| ||
D-Lib Magazine
|
|
|
Amy Brand |
![]()
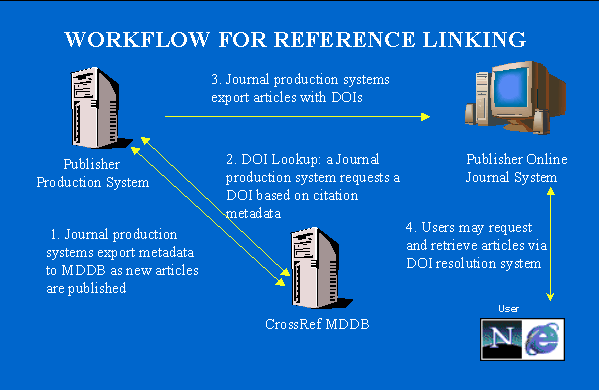
IntroductionCrossRef, the only full-blown application of the Digital Object Identifier (DOI®) System [1] to date, is now a little over a year old. What started as a cooperative effort among publishers and technologists to prototype DOI-based linking of citations in e-journals evolved into an independent, non-profit enterprise in early 2000. We have made considerable headway during our first year, but there is still much to be done. When CrossRef went live with its collaborative linking service last June, it had enabled reference links in roughly 1,100 journals from a member base of 33 publishers, using a functional prototype system. The DOI-X prototype was described in an article published in D-Lib Magazine in February of 2000 [2]. On the occasion of CrossRef's first birthday as a live service, this article provides a non-technical overview of our progress to date and the major hurdles ahead. The importance of reference linkingThe electronic medium enriches the research literature arena for all players -- researchers, librarians, and publishers -- in numerous ways. Information has been made easier to discover, to share, and to sell. To take a simple example, the aggregation of book metadata by electronic booksellers was a huge boon to scholars seeking out obscure backlist titles, or discovering books they would never otherwise have known to exist. It was equally a boon for the publishers of those books, who saw an unprecedented surge in sales of backlist titles with the advent of centralized electronic bookselling. In the serials sphere, even in spite of price increases and the turmoil surrounding site licenses for some prime electronic content, libraries overall are now able to offer more content to more of their patrons. Yet undoubtedly, the key enrichment for academics and others navigating a scholarly corpus is linking, and in particular the linking that takes the reader out of one document and into another in the matter of a click or two. Since references are how authors make explicit the links between their work and precedent scholarship, what could be more fundamental to the reader than making those links immediately actionable? That said, automated linking is only really useful from a research perspective if it works across publications and across publishers. Not only do academics think about their own writings and those of their colleagues in terms of "author, title, rough date" -- the name of the journal itself is usually not high on the list of crucial identifying features -- but they are oblivious as to the identity of the publishers of all but their very favorite books and journals. Citation linking is thus also a huge benefit to journal publishers, because, as with electronic bookselling, it drives readers to their content in yet another way. In step with what was largely a subscription-based economy for journal sales, an "article economy" appears to be emerging [3]. Journal publishers sell an increasing amount of their content on an article basis, whether through document delivery services, aggregators, or their own pay-per-view systems. At the same time, most research-oriented access to digitized material is still mediated by libraries. Resource discovery services must be able to authenticate subscribed or licensed users somewhere in the process, and ensure that a given user is accessing as a default the version of an article that their library may have already paid for. The well-known "appropriate copy" issue is addressed below. Another benefit to publishers from including outgoing citation links is simply the value they can add to their own journals. Publishers carry out the bulk of the technological prototyping and development that has produced electronic journals and the enhanced functionality readers have come to expect. There is clearly competition among them to provide readers with the latest features. That a number of publishers would agree to collaborate in the establishment of an infrastructure for reference linking was thus by no means predictable. CrossRef was incorporated in January of 2000 as a collaborative venture among 12 of the world's top scientific and scholarly publishers, both commercial and not-for-profit, to enable cross-publisher reference linking throughout the digital journal literature. The founding members were Academic Press, a Harcourt Company; the American Association for the Advancement of Science (the publisher of Science); American Institute of Physics (AIP); Association for Computing Machinery (ACM); Blackwell