| ||
D-Lib Magazine | |
| Rachel Heery Harry Wagner |
![]()
AbstractThe Semantic Web activity is a W3C project whose goal is to enable a 'cooperative' Web where machines and humans can exchange electronic content that has clear-cut, unambiguous meaning. This vision is based on the automated sharing of metadata terms across Web applications. The declaration of schemas in metadata registries advance this vision by providing a common approach for the discovery, understanding, and exchange of semantics. However, many of the issues regarding registries are not clear, and ideas vary regarding their scope and purpose. Additionally, registry issues are often difficult to describe and comprehend without a working example. This article will explore the role of metadata registries and will describe three prototypes, written by the Dublin Core Metadata Initiative. The article will outline how the prototypes are being used to demonstrate and evaluate application scope, functional requirements, and technology solutions for metadata registries. IntroductionEstablishing a common approach for the exchange and re-use of data across the Web would be a major step towards achieving the vision of the Semantic Web. The Semantic Web Activity statement articulates this vision as ' having data on the Web defined and linked in a way that it can be used for more effective discovery, automation, integration, and reuse across various applications. The Web can reach its full potential if it becomes a place where data can be shared and processed by automated tools as well as by people.' [i] In order to move towards this vision, we need to consider the tools on which such 'data sharing' will be based. In parallel with the growth of content on the Web, there have been increases in the amount and variety of metadata to manipulate this content. An inordinate amount of standards-making activity focuses on metadata schemas (also referred to as vocabularies or data element sets), and yet significant differences in schemas remain. Different domains typically require differentiation in the complexity and semantics of the schemas they use. Indeed, individual implementations often specify local usage, thereby introducing local terms to metadata schemas specified by standards-making bodies. Such differentiation undermines interoperability between systems. Certainly unnecessary variations in schemas should be avoided wherever possible, but it is impossible, and undesirable, to try to impose complete uniformity. Innovation emerges from such differentiation. This situation highlights a growing need for access by users to in-depth information about metadata schemas and particular extensions or variations to schemas. Currently, these 'users' are human — people requesting information. Increasingly, such 'users' will be automated — 'agents' as part of applications that need to navigate or query schemas. It would be helpful to make available easy access to schemas already in use to provide both humans and software with comprehensive, accurate and authoritative information. The W3C Resource Description Framework (RDF) [ii] has provided the basis for a common approach to declaring schemas in use. At present the RDF Schema (RDFS) specification [iii] offers the basis for a simple declaration of schema. It provides a common data model and simple declarative language. Additional work is underway in the context of the W3C's RDFCore Working Group [iv] and the Web Ontology Group [v] to add 'richness' and flexibility to the RDF schema language, to incorporate the features of the DARPA Agent Markup Language (DAML) [1] and the Ontology Interface Layer (OIL) [2] ontology language [vi], and to bring this work to recommendation status. Even as it stands, an increasing number of initiatives are using RDFS to 'publish' their schemas. Metadata schema registries are, in effect, databases of schemas that can trace an historical line back to shared data dictionaries and the registration process encouraged by the ISO/IEC 11179 [vii] community. New impetus for the development of registries has come with the development activities surrounding creation of the Semantic Web. The motivation for establishing registries arises from domain and standardization communities, and from the knowledge management community. Examples of current registry activity include:
Metadata registries essentially provide an index of terms. Given the distributed nature of the Web, there are a number of ways this can be accomplished. For example, the registry could link to terms and definitions in schemas published by implementers and stored locally by the schema maintainer. Alternatively, the registry might harvest various metadata schemas from their maintainers. Registries provide 'added value' to users by indexing schemas relevant to a particular 'domain' or 'community of use' and by simplifying the navigation of terms by enabling multiple schemas to be accessed from one view. An important benefit of this approach is an increase in the reuse of existing terms, rather than users having to reinvent them. Merging schemas to one view leads to harmonization between applications and helps avoid duplication of effort. Additionally, the establishment