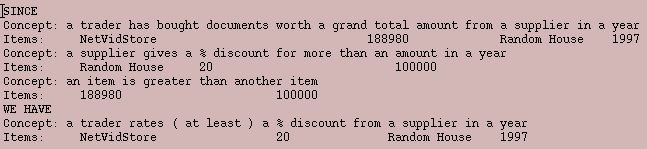D-Lib Magazine
May 1998
ISSN 1082-9873
Safeguarding Digital Library Contents and Users
Storing, Sending, Showing, and Honoring Usage Terms and Conditions
Henry M. Gladney and Jeff B. Lotspiech
IBM Almaden Research Center
San Jose, California 95120-6099
(gladney, lotspeich)@almaden.ibm.com

Abstract
This article knits together ideas and technologies discussed in several prior articles in the Safeguarding ... series in D-Lib Magazine.
We discuss languages for representing intellectual property usage terms and conditions in databases, for network transmission, and for presentation to and editing by human beings. Prototypes, one in each domain, can be knit together as a component of digital library services. We favor an approach based on cryptographic envelopment of document packets because this provides end-to-end protection and requires less network infrastructure and administration than alternatives. It needs protocols for enforcing information owners' rules -- protocols which govern how a user might select, request, possibly pay for, and eventually gain access to what she wants.
A deployed permission management and revenue collection mechanism will implement at least three system roles: a source S which encrypts and bundles valuable objects, an end user system U which manages requesting and receiving protected information, and a clearance center C which checks users' commitments to observe owners' conditions. We consider three alternative configurations.
We remind the readers why incomplete schemes based on much-ballyhooed "trusted systems" are fundamentally flawed, and suggest why it is unlikely that these notions will evolve to practical personal computer services. People might be less likely to be misled if this elusive objective were called "trustworthy systems".
Introduction
The Safeguarding ... series in D-Lib Magazine is intended to explore and illustrate technical contributions to mitigating intellectual property exposures which digital representations have raised. That technology can contribute only in a complex of administrative, legal, contractual, and social practices is well known; the current article is driven, more than any previous article in the series, to considering relationships among technical and other measures.
Until now, each article in our Safeguarding ... series has presented some narrow theme without connecting it carefully to other elements needed to realize "complete" digital library services. Articles in the series and elsewhere have discussed identifying what is to be protected [Gladney 1998]; how users might inspect and edit protection rules [Walker 1998]; how protection rules can record for future years the terms and conditions for each property [Alrashid 1998]; transmitting rule sets from where they are generated to where they are needed [Ciccione 1996]; efficient payment mechanisms [Herzberg 1998]; trustworthy identification of who is generating a rule set (authentication), providing a document, or requesting one; how properties can be bundled for distribution with first-rate protection against many different kinds of misuse [Lotspiech 1997]; and so on. The current article makes a start towards describing how these proposals could be combined.
Until now, each of our Safeguarding ... articles has also described work complete to at least a prototype and pilot implementation. The current article shifts from this retrospective approach to a prospective one, considering modest and feasible next steps.
We are forced to reconsider what might be a controversial issue, personal computers as so-called "trusted systems". We believe that what has been widely publicized under this rubric is not only a repetition of old work, but also impractical today for reasons similar to those which caused it to be abandoned 15 years ago.
In fact, one value of technological aids is to provide mitigations for mistrust, augmenting legal, contractual, and social pressures by making cheating difficult and forcing cheaters to take overt steps which remind them of property rights and create evidence of violations. There is another practical value to the work we are about to describe: although the terms and conditions for each work might be simple, the aggregated terms and conditions of millions of works held for decades -- often beyond the job tenures of the individuals who negotiated for each work -- constitute an administrative nightmare that digital storage, communication, and analysis go a long way towards relieving. What we describe are essential elements of larger complete solutions.
Languages Expressing Usage Terms and Conditions for Intellectual Property
We need to represent terms and conditions in at least three domains: on screens in a style that administrators and end users can edit, understand, and analyze with a minimum of prior training or "help" text; in databases made reliably durable for survival over decades and longer; and for transmission among heterogeneous computing systems, i.e., supporting "open" systems so that software consumers have the benefit of multiple technology sources.
In what follows, we use language somewhat more broadly than some readers may be accustomed to. Information representation on a screen together with patterns of interaction, considered together with the interpretation of their meanings, is language. Database tables together with programs to interpret them and to map to/from other representations are language expressions.
These languages could be different -- in fact, it is best to make them so. For example, the best storage representation is one that allows the administrative data to be reliably preserved for many years; this can be done at low cost only by holding the information in a database used by other applications -- we strongly favor relational database technology. In contrast, the transmission format must be linear, which could be simply a linearization of the database format. And finally, the external language should be whatever is best for human comprehension and convenience, with minimal compromise for easy programming. We have three candidates from three sources that began their work independently of each other.
The first comes from James Barker and his colleagues at Case Western Reserve University [Alrashid]; this work includes a database representation [Barker1995], defined as a set of relational database tables and their interpretation. The basic tables and their columns have names as shown in the following table. Although space does not permit a careful description of the language rules and interpretation, it is, in fact, simple enough for the reader to infer what can be expressed and for the developers to extend to anything needed for environments beyond those of the CWRU prototypes.
