|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Theo van Veen |
![]()
AbstractThe Koninklijke Bibliotheek (KB) is engaged in a major renewal of its information infrastructure. This article reviews the current information infrastructure and explains possible changes. It also lists a number of recommendations for development strategies to use available (browser) technology optimally, provide data in machine-readable formats (XML), comply with relevant protocols and standards and enhance modularity not only at the Koninklijke Bibliotheek but at other similar organisations as well. IntroductionFrom time to time organisations need to review and innovate their basic information infrastructure in order to increase functionality, keep up with current technology, increase standardisation and uniformity and get rid of old technology. At the Koninklijke Bibliotheek (KB) we are currently at the start of a major renewal of the library's information infrastructure. In this article I will review today's information infrastructure in several areas and explain possible changes, the main purpose being to improve the integration and exchange of information between internal and external services, and lowering implementation barriers for new functionality. Following this review, I provide a number of recommendations for development strategies to use available (browser) technology optimally, provide data in machine-readable formats (XML), comply with relevant protocols and standards and enhance modularity. Although this article is based on my experiences with the infrastructure of the KB, the review and recommendations may be applicable to the infrastructures of other similar organisations as well. It is a representation of a personal view of the author and decisions about the infrastructure are at the time of writing this article still to be made. GoalsCurrently, the primary goal of evaluating and renewing the KB information infrastructure is to be able to offer services that can understand the data coming from other services and to offer data from the KB in such a way that other services can understand and use it. This requires syntactic and semantic interoperability. Enrichment of information by means of the integration of data originating from different sources under the user's control and, if needed, on the user's desktop, is the key issue here. [See Note 1 for more detail.] The secondary goal of the information infrastructure renewal is to minimize development and maintenance efforts for the services offered by the KB. Although this secondary goal will be achieved mainly by standardisation and uniformity, it is also our intention to guarantee that users, service providers and data providers maintain enough control and freedom to meet their own specific functional requirements without unnecessary restrictions. Standards need to be developed based on current practices and needs. Therefore the goal is not only to follow standards but also to contribute to their development. A major challenge to meeting this goal is to contribute to standards that are flexible enough to be extended without a new version being needed every time an extension is made to a standard, and with a minimum of incompatibility between earlier and later implementations. [See Note 2 for an example] Although our work at KB mainly concerns its internal infrastructure, we certainly expect that the approach recommended in this article will support integration with external information infrastructures, such as those of other national libraries and museums, archives, Google, etc. The current situationThe information infrastructure found in many organisations has evolved as the result of many different projects. This has led to the development of fragmented infrastructures with the legacy of a variety of websites, data formats and databases. Apart from the high maintenance efforts required to sustain such infrastructures, this situation makes it more difficult to integrate different services. For many websites that were created for specific collections, integrating the results of searches using different databases requires a great deal of development effort. Other consequences of fragmented infrastructures show up in, for example, dead links (because URL syntaxes have been changed) and access barriers (because each service has its own authorisation rules). Finally, when users find relevant information, it is not easy for them to make use of the data according to their own preferences; they are restricted to the functionality offered by the data and service providers. To integrate data and services, users often have to copy data from the screen and paste it into other services. Another aspect of the current situation is that there are many different points of entry for searching information from separate databases. This is the case because there is no common data model, and for many services output is not machine-interpretable. Therefore, these services require their own user interfaces. As a result, users tend to search using Google, and libraries lose control over the presentation to the user of their own contents. The strong points of the current situation are that 1) XML is used increasingly, making data better machine-interpretable and 2) the increased use of http/XML-based protocols like SRU [16] (Search and Retrieve via URLs) and OAI-PMH [12] (Open Archive Initiative Protocol for Metadata Harvesting) makes the exchange of information much easier. In addition to SRU, OpenURL [13] helps to link information from different sites. The advance of browser technology (such as support for XSL [20] transformations in the browser and user definable browser extensions), combined with the enormous amount of unused processing power at the users' desktop, should enable us to fully utilize this http/XML-based communication between browsers and services. (See Note 3.) At the KB we are currently in the process of migrating to Verity as our search engine. This migration offers the possibility for introducing SRU access for all databases and web applications, and to define a new approach for the integration of different services. For this we will make use of the experience gained from the European Library project [4] and [19], where a similar infrastructure has been created, and of the experience gained from the recent introduction of the KB's portal service. ApproachThe model whereby integration of data takes place under the user's control will become increasingly important. In most cases, this integration will take place at the desktop. Search results obtained from one service can then be re-used by other services, as opposed to monolithic black-box solutions or fixed configurations. Although such integration can be obtained manually by copying and pasting, it is assumed that user-controlled browser extensions can do this semi-automatically.