of registries to index terms actively being used in local implementations facilitates the metadata standards activity by providing implementation experience transferable to the standards-making process. Scope And FunctionalityThe Dublin Core Metadata Initiative (DCMI) has defined a relatively small set of data elements (referred to within the DCMI as the DCMI vocabulary or DCMI terms) for use in describing Internet resources as well as to provide a base-line element set for interoperability between richer vocabularies. The DCMI has long recognized the need to provide users with enhanced access to information about these terms in the form of an added-value 'information service'. This service should include information about the DCMI vocabulary over and above that provided by the RDF schema, or any explication of the vocabulary on the DCMI Web site. This service is intended to assist humans and applications to obtain reliable and trusted information about the DCMI. The interests of a variety of DCMI members have converged around this idea, including: those interested in building a generic schema registry, those interested in expressing the rich structure of ontologies in a schema language, those interested in providing a user friendly search interface to the DCMI vocabulary, and those interested in effectively managing the evolution of the DCMI vocabulary. It was with these goals, and this level of interest, that the DCMI Registry Working Group [xv] was chartered. The original charter for the DCMI Registry Working Group was to establish a metadata registry to support the activity of the DCMI. The aim was to enable the registration, discovery, and navigation of semantics defined by the DCMI, in order to provide an authoritative source of information regarding the DCMI vocabulary. Emphasis was placed on promoting the use of the Dublin Core and supporting the management of change and evolution of the DCMI vocabulary. The overriding goal has been the development of a generic registry tool useful for registry applications in general, not just useful for the DCMI. The design objectives have been to provide a tool suitable for use for the DCMI registry while also ensuring the registry was sufficiently extensible to include other, non-DCMI schemas. In addition, the DCMI Registry Working Group has been committed to using open standards and developing the software from open-source distributions [3]. Discussions within the DCMI Registry Working Group (held primarily on the group's mailing list [4]) have produced draft documents regarding application scope and functionality. These discussions and draft documents have been the basis for the development of registry prototypes and continue to play a central role in the iterative process of prototyping and feedback. Application scope and functional requirements have evolved through an iterative process of prototyping, discussion and evaluation. Many aspects of functionality have been identified using this process, including:
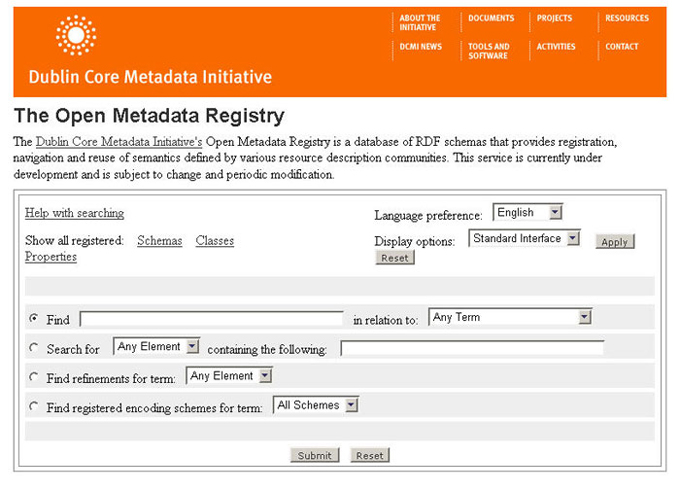
An important focus of the prototyping effort has been to provide a DCMI oriented view of the data model that exists in the underlying RDF schema. This enables users to easily visualize the 'grammar' that structures the DCMI semantics (elements, element qualifiers and encoding schemes). In this article, the 'classification' of DCMI terms is referred to as a taxonomy. A user interface based around this taxonomy is felt to be particularly important for the novice user. Another significant issue, and one not easily solved, has been the requirement to manage the evolution of the DCMI vocabulary. This has involved balancing our internal vocabulary management requirements (audit trail, versioning, status of proposed terms) with the provision of a clear and authoritative view of the current vocabulary. Developing With PrototypesMany of the issues regarding metadata registries are unclear and ideas regarding their scope and purpose vary. Additionally, registry issues are often difficult to describe and comprehend without a working example. The DCMI makes use of rapid prototyping to help solve these problems. Prototyping is a process of quickly developing sample applications that can then be used to demonstrate and evaluate functionality and technology. The following sections describe three metadata registry prototypes that were written by the DCMI [5]. They serve two purposes: to facilitate the generation of scope and functional requirements, and to assist in the identification of practical technology solutions for registry applications. While each of the prototypes provides a different solution, they have several features in common. For example, the prototypes are all open-source solutions, built entirely from open-source distributions [6]. All three prototypes rely on RDF schemas for their input data format, and all three are multilingual [7] Java servlet applications. From there the prototypes diverge, each providing a different solution and each building on experience gained from the previous prototype(s). Prototype 1Prototype 1 is a database solution, based on the Extensible Open RDF Toolkit (EOR) [xvii]. EOR is an open-source RDF toolkit