Science; Elsevier Science; The Institute of Electrical and Electronics Engineers, Inc. (IEEE); Kluwer Academic Publishers (a Wolters Kluwer Company); Nature; Oxford University Press; Springer-Verlag; and John Wiley & Sons, Inc. Start-up funds for CrossRef were provided as loans from eight of the original publishers. Where we are nowSince its inception, CrossRef has grown to include 70 leading journal publishers, both commercial and nonprofit, with over three million deposited records from 3,875 journals [4]. We are on track to add between 500,000 and one million new records per year. At present, the DOI Handle System resolves roughly 400,000 CrossRef DOI clicks per month. Hence, CrossRef has already transformed the experience of many scholars using electronic journals, by allowing them to go reliably from a citation in a given article to the full text of the cited material at another publisher's website. CrossRef aims to become nothing less than the complete reference-linking backbone for all scholarly literature available in electronic form. Like the centralized electronic bookseller who provides an invaluable research tool because their aggregated metadata is so comprehensive, CrossRef will be measured by the robustness of its linking coverage; the usefulness of the system is directly proportional to the volume of linkable content. By that measure, we are still in our infancy. There are thousands of electronic journals and issues still to be added to the system. And, of course, journal articles do not exclusively cite other journal articles. Our linking capabilities must be extended to e-prints, conference proceedings, reference works, etc. Hence, we are rapidly recruiting new member publishers, adding other content types to the linking process, and expanding the range and depth of the citation coverage of participating journals to include more backlist issues. CrossRef is not an exclusive club. Any publisher of primary research material can become a contributing member. Members are automatically assigned a DOI prefix, and their DOIs are registered as part of the metadata submission process. Affiliate access to our database of journal metadata and associated DOIs is also open to libraries, secondary publishers, aggregators, and researchers in the digital library arena. System OverviewCrossRef is a process, not a product. Each member publisher creates a DOI incorporating its own DOI prefix for each journal article, tagging it to article metadata and a URL. Records are assembled into batch file submissions to the CrossRef metadata database (MDDB) in a strict XML-based DTD format. CrossRef then registers each article DOI and URL in a central DOI directory. In a separate process, the publisher also submits the reference citations contained in each article to the reference resolver, a front-end component of the MDDB that allows for the retrieval of DOIs. The publisher can insert CrossRef links into any of an article's citations that point to content already registered in the CrossRef system. Figure 1 presents a schematic of this process.
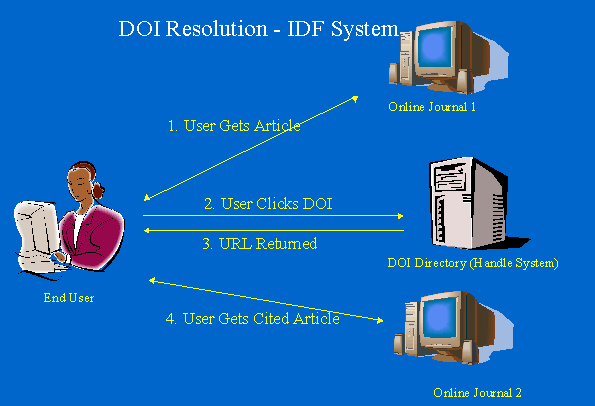
In September of 2000, CrossRef became the first official DOI Registration Agency, authorized by the International DOI Foundation (IDF) [1] to allocate DOI prefixes, register DOIs, and provide the infrastructure to enable our members to declare and maintain metadata and state data. DOI-URL pairs are registered in the DOI System, which is an implementation of the Handle System® [5] (a distributed computer system for naming digital objects and storing the names and the information needed to locate and access the objects via the Internet) managed by the Corporation of National Research Initiatives (CNRI) [6] on behalf of the IDF. The CrossRef system uses open standards; the DOI syntax is itself a NISO standard [7]. CrossRef also employs a uniform set of rules to accommodate the publishers' right to control their business policies and maintain branding, while allowing the researcher to navigate through the widely distributed content of multiple publishers. The rules cover what can be named by a DOI, what types of data can be stored in the DOI System, and the way prefix holders can use DOIs on the Web. A researcher clicking on a CrossRef link will be connected to a page on the publisher's website showing a full bibliographical citation of the article, and, in most cases, the abstract as well. The reader can then access the full-text article. While subscribers can generally go straight to the text, non-subscribed users are presented with options for access. See Figure 2.
