
D-Lib Magazine
June 1998
ISSN 1082-9873
Pass-Through Proxying as a Solution to the Off-Site Web-Access Problem
Richard Goerwitz
Brown University Scholarly Technology Group
Providence, Rhode Island
[email protected]

Abstract
This article outlines a system developed by Brown University's Scholarly Technology Group that provides a scalable, secure near-term solution to the problem of off-site access to IP-restricted Web resources.
Table of Contents
- The Problem
- Certificate Authorities
- Cross-Institutional Databases
- Existing Authentication Methods; Kerberos
- Proxy Servers
- Pass-Through Proxy Servers
- STG's Implementation
- URL Encapsulation
- Conclusions
The Problem
A mere ten years ago, access to vital institutional information resources was largely a matter of physical proximity. As information resources have made their way onto the Web, however, physical proximity has taken on an increasingly secondary role. This has created a critical problem for universities and their shared information resources: If physical presence is no longer necessary, how can we determine whether someone is a member of our community? That is, how can we authenticate them? And how can we verify that they should receive access to our licensed, site-restricted Web-based information resources?
Certificate Authorities
In efforts to overcome this authentication/access problem, many institutions are setting up certificate authorities (CAs), and are issuing public/private key-pairs to individual users -- key-pairs that must be carried around on floppy disks, copied across the network, or generated separately on every machine used, in order to gain off-cite access to all licensed, site-restricted networked resources.
Although these and other such efforts may prove viable in the longer run, they rely on fast-changing technologies. They also require that a whole new family of support software be put into place. And, realistically, all we are really looking for in a near-term solution to the Web-access problem is a secure test of membership in our community. All that is truly required, therefore, is a list of people who belong to that community, plus a list of passwords. Public/private key-based athentication schemes, at this stage, are overkill.
Cross-Institutional Databases
Another strategy that libraries in particular are using to solve their authentication problems is to piggyback on a separate cross-institutional user/password database run by a vendor, by an institutional consortium, or by a state library system.
Although this strategy is appropriate in many instances, in others it, like the CA solution, is overkill, requiring that a whole new infrastructure be put in place -- often not only for the participating institutions themselves, but also for the vendors whose information resources are being accessed. And typically, the authentication methods used in these instances are weak, depending on passwords passed as plain text over the network.
Existing Authentication Methods; Kerberos
Fortunately, many institutions already have the tools they need to authenticate users without establishing any such infrastructures. These tools come in the form of cluster login IDs or Kerberos principals, and passwords. The trick to any supportable, economical near-term solution to the Web-access problem is to make use of this existing infrastructure.
Unfortunately, integrating an existing authentication infrastructure, such as Kerberos, into generic commercial Web browsers has proven an arduous task, requiring the creation and/or formal support of specialized browser helper applications and plug-ins for every supported platform.
One way to lessen the amount of support required here is to piggyback existing authentication methods on clear-text "basic" Web authentication protocols. Such a move, however, makes it easy for someone with physical access to the network to steal IDs and passwords. In our (Brown University's) case, this was not an acceptable option. Perhaps more importantly, neither was it for many of the vendors whose databases we license.
In our opinion, then, a clean, workable solution to the Web-access problem must encrypt passwords. It must also work without extra plug-ins and helper applications. And to be economically viable and supportable, it must take full advantage of authentication systems that are already in place, and supported, on campus.
Proxy Servers
One tool for solving the Web-access problem that has recently gained much favor is the proxy server. A proxy server is an intermediary webserver that forwards HTTP requests from clients on to other servers, making those requests look like they originated with the proxy server. For a proxy server to work securely, however, some form of encrypted password or key-based authentication must be enabled between the client and the proxy. Most proxy servers, however, ship with the ability to do only basic or public/private-key based authentication (which, for reasons noted above, are not viable options for many institutions).
It is true that some proxy servers can be outfitted with special authentication packages. But doing this requires additional client-side software to work. This additional client-side software poses a problem because it creates the need for yet another layer of institutional software support. And by complicating client setup it ultimately reduces the accessibility of the proxy.
A further problem with proxy servers is that they are often tied to a specific Internet service provider (ISP). That is, many ISPs run firewalls that force customers to use their proxy. If a user dialing in through such an ISP tries to change her proxy configuration (e.g., to use the university's proxy), her browser may no longer function properly.
Pass-Through Proxy Servers
The only way to run a proxy service that any member of one's extended community can use is to run a reverse- or pass-through proxy (when outfitted with a cache, one also hears these called accelerators). A pass-through proxy is a proxy that masquerades as the remote server it is proxying for, such that the proxy appears to hold a mirror image of whatever is on the remote server.
The process works like this: An outside client (most often a web browser) requests a page from the pass-through proxy over a secured channel. The proxy, in turn, prompts the client for an ID and a password, if one was not provided. After clearing the ID and password with some local authentication system (e.g., a Kerberos keyserver), the pass-through proxy then fetches the requested page from the remote server (i.e., from the server it is mirroring). Finally, it sends the requested information to the client. Throughout this process, the remote server never talks directly to the client. Nor does the client (which sees the pass-through proxy as an origin webserver) ever talk directly to the remote server.