providing a collection of Java classes and services designed to facilitate the rapid development of RDF applications. EOR is based on the Stanford RDF API [8], which provides classes and methods necessary for processing RDF data (i.e., parsing, serializing, etc.). Prototype 1 is essentially a search and navigation service for RDF schemas. It extends the EOR search service by providing a compound search function, which is required for several of the search types, such as "find x in relation to y" and "find classes containing the following term". The user interface (UI) for Prototype 1 is forms-based (see Figure 1) and is a combination of Java Server Pages (JSP) and Extensible Stylesheet Language Transformation (XSLT). The UI provides both standard and RDF interfaces, intended to serve two different types of users: metadata specialists and RDF experts. The differences between the two interfaces are the types of searches supported and the labels used for the search result set. For example, the standard interface provides queries for "find refinements for term x". The corresponding RDF interface query is "find terms that are a subProperty (or subClass) of x". Additionally, the standard interface supports the query "find registered encoding schemes for term x". This is a good example of functionality that supports local terminology relevant to its target audience (in this case, those interested in the DCMI). One can envisage other 'community specific' registries orientating their UI to specialized audiences (e.g., the IMS community [9]). The registry also provides an 'RDF interface' that takes account of the underlying DCMI taxonomy of terms, but uses RDF terminology for the user interface, rather than the more familiar DCMI terminology.
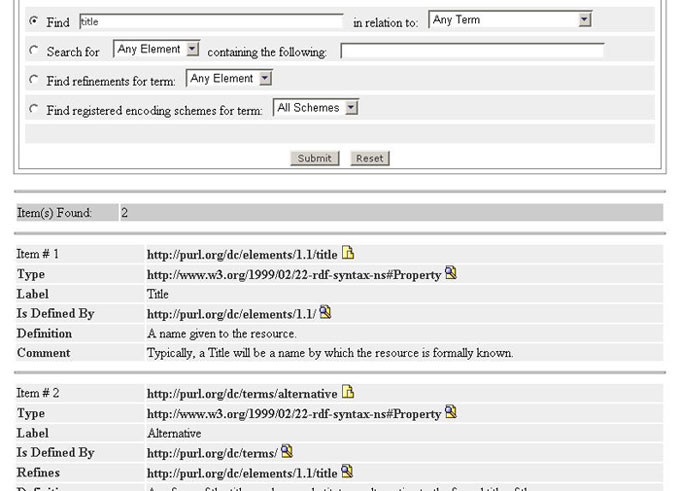
An additional difference between the standard and RDF interface is in the labels generated for query results. Standard interface labels are natural-language oriented and translated into each of the supported languages. The RDF interface uses the fully qualified predicate (namespace-URI and local-name) for its labels. One feature the standard and RDF interfaces have in common is that every resolvable resource in the result-set is an HTML link either to that resource or to a symbol used to link and navigate terms. Query results often include both. For example, clicking on any of the labels or resources generated by the query in Figure 2 would resolve to that resource. Clicking on the "show refinements" symbol ( Prototype 1 uses a PostgreSQL relational database [10] as a persistent data store. PostgreSQL was chosen because it is one of the few open-source database management systems (DBMS) that support Unicode. Separate databases are maintained for each language. This is due to the limited support within EOR and the Stanford RDF API for the xml:lang attribute. This distribution of translations works fine for displaying results in a particular language, but it limits the application's ability to simultaneously display all the translations for a particular term (i.e., display all translations for the term "title").
Multilingual support for the user interface is provided using Java resource bundles [11]. Resource bundles are Java classes that are essentially tables of locale-specific translations. A separate bundle was created for each supported language. These bundles are loaded into the client session whenever a language selection is made. The registry uses the resource bundles to display the user interface in the selected language. Ontology relationships (i.e., complementOf, equivalentTo, inverseOf, etc.), as are provided with DAML+OIL, are supported by the Stanford RDF API via the DAML_O class. However, this layer of support is not currently part of the EOR toolkit and is not supported by this prototype. Solutions built on RDF toolkits such as EOR can be implemented quickly due to the extensive classes and services provided by the toolkit (only a small number of changes to EOR were required to produce Prototype 1). However, this is a complex and resource-intensive approach, which did not perform as well as other solutions. Prototype 2Prototype 2 is an extremely lightweight, in-memory solution. It is a small Java servlet application and differs significantly from the other prototypes in that it does not use an RDF API. Data is parsed using an XML parser, and queries are resolved on the client-side using XSLT stylesheets. All input data is in the form of RDF schemas, which are stored locally as sequential ASCII files [12]. The schemas are loaded by the XSLT stylesheets and rely on the search servlet to identify which schemas to load. This information is passed from the servlet to the stylesheets as parameters. All non-ASCII characters in the schemas are required to be escape-sequenced. The server-side processing for this prototype is very simple and is the key to its flexibility. The search servlet is the primary component and consists of less than 200 lines of code. This servlet evaluates the input data that was posted and sets parameters identifying the specific request and the current language selection. These are then passed to the appropriate stylesheet for processing.