Schema of CWRU Permission Manager Base Tables Table Column Names Billing Licensor ID, User Email ID, Holding ID, Date of Use, Time of Use, Rule Identification Number, Category of Work Code, Title of Work, Use Description, Charges Incurred, User ID, Last Name, First Name, Middle Initial, Name Prefix, Name Suffix, Street Addr - Linel, Street Addr - Line2, City, State or Province Code, Zip Code, Country Code, Phone Number, FAX Number, Language Code Element
PermissionsHolding ID, Element ID, User Category Code, Use Type, Rule Type, Element Rate Type, User ID, Rule ID, Organization Category, Element Major Type, Element Minor Type, Internet Address Profile Code, Transmission Profile Code, Protection Profile Code, Processing Profile Code, Percent Excerpt Limit/Year, Percent Excerpt Limit/Term, Rule Begin Date, Rule End Date, Element Rate, Maximum Concurrent Users, Language Code Elements Holding ID, Element ID, Element Description, Element Major Type Code, Element Minor Type Code, First page # in element, Number of pages in elem, Disc # w/in disc set, Track # on the disc, Length of performance, Language Code Holding
PermissionsHolding ID, User Category Code, Use Type, Rule Type, Holding Rate Type, Rule ID, User ID, Organization Category, Element Major Type, Element Minor Type, Internet Address Profile Code, Transmission Profile Code, Protection Profile Code, Processing Profile Code, Percent Excerpt Limit/Year, Percent Excerpt Limit/Term, Rule Begin Date, Rule End Date, Holding Rate, Maximum Concurrent Users, Language Code Holdings Holding ID, License Agreement ID, Copyright Effective Date, Copyright Expiration Date, Title of Work, Category of Work Code, Number of Elements, Creator ID, Work Order ID, Language Code Licence
Agreement
PermissionsLicense Agreement ID, User Category Code, Use Type, Rule Type, License Rate Type, Rule ID, User ID, Organization Category, System Major Type, System Minor Type, Internet Address Profile Code, Transmission Profile Code, Protection Profile Code, Processing Profile Code, Percent Excerpt Limit/Year, Percent Excerpt Limit/Term, Rule Begin Date, Rule End Date, License Rate, Maximum Concurrent Users, Language Code Licence
AgreementsLicense Agreement ID, License Agreement Type, Licensor ID, License Description, Effective Date of License, Expiration Date of License, Copyright Notice, Language Code Licensor
PermissionsLicensor ID, User Category Code, Use Type, Rule Type, Licensor Rate Type, Rule ID, User ID, Organization Category, Licensor Major Type, Licensor Minor Type, Internet Address Profile Code, Transmission Profile Code, Protection Profile Code, Processing Profile Code, Rule Begin Date, Rule End Date, Licensor Rate, Language Code Licensor
ProfilesLicensor ID, Licensor User ID, Licensor Email ID, Licensor Organization Name, Licensor - Last Name, Licensor - First Name, Licensor - Mid Initial, Licensor Name Prefix, Licensor Name Suffix, Licensor Address - Streetl, Licensor Address - Street2, Licensor Address - City, Licensor State/Province, Licensor Address - Zip Code, Licensor Country Code, Licensor Phone Number, Licensor FAX Number, Contact User ID, Contact Email ID, Contact Last Name, Contact First Name, Contact Mid Init, Contact Name Prefix, Contact Name Suflix, Contact Address - Streetl, Contact Address - Street2, Contact Address - City, Contact State/Prov, Contact Address - Zip Code, Contact Country Code, Contact Phone Number, Contact FAX Number, Agent User ID, Agent Email ID, Agent Last Name, Agent First Name, Agent Mid Init, Contact Name Prefix, Contact Name Suffix, Agent Address - Streeti, Agent Address - Street2, Agent Address - City, Agent State/Prov, Agent Address - Zip Code, Agent Country Code, Agent Phone Number, Agent FAX Number, Language Code System
PermissionsUser Category Code, Use Type, Rule Type, System Rate Type, Holding ID, Element ID, Rule ID, User ID, Organization Category, Element Major Type, Element Minor Type, Internet Address Profile Code, Transmission Profile Code, Protection Profile Code, Processing Profile Code, Rule Begin Date, Rule End Date, System Rate, Language Code User
ProfilesUser ID, User Email ID, User Last Name, User First Name, User Middle Initial, User Name Prefix, User Name Suffix, User Organization ID, User Address - Streetl, User Address - Street2, User Address - City, User State/Province, User Address - Zip Code, User Country Code, User Phone, User FAX, Language Code Not shown are a larger number of administrative, logging, and support tables. The support tables are key to what the CWRU RightsManager System allows; the values in columns of the basic tables shown are not restricted by software, but rather by administrators' entries in support tables; this permits tailoring to any installation's needs together with validity checking of permission table entries.
A second language, for transmission of the same rights management information, has been outlined by a team at the Xerox Corporation [Stefik 1997a, Stefik 1997b]. This is Xerox's DPRL (Digital Property Rights Language) [Ciccione 1996]; the example immediately below hints at its origin in artificial intelligence work. We could use this linear language to carry terms and conditions from content repositories S to content users U as needed by the network configurations discussed below.
(Work: (Description: "Title:'Fanciful' Author:'I.A. Fancy' Copyright:'I.A. Fancy'")
(Owner: "J Books, Inc.")