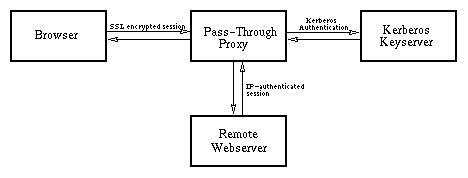
Because pass-through proxies look like origin (i.e., "normal") webservers, they can be used in conjunction with other proxies, or through a firewall -- just like any other webserver. And because pass-through proxies can easily be configured to run fully encrypted Secure Socket Layer (SSL) sessions, IDs and passwords can be passed back and forth through various networks without fear of snooping.
The only serious problem with using a pass-through proxy to solve the Web-access problem turns out to be that links branching off of pages fetched from the mirrored (i.e., origin) server will often connect users directly back to that server. The only way to avoid having users follow those links, and consequently leave the mirror that the pass-through proxy has created, is to insert a parsing module on the pass-through proxy that rewrites pages sent back to the user so that they contain no reference to the server of origin -- i.e., so that links back to the server of origin are replaced by links to the proxy.
STG's Implementation
At Brown University's Scholarly Technology Group, we implemented a pass-through proxy system that works along the above-described lines (with the parsing module that rewrites fetched pages so that they contain no reference to the server of origin). We used a locally modified copy of Apache as our Web server, compiled in support for Kerberos authentication, and set it up to operate in pass-through mode. We also wrote scripts to automate the process of adding new remote hosts to be proxied (the pass-through proxy only mirrors servers we explicitly tell it to; we regard this as a security feature).
As noted above, our basic constraints were that we had to leverage our existing campus Kerberos authentication infrastructure without passing around extra headers or cookies -- and without handing out clear-text passwords over the network. We also had a mandate to make the system work with Netscape 3.0 and higher, and to do so without forcing either our users, or our vendors, to install any plug-ins or helper applications. Our goal was to do this without imposing unreasonable performance penalties on users, and without leaving users coming from firewalled ISPs out in the cold.
Although our system ended up meeting all of these constraints, it did not end up completely transparent to the user -- due mainly to the problems with buggy Web clients, firewalled ISPs, and the inherently complex nature of pass-through proxies as mirrors, or stand-ins, for origin webservers (with pass-through proxies, you can't just add a machine name to the browser's proxy configuration menu).
Our remedy for the system's lack of complete transparency was to provide solid "in case you're off campus" documentation and an informative bounce page to redirect users who have found themselves locked out of a resource when coming in from off-site. We also offered local Brown webmasters extensive documentation on how to create entry points into the proxy service (e.g., alternate on-campus and off-campus links to IP-restricted library services; a general "in case you're off campus" link). This required some extra work on the systems end, but was worth the effort.
In the four months that we have been testing it, we have found our system to be flexible, extensible, fairly fast, and (now that the initial overhead of developing it is past) low-cost. The only serious, systematic problems we have found to date are that the parsing module that rewrites fetched pages will not work for pages that use Java to open certain network connections. It will also fail to catch certain pages that use Java or JavaScript to compose URLs on the fly. We also foresee a problem if our vendors start using domain-restricted HTTP cookies for authentication and state-maintenance (we have a workaround ready for this, in case). And finally, the system as a whole is limited by the fact that it only works with pages protected by IP-based authentication.
In our testing, we have had little trouble mirroring hundreds of remote webservers, and servicing hundreds of thousands of user requests. The system, therefore, will scale well beyond what we foresee needing (we currently proxy fewer than two dozen remote servers and service at most a thousand hits per day).
URL Encapsulation
It is worth noting that a system very much like STG's pass-through proxy has recently been announced by the University of Virginia (UVa). This system, called mIm, uses encapsulated remote IP-restricted URLs. Whenever a Library patron follows a link to a UVa IP-authenticated resource, that patron's browser sends an encapsulated URL to the server running mIm, which in turn unpacks this encapsulated URL, calls up the remote server the URL references, and then passes the remote server's response back to the user -- rewriting the HTML on the return trip in much the same way as STG's pass-through proxy.
Documentation on the UVa system is limited right now. There is, however, a brief but lucid set of project specs. More documentation is on its way. Stay tuned.
Conclusions
We feel that, for the near-term, the most sensible way of obtaining a simple, economical solution to the limited problem of off-campus access to source-IP authenticated campus Web resources is to pick a cheap, solid solution, to make it work, then to wait a year or two until the landscape changes, and see if another solution presents itself (ideally one that ties into some major distributed authentication infrastructure).
We chose a pass-through proxy server as our solution because it was relatively easy to implement; it requires no special client-side or vendor-side software; it necessitates only a few simple changes to client browser configurations; it is cheap to run, relatively easy to use, tolerably fast (especially with caching turned on); and it is secure. Although the pass-through proxy server only handles IP-authenticated resources, and although it is not as transparent as we would have liked, we have found it to be well suited to our modest needs during this transitional time.
Copyright © 1998 Richard Goerwitz
Top | Magazine
Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editorhdl:cnri.dlib/june98-goerwitz