|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
|
|
D-Lib Magazine
|
|
Laura M. Bartolo Timothy W. Cole Sarah Giersch Michael Wright |
![]()
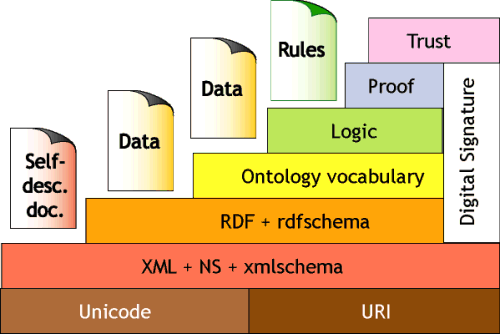
IntroductionThis article discusses a workshop on scientific markup languages (MLs), sponsored by the National Science Foundation and the National Science Digital Library (NSDL) on June 14-15, 2004. The workshop brought together forty-three higher education, publishing and software, and government representatives from the disciplines of biology, chemistry, earth sciences, mathematics, materials sciences, and physics. The goals of the workshop were to assess and document scientific disciplines' work on markup languages (MLs) and to begin to articulate a vision for the future evolution and implementation of markup languages in support of a cyberinfrastructure for research and education, with a particular focus on using markup languages in the context of the NSDL. The workshop opened with presentations that 1) provided a framework for the workshop discussions about scientific markup languages as they relate to the broader development of knowledge infrastructures and that 2) suggested that there is an ongoing tension between static data exchange standards and the dynamic nature of science, science research, science education, and scientific data. Presentations on the current state of scientific MLs as used in the four specific scientific domains (chemistry, earth sciences, materials sciences, and mathematics) highlighted the idea that for MLs to move forward in a discipline, adoption and development must occur among communities of scientists, publishers and vendors, and end-users simultaneously. Cross-domain discussions around topics (Education and Domain Experts; Markup Languages (in general); Publishers / Professional Societies; and Database / Tool Developers & Data Users) identified several cross-cutting themes and recommendations. These were refined during the closing session and next steps were identified. PresentationsMaking the Web Safe for Intelligent AgentsThe workshop opened with a keynote presentation from Tim Finin [1], who addressed the issue of how to make the web machine-usable and why it should be done. He provided a framework for the workshop discussions about scientific markup languages as they relate to the development of a knowledge infrastructure that supports software agent applications. Finin noted the current web does not support software agents because of its inability to provide, among other things, machine usable and understandable interfaces. For the current web to be usable by software agents, several layers of languages, data and ontologies must be in place first. The first layer consists of XML markup languages, followed by a second layer of data over the web. This foundation allows machine-understandable structures to be built that will provide the basis for the future software agent applications. The next step is to develop a layer of knowledge representation. The semantic web (See Figure 1 developed by Tim Berners-Lee [2]) is the beginning of that process. A key component of the semantic web is ontologies – theories of what exists. Information systems have adopted ontologies from philosophy and formalized them into specifications for use in applications (e.g., UML diagrams, data dictionaries, database schemas, conceptual schemas, and knowledge bases). But there is also a need for tools to be "semantic web aware." Finin observed that it would take time to achieve the intelligent agent paradigm either on the Internet or in a pervasive computing environment. The development of complex systems is an evolutionary process. He recommended that researchers and developers start with the simple and move toward the complex (e.g., from vocabularies to full ontology language theories), allow many ontologies to bloom, and support a diversity of ontologies since monocultures are unstable. Figure 1: Layers of the Semantic Web An Historical Perspective on Markup LanguagesThe second plenary presentation, from John Rumble [3], focused on placing scientific markup languages in the context of the broader body of scientific standards which facilitate and enable effective reporting, dissemination, and use of scientific data and analyses. In particular, Rumble suggested that there is an ongoing tension between static data exchange standards and the dynamic nature of science, science research and scientific data. XML-based markup languages, because they can be defined to include a measure of flexibility and extensibility, have the potential to help bridge that dynamic tension. To achieve that potential, developers of scientific markup languages should examine how successful scientific standards historically have tended to evolve and attain prominence, the motivations of standards users and adopters, the nature of the data exchange tasks being attempted through the use of markup languages, and the lessons to be learned from studies of language evolution more generically. Rumble concluded with a challenge for workshop participants to make markup languages address, first and foremost, the needs of scientists, who are seen as the primary users of scientific markup languages. And just as human languages evolve over time, markup languages must be developed with an eye towards evolution. Rumble noted that nature is tricky; describing nature is even trickier. Discipline-specific