library).
[15] Arabic demo collection (http://www.nzdl.org/cgi-bin/library? [16] See interface language menu on Preferences page (http://www.nzdl.org/cgi-bin/library?a=p&p=preferences). [17] Humanity Development Library in text-only format (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=hdl&v=1). [18] Music videos. (http://www.nzdl.org/cgi-bin/library?a=p&p=about&c=musvid). [19] New Zealand Digital Library music library (http://nzdl2.cs.waikato.ac.nz/cgi-bin/gwmm?c=meldex&a=page&p=coltitle). [20] Witten, I.H., Moffat, A. and Bell, T.C. (1999) Managing gigabytes: Compressing and indexing documents and images. Morgan Kaufmann, San Francisco, CA. [http://www.cs.mu.OZ.AU/mg/]
[21] Witten, I.H., Loots, M., Trujillo, M.F. and Bainbridge, D. (2001) "The promise of digital libraries in developing countries." Comm. ACM, Vol. 44, No. 5, pp. 82-85. [http://www.acm.org/pubs/articles/journals/cacm/2001-44-5/ [22] Bainbridge, D., Witten, I.H., Buchanan, G., McPherson, J., Jones, S. and Mahoui, A. (2001) "Greenstone: A platform for distributed digital library applications." Proc European Digital Library Conference, Darmstadt, Germany; September. [http://www.cs.waikato.ac.nz/~davidb/ecdl01/platform.ps]
[23] Witten, I.H., Bainbridge, D. and Boddie, S.J. (2001) "Power to the people: end-user building of digital library collections." Proc Joint Conference on Digital Libraries, Roanoke, VA, pp. 94-103. [http://www.acm.org/pubs/articles/proceedings/dl/379437/
[24] Paynter, G.W., Witten, I.H., Cunningham, S.J. and Buchanan, G. (2000) "Scalable browsing for large collections: a case study." Proc Fifth ACM Conference on Digital Libraries, San Antonio, TX, pp. 215-223; June. [http://www.acm.org/pubs/articles/proceedings/dl/336597/ Copyright 2001 Ian H. Witten, David Bainbridge, and Stefan J. Boddie |
|
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/october2001-witten
|