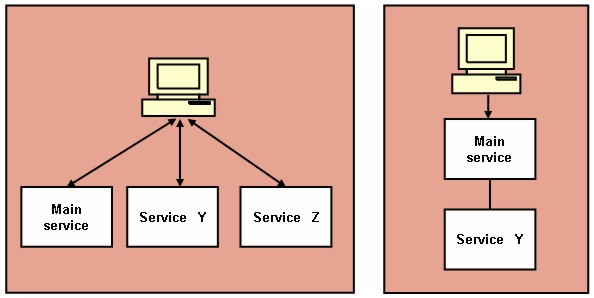
Figure 1 illustrates models that show the difference between two service concepts. In the model on the left a user can use the output from the main service function as input for a service of his choice (Y or Z). In the model on the right the main service is connected to Service Y, and the user doesn't have the option to choose Service Z. In order to offer flexibility to the user, it is necessary to make a clear distinction between data and presentation. It is the user's control over the presentation that gives him or her control over which data and which services to use, or how to use both. Two things must be noted here. First, there is a security issue involved in integrating services and data from different parties; users should accept functionality running in their browser only from trusted parties. Second, the integration of services can be a service in itself—running on a central system—and does not have to be running on the user's computer. This method is more secure, but it will result in the user having less control. Nevertheless, conceptually the model remains the same. I have reviewed five areas of the KB's information infrastructure and recommendations for each are provided in the next section of this article. These five areas are:
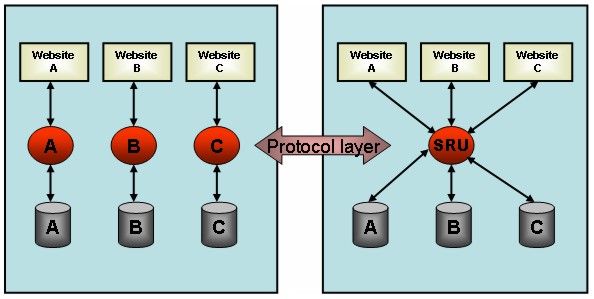
These areas have been reviewed in the current KB infrastructure with the flexible model described above in mind, but they are not restricted by any specific project or application, and the five areas were reviewed in combination with an extensive user scenario. Thus we have established how infrastructures need to develop to become more generic, more powerful and extensible with respect to the integration of services while at the same time retaining low implementation barriers. Concurrently, we evaluated available standards to see which ones are expected to become important in the near term and which we need to watch very closely in order to incorporate those at the right moment. RecommendationsThe recommendations for each of the five areas listed above are summarized below. These recommendations do not specifically apply to the KB infrastructure but may be applied, in general, to the information infrastructure of other heritage institutions as well. Search and RetrievalIt is recommended to index all metadata in a single index, and use as few different databases as possible for storage. There are hardly any databases or collections for which the use of a specific database package is justified. When there is a choice between indexing distributed databases in a central index or performing federated searching in distributed databases, it is best to choose the central indexing. There are several reasons for this, but it should be sufficient to compare Google as a central index with a theoretical Google that would distribute every user search to all websites all over the world. A combination with federated searching remains needed for databases that do not allow harvesting into a central index or for focussing a search into a specific area. All metadata should be available via the SRU protocol and should comply with standard record schemas. This will allow searching with any SRU client in any compliant databases and provides full integration in a web environment. This is illustrated in Figure 2.