(Rights-Group: "Distributor" (Comment: "Rights limited to licensed distributors")
(Bundle:(Access:(Security-Class:5) (User-Authorization: "IDG Books Worldwide")))
(Copy: (Access (Fee: (Ticket: "IDG Inventory 12345")))
(Play: ) )(Rights-Group: "Consumer" (Comment: "Rights for any purchaser")
(Bundle:(Access: (Security-Class:3)))
(Copy:(Next-Copy-Rights: (Delete:"Distributor) (Fee:(Per-Use:10)(To:"Account IDG35")))
(Play:(Fee:(Metered:(Rate: .09)(Per: 1:0:0)(To:"Account IDG36")))
(Delete:(Comment:"This right is unrestricted"))
(Transfer: ))))A more recent alternative linear language is XML; we need to consider this because it seems about to become the popular choice for Web documents, and also because there is a proposed W3C XML standard.
A third language provides our preferred human interface; also coming from an artificial intelligence tradition; it is Adrian Walker's Internet Knowledge Manager (IKM) [Walker 1998]. It is the best candidate we know that:
- allows human beings to understand and write rules
- that can interface transparently with relational databases; and
- permits people to ask not only what the permissions and prices of access to a holding are, but also to inquire what instances of general policy rules were used to find the answer. For example, this is of interest when pricing is dependent on factors such as organizational affiliation and prior purchases.
A Web-friendly IKM implementation is freely available for readers' inspection and experiments.
In a session with the IKM, one uses an ordinary Web browser to write agents, and also to run them. In doing this, one can make use of a library of agents that have already been written, for business subjects such as insurance, international transfer pricing, and so on. Here is an outline of an example in which a distributor gets a discount from a publisher, based on the volume of sales of multilayer documents. We first write a table saying how a document is made up of other documents.
Figure 1: A Simple IKM Table of Documents and Their Components In the table, the Web Encyclopedia has a component that in turn has a subcomponent. To collect all its components we write a general rule like this.
Figure 2: An IKM Rule about the Subcomponents of a Document After writing some more tables and rules, we can ask what discount a trader called NetVidStore got in 1997. Answer is a table like this.
Figure 3: An IKM Answer Table from the Discount Agent Even in a simple example like this, it's good to be able to see the reasons for an answer. The IKM provides an overview like this.
Figure 4: The Main Reasons for an IKM Answer and we can drill down into more detailed reasons if we so wish.
You are invited to look at the full example, called Market-1, and also to run it
The authors of these prototypes have examined each other's work sufficiently to be confident that the needed translators will be easy to build. Why have we not already built them? Although some big publishers have vigorously urged the need for tools to store, audit, and manage their contracts with authors, photographers, and other original sources and similar relationships with their customers, none of these publishers has yet been ready to deploy a pilot to scale. We are leery of building something without a committed user community, because software built on speculation so often misses the mark.
Trust Management Involves at Least Three Administrative Domains
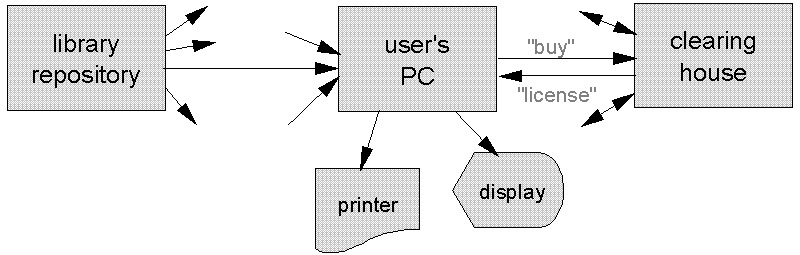
We know of three practical network configurations for automated distribution of valuable intellectual property: (1) publishers' repositories delivering under contract to libraries which provide access to limited communities; (2) publishers delivering massive encrypted content to potential end users who negotiate with clearance centers for access for selected small subsets of the content; and (3) a variant of the second scenario in which the user's workstation can view, at most, incomplete works locally, but render full works on protected terminals or printers.
The first arrangement was explored by IBM and ISI (Institute for Scientific Information, Philadelphia) in a dozen customer pilot installations [Choy 1996]. Scientific, engineering, and medical periodicals are mostly sold in subscriptions to libraries, which provide access primarily to limited communities (e.g., the members of a university), but extend limited access to larger communities (e.g., anyone who goes to the library building). We discovered that publishers cautiously accept the digital distribution layout depicted in Figure 5, with the library delivering limited and tracked amounts of in-the-clear content to end user workstations. Its attractions include immense performance improvements for large user groups distant from their libraries, easy protection of the anonymity of individual readers, single points of authentication for the thousands of users of each of many (university) libraries, and emulation of the common practice of institutional subscriptions to periodicals.
In this network layout, the manager of the publisher's or distributor's repository, Simon Supplier, delivers to Linda Librarian, or makes accessible for rapid download, all volumes of each subscribed periodical. Linda publishes her library catalog and enables every Ulrich User in her community for download of individual pages or individual articles. Simon, Linda, and Ulrich each accept this scenario, without necessarily being delighted, because it enables workable compromises: Simon and Linda each want the budgeting predictability of annual subscriptions; Simon can shift the responsibility of limiting access to a contractually-defined community to Linda, who is incented to comply both because universities intend to be honorable and because she does not want to risk loss of license to the materials; Linda further gets the ability to protect her readers' privacy; and Ulrich gets access to what he needs. Because of the nature of the material (each individual article is of interest only to a small number of scholars), and because violations can readily be detected and traced, Simon is not greatly worried by the possibility that Ulrich will violate "fair use" by wide distribution of licensed content.