Markup LanguagesEarth Sciences – ArcXML, ESML, GML, NcML [4]The earth sciences, including sub-domains such as atmospheric science, have developed a range of markup languages, including GML (Geography Markup Language), ESML (Earth Science Markup Language), NcML (NetCDF) Markup Language, and ArcXML (ArcGIS Markup Language). Needs driving the development include accommodating massive, and increasingly large, amounts of observational data from multiple sources such as in-situ instruments, satellite remote sensing, and observation campaigns (e.g., sonar sweeps of the ocean floor). In addition to the observational data, more data is being made available from models and simulations, often run on high performance computing systems. These models are often initiated from, and calibrated against, observational data. The complexity of the models and simulations are important to record and preserve. Other common aspects are the need for data to be geo-referenced and time-referenced. In some cases the requirement may be more specific to one type of data, for example, geo-referencing of a location such as a city, or physical occurrence such as a rock type. In other cases, the need is for a complex four-dimensional data model such as in weather and climate data. With the development of a number of different frameworks, the need for crosswalks and mediation has become apparent. This need has led to the development of higher-level, or knowledge-level, mediation mechanisms. An example of an ontology for mediation in the Earth sciences is SWEET (Semantic Web for Earth and Environmental Terminology, developed at NASA/JPL) which is designed to enable the scalable classification of earth science concepts. SWEET is available as an OWL (Web Ontology Language) structure that can be used in tools being developed in the semantic web community such as inference engines. Chemistry – CML [5]Chemistry Markup Language (CML) began in 1994 and is based on XML. Built upon STMML (scientific, technical and medical markup language) used in publishing, CML is comprised of 5 parts: CMLCore (micro molecules, atoms, bonds) CMLSReact (reactions), CMLComp (computational chemistry), CMLSpectra (spectra) and CMLCryst (crystals). The early adopters of CML have been government agencies, such as the National Cancer Institute and the National Institutes of Health as well as the European Patent Office, and societies and publishers, like the Royal Chemistry Society and Nature Publishing Group. The vision for the Chemical Semantic Web is an infrastructure where a robot can, for example, find phase diagrams for lipid mixtures or add molecular data to a researcher's monthly report following specified guidelines. More advanced applications would include reading a published paper in the Journal of Medicinal Chemistry and computing the geometries and energies for all new molecules, calculating binding to HIV protease, and ordering the chemicals required for synthesis. To reach this vision, emphasis needs to be placed on creating compound documents that merge text and data, such as papers with editable chemical equations that animate chemical reactions. Currently most information associated with chemical work is destroyed when papers are published as PDF and Word documents. Documents need to be transformed into CML; however, publishers and secondary database providers are resistant to change traditional business models. The development of authoring tools, browser enhancements, and generic physical science ontologies will enable early adopters, key industries, publishers, and software developers to advance markup languages to meet real world needs. Mathematics – MathML [6]Initial work on what became MathML predates the formal release of XML and draws on earlier experiences representing mathematics in SGML (e.g., the ISO 12083 Mathematics DTD fragment [7]), HTML (e.g., inclusion in HTML version 3.0 of math-specific elements, attributes, and constructs, only some of which were retained for HTML 3.2 and later releases), and TEX (created in 1979). Given the complexity and ongoing evolution of mathematics notation, it was not feasible to make MathML comprehensive. The authors of MathML explicitly targeted it for expressing mathematical content through early undergraduate level (first-order calculus). MathML is intentionally bimodal, containing markup to describe the presentation separate from markup to describe semantics. Early implementers have focused on one or the other but not both, resulting in asymmetrical implementations that do not always interoperate as well as might be desired. There have been major inroads in getting the middle layer of the scholarly communication architecture to embrace MathML. Publishers and vendors of computer algebra engines and related tools are incorporating MathML into their workflows and products. This provides a high level of interoperability between systems and has the potential to provide enhanced user experience for the consumers of mathematical content. However, the utility of MathML to enhance searching and improve accessibility of online mathematical content has yet to be proven. A major step forward has been the adoption in Unicode of additional code points for mathematical symbols and special characters, and the concurrent work on a freely shareable font set including the associated glyphs [8].Materials Science – MatML [9]In order to improve the