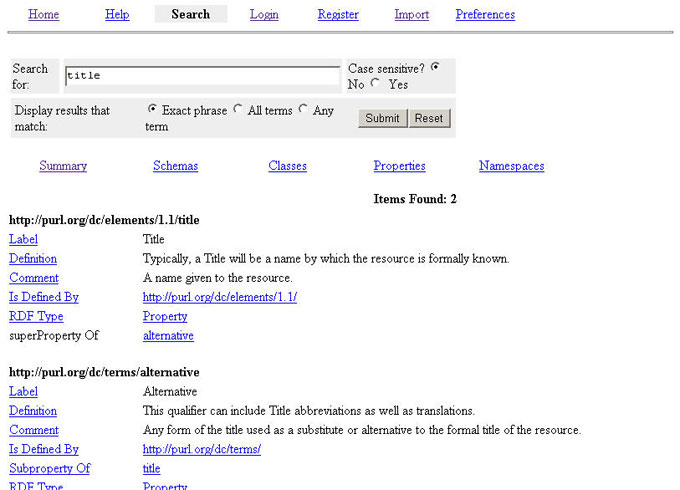
The user interface has an intuitive point-and-click style, designed to facilitate navigation rather than searching [13] (see Figure 3). The UI of the search service is composed entirely of XSLT stylesheets. The stylesheets are segregated by function (banner, navigation bar, footer, etc.) and language. The multilingual aspects of the UI are managed by isolating all language-dependent text to individual stylesheets, and including those stylesheets as needed. In Prototype 2, the translations were isolated to the intro, navbar and labels stylesheets. Non-ASCII characters in these stylesheets are encoded as escape-sequenced strings. Prototype 2 provides one interface style. This UI is designed to provide native-language labels for terms. However, due to the modular approach of the XSLT stylesheets, additional interfaces (i.e., the RDF interface provided in Prototype 1) could be added. All resources in the result-set are displayed as HTML links that resolve either to the listed resource, or that initiate a new query for the listed resource. This includes both labels (predicates) and property values (objects) and allows users to easily navigate the metadata terms and explore the relationship between terms. Due to the simplified data model of Prototype 2, refinements for terms (subClassOf or subPropertyOf) are much easier to discover and navigate, and can be displayed in a more intuitive manner. All refinements for each selected term are automatically included in query results (see Figure 4). Support for ontologies is limited. Complex relationships (such as those provided with DAML+OIL) between terms cannot be easily automated without an RDF parser, and would be difficult to implement with this type of lightweight solution. The modular approach of the stylesheets does offer, to a greater degree, more flexibility regarding local DCMI vocabulary taxonomy (i.e., elements, qualifiers, encoding schemes, controlled vocabulary terms). However, a method to automate the discovery and navigation of this taxonomy has not yet been discovered.