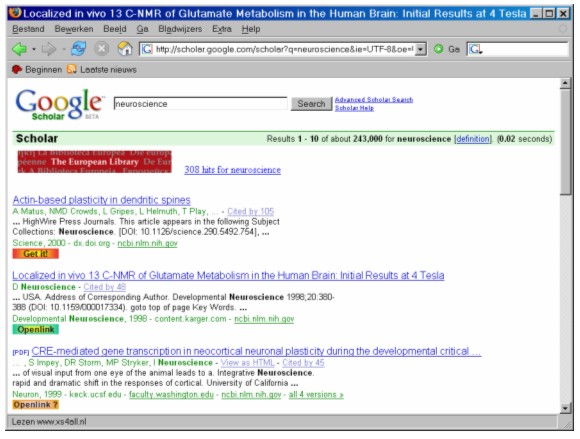
Use only XSL stylesheets for creating "data driven" user interfaces, and base these stylesheets as much as possible on the same template. Doing so will make it easier to create services and portals that can be tailored to different collections as well as to different audiences. These stylesheets should be implemented in a way that allows for XSL transformation at the client site as well as on a central server, depending on what the user wants or what the client is capable of. In this way users can select their preferred presentation at their desktops, but they will also be able to access the same data via a handheld device with a provider's presentation. Offer the client or user collection descriptions that are in compliance with the NISO standard for collection descriptions (under development) [2] and from which the user can choose targets. It is expected that modern clients will be able to process these "NISO-compatible" collection descriptions automatically and will make use of registries of services that provide these collection descriptions via SRU [14]. Integrate various types of metadata records describing different object types or relation types (e.g., a thesaurus) in a single index, and present these types of objects or relations according to their own metadata formats. Relations between the search terms and various metadata types are in this way available to the user or client as soon as the terms and metadata become relevant for navigation, without the user having to request them specifically. These relations can be used to suggest a new query to the user in an intelligent way that depends both on search results and the user's preferences. Search results: text and objectsThe results of search and retrieval can be quite diverse, ranging from a thesaurus record to compound multimedia objects. We make a distinction between results that are potential targets of our search for information (objects) and results that provide information that might be used to improve the search, like thesaurus relations (see below). Store compound objects containing text, images and fingerprints (a list of the statistically most significant words in a document) in a way that makes the complex objects self-describing. This will enable external parties or users to process the objects. In order to make objects self-describing, use a standard for describing the structure of the objects, such as MPEG-21 DIDL[11]. Standardize the syntax of links that point to the objects and sub-objects in order to improve navigation and the passing of parameters, in the same way as OpenURL does for metadata. (An example is given in Note 4.) In general, the result of a search is a list of records linking to different kinds of data that need their own processing. It is important to make a clear distinction between search and retrieval and navigation between different objects on one hand, and navigation within (compound) objects on the other hand. The reason for this is that the metadata schema for search and retrieval should comply with a few common standards focused on resource discovery and should not depend on the contents of individual objects. Besides that, the structure of objects can change over time, and therefore the object should be self-describing without the need for external metadata. (See Note 5 for more on this.) Search results: semantic relationsQuery results can also contain records with information meant to give the user suggestions to improve his or her query, such as thesaurus records. To be able to get these relations without having to solicit them, integrate full text indexing with the indexing of metadata describing objects, name authorities, thesauri and other databases containing semantic relations. Do not restrict searches to databases with the semantic relations of the organisation's own records, because relations found in external databases are equally useful for retrieving semantic relations. This semantic information may be used on a user request or, in case of unsatisfactory results, by a portal to suggest a new search based on these semantic relations. When these semantic relations can be obtained in XML, a service provider may add its own functionality when presenting them. (See Note 6 for an example and more detail.) MetadataMake all metadata available in standard XML formats with a vocabulary or schema that fits the nature of what these metadata are describing or for what the metadata are being used. At the same time allow for the controlled evolution of data models to enable new functionality. To make the organisation's metadata available to as many services as possible, provide these metadata at least in Dublin Core [3], in addition to the most appropriate schema for the specific object type (if this is available). Using Dublin Core as a minimum will allow access by generic search and retrieval applications without these applications needing to know the organization's specific schema for those metadata. (For more information, see Note 7.) Allow for extensions of Dublin Core that comply with DC Application Profiles, and make these extensions accessible under a single name (Dublin Core eXtended) to avoid making it necessary for data providers and service providers to be aware of all the possible variations on Dublin Core. This is possible because, in general, applications are capable of using the fields they understand and neglecting the fields they don't understand. (See Note 8.) Besides Dublin Core extended (DCX), it is