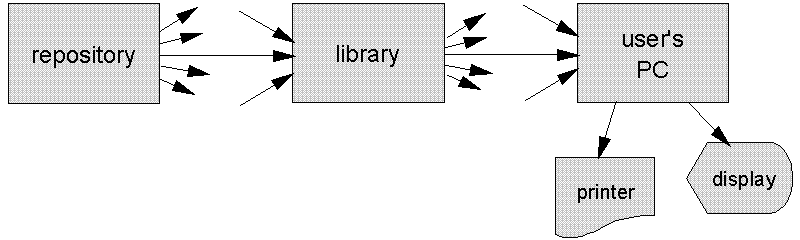
Figure 5: Library redistribution of publisher's content Of course publishers also want to distribute both subscriptions and individual content elements directly to end users for money or other considerations. Figure 6 suggests how this is enabled by our previously described Cryptolope (TM) technology [Lotspiech 1997]. Simon packages each attractive set of materials as a set of files, each encrypted under a different key; he further includes descriptive and promotional material in the clear, a statement of terms and conditions both in the clear and encrypted, a bill of materials, and an encrypted file of the prior encryption keys. The master key for this data set of individual document keys is either the public encyption key of a clearance center (Simon would need to provide such a key file for each potential clearance center) or a secret shared with clearance centers by an independent channel.
Ulrich decides from the promotional material and the clear-text terms and conditions which portions of a package he wants to buy, and sends to a clearance center this information together with the encrypted terms and conditions, the encryption key files, and whatever information about himself will be needed to check authorization, doing so under the public key of the clearance center. The clearance center checks whether what the information owner demands is satisfied, forwards bookkeeping entries as needed, and returns to Ulrich the encryption keys of the sections he has purchased, doing so under Ulrich's public key.
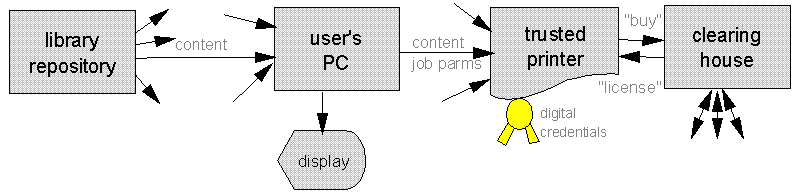
Figure 6: Cryptolope delivery with delayed purchase by information consumer A third layout, made feasible by the advent of printers with sophisticated embedded computers (and in the future, other presentation devices), might be attractive to large libraries (Figure 7). It is made practical by the willingness of content providers to enter trust relationships with university and public libraries, which would manage the printers in controlled environments (e.g., behind the counters of a circulation desk).
Figure 7: Copying limited by a Trustworthy Intelligent Print Server (in this layout, the clearing house could be packaged as part of the printer) It will often be inconvenient to package very large materials (e.g., feature-length movies, large scientific files) or sessions of indeterminate length (e.g., interactive consulting services mediated by digital communications) within Cryptolopes. It is, in fact, sufficient to send the administrative information in a Cryptolope, together with whatever addressing and other information Ulrich would need to access the large objects directly. After the administrative checks are made for such a session, the networked systems can choose and set up the most efficient channel between the repository and the printing or display device. This would work in any of the layouts shown.
The above schemes require each clearinghouse to receive secret information from each repository whose offerings it will mediate. No confidential delivery channels are shown because public key cryptography can hide secrets in the depicted channels.
What makes each layout shown attractive is the willingness of content providers (publishers, movie studios, various kinds of distributors) and institutional libraries to enter into predictably-priced agreements to supply content from each information resource to large numbers of end users. Such agreements are usually explicitly or implicitly contractual, with defined penalties for failures to perform. Similar agreements directly between each of thousands of providers with each of millions of recipients would be impractical and often inconvenient. Note that each network configuration requires at least three processes: an information source, a personal environment, and a clearing house.
Convergence of Access Control and Permission Management
The reader who compares the CWRU permission management database schema above schema in access control subsystems [Gladney 1997] will see similarities. These suggest that access control and permissions management might be made to grow together. As access control is enriched by finer granularity for object-oriented programming, delegation of privileges for office environments, more flexible grouping of users and privileges based on organizational affiliation rather than directly on user identification, and privileges sensitive to environmental circumstance (e.g., time of day, funds availability), the similarity of the supporting databases will increase. We intend to investigate whether this convergence is as attractive as it superficially seems.
Trusted Systems? Trustworthy Services Belong in Glass Houses
We encounter colleagues who are not directly involved in this kind of research who project unrealistic expectations onto the technology. At least some of the publicly available literature (see, for example, [Stefik 1997a, Stefik 1997b]) seems to fuel these fancies -- although the unpublished white papers and technical discussions may have moved beyond the information contained in the publicly accessible record. Nevertheless, the published material is unfortunately incomplete on critical points: what trust is to be held by whom in whom else, what attributes a system must have to be trustworthy, and what technical means can realize such attributes reliably. Since the published writings are incomplete on these points, we must infer what we can from the available articles in Scientific American and the Berkeley Law Review and then relate that to the best available prior work, [Weingart 1987] and [White 1987], as well as some 1998 IBM work which we learned about just as the final drafts of this article were being edited.