Lightweight, in-memory solutions, such as Prototype 2, can be implemented quickly, and are flexible and fairly simple to maintain. However, they are not expected to scale well due to the limitations of in-memory processing. This may be perfectly acceptable for applications that are able to limit the number of schemas they plan to register. Prototype 3The third prototype, like Prototype 1, is a database solution. It is based on the Jena Semantic Web Toolkit [14], the ARP RDF Parser [15] and the BerkeleyDB [16] database management system. Jena is a functionally rich Java API for processing RDF data. It supports both in-memory and persistent storage RDF models, RDF Data Query Language (RDQL), integrated RDF parsers (i.e., ARP and SirPac) and a rich set of resource-centric and model-centric methods for manipulating RDF data. Jena and the ARP parser are open-source and were developed by the HP Labs Semantic Web Activity. Prototype 3 uses BerkeleyDB for persistent data storage. BerkeleyDB is an open-source database management system that provides a comprehensive set of features, including data concurrency, recovery and transaction support. It differs from most database management systems in that it is neither relational nor object-oriented. Databases are composed of simple key-value pair records. BerkeleyDB performs better than relational database systems for a couple of reasons. First, it uses simple function calls to access data, thus eliminating the overhead of a query language, such as SQL. Second, it is an "embedded" database, running in the same address space as the application that uses it. This eliminates the need for inter-process communication. BerkeleyDB appears to be a perfect solution for a persistent RDF data store, but the interface between Jena and the database is not completely stable and can result in unexpected system failures. Prototype 3 is also a Java servlet application. It builds on the previous prototypes and is composed of a number of services, including search/navigate, registration, login, and import. The user interface is written entirely in XSLT. Each of the services produces an XML document that is then parsed using XSLT. The XSLT stylesheets produce HTML, which is delivered to the client. One UI style is currently provided, which produces native-language style labels (i.e., DCMI data element identifiers such as title, description, publisher, etc.). The search/navigate service includes features from both of the previous prototypes. The user interface has a more advanced search engine than Prototype 1 (see Figure 5) and incorporates the point and click navigation style of Prototype 2. The search form enables case-sensitive searching and supports specific types of searches (i.e., match all terms, match any term, etc.). This function can be easily expanded to further refine searches to a specific schema or taxonomy.
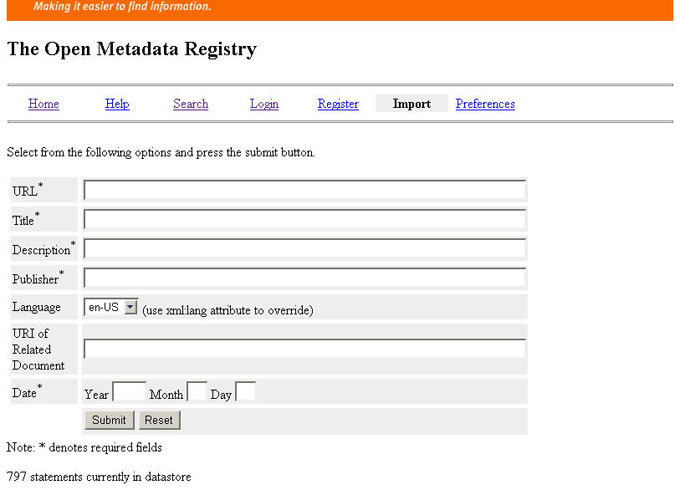
Like Prototype 2, this application uses an intuitive point-and-click style of navigation. As with the previous prototypes, all resources are displayed as HTML links that resolve to the listed resource or initiate a new query for that resource. Additionally, "canned" queries are provided for displaying registered schemas, properties, classes, namespaces, or a summary of all registered items. The register, login, and import services provide a means for authorizing users and for allowing those users to register schemas. Additionally, the import service provides two very important functions: an alternative means for users to specify the schema language, and two methods for specifying the administrative metadata associated with a schema. Metadata describing the schema itself is required for each registered schema. This includes title, description, publisher, URL of related documents, and date. This information can be included as part of the schema, as is the case with the DCMI schemas, or can be provided when the schema is imported using the fields provided on the import screen (see Figure 6).
The schema language must also be specified when the schema is registered. This can be accomplished in two ways: by coding the xml:lang attribute on all literals within the schema [xviii] (see Figure 7) or by specifying the language at registration time using the field provided on the import screen. Identifying the schema language during registration enables the discovery and navigation of terms and schemas in multiple languages. Users can specify their language preference, using the preferences service, by selecting from a list of supported UI languages and result-set languages. The search service selects the appropriate query results based on the language preferences selected and the language encoding used by the schemas.