advisable to offer metadata in the most appropriate commonly accepted standard record schemas. For example MARCXML [10] for bibliographic records, Zthes [21] for thesaurus records, EAD [6] for collection descriptions, etc. Because SRU enables records to be delivered to the desktop in XML, schema-based and web-based XML editors are recommended for editing XML records as an alternative for specific packages that need installation at the desktop. Because these XML records can come from anywhere, this edit facility will enable a very generic "copy cataloguing". Within a single institution, it will also lower the barrier for sharing metadata on a central location rather than storing metadata in local databases on the user's desktop computer. ResolutionWe recommend that all links to objects lead to an organisation's central resolver, allowing interception of all requests. This enables the translation of URL requests from one syntax to another syntax, redirection of requests to the right service, or responding with an appropriate error message. The resolution service should be capable of handling requests for NBN (National Bibliographic Number) or DOI (Digital Object Identifier) without the need for carrying out a bibliographic search, and is comparable to DOI resolution via CrossRef [5]. Anticipating a standard URL syntax for retrieving objects directly via standard identifiers embedded in a URL, such resolution service is easily modified to accept a new standard and translate these URLs to the existing URLs without modifying existing links to objects. OpenURL [13] resolution services should be seen as complementary to SRU (and not be confused with it). It is advisable to make a distinction between 1) resolution services for local users searching in the outside world who want to be linked to local services and 2) resolution services for external users searching in, for example, the KB, who want to be linked to their own local services. (For more information, see Note 9.) A good example of integration of information via the OpenURL concept is a Firefox browser extension from Peter Binkley [1] and Eric Hellman [8]. Their extension takes the Google Scholar response and creates OpenURL links for each item. The modification made by Hellman allows users to configure base-URLs to point to their own preferred OpenURL services. So for each item displayed in the Google response, the user can enter the specific metadata displayed by Google into his or her own preferred service with only one click. In Figure 3 below a screen dump is shown in which I used Peter Binkley's example and modified it even further. The links shown in the figure are the results of a SRU search after the page is displayed: when the item is found in the library, you may get the object directly, when not found in your organizations library, you may link to the OpenURL service.
Figure 3 is a good illustration of integration of services under the user's control, in this case being Google Scholar, a local SRU search and an OpenURL linking service. We expect in the near future more services to be integrated in this way and hope their responses will mainly be coded in XML (which makes this type of linking more reliable), because this example depends on screen scraping rather than machine-readability. AuthenticationThe purpose of authentication as discussed here is to establish a single sign-on in a non-heterogeneous environment and to reduce the maintenance of distributed user databases within the KB. It is best to gather different types of user data in a single database accessible via LDAP [9]. Because authorisation is not restricted to access to services, but also applies to authorisation within services, it is also best to use a single authentication token, encrypted according to an internal or global standard, to be exchanged between authentication server and requested services as a URL parameter or as a cookie. Future extensions, such as the use of authentication for authorisation by external services and vice versa, will require extensions of the KB authentication server and does not need specific recommendations at this stage. For authorisation to local KB services for users from external organisations and authorised by their own organisation, or providing authentication for KB users to access external services that require authorisation, using Shibboleth is recommended [15]. GeneralOne of the aims of the KB is to improve knowledge exchange with the outside world. This cannot be achieved by design and development only but also requires a lot of experimenting. For this purpose it is advisable to let the outside world share in the development efforts without the experimentation being hidden behind firewalls and other access restrictions. If organizations don't engage in this kind of sharing and experimentation, there is the danger that, in the end, many organisations will have developed their own internal protocols and metadata models that cannot be used externally. The philosophy behind the recommendations in this article is a simple one: most services have a base-URL and accept URL parameters in compliance with appropriate standards. The responses are in XML, which is also in compliance with standards. The combination results in machine-readable responses that can generate machine-readable requests to get information from services selected by users. The addresses (base URLs) of these services can be entered by users, but the addresses can also be obtained as part of the information from other services.