The simple inferences to be drawn from this research is that notion of trust is the same as what we understand from common usage in natural language. Specifically, what is called for is:
- that what is to be trusted is that valuable documents are printed only if specifically stated conditions, including payments required, have been satisfied
- that copying is limited to bounds which may demand destruction of the copy instances in one system when copies are forwarded to another system; and
- that technical means to enforce such compliance are known.
Further, that personal computers and workstations will achieve such means of enforcement is implied by examples in pictures and text in the Scientific American article [Stefik 1997b] from which much of our understanding of the "trusted systems" approach is based (absent other sources of information). We argue below that little, if any, of this is practical, because:
- trust is limited to human beings, but may be extended to include corporate entities;
- trust can be extended to inanimate systems only indirectly and cautiously; and
- such systems do not include personal computers or workstations today and will not, we believe, soon do so.
The notion of trust antedates any digital system. Is there is a reasonable extension to inanimate systems? Human trust relationships come into existence only when one individual knows another sufficiently to be confident that some limited responsibility will be faithfully discharged (e.g., that my neighbor's daughter, whom I have known for 5 years, is trustworthy as a baby sitter) or that some defined risks will be avoided (e.g., that my son is a skilled and careful driver who will avoid damage to my new Volkswagen). In most cases of trust conferred, there are adverse consequences to a breach of trust; these may be explicit but are often implicit (if the babysitter ignores my wailing child, I will probably not employ her again, and I tell my son that if he misuses the automobile, I will not lend it to him again). Trust relationships are extended from individuals to corporate entities by agreements made with human agents of those corporations and tend to be more explicit both in their scopes and their damage commitments than are those between individuals, i.e., explicit or implicit contracts are frequent when the trusted entity is a corporation.
We know no sensible and economic way to extend such notions to computing or communications systems, unless "system" is construed to include the human beings who manage the machinery -- a construction which is neither conventional nor voiced by the "trusted system" articles already cited. Attempts were made 15 years ago to enforce outside rules with workstation components [White 1987]. Their authors decided such efforts impractical then, and continue today to stand by their conclusions; we'll summarize the specifics below, and direct the reader to some continued consideration of the conundrum.
One problem is that we must make it possible, in advance, to know that a remote target machine managed by someone else truly satisfies certain attributes, e.g., that it contains a certain kind of security coprocessor with appropriate installed software, and that these have not been modified or bypassed by known or unknown people. Parts of this problem have only recently been addressed by Smith and colleagues [Smith 1998], who discuss the following scenario:
Suppose Sam develops and sells some rights management software for our secure platform, and Alice and Bob are (distributed) participants. If Alice trusts:The Cryptolope-exploiting network layouts we suggest above are made practical by agreements between content providers and enterprises which run library centers, protected printers, or clearance centers. The number of such enterprises will be 100- to 10,000-fold smaller than the number of individual users; each enterprise will be motivated strongly to honor commitments; and each also has the ability to purchase and manage relatively sophisticated machines in "glass house" environments. Such characteristics are unlikely for individuals, as is evidenced by the very large numbers of software copies installed out of licence. Like the software industry, intellectual content providers will make some offerings available in the clear to end users on their own workstations, but will do so not out of trust but rather based on market estimates which take into account massive unlicensed use.then she can always distinguish betweenthat public key crypto works that IBM builds and certifies only bona fide devices that the certification Alice has in hand truly comes from IBM that Sam's software behaves as Sam alleges even ifa message from Sam's program, running on an untampered device at Bob's site and a message from a clever adversary Alice, Bob, and Sam have never met the adversary might be using Sam's software on a tampered device, or other software on an untampered device there are no "trusted couriers" or "trusted security officers" anywhere. Returning to the possibility of improving the situation by some device built into personal computers to enforce the conditions specified by content providers, we note that a device would have to include a hardware component, because software is readily bypassed or substituted. A practical fact is that this particular horse has long ago escaped the barn. 100,000,000 personal computer owners will neither pay for a hardware addition that inhibits freedoms they currently have nor permit enforced installation of new devices. They also will not give up print redirection which currently permits them to capture the unencrypted form of any file at all for any use they subsequently choose.
Even if this horse had not already escaped, it would have been impractical to build a strong barn. This is what Weingart and White attempted; they found that the PC builders were unwilling to install any device which increased their manufacturing cost if the device did not benefit the immediate customer. This is because Ulrich User will refuse, as a matter of principle, any unlegislated taxation intended to benefit Simon Source. The only possibility for "trust technology" is that it is legislated, as has been attempted from time to time for music reproduction devices, or agreed to privately by commercial enterprises. For example, as part of deploying DVD technology, a consortium of movie studios, consumer electronic companies, and computer hardware companies are trying to enforce constraints by licensing device producers.
Specifically, about 15 years ago, an IBM research team [White 1987, Weingart 1987] designed a personal computer security coprocessor, called ABYSS, and an ABYSS operating system with security kernel primitive operations which could enforce constraints called for by permissions languages. They packaged it to resist code substitution and other tampering. Although the 1985 projected incremental cost of ABYSS enablement was under $10, the IBM Personal Computer product groups refused to include the technology because it would increase prices for PC purchasers without increasing their direct benefits.