The multilingual user interface is accomplished via an XSLT "translate" stylesheet. This stylesheet is passed the term requiring translation and the requested language. It uses language-specific XML documents, similar to Java resource bundles, to perform the translations. Translations are done both for the user interface and the result-set labels. Prototype 3 appears the most promising of the three solutions. The extensive amount of functionality for manipulating RDF data provided with the Jena API offers a big advantage over the other prototypes. This is especially significant regarding support for DAML ontologies. ConclusionsSoftware and performance issuesJava proved an ideal solution for multilingual registry applications because of its use of UTF-8 encoding for internal string representation and because of the rich application-programming interface provided for internationalization [xix]. One significant difference between the multilingual solutions we tried is the xml:lang support offered by the Jena API. This attribute simplifies language processing and enables flexibility not easily offered by other solutions. Relational database solutions, such as was tried with Prototype 1, do not appear to be an ideal fit for RDF, at least not from a performance standpoint. The overhead of using a high-level data access (such as SQL) with a data model as minimalist as RDF is noticeable, and performance suffers. BerkeleyDB, in conjunction with the Jena API, offers significantly better performance, but is not 100% stable. This problem is expected to be resolved in the near future. In the interim, the best choice for a persistent data store for RDF metadata registries appears to be the slower-performing, but more reliable, relational model. Prototype 3 demonstrates a solution for automating the identification and management of administrative metadata that describes the registered schemas (i.e., title, publisher, description, etc.). A standard method for describing administrative metadata for schemas does not currently exist. Prototype 3 resolves this issue by providing two alternative methods for capturing this information. The modular use of XSLT stylesheets has proven to be a good solution for providing user interfaces that can be customized to suit multiple user types. This level of functionality is demonstrated with Prototype 1, and could be easily adopted by the other prototypes due to their common use of XSLT. Functionality and data model issuesThere has been an ongoing tension between the requirements for managing the evolution of the DCMI vocabulary and the requirement to provide user friendly navigation of the DCMI vocabulary. The internal vocabulary management requirements of the DCMI (i.e., audit trail, versioning, tracking status of proposed terms, etc.) could not easily be resolved with the requirements for an "open" metadata registry and were not addressed by the three prototypes described in this article. The principal obstacle to satisfying vocabulary management requirements has been a lack of data. The DCMI RDF schemas do not include this level of information. Although several solutions were proposed-- including overloading the schemas to include this data and maintaining multiple data sources-- none were considered acceptable. While this may be considered a complication particular to metadata 'standards-making bodies', such as the DCMI, it is also, to a lesser extent, an issue faced by all schema maintainers. The DCMI has chosen to split their vocabulary management requirements into a separate application. It will be interesting to see if such a system has more widespread use amongst schema maintainers. The formulation of a 'definitive' set of RDF schemas within the DCMI that can serve as the recommended, comprehensive and accurate expression of the DCMI vocabulary has hindered the development of the DCMI registry. To some extent, this has been due to the changing nature of the RDF Schema specification and its W3C candidate recommendation status. However, it should be recognized that the lack of consensus within the DCMI community regarding the RDF schemas has proven to be equally as impeding. The identification and navigation of the 'taxonomy' (the 'grammar' of a vocabulary arising from the data model) belonging to different resource communities is still an open issue. Each of the prototypes demonstrate a limited degree of functionality in this area, but do not provide a method for automating it. Until an automated method can be found, "canned queries" and other navigational aids to these structures will be limited to widely accepted taxonomies (i.e., properties, classes, etc.) and locally defined taxonomies (such as DCMI elements, qualifiers, etc.) that are manually maintained. The automated sharing of metadata across applications is an important part of realizing the goal of the Semantic Web. Users and applications need practical solutions for discovering and sharing semantics. Schema registries provide a viable means of achieving this. Much has been learned from the prototyping efforts to date, and the DCMI has renewed its commitment to developing an operational registry that facilitates the discovery, exchange and reuse of semantics. AcknowledgementsThe authors would like to acknowledge the DCMI Registry Working Group and other members of the DCMI