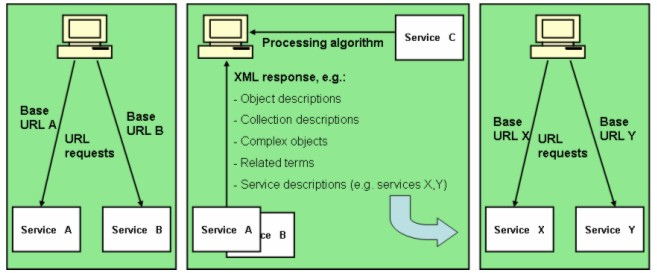
This concept is illustrated in Figure 4 above. As shown, we have four classes of components: 1) base URLs, 2) URL request syntaxes, 3) XML response schemas and 4) XSL processing algorithms that are mixed under the user's control. These components form the basis for a very flexible and intelligent way of linking information. In the recommendations URL-based requests have been assumed, but the proposed concept is also applicable in web services based on SOAP [17]. The implementation barrier for URL-based services is, however, assumed to be lower than for web services based on SOAP. ConclusionTo change an organization's information infrastructure according to the above recommendations requires changes in philosophy and strategy. The primary change is that we no longer consider the information infrastructure of organisations like the KB as closed systems but rather as a part of global knowledge, with users accessing various services to obtain information. Barriers to the adoption of new functionality can be lowered by integrating information from open, non-monolithic systems. This integration should take place under the user's control and preferably located on the user's desktop. By using appropriate standards and/or mechanisms, it is possible to integrate and link information without services having to be connected or even having to be aware of another service's existence. In the process of making these changes, we may discover that standards need to be changed or that we need to introduce new standards or contribute modifications to existing standards, but that is part of a normal technological evolution. Notes[1] When a user finds a description (metadata record) of an object, we will offer him services based on the fields in this description, such as related searches in other databases or services for translation of fields. On the other hand, when a user finds information elsewhere (for example, an article reference in Google), we should provide the functionality to link this information to the local services (e.g., to order a copy of that article held by the KB). In order to do so, we will mainly aim for machine readability of metadata, but screen-scraping techniques may be needed until the outside world joins us. [2] When a protocol defines request parameters and response fields, it should be possible for a service to add fields without introducing incompatibilities. Additionally, a mechanism is needed to find information about the added field such as its meaning and its potential usage. The client should be able to request a new field from services, without knowing whether or not a service has implemented that field, and still get a decent response rather than an error message. It is up to the client to recognize unknown or implemented fields and to let the user know about these fields. Registration of new parameters and fields—centrally or locally—should be a part of the protocol. [3] The SRU, OAI and OpenURL protocols define a standard URL syntax for requesting information. Such a URL can easily be dynamically generated and integrated within web pages. SRU and OAI also specify a standard response in XML. XSL is a language that can be used to transform XML responses into a webpage. Most modern browsers support this kind of transformation. This is particularly powerful in that users might choose to use XSL stylesheets from third parties to obtain functionality not offered by the provider of the requested XML data. [4] The original search term is an example of an extra parameter that can be passed as URL parameter when linking from the metadata to a full text object. The application presenting the full text can use this parameter for highlighting. To make this feature available for other portals that might link to this object, we need to create a mechanism to let the other portal know that it may provide the query as an extra parameter. This requires standardisation. An example URL is: http://host/application?collection=xyz&object=abc&role=thumbnail&query=test. The index entry will point to http://host/application?collection=xyz&object=abc as being the identifier of the compound object. The portal might add query=test to this URL in case the application providing the object will do something useful with the query (for example highlighting). The portal might add role=thumbnail to indicate that it does not expect the complete object but only a thumbnail to accompany the metadata. All the portal needs to know is that the identifier URL conforms to such a specific syntax. When the portal does not know the syntax of the URL for requesting this object, it will just use the URL as pointed to by the index. [5] Metadata should be useful for search and retrieval by external organisations without requiring additional knowledge of the metadata to be able to access the object. For example metadata should link to an appropriate point in an object, like a table of contents, and from this point the system or software that provides the object will provide the information for further navigation. When the structure of the object is changed, the table of contents within the object will change along with the structure of the object, but the metadata for resource discovery remain valid. [6] When, for example, a user searches for the wrong variant of an author name, the index might point to a name authority file where the correctly spelled name is found and that can then be used for doing a new search with the correct name. A similar example of a relation may be in a thesaurus record. As soon as a thesaurus record has been retrieved, new