|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Gordon Paynter, Susanna Joe, Vanita Lala, Gillian Lee |
![]()
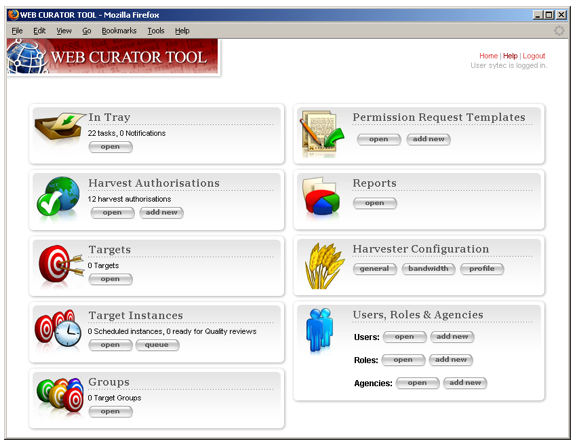
AbstractThe Web Curator Tool is an open-source tool for managing selective web archiving developed as a joint project between the National Library of New Zealand and the British Library. It has now been in everyday use at the National Library of New Zealand since January 2007. This article describes our first year of selective web archiving with the new tool. The National Library of New Zealand is reaping the benefits of the Web Curator Tool development and will continue our selective harvesting program with the Web Curator Tool for the foreseeable future. 1. IntroductionThe Web Curator Tool is a tool that supports the selection, harvesting and quality assessment of online material when employed by collaborating users in a library environment. It is used for selective web harvesting, where a subject expert identifies parts of or whole websites for harvest, usually in relation to a focused subject area or a significant event. The software was developed as a collaborative project between the National Library of New Zealand and the British Library, conducted under the auspices of the International Internet Preservation Consortium. The tool is open-source software and is freely available from the website at <http://webcurator.sf.net/> for the benefit of the international web archiving community. The National Library of New Zealand ("the Library") has used the Web Curator Tool as the basis of its selective web archiving programme since January 2007. During the first year a new version of the tool was developed that has allowed us to dramatically increase and improve the quality of our harvesting activities, and to perform two event harvests. This article describes our experience using the Web Curator Tool in a production environment. The next section of the article provides background about the Library's web harvesting activities and the development of the Web Curator Tool. The following sections summarise our experiences with the software, and we conclude by describing an event harvest performed with the software. 2. Selective web archiving at the National Library of New Zealand2.1. MotivationThe National Library of New Zealand has a legal mandate, and a social responsibility, to preserve New Zealand's social and cultural history, be it in the form of books, newspapers and photographs, or of websites, blogs and YouTube videos. Increasing amounts of New Zealand's documentary heritage is only available online. Users find this content valuable and convenient, but its impermanence, lack of clear ownership, and dynamic nature pose significant challenges to any institution that attempts to acquire and preserve it. The Web Curator Tool was developed to solve these problems by allowing institutions to capture almost any online document, including web pages, web sites, and web logs, and most current formats, including HTML pages, images, PDF and Word documents, as well as multimedia content such as audio and video files. These artefacts are handled with all possible care, so that their integrity and authenticity is preserved. The public benefit from the safe, long-term preservation of New Zealand's online heritage is incalculable. Our online social history and much government and institutional history will be able to be preserved into the future for researchers, historians, and ordinary New Zealanders. They will be able to look back on our digital documents in the same way that the New Zealanders of today look back on the printed words left to us by previous generations. 2.2. Harvest historyThe Library has had a selective web archiving programme in operation since 1999. Until the end of 2006, the Library used the HTTrack Website Copier software1 to harvest materials, and the Library tracked them in a MARC-based selection and acquisition database. The HTTrack software left the Library with a backlog of harvested material that could not be archived for long-term preservation. A data migration program is now underway to convert this material into a format suitable for archiving. 2.3. The Web Curator ToolThe Web Curator Tool supports a harvesting workflow comprising a series of specialised tasks: selecting an online resource; seeking permission to harvest it and make it publicly accessible; describing it; determining its scope and boundaries; scheduling a web harvest or a series of web harvests; performing the harvests; performing quality review and endorsing or rejecting the harvested material; and depositing endorsed material in a digital repository or archive. Figure 1 shows the main menu of the tool.