The idea of coprocessors whose owners were constrained in clearly articulated and certified ways from certain explicitly defined changes [Yee 1994] has not been abandoned in the IBM T.J. Watson Research Center. Some ABYSS design ideas have evolved into more expensive security processors for "glass house" systems, such as the IBM 4758 Crypto Controller(TM), an application which makes sense because managers of corporate computing servers have economic incentives (contract obligations, loss of essential licensing, reputation for integrity) to enforce access control policies. The embedded processor is in fact a much more capable engine than ABYSS, being an Intel 486 (TM) with 2 Mbyte of storage, of which a small portion is protected against unprotected change. Just in case a way can be found to motivate personal computer users to purchase and install security coprocessors (e.g., by persuasively cost-saving applications made available only by way of PC's with such hardware installed), work continues to define and harden such machinery. Being pursued are engineering modifications and repackaging of evolutions of what went into the IBM 4758; even assuming that persuasive applications are found, the cost seems to us more than an order of magnitude too high in the current embodiments whose protection is good and whose power is sufficient for the kinds of applications conjectured by Smith and colleagues [Smith 1998] (commercial applications, rather than information distribution applications).
We re-emphasize that we cannot make a contract with a machine -- a contract in which the machine undertakes to execute or to avoid executing each of a list of carefully described actions.
The questions of trust debated above were the topic of a panel and public discussion in the May 1998 IEEE Symposium on Security and Privacy. Our perception is that both the panelists and the 300 people in the room agreed that trust is a human attribute without any direct machine analogue. Even if we construe "system" to include the individual or organization that ensures that the machinery complies with agreed-upon rules, the notion of "trusted system" is weak because the phrase implies something about the attitude of the people giving trust. For these reasons, we would prefer at most to consider the feasibility of practical "trustworthy services" in which legal or contractual constraints figure as part of enforcement of explicitly stated rules and limitations.
Returning to the DVD case, the above chicken-and-egg deadlock can be addressed if the market is being created from scratch. DVD players are a case in point. Each player (or "movie-compatible" PC) contains some logic to make it difficult, but not impossible, for the casual consumer to copy a DVD movie. The manufacturers are not legally compelled to put this logic in their boxes. Instead, the movies are scrambled, and to learn the scrambling secret, the manufacturers sign a licence by which they are contractually bound to certain restrictions. (Of course, they sign the licence, because a DVD player that cannot play Hollywood movies would have a negligible market.) Although the situation is still somewhat murky, it is possible that the DVD descrambling licence may become the initial domino by which other copy protection schemes become deployed: for example, protection on the "Firewire" (consumer digital video connection) and copy watermark detectors in recorders and players. The dominos may fall as follows:
- DVD players are required by descrambling licence to put copy protection on the Firewire bus.
- Digital TVs and VCRs will want to connect to DVD players and will need to get the licence for the Firewire copy protection scheme.
- All licences will require that watermark detection logic exist to help find and block illegal copies.
The concern above is for situations in which content recipients have little motivation for observing constraints wanted by content owners. For this situation, the DVD example illustrates what might be possible when there is the luxury to design the system from scratch -- as might happen if the PC technology ground rules suddenly change. However, in today's PC arena, we view the idea of "trusted systems" with hearty skepticism. For situations in which content recipients share objectives with content owners, as is discussed for limiting children's access to pornographic materials, PC-enforcement is plausible. Blaze [Blaze 1997] discusses mechanisms, trust models, and an implementation for such cases.
Sandbox Protection for End Users
The sections above are mostly concerned with protecting the interests of copyright holders. What about the interests of personal computer users? Solutions based on "trusted systems" create risks for them also, if such solutions require their machines to execute programs written by content providers or their agents. It is not easy to protect end users from such risks. This is because a marketplace with thousands of providers and millions of consumers would probably be administratively efficient only if each producer loaded into each actual consumer's machine the software required to interpret and enforce the kinds of terms and conditions suggested by the language examples above. If this is done, for user safety, the personal computers must somehow fence in the execution of the imported code so that it cannot capture control of the entire machine. Such a fencing is sometimes called a "sandbox" [Anderson 1972].
We'll discuss the feasibility of sandbox architecture after disposing of the only alternative we know of, trustworthy security kernels. The hope is similar to that suggested by "trusted systems", except that the sought-for protection would be for the personal computer user rather than for the content provider. Presuming that a technical solution could be devised, this would have to be tested and demonstrated in a sufficiently public way or with sufficient promises of indemnification to consumers suffering invasions with breach of the solution. Without such measures, rational consumers would not buy and install the technology. Assuming that all this could be accomplished, the technology would have to be deployed into an economically significant fraction of the installed or newly installing personal computer population. We understand the infrastructure and delays such certification would require; the model is the testing required for various levels of computer security certification by the U.S. Department of Defense; it is expensive and introduces a delay of several years. Such challenges are so high that no manufacturer is following this course for commercial personal computers, or even considering it as far as we know. We believe combined hardware/software protection can make economic sense only for entirely new business segments, as illustrated by the above discussion of DVD.