searches may be suggested based on the contents of that record. This does not have to be restricted to bibliographic records. A database with for example geographic names can relate places that are located near each other. A dictionary can relate different conjugations of verb, etc. The use of these extra records may depend on query results and query operators. For example, a query containing "close to Amsterdam" could trigger the use of a geographical database. A query giving too many hits may trigger the use of narrower terms from a thesaurus record. [7] It cannot be expected that external services are familiar with all record schemas (MARCXML records, HTML pages and so on), but it is expected that Dublin Core in most cases is supported. When users find records that are interesting enough but the user's application can only process Dublin Core rather than the original format, the users will at least be aware of these potentially interesting records and can undertake actions to retrieve and display the full records (e.g., by using the original user interface or by selecting a third-party browser extension for this record type). This is a typical example where control over the user interface is very useful. [8] This DCX concept becomes increasingly important because of the protocols like SRU and OAI-PMH that require both the data provider and the data requestor to know the record schemas that can be asked for. When a data provider finds out that extra fields are needed to offer extra functionality, the data provider can add these fields to a Dublin Core record and create a new record schema for it. Another provider might do the same with other fields. Portals that can be used to access different targets will in general continue to ask for Dublin Core. First suppose that a provider just adds some fields. Probably no client will notice because most applications will use stylesheets to retrieve specific fields and will not be aware of the extra fields. Now suppose that a client application can alert the user about the existence of these extra data; the user can ask his organisation to adapt the service to make use of the extra data. This would not have been possible if these extra data had to be requested specifically because a client won't ask for an unknown record schema. Requesting DCX in fact means, "give me qualified DC and any extra fields that you have available". [9] OpenURL is intended to link from one service to another service carrying original metadata in a standard way. An example is a resolution service that offers new links based on the context of the metadata, for example a link to amazon.com in order to buy a book or a link to a system providing the full text of an article described by the metadata. To link from metadata to services within an institution does not require OpenURL and can also be established just by direct dynamic links without an intermediate OpenURL resolution service. Better utilisation of OpenURL can be achieved by introducing a mechanism allowing users to define the location of their own OpenURL service. When a KB metadata record is retrieved and the KB service offers an OpenURL link, this link can then point to the services of the user's choice rather than to the KB's choice. Of course, other organisations are expected to do the same, and this requires a standard mechanism for setting a personalised base-URL that is not restricted to commercial implementations of a single vendor. See also [7]. References[1] Peter Binkley, Google Scholar OpenURLs—Firefox Extension, <http://www.ualberta.ca/~pbinkley/gso/>. [2] Standards in Development—NISO, <http://www.niso.org/committees/index.html>. [3] Dublin Core Metadata Initiative, <http://dublincore.org/>. [4] Theo van Veen and Bill Oldroyd, "Search and Retrieval in the European Library: A New Approach", D-Lib Magazine, Volume 10, Number 2, February 2004, <doi:10.1045/february2004-vanveen>. [5] The Digital Object Identifier System, <http://www.doi.org/>. [6] Encoded Archival Description, <http://www.loc.gov/ead/>. [7] Theo vanVeen, 2001, "Linking electronic documents and standardisation of URL's", paper presented at the European Library Automation Group 2001, Integrating Heterogeneous Resources, April 2001 Prague, available online at <http://www.stk.cz/elag2001/Papers/>. [8] Eric Hellman and Tom Ventimiglia, OpenURL Referrer, <http://www.openly.com/openurlref/>. [9] Lightweight Directory Access Protocol, <http://www.ietf.org/rfc/rfc2251.txt>. [10] MARC in XML, <http://www.loc.gov/marc/marcxml.html>. [11] MPEG-21, <http://www.chiariglione.org/mpeg/standards/mpeg-21/mpeg-21.htm>. [12] Open Archives Initiative-Protocol for Metadata Harvesting, <http://www.openarchives.org>. [13] The OpenURL Framework for Context-Sensitive Services, <http://www.niso.org/committees/committee_ax.html>. [14] Robert Sanderson, Jeffrey Young, Ralph LeVan, "SRW/U with OAI, Expected and Unexpected Synergies", D-Lib Magazine, Volume 11, Number 2, February 2005, <doi:10.1045/february2005-sanderson>. [15] Shibboleth Project, <http://shibboleth.internet2.edu/>. [16] Search/Retrieve Web Service, <http://www.loc.gov/z3950/agency/zing/srw/>. [17] Simple Object Access Protocol, <http://www.w3.org/TR/soap/>. [18] Z39.50 International Next Generation, <http://www.loc.gov./z3950/agency/zing/>. [19] Homepage of the European Library, <http://www.europeanlibrary.org>. [20] XSL Transformations, <http://www.w3.org/TR/xslt>. [21] Zthes: a Profile for Thesaurus Navigation in Z39.50 and SRW, <http://zthes.z3950.org/>. Copyright © 2005 Theo van Veen |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/march2005-vanveen
|