standardization, interoperability, and ultimately utility of electronic materials property data, the Materials Science and Engineering Laboratory of the National Institute of Standards and Technology, with Ed Begley as the Project Leader, initiated the development of the Materials Property Data Markup Language (MatML). MatML provides a standard way to specify the hundreds of materials properties that materials scientists and engineers need to know and access. MatML aims to allow users in the industrial, research, and educational communities to more easily use materials property data from multiple sources in models, simulations, or distributed databases. MatML has the broad participation of private industry, government laboratories, universities, standards organizations, and professional societies from the international materials community. MatML builds on well-established work in domains of general-purpose markup languages (e.g., SGML, HTML, and XML) and materials data standards (e.g., those promulgated by the American Society for Testing and Materials [ASTM], the International Standards Organization [ISO], and other standards organizations). The MatML effort is led by an ASM Committee comprised of working groups for technical development, schema development, and OASIS standardization. The MatML schema 3.1 [10] (May 2004) addresses the needs of those involved in the development, reporting, interchange, and application of materials information, including:
Themes across Domains & Markup LanguagesDuring the final wrap-up session of the workshop, representatives from each topical group (Education and Domain Experts; Markup Languages (in general); Publishers / Professional Societies; and Database / Tool Developers & Data Users) reported on common cross-domain issues that were discussed in the afternoon sessions. Five themes emerged based on these discussions and on key comments from the morning presentations. These themes encapsulated the current state of activity and thought, not just on ML development and use by groups working independently, but also on the effects of MLs broader dissemination and use in the context of various sectors (e.g., education, publishing, government). Theme A: VisionEncapsulating information in XML underpins the interoperability concepts in the current web services environment where information or data encoded in XML can be easily exchanged between systems. As highlighted by the domain-specific breakout groups at the workshop, the development of markup languages that build on the XML framework has generated considerable momentum in the sciences over the past few years. Providing a means to exchange information or data in a structured form so that colleagues across scientific domains can read, understand, and use scientific research, motivates the development of XML-based markup languages. Through common interoperability mechanisms, NSDL supports the exchange of information between the sciences and provides a framework for markup languages to be extended in science education settings. Theme B: Demonstrating the value of markup languagesThere was a clear consensus that markup languages can be of significant benefit in scientific research and science education. However direct benefits to users that outweigh start-up and ongoing implementation costs need to be clearly demonstrated in order to stimulate broader adoption of scientific markup languages and broader support from potential funding groups. While markup languages have been established as a good way to link between information objects, their broadest implementation to date occurs in processes that are virtually invisible to most users. Most significant implementations of scientific markup languages have been undertaken in the context of backroom and "middlemen" applications in the scholarly information creation and dissemination cycle. There was agreement that markup languages have potential benefits as an approach that would facilitate:
Theme C: Creating & disseminating the pre-requisite toolsParticipants from all domains agreed that better tools, both technical tools and broader, more robust ontologies, would facilitate and speed the adoption of scientific markup languages. Specific examples included:
Theme D: Mediation of markup languagesThe need for cross-markup language understanding (e.g., how the structure and semantics of one language relate to those of a second language) was a common theme in the workshop, a theme that was mentioned in the keynotes and again in various breakout discussions. "Mediation" addresses the need for tools and services that provide a translation interface between representations in different markup languages, or that provide access to information in a single markup language to a wide variety of users. The development of taxonomies and controlled vocabularies are one approach to achieving cross-language interoperability. Ontologies are another approach to being able to relate the semantic meaning of one language to that of another. A number of the markup languages discussed at the workshop have rich vocabularies in their structures, but the idea of linking these to a broader knowledge representation, such as to an ontology, is just beginning to be explored. Another aspect of mediation relates to end user access to information as it is structured in a particular language. For example, the semantic structure of a language has been developed by early