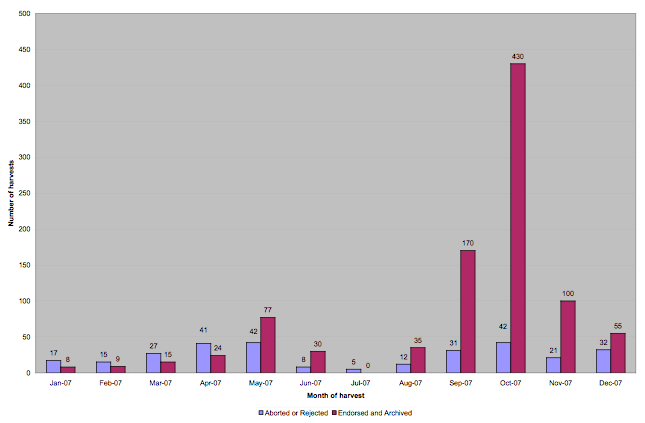
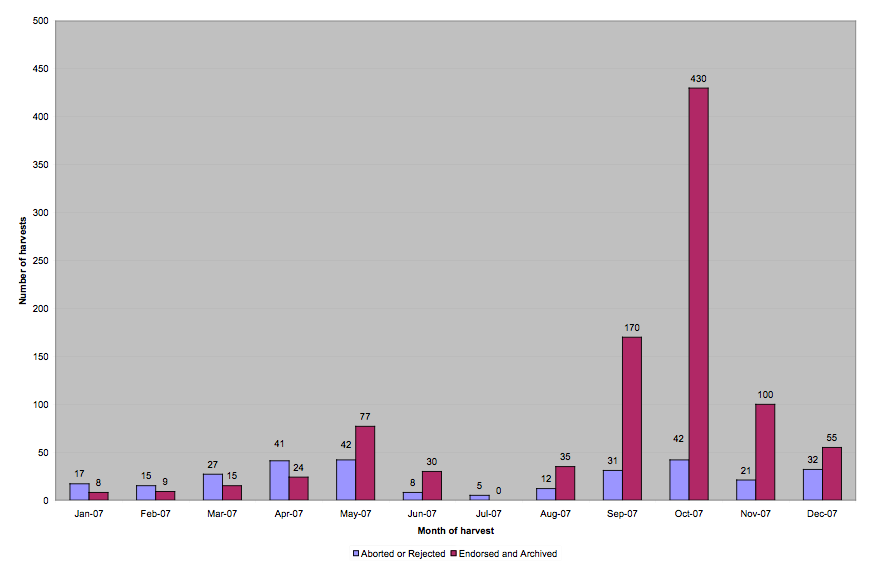
Most current web archiving activities rely heavily on the technical expertise of the harvest operators. The Web Curator Tool, on the other hand, makes harvesting the responsibility of users and subject experts (rather than engineers and system administrators) by handling automatically the technical details of web harvesting. The tool is designed to operate safely and effectively in an enterprise environment, where technical support staff can maintain it. The Web Curator Tool is open-source software and is freely available from the website at <http://webcurator.sf.net/> under the terms of the Apache Public License. The website provides access to user manuals, mailing lists, screenshots, an FAQ, technical and administrative documentation, source code, bug trackers, and the Sourceforge project page. (Paynter and Mason (2006) describe the tool, and its development, in more detail in their 2006 LIANZA conference paper.2) 2.4. Staff and resourcesAt the National Library of New Zealand, the Web Curator Tool is the primary tool and responsibility of the e-Publications Librarians in the Alexander Turnbull Library. During 2007 the equivalent of 2.5 full time e-Selectors used the tool directly, managing all selection, harvesting, and quality review. However, the tool is tightly integrated with the Library's policies, workflows, telecommunications and support services, and affects a much wider group of staff. For example, the hardware and software are maintained by Technical Services and managed through their Helpdesk; cataloguing is carried out by Content Services; and the digital archive is maintained by the National Digital Library. The Web Curator Tool was designed to be integrated as tightly as possible with any existing enterprise systems. Our deployment uses the Library's standard hardware (Sun SPARC servers), operating system (Solaris), database (Oracle), web services (Apache HTTP Server and Tomcat), and user authentication service (Novell eDirectory). The production system is deployed across two servers, one for the core module and one for the harvester (configured to run up to eight concurrent harvests), and shares existing database and file servers with other Library systems. A separate test system is maintained with a similar configuration. 2.5. Level of harvestingFigure 2 shows the number of harvests performed by the Library in 2007. For each month, the purple bar shows the number of harvests that were not accepted into the archive. These were either Aborted (stopped before they could complete) or Rejected during the quality review stage because they did not capture some essential aspect of the website. The red bars show the number of successful harvests that have been archived in the Library's digital archive.