In short, CrossRef provides a database of DOIs and metadata that enables DOI lookup, akin to a telephone book and directory assistance. If you know the DOI for an article, that's all you need to know in order to locate it persistently. If a publisher changes the location of an article, it need only update the URL for the article in one place. Some member publishers and affiliates have availed themselves of local hosting, which provides them with regularly refreshed local copies of the MDDB. By implementing some additional functionality, they can effect dynamic linking, generating links on the fly from an updated bank of deposits. Developments in progressThe shortcomings of the DOI-X functional prototype system were described in the Atkins et al. article published in this magazine in February 2000 [2]. CrossRef has made considerable investment to date in refining the system hardware and software. Perhaps more importantly, we have established the legal, technical, and managerial framework to transform the prototype vision into a functioning company. With the groundwork firmly in place, there is now a major system upgrade underway that will greatly improve overall performance. Core requirements are highlighted and briefly discussed here. Data validation. At present, roughly 10% of citation queries submitted to the MDDB fail to retrieve the correct DOI link for reasons of poor data quality. This is due mainly to errors in the bibliographic metadata itself, with a small number of failures attributable to inaccuracy of the URLs registered in the DOI Handle System. Stricter validation is thus needed to ensure the integrity of the data. While uploaded XML data is currently parsed and validated according to the upload DTD and data rules, one core specification of the system rewrite is a more sophisticated syntax check. Parameter passing. The DOI is simply a number that redirects the user to a URL at the publisher's site. The publisher can tell very little about where the user is coming from and what terms of access should be granted. Some CrossRef publishers would understandably like to know more about the inbound links to their content. Parameter passing, which refers to when a key or some encoded text is sent along with a DOI link, would enable extra functionality that will benefit both publishers and end users. The "parameter" could be information about the source article (i.e., the article containing the reference the user clicked on). Therefore, the publisher receiving the link would know the exact article and publisher the user came from. Crucially, no information about the individual user would be tracked or stored in a central location; resolution occurs within the DOI system, which is distinct from the CrossRef system. Each publisher could track the links that arrive at its own site, and would thus know which journals were linking to its own journals. Parameter passing would also enhance the end-user experience, by allowing branded response pages, "return" buttons (or links back to the original site), customized messaging or error handling, and special trading rules, such as allowing immediate full-text access to users coming from certain sites or journals. This is one of a group of functions referred to as "enhanced resolution", which also includes multiple resolution and reverse metadata look-up. Multiple resolution entails the association of multiple elements with a DOI. In this case, citation query results would include metadata about all items potentially associated with a DOI. These might be additional URLs for geographically dispersed mirror sites (for example, to enhance performance and lower telecommunications costs), or possibly an e-mail address or a pointer to a metadata record. Reverse metadata look-up refers to the return of an article's complete metadata given its DOI as input. This would allow a local linking server in a library to create customized links for its readers, an element of the solution to the appropriate-copy problem. Localized linking. All the elements of enhanced resolution will be incorporated into a localized linking capability, a prototype of which should be operational shortly. A central goal of localized linking is to provide a solution to the appropriate-copy problem, to ensure that a researcher at a given institution is not directed to a version of an article that requires payment for access if in fact that article is already available via library subscription (electronic or print) [8]. The solution to the localized linking prototype will involve an implementation of the OpenURL protocol, which employs a form of parameter passing to provide institutional service providers with the information they need to select the "appropriate" source, functioning as a proxy server at the client location. The prototype is under collaborative development by Ex Libris, the IDF, CrossRef, CNRI, the Digital Library Federation, the Los Alamos National Laboratory, OhioLink, and the University of Illinois at Urbana-Champaign [9]. Expansion of content. At present, the CrossRef system only accomplishes journal citation linking. We are currently enhancing the metadata schema to allow for scholarly material other than journal metadata to be deposited and link-enabled. Associated extensions to the upload DTD, upload parsing component, and query DTD are also being made. Inexact matching. In the current system, ambiguous, partial, and incorrect citation queries do not fare well. Ambiguous queries, in which more than one record matches the input, only return one result, while incorrect queries return no results from the MDDB. A major component of the revised system will be inexact, or approximate, matching, in which every value provided in a query is considered in a weighted manner, and probabilistically ordered results are returned. This greater flexibility in the reference resolver will provide publishers with the feedback they need to clean up their references. They will then also be able to use CrossRef regularly in the most labor-intensive part of the editorial process: checking references. Some remaining challengesRobustness. Citation queries input to our system now average several hundred thousand per week and have at times been as high as four million in one week. At present, only 40% of queries result in locating the relevant record. This is because the majority of the full-content links that publishers and affiliates are looking for are not yet enabled. Hence, one major challenge is to build up the database through increased publisher deposits. More content will no doubt be available online going forward. Given the current widespread interest among publishers, librarians, secondary publishers, and others, recruiting more members and affiliates does not look like it will be difficult. The real hurdle is in helping member publishers to deposit more metadata, and more regularly. This requires not only that