Since such trustworthy security kernels seem impractical, significant effort is currently being expended on various software-only "sandbox" possibilities. Currently, attention is focused on Java(TM) as a cross-platform program transmission vehicle. That accepting programs from unknown and unpredictable sources is very risky is illustrated by work which has recently identified a Java security exposure -- a way to use the subroutine return protocol [Malkhi 1998] -- and is proposing a change to Java virtual machines to close this loophole. (It is in the nature of such loopholes that a malicious application program can capture control of the computer and can do whatever damage it's author wants, without the machine owner being aware that it is happening until it is too late.) I.e., sandbox protection for personal computer users is being looked into, but it is a difficult challenge. Of course, it can be solved with computer operating systems similar to those on "big iron", but this is not a current prospect.
Questions of Public Policy and Law
The technical topics that are the focus of this paper lead directly to open questions of legal interpretation and policy -- questions that are being carefully considered in public discussions, in other articles, by legal, political, and economics scholars, and in some cases by legislative committees. We feel impelled to mention some of these topics, but will limit this to suggesting issues in which technical considerations intersect broader domains.
One such is the meaning of "copy" in interpreting current copyright law and suggestions how current law might need to be refined or extended to cope with the pliability of digital representations and derivative works. Stefik [Stefik] touches on some aspects, calling for enforced rules about how many copies of a work a licensee can create, but does not settle a more fundamental concern. It is not clear whether or not the copyright law sees as copies the several instances computers make today in order to make any work accessible to a single reader. (Current U.S. copyright law defines a "copy" to be a physical or material object; this definition essentially appears in the Berne convention; some people believe that this definition has been superceded by practice.) A possible remedy is to define different forms of "copy" and to formulate rules distinguishing among these kinds, e.g., a cached copy would be different from a screen image copy, and both would be different from a print copy. (This distinction was suggested to us by Professor Pamela Samuelson of University of California, Berkeley, but has surely occurred to many people.)
A controversial topic is inherent in packaging intellectual property cryptographically. In the context of a recent public panel debate, one participant took strong exception to the notion, on the grounds that it will deny "fair use rights of access" to scholars. Although we are sympathetic to his motivation, the political value of open information, we are also skeptical of his case in current law. As we understand the U.S. copyright law, "fair use" is an effective defense against an action claiming copyright violation. However, "fair use" in no way compels any owner of content to make it available to anyone, or to make it as available to one person as he has made it to another. We hasten to say that our point here is not to argue one side or another of this important question, but rather to illustrate how intimately the technology is intertwined with difficult questions of law and public policy.
This last question may lure some civil liberties extremists into an absurdity. We would not be surprised to see some lobby simultaneously insisting that governments should not limit private use of cryptography, as some police and defense lobbies propose, and also that intellectual property owners should not be permitted to use encryption to deny access to their holdings. Again, our purpose here is not to suggest what makes sense, but to illustrate that we are faced with policy choices -- choices that will probably be settled differently in different jurisdictions.
Another controversial topic is the doctrine of "first sale", which holds that once a publisher has sold a copy of a work, the current owner of that copy can lend or give it to anyone else without permission or further payment to the publisher. Although DPRL provides language to express transfer, no reliable implementation has been built. Publishers are understandably reluctant to agree that the notion of "first sale" of physical copies has a digital equivalent.
Such questions are important enough, urgent enough, and difficult enough that the U.S. National Science Foundation has commissioned a U.S. National Research Council-managed Study Committee for Intellectual Property Rights in the Emerging Information Infrastructure. Individual members of this committee would like to hear carefully considered opinion on any topic within the committee scope.
Conclusions
Our objective has been to show likely direction in which previously discussed intellectual property protection technologies will be knit into complete solutions. Among other things, languages and their interpreters are needed to express, record, and administer whatever rules are chosen. For situations in which information providers and information users have conflicting economic motivations, practical enforcement scenarios require three (or more) processing environments for every transaction: a content originator's, an end user's, and a clearance center which could be folded back into the content originator's environment in some situations.
In contrast, we argue that it is not reasonable to expect to use personal computers to enforce content providers' interests as so-called "trusted systems". Further, we believe it misleads the public to refer even to clearance centers as "trusted systems"; to convey what useful function such machines and their human managers can provide, it would be better to call them "trustworthy services".
Processes and databases to record the rules for managing intellectual property and access control databases can be made to be similar. We believe these similarities will offer simplifications for both users and software providers. IBM work on a human-intelligible rules language with easy Web and database interfaces [Walker 1998] seems to us ready to deploy. What the transport language for rules should be is an open question; the momentum in the near future favors DTDs and interpreters for XML rule expressions.
We find it impossible to discuss rights management technology without encountering unsettled questions of policy. We have identified a few of these that are intertwined with network delivery of protected information; it will be possible to continue the technical development to accommodate some likely policy choices, but others will be beyond practical technical measures. It will be important for the technical and legal community to communicate to policy makers which policies can and cannot be effectively administered by digital computers, and which seemingly distinct policy objectives are, in fact, incompatible.
Acknowledgements
This article was made possible by conversations with many colleagues -- Jim Barker, John Hurley, Paul Karger, Steven Newell, Sean Smith, Adrian Walker, Steve White, and others -- who shared their deep understanding of the field, pointed us at the seminal works, and critiqued drafts of the article. We are also indebted for access to unpublished materials to Jim Barker and his CWRU team, to Mark Stefik and his Xerox colleagues, and to Adrian Walker.