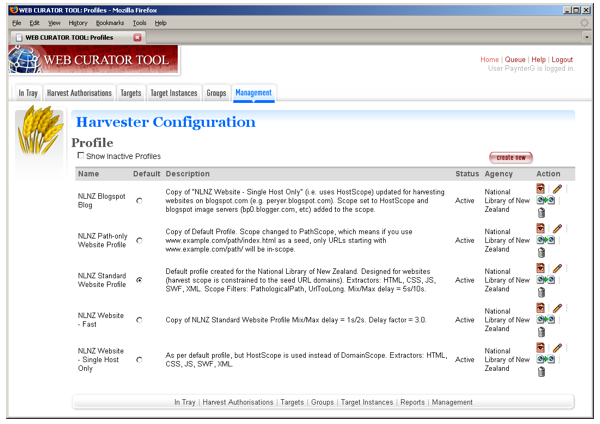
In total, 1,249 harvests were launched by our production system in 2007. Of these, 953 (76%) were successfully harvested, quality reviewed, Endorsed, and Archived. Of the remainder, 69 (6%) were Aborted during harvest and 224 (18%) were Rejected because they did not pass quality review. (The remaining 3 are awaiting quality review or collection scope decisions.) Three phases of harvesting are visible in Figure 2. The first is from January to May, while the e-Selectors used the Web Curator Tool version 1.1 in their harvesting activities. Harvesting was light in this period, peaking at 75 successful harvests in May, as the team built up experience with the tool and its workflows, and uncovered several issues with the early software. From June to mid-September the e-Selectors were asked to test version 1.2 of the Web Curator Tool, and therefore cut their regular harvesting activities back even further. The final phase of harvesting begins in mid-September, and shows a dramatic increase in harvesting activity. Several factors contributed to this increase, including the adoption of version 1.2 of the Web Curator Tool in our production system, a 50-fold increase in the Library's internet capacity (from 2Mb/s to 100Mb/s), the resolution of most workflow issues around harvesting and cataloguing, and the initiation of two event-based harvests (described below). As a result, almost half of the year's harvesting (by number of websites) took place in October alone. A welcome feature of this phase of operation is that while the number of successful harvests increased significantly, the number that were Aborted or Rejected did not. 3. Harvesting with Web Curator Tool version 1.1As the e-Selectors used the Web Curator Tool version 1.1 from January to May, they gained experience with the software and discovered several harvesting activities that had to be approached in a different way as well as several problems that needed to be fixed in version 1.2. This section summarises this experience; a more detailed description is available from the authors upon request. 3.1. Initial experienceThe most significant change introduced by the Web Curator Tool is that it stores harvested material in the ARC file format, which has preservation advantages but requires specialised software to mediate viewing and other quality review activities. This brought about a fundamentally new way for the e-Selectors to approach quality review. With this new style of interaction it can be difficult to tell whether quality issues are caused by shortcomings of the harvester or by inadequacies in the quality review tools. For example, if a reviewer opens a web page in the Browse Tool and it is displayed with a missing image, e-Selectors first have to determine whether the image is genuinely missing from the harvest, or whether it was harvested successfully but the browser is unable to display it. It quickly became obvious that additional training was required to support the staff in making these distinctions. Whilst the Librarians had considerable experience reviewing HTTrack harvest results, they did not know how to troubleshoot unsuccessful harvests in the Web Curator Tool. All the new harvest problems were recorded in an issues register, and it became obvious that the same types of errors were reoccurring. Consequently, a training session was held, and a diagnostics process developed and added to the Web Curator Tool manual. Another issue encountered in the first months was that it took time to develop a useful set of harvest profiles, particularly for blogs. Figure 3 shows the set of harvest profiles that were eventually created.