for their contribution to the formulation of ideas expressed in this article and for their support in the development work. Notes and References[1] The DARPA Agent Markup Language is accessible at <http://www.daml.org/>. [2] The Ontology Interface Layer is accessible at <http://www.ontoknowledge.org/oil>. [3] Source code for the registry applications is available at <http://eor.dublincore.org>. [4] The registry working group archives are available at <http://www.jiscmail.ac.uk/lists/dc-registry.html>. [5] The prototypes are accessible at <http://wip.dublincore.org:8080/registry/Registry>. [6 ] Java is developed using Sun's Java Community Process. This process is dedicated to open standards and has many similarities to open-source, but is not technically considered open-source. [7] One of the known requirements for the metadata registry is that it be multilingual, both from a user interface (UI) and a data perspective. All three of the prototypes were written with this requirement in mind, and several different approaches were used. The Dublin Core element set is currently translated into fourteen different languages, of which six were selected to serve as proof of concept. The selected languages include those comprised of both single and double byte character sets (i.e., Spanish and Japanese). Due to the cost of the translations, and the temporary nature of the prototypes, only portions of the data and user interface (enough to serve as proof of concept) were translated in each application. [8] The Stanford API is accessible at <http://www-db.stanford.edu/~melnik/rdf/api.html>. [9]The IMS Global Consortium, Inc. (<http://imsproject.org/metadata/>) is an organization committed to the development and promotion of metadata standards related to various aspects of distributed learning. [10] PostgreSQL is accessible at <http://www.us.postgresql.org/>. [11] The ResourceBundle class documentation (<http://java.sun.com/products/jdk/1.1/docs/api/java.util.ResourceBundle.html>) is a good source of information regarding resource bundles and their use. [12] This was done as a temporary measure. A more practical approach for a production version of this prototype would be to store the URL of the registered schemas and load them via the network at system startup. [13] A limited degree of searching is still possible due to the internal search function provided with most Web browsers. [14] Jena is accessible at <http://www.hpl.hp.com/semweb/jena-top.html>. [15] The ARP Parser is accessible at <http://www.hpl.hp.com/semweb/arp.html>. [16] BerkeleyDB is accessible at <http://www.sleepycat.com/index.html>. Resources[i] W3C Semantic Web Activity Group. Accessed February 11, 2002. <http://www.w3.org/2001/sw/Activity>. [ii] Resource Description Framework (RDF). Accessed February 11, 2002. <http://www.w3.org/RDF/>. [iii] Resource Description Framework (RDF) Schema Specification 1.0. W3C Candidate Recommendation 27 March 2000. Work in progress. <http://www.w3.org/TR/rdf-schema>. [iv] RDFCore Working Group. Accessed February 11, 2002. <http://www.w3.org/2001/sw/RDFCore/>. [v] W3C Web-Ontology (WebOnt) Working Group. Accessed February 11, 2002. <http://www.w3.org/2001/sw/WebOnt/>. [vi] DAML+OIL Web Ontology Language. Accessed January 14, 2002. <http://www.w3.org/Submission/2001/12/>. [vii] ISO/IEC 11179-1:1999 Specification and standardization of data elements. Part 1: Framework for the specification and standardization of data elements (available in English only). International Standards Organisation. [viii] National Health Information Knowledgebase. Hosted by the Australian Institute of Health and Welfare. Accessed February 11, 2002. <http://www.aihw.gov.au/knowledgebase/index.html>. [ix] Environmental Data Registry. Accessed February 8, 2002. <http://www.epa.gov/edr>. [x] The XML Registry hosted by OASIS. Accessed February 11, 2002. <http://www.xml.org/xml/registry.jsp>. [xi] MetaForm: Database containing Dublin Core manifestations and other metadata formats. Hosted at the State and University Library in Goettingen. Accessed February 11, 2002. <http://www2.sub.uni-goettingen.de/metaform/>. [xii] SWAG Dictionary. Accessed February 11, 2002. <http://webns.net/>. [xiii] LEXML: Open Source Development of an RDF Dictionary. Accessed February 11, 2002. <http://home.snafu.de/mmuller/lexmlde/rdf.htm>. [xiv] SCHEMAS Forum for Metadata Implementors Registry. Accessed February 11, 2002. <http://www.schemas-forum.org/registry/>. [xv] Dublin Core Metadata Initiative. DCMI Registry Working Group. Accessed January 14, 2002. <http://dublincore.org/groups/registry/>. [xvi] Dublin Core Metadata Initiative DCMI Registry Functional Requirements. Rachel Heery. Accessed January 10, 2002. <http://dublincore.org/groups/registry/fun_req_ph1-20011031.shtml>. [xvii] OCLC Office of Research. Dublin Core Metadata Initiative. Extensible Open RDF Toolkit. Accessed January 14, 2002. <http://eor.dublincore.org/>. [xiii] World Wide Web Consortium. RDF Schema for the RDF Data Model. Accessed January 15, 2002. <http://www.w3.org/1999/02/22-rdf-syntax-ns>. [xix] Sun Microsystems. Internationalization. Accessed January 15, 2002. <http://java.sun.com/products/jdk/1.1/docs/guide/intl/>.
Copyright © Rachel Heery and OCLC | |
| | |
| Top | Contents | |
| | |
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/may2002-wagner
|