developers, often in the research area where the end user must have a high level of domain understanding in order to use, or access, a document in the language. For NSDL, with its mission to support education, providing access to markup languages for users who are not domain experts is critical. For markup languages to be used widely in education, it will be important to develop tools and services that can mediate the semantics of markup languages to pedagogical concepts related to developing domain understanding. Theme E: Identifying challenges to maturation of markup languagesPoorly developed scientific markup languages can be obstacles to useful interoperability and thereby can impede innovation – the exact opposite of their intended function. A common issue in the growth of markup languages is the tension between the dynamic nature of science and the need for standardization, which cements a language but which also enables broad interoperability. The consensus of workshop participants was that this tension can be successfully addressed only if a broadly consultative and inclusive language development process is given an adequate amount of time and support. To find the right balance between rigidity and flexibility requires an iterative cycle that is open to contributions from a diverse community of experts representing researchers, publishers, librarians, educators, students and other end-user consumers of scientific knowledge. Participants also noted a market-related challenge to the maturation of scientific markup languages. Traditionally, commercial self-interest provides adequate incentives for publishers to convene the necessary experts to write, test, and promulgate a standard that insures interoperability. However, since the means to implement XML-based markup languages standards are non-proprietary and transparent by definition, the business models for initial software implementations based around scientific markup languages are marginally profitable. At the same time, the intellectual effort for routine tasks involving markup languages is often greater than similar tasks as currently performed. The lack of viable business models and the prospect of increased operating costs become significant disincentives for commercial software vendors and publishers to convene a broader community of stakeholders required to develop a consensus around scientific markup languages and core software tools. Workshop participants recognized a need for quantitative cost-benefit cases that demonstrate the ultimate value of scientific markup languages. But they also expressed concern that in the meantime, the evolution of some scientific markup languages might slow to a hazardous degree for lack of aggressive software implementations and language development. In this case, the government, rather than the private sector, might best support scientific markup languages during their transition towards maturity. AcknowledgementsThe workshop organizers would like to thank the NSF Directorate for Education and Human Resources (EHR) and the Division of Undergraduate Education (DUE) for supporting the workshop, with special thanks to Dr. Lee L. Zia, Program Director for the National Science Digital Library (NSDL), for support and encouragement. Thanks also to the workshop attendees for furthering and expanding scientific markup languages by providing perspectives about markup languages through written statements, participating in the workshop, and commenting on this report. The workshop was sponsored by the National Science Foundation under grant no. DUE-0333520. ReferencesAll of the documents association the workshop can be found on the workshop website: <http://scimarkuplang.comm.nsdl.org/>. Below are URLs from the plenary presentations. Plenary Presentations
Presentations on Domain-specific Needs for Markup Languages
Presentations prepared for panel of breakout discussions
Notes1. Tim Finin is a Professor in the Department of Computer Science and Electrical Engineering at the University of Maryland, Baltimore County. 2. Berners-Lee, Tim. (2000). Semantic Web on XML. In XML2000. Washington, DC. Online: <http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html>. 3. John Rumble is the Technical Director for Information International Associates, Inc. 4. Rob Raskin, NASA – Jet Propulsion Laboratory, gave the introductory presentation regarding the state of markup language development in the discipline of mathematics. 5. Peter Murray-Rust, Cambridge University, gave the introductory presentation regarding the state of markup language development in the discipline of chemistry. 6. Robert Miner, Design Science, gave the introductory presentation regarding the state of markup language development in the discipline of mathematics. 7. Available <http://www.xmlxperts.com/mathdtd.htm>. Accessed 1 October 2005. 8. The STIX Fonts project <http://www.stixfonts.org/>. Accessed 1 October 2005. 9. Adam Powell, MIT, gave the introductory presentation regarding the state of markup language development in the discipline of materials sciences. 10. Available <http://www.matml.org/schema.htm>. Accessed 1 October 2005 11. In the W3C sense of the phrase; see: <http://www.w3.org/2004/CDF/>.
Copyright © 2005 Laura M. Bartolo, Timothy W. Cole, Sarah Giersch, and Michael Wright |
|
|
|
|
|
Top
| Contents |
|
| |
|
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/november2005-bartolo
|