they digitize more of their journal content, including backlist issues, but also that they integrate regular CrossRef depositing into their own production processes. This raises intimidating data management issues for some publishers; we know it will take time before all of these pieces are in place for all participants. As a limited solution, we offer implementation workshops to provide member publishers with an overview of the CrossRef process, guiding them through the steps of depositing their metadata and retrieving the DOIs necessary for link creation, and generally enhancing their understanding of the system. Archiving. How is digital content going to be archived? In the current process, publishers are responsible for maintaining the accuracy of the URL associated with an article's DOI. The DOI itself never changes, even when ownership of a journal or publisher changes hands, but the URL and the content behind it have to be maintained by the publisher. Clearly, this is not a permanent solution. The development of policies for the archiving of electronic content is an industry-wide concern, and the DOI was not itself designed to tackle archiving. But CrossRef may well have a role in working out solutions here. At the moment, CrossRef has started to link to archiving services such as JSTOR and the Astrophysic Data Center (ADS). Assigning DOIs to these older articles means they can be included in the linking network, even if the electronic version is simply scanned in. The oldest articles currently in the CrossRef system are from the Astronomical Journal from 1849. Misconceptions? CrossRef has not yet carried out any PR campaigns, and does not even insist that publisher links carry CrossRef branding. So perhaps it is no surprise that the greatest challenges are the misconceptions in the broader information community. One misconception is that OpenURL and CrossRef are competitive endeavors. They are not. OpenUrl is simply a syntax for transporting metadata and identifiers within URLs. The target of an OpenURL is a given institution's preferred service component [9]. In essence, OpenURL enables extended linking services by inserting another, customizable step in the linking process. It does not itself accomplish persistent linking to full-text content, and so is in fact complementary to the CrossRef system. Another seeming misconception is that Crossref is a so-called "closed" system, while other linking initiatives are not; the co-opting of the term "open" may contribute to this perception. Barriers to entry in CrossRef are in fact low. The service is available on a membership basis to any publisher meeting basic requirements and willing to pay minimal fees. CrossRef itself costs the end-user nothing. Its expenses are covered by nominal charges to publishers for depositing their metadata, annual membership fees, and fees charged to any affiliates -- libraries, secondary publishers, aggregators, and others -- who access CrossRef's MDDB to retrieve DOIs to create links to full-text content. A number of libraries and other affiliates have already signed up and started using the system. "Members" are primary publishers of original content in electronic form willing to make that content accessible, and committed to active participation via depositing metadata and retrieving DOIs for outbound links from their own material. The membership model is necessary to ensure the integrity of the records and, ultimately, the success of the undertaking. But it does not signify an exclusive club. Equally important, the data collected by CrossRef is minimal. Since our metadata format falls short of the full bibliographic record and does not include abstracts, the system as it now stands is not a threat to A&I or other aggregation services (many of which are publisher owned). Since our mission is to involve all scholarly publishers in cross-reference linking, we must, and do, set manageable thresholds for participation. Multiple versions. As multiple versions of articles proliferate on the internet, there may be increasing confusion surrounding citation protocols. A given paper may exist in pre-print or e-print form on a university server, and in finalized form at both the publisher's website and at another hosting location. One key role that CrossRef will no doubt play going forward is to ensure discovery of and access to any so-called "canonical" version of a given paper -- one that has been peer-reviewed, edited, and officially published. As long as canonical versions of publications exist, scholars will want to identify, access, and cite them. With multiple resolution capabilities in hand, whereby a single DOI might resolve to all known electronic manifestations of a work, and by making a commitment to interoperability with other distributed metadata posting and searching initiatives, we will be in a position to help researchers distinguish among different versions of a given work. ConclusionCrossRef is about reducing friction in the means of discovering and accessing scholarly content online. We are well on the road to creating a comprehensive reference linking backbone, and there are many directions in which we can venture from here. Admittedly, balancing the concerns of various interested parties is something of a juggling act. But publishers, librarians, and researchers working together will surely produce other methods of lessening the friction, both technical and economic, in scholarly communications. We expect to play an active role in this process. AcknowledgmentsSincere thanks to Ed Pentz and Mark Kosinski of CrossRef, Sue Kesner of Infotrieve, and the editors of D-Lib Magazine for their improvements to this article. References[1] For more information on the DOI: <http://www.doi.org>. [2] Atkins, Helen, et al. 2000. Reference Linking with DOIs. D-Lib Magazine. 6(2). <http://www.dlib.org/dlib/february00/02risher.html>. [3] "Article Economy" was a term used by Jan Peterson of Infotrieve in her December, 2000 presentation at the STM meeting. [4] A browsable list of Cross-linked journals is available at <http://www.crossref.org/journallist.html>. [5] For more information on the Handle System: <http://www.handle.net>. [6] For more information on the Corporation for National Research Initiatives (CNRI): <http://www.cnri.reston.va.us>. [7] NISO. 2000. Syntax for the Digital Object Identifier, Z39.84. <http://www.niso.org/>. [8] NISO. 2000. Report on the Meeting held July 24, 2000 at CNRI, Reston, VA. NISO/DLF/CrossRef Workshop on Localization in Reference Linking. <http://www.niso.org/CNRI-mtg.html>. [9] Van de Sompel, Herbert, and Beit-Arie, Oren. 2001. Open Linking in the Scholarly Information Environment Using the OpenURL Framework. D-Lib Magazine. <http://www.dlib.org/dlib/march01/vandesompel/03vandesompel.html>. Copyright 2001 Amy Brand |
|
| |
|
|
Top
| Contents |
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/may2001-brand
|