Bibliography
[Alrashid 1998] Tareq M. Alrashid, James A. Barker, Brian S. Christian, Steven C. Cox, Michael W. Rabne, Elizabeth A. Slotta, and Luella R. Upthegrove, Safeguarding Copyrighted Contents: Digital Libraries and Intellectual Property Management, D-Lib Magazine, (April 1998).
[Anderson 1972] Investigating the sandbox approach was first suggested in James P. Anderson, Computer Security Technology, ESD-TR-73-51, Vol. II, pp. 58-69, (Oct. 1972) (HQ Electronic Systems Division, Hanscom Field, Bedford, MA).
[Barker 1995] J. Barker et al., RightsManager System: Permissions Manager Subsystem (Version 2 draft), from Library Collections Services, Case Western Reserve University, (July 1995).
[Blaze 1997] M. Blaze, J. Feigenbaum, P. Resnick, and M. Straus, Managing Trust in an Information-Labeling System, European Transactions on Telecommunications 8(5), 491-501, (September 1997).
[Choy 1996] D.M. Choy, J.B. Lotspiech, L.C. Anderson, S.K. Boyer, R. Dievendorff, C. Dwork, T.D. Griffin, B.A. Hoenig, M.K. Jackson, W. Kaka, J.M. McCrossin, A.M. Miller, R.J.T. Morris, and N.J. Pass, A Digital Library System for Periodicals Distribution, in Proceedings of ADL96 - A Forum on Research & Technology, Advances in Digital Libraries, IEEE Computer Society Press, Los Alamitos, CA, pp. 95-103, (1996).
[Ciccione 1996] B. Ciccione, K. Duong, S. Okamoto, P. Ram, X. Riley, and M. Stefik, The Digital Property Rights Language, private communication, (1996). Stefik includes a language sample.
[Gladney 1997] H.M. Gladney, Safeguarding Digital Library Contents and Users: Document Access Control, D-Lib Magazine, (June 1997). This is a synopsis of Access Control for Large Collections (ACM Trans. Info. Sys. 15(2), 154-194, (1997)), which shows the database schema alluded to.
[Gladney 1998] H.M. Gladney, Safeguarding Digital Library Contents and Users: a Note on Universal Unique Identifiers, D-Lib Magazine, (April 1998).
[Herzberg 1998] A. Herzberg, Charging for Online Content, D-Lib Magazine, (January 1998).
[Lotspiech 1997] J.B. Lotspiech, U. Kohl, and M.A. Kaplan, Safeguarding Digital Library Contents: and Users: Protecting Documents Rather Than Channels, D-Lib Magazine, (September 1997).
[Malkhi 1998] D. Malkhi, M.K. Reiter, and A.D. Rubin, Secure Execution of Java Applets using a Remote Playground, 1998 IEEE Symposium on Security and Privacy, 40-51, (May 1998).
[Smith 1998] S.W. Smith, E.R. Palmer, S.H. Weingart, Using a High-Performance, Programmable Secure Coprocessor, FC98: Proceedings of the Second International Conference on Financial Cryptography. Anguilla, BWI, Springer-Verlag LNCS, 1998 (to appear). S.W. Smith, S.H. Weingart, Building a High-Performance, Programmable Secure Coprocessor, IBM Research Report RC21102, (1997).
[Stefik 1997a] M.Stefik, Shifting the Possible: How digital property rights challenge us to rethink digital publishing, Berkeley Technology Law Journal, 12(1), 137-159, (1997).
[Stefik 1997b] M. Stefik, Trusted Systems, Scientific American 276(3), 78-81, (1997).
[Walker 1998] A. Walker, The Internet Knowledge Manager: Dynamic Digital Libraries, and Agents You Can Understand, D-Lib Magazine, (March 1998). The Internet Knowledge Manager, and its Use for Rights and Billing in Digital Libraries. Proc First International Conference on the Practical Applications of Knowledge Management, March 1998.
[Weingart 1987] S.H. Weingart, Physical Security for the microABYSS System, Proceedings of the 1987 IEEE Symposium on Security and Privacy, Oakland, CA, pp. 52-58, (April 1987).
[White 1987] S.R.White and L. Comerford, ABYSS: A Trusted Architecture for Software Protection, Proceedings of the 1987 IEEE Symposium on Security and Privacy, Oakland, CA, pp. 38-51, (April 1987).
[Yee 1994] B.S. Yee, Using Secure Coprocessors. Ph.D. dissertation, Carnegie Mellon University, Department of Computer Science (1994).
Copyright and Disclaimer Notice
Copyright IBM Corp. 1998. All Rights Reserved. Copies may be printed and distributed, provided that no changes are made to the content, that the entire document including the attribution header and this copyright notice is printed or distributed, and that this is done free of charge. We have written for the usual reasons of scholarly communication. Wherever this report alludes to technologies in early phases of definition and development, the information it provides is strictly on an as-is basis, without express or implied warranty of any kind, and without express or implied commitment to implement anything described or alluded to or provide any product or service. Use of the information in this report is at the reader's own risk. Intellectual property management is fraught with policy, legal, and economic issues. Nothing in this report should be construed as an adoption by IBM of any policy position or recommendation.
The opinions expressed are those of the authors, and should not be construed to represent or predict any IBM position or commitment.
Top | Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editor
hdl:cnri.dlib/may98-gladney