3.2. Harvest problemsThe following problems were encountered in version 1.1 and resolved in version 1.2:
3.3. Summary of experience with version 1.1Despite some limitations, the first version of Web Curator Tool was a vast improvement over the previous HTTrack tool. It was a significant milestone when we submitted our first harvested website to our digital archive. During the first year the Web Curator Tool performed 1250 harvests, and almost 950 of these were reviewed, endorsed and added to the archive. 4. Harvesting with Web Curator Tool version 1.2Web Curator Tool version 1.2.6 was deployed to production in the middle of September 2007, and it was used in the following months in two event harvests. It was replaced with version 1.2.7 (a bug fix release) at the end of October. 4.1. Harvest history toolOne of the areas in which the most progress has been made is that of quality review. The enhancements made to this area have dramatically improved the ease and effectiveness of quality reviewing, making the process faster and more proficient. The harvest history quality review tool has proven to be the most useful of the quality review enhancements. This tool lists all the harvests of a particular Target, with summary information like start date, data downloaded, URLs harvested and failed, elapsed time and current status. This is very useful as it consolidates much of the information needed throughout the quality review process. 4.2. Browse toolA simple yet effective change to the review interface was the addition of options for viewing a harvested site in the three different ways: viewing the currently harvested instance in the browse tool, viewing the live site, or viewing a previously archived version (at the Internet Archive or a local archive). These instances open in another tab or browser window, and allow the reviewer to compare a harvested copy to other versions of the site. Major improvements were also made to the browse tool, which allowed us to successfully browse and review many sites that were previously not viewable. There remain, however, a few unresolved issues. Rendering websites that use Javascript continues to cause problems, particularly reproducing the functionality of elements like drop-down menus, which can make harvested sites difficult to navigate. Harvesting stylesheets can still be problematic, though this is more often a harvesting issue than a review issue. Other outstanding issues include problems reviewing URLs with spaces (a deployment environment issue) and harvesting certain embedded background images. 4.3. Prune toolThe Web Curator prune tool was also updated, but the Library does not use the prune tool to alter websites, so it will not benefit directly from many of those changes. However, we have experimented with the tool, and while it can be very slow to use for large sites, the new view function of the Prune Tool proved very useful for selecting and viewing arbitrary files from the harvest. 4.4. Larger websites being harvestedIn the final months of the year, we noticed that our harvesting activities included larger and larger websites. The largest harvest completed and reviewed by the Library as part of the harvesting program was 21GB in size, though this was rejected after quality review. Several 10GB websites have been successfully harvested, reviewed and archived. As the size of the websites grew, e-Selectors came to rely more on custom profiles and on Profile Overrides, particularly exclusion filters that allowed e-Selectors to stop the harvester from gathering specific parts of websites. 4.5. Digital Asset Store deploymentA consequence of the increasing number and size of harvested websites was that the Web Curator Tool needed a larger Digital Asset Store (the temporary space used to store harvests while they are quality reviewed and before they are archived). This was a particular problem in October and November, because the number of websites selected, harvested and endorsed increased quite suddenly and consequently took much longer to catalogue, creating a backlog of material. As a result, the space allocated for the Digital Asset Store, which earlier had appeared quite generous, suddenly seemed very small indeed. As a result, a new, much larger disk was introduced for the Digital Asset Store, and reporting tools were supplied to allow the Librarians to monitor disk use continuously. This situation also exposed an issue in our interim digital archive, which shared disk space with the Digital Asset Store: under certain circumstances the fixity checks were not working! 4.6. CommunicationGood communication between the different Library staff affected by the tool is essential, but several gaps in communication have been identified since the Web Curator Tool was first used in production. Though some improvements have been made in version 1.2, many of the omissions have been addressed outside the tool by periodically generating reports from the Web Curator Tool database (the software documentation includes a full data dictionary). For example, a weekly report of endorsed harvests is sent to cataloguers to alert them to websites that need describing, and quarterly predictions of the number and size of web harvests are compiled by the E-Publications Librarian for Technical Services staff. When these have settled into a mature form, we hope to add them to the set of built-in Web Curator Tool reports. 4.7. Cataloguing workflow and accessWhile it is possible to use the Web Curator Tool to describe websites, it is Library policy to describe the Library's entire collection in its catalogue and to provide a link from the library catalogue record to digital items stored in the digital repository. (However, complex digital holdings such as serials and websites will not be accessible to the public until the National Digital Heritage Archive replaces our interim digital repository in 2008.) One drawback in searching the library catalogue for websites is the inability to fully reflect event harvesting since each website is catalogued individually. To address this issue, the British Library plans to develop a web interface tool that provides access to harvested material based on subject and event as an additional aid for users wanting to search specifically for websites. The Web Curator Tool concepts of Targets (individual websites) and Groups (collection of websites) make such an interface possible. We will follow the British Library's progress with great interest. 5. Local body election event harvestThe Library has previously undertaken event harvests of major sporting events (the America's Cup yachting) and elections (national parliamentary elections) using the HTTrack harvesting software. In 2007, the Library planned two further event harvests, which fortuitously coincided with the deployment of version 1.2 of the Web Curator Tool. Local government elections are a triennial event, and every local authority in New Zealand is required to hold an election of its members. The Library undertook a 12-week event harvest focussing on the 2007 Local Body Elections, starting in September. The Local Body event harvest was the first major event harvest using the Web Curator Tool, and it was also the largest yet attempted at the Library, with 238 websites selected. These sites included candidate and party campaign websites and blogs, all regional, city and district council websites, news sites, and general sites or blogs with content relevant to either the election or local government. Overall, a broad spectrum of websites was chosen that represented formal and informal commentary, with a wide geographical spread. All the selected sites were in scope of New Zealand's legal deposit legislation, so we did not need to seek explicit permissions to acquire them. The selected sites were prioritised to determine harvest frequency, and then a harvest schedule was designed to cover the key dates throughout the 16-week election timeline. The schedule was limited due to the large number of selected sites, and with manageability also being a primary concern due to limited staff resources, the small number of harvests ensured there would be sufficient time spaced between each harvest for 2 staff to complete the crawls and quality review processes. Another influence on setting the harvest schedule came from the different workflow practices now in place using the Web Curator Tool. In previous event harvests, a highly iterative harvest schedule was possible since quality review could take place after the completion of all the harvests; however, with the large number of selected sites in this event, this approach on the Web Curator Tool would have been both impractical and cumbersome. With the harvest schedule and period set, we created target groups using the system's Groups functionality. The selected sites were sorted into 36 groups determined by website category, or in the case of the council sites, broad geographical region. These groups were fairly informal since the primary use of groups in this event was to facilitate ease of harvest scheduling, not for logical grouping. Using Groups was also helpful in managing the workload amongst the team, and staggering the harvest by groups also permitted a degree of load balancing across the harvester hardware. The aim was to run the harvests in the evening; however, this was not always possible, even with eight concurrent harvesters running. Many scheduled harvests were queued for several hours before a harvester became free, but fortunately, long harvest queues did not create any issues, and with many of the sites being small, harvest queues did clear quickly. The system coped well with periods of intensive, prolonged harvesting using eight concurrent harvesters. Difficulties did arise when the crawls of the much larger-sized council websites coincided with a backlog in the interim digital archive of websites that were awaiting cataloguing prior to being archived. The result was a critical strain on disk space capacity, and since other areas of the Library shared the same storage facilities, this had potentially very serious repercussions. At one point we were forced to postpone harvesting for a time until sufficient disk space was available. Despite these later complications, the majority of the websites were harvested, quality reviewed, endorsed and archived successfully. At the end of the harvest schedule, over 600 website harvests had been endorsed or archived for this particular event, a significant achievement for the Library's web archiving program. In general, the Local Body Elections provided an important test case in event harvesting using the Web Curator Tool. We were able to schedule and manage a large event with ease on the system, and we gained useful experience in utilising features of the system that we had not had occasion to use before. More significantly, this event harvest demonstrated that the Web Curator Tool could successfully cope with the demands of web harvesting activity of a significantly increased size, and where areas requiring more scrutiny and monitoring were also highlighted, valuable lessons were learnt and experience gained. The 2007 Local Body Elections were followed soon after by an event harvest based on the 2007 Rugby World Cup. This was much smaller in scale than the first event harvest, but included websites outside the scope of New Zealand Legal Deposit legislation that required the use of the Web Curator Tool's Harvest Authorisation facility for the first time. 6. ConclusionsThe Library's e-Selectors routinely use the Web Curator Tool to select, schedule, harvest and review websites, then submit them to the digital archive. The e-Selectors began work with version 1.1, and as they became familiar with the tool, there was an increased awareness of its limitations, which informed the specification for a new version. New and updated quality review tools have made a big difference, and many of the sites that were difficult to review with the earlier version are routinely harvested and reviewed with version 1.2. There are still some niggling issues, which we are recording in the bug trackers on the open source website to inform future revisions of the tool. In the last few weeks, a new version of the tool (version 1.3) has been released, and we expect it to offer even more improvements to our web harvesting workflow. Following the two event harvests, the Library is developing capacity models for our future storage and bandwidth requirements. We are also planning access tools and domain-level harvest of New Zealand websites. Notes1. HTTrack Website Copier, <http://www.httrack.com/> (Accessed 2008-05-15.) 2. Paynter, G. W. and Mason I. B. (2006) Building a Web Curator Tool for The National Library of New Zealand. New Zealand Library Association (LIANZA) Conference, October 2006. <http://opac.lianza.org.nz/cgi-bin/koha/opac-detail.pl?bib=121>. (Accessed 2008-05-15.) Copyright © 2008 Gordon Paynter, Susanna Joe, Vanita Lala, and Gillian Lee |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/may2008-paynter
|
{kind=link}