|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Lois Mai Chan Marcia Lei Zeng |
![]()
AbstractThe rapid growth of Internet resources and digital collections has been accompanied by a proliferation of metadata schemas, each of which has been designed based on the requirements of particular user communities, intended users, types of materials, subject domains, project needs, etc. Problems arise when building large digital libraries or repositories with metadata records that were prepared according to diverse schemas. This article (published in two parts) contains an analysis of the methods that have been used to achieve or improve interoperability among metadata schemas and applications, for the purposes of facilitating conversion and exchange of metadata and enabling cross-domain metadata harvesting and federated searches. From a methodological point of view, implementing interoperability may be considered at different levels of operation: schema level, record level, and repository level. Part I of the article intends to explain possible situations in which metadata schemas may be created or implemented, whether in individual projects or in integrated repositories. It also discusses approaches used at the schema level. Part II of the article will discuss metadata interoperability efforts at the record and repository levels. 1. IntroductionIn response to the rapid development of digital libraries and repositories, many general and domain-specific metadata standards have been developed or proposed by various user communities. Even within the same subject domain or for the same type of resource, there are often two or more options of metadata standards. In building a large digital library or repository, an issue often encountered is that the participants may have used diverse schemas and description methods to create their metadata records. Ideally, users of such a digital library or repository "should be able to discover through one search what digital objects are freely available from a variety of collections, rather than having to search each collection individually" [Tennant, 2001]. In other words, users should not have to know or understand the methods used to describe and represent the contents of the digital collection. However, in reality, the diversity of standards for the description of varying types of resources, sometimes within the same digital library or repository, poses particular challenges to users as well as those who are responsible for managing these resources. Only if devices can be developed to attain interoperability will it be possible to facilitate the exchange and sharing of data prepared according to different metadata schemas and to enable cross-collection searching. In recent literature, a great deal has been written about achieving interoperability among different metadata schemas. A methodological analysis of interoperability focusing on knowledge organization systems (KOS) was presented in a previous article by the authors [Zeng and Chan, 2004]. This article analyzes some of the methods currently used to achieve interoperability in a broader context, that is, among different metadata schemas and applications. 2. Definitions2.1 Metadata SchemaA metadata schema consists of a set of elements designed for a specific purpose, such as describing a particular type of information resource [NISO, 2004]. As defined in the report of the American Library Association Committee on Cataloging: Description and Access (CC:DA) Task Force on Metadata: "A metadata schema provides a formal structure designed to identify the knowledge structure of a given discipline and to link that structure to the information of the discipline through the creation of an information system that will assist the identification, discovery, and use of information within that discipline" [CC:DA, 2000]. In the literature, the words "schema", "scheme", and "element set" have been used interchangeably to refer to metadata standards. In practice, the word "schema" usually refers to an entire entity including the semantic and content components (which are usually regarded as an "element set") as well as the encoding of the elements with a markup language such as SGML (Standard Generalized Markup Language) and XML (Extensible Markup Language). A metadata element set has two basic components:
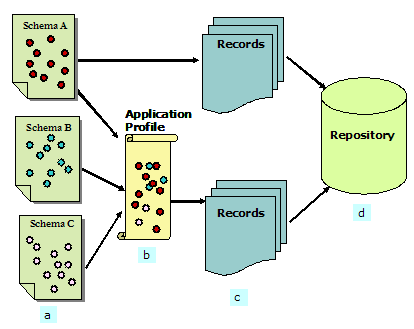
For each element defined, a metadata standard usually provides content rules for how content should be included (for example, how to identify the main title), representation rules for content (for example, capitalization rules or standards for representing time), and allowable content values (for example, whether values must be taken from a specified controlled vocabulary or can be author-supplied, derived from text, or added by metadata creators working without a controlled term list.) It is our observation that many metadata standards provided an element set without considering the encoding format in their preliminary versions. For example, Dublin Core (DC), VRA (Visual Resource Association) Core Categories, Categories for the Description of Works of Art (CDWA), and the Learning Object Metadata (LOM) were all published and accepted in terms of their semantics and content long before the specific encoding methods for their data models were published. On the other hand, a few other metadata standards, like the Encoded Archival Description (EAD) Document Type Definition (DTD), provided an encoded element set from the beginning. The EAD DTD, a standard for encoding archival finding aids currently using XML, was published a decade ago with an SGML DTD [Library of Congress, 2003]. In this article, the term "schema" is used to refer to all metadata standards being discussed, although most of the time the focus of the discussion will be on the semantics and content of the schemas. 2.2 InteroperabilityThere have been many attempts at defining the concept of interoperability. A few examples are given below: "Interoperability is the ability of multiple systems with different hardware and software platforms, data structures, and interfaces to exchange data with minimal loss of content and functionality" [NISO, 2004]. "Interoperability is the ability of two or more systems or components to exchange information and use the exchanged information without special effort on either system" [CC:DA, 2000]. "Interoperability: The compatibility of two or more systems such that they can exchange information and data and can use the exchanged information and data without any special manipulation" [Taylor 2004, p. 369]. It is becoming generally accepted in the information community that interoperability is one of the most important principles in metadata implementation. Other basic metadata principles include simplicity, modularity, reusability, and extensibility [Duval et al., 2002; Zeng et al., 2003]. These principles inform metadata database design as well as other system-dependent developments. From the very beginning of a metadata project, the principles that enable user-centered and interoperable services should be foremost in design and implementation. 3. Metadata Interoperability Projects at Different LevelsIn recent years, numerous projects have been undertaken by the many players and stakeholders in the information community to achieve interoperability among different metadata schemas and their applications. Ideally, a uniform standard approach would ensure maximum interoperability among resource collections. If all participants of a consortium or repository were required to use the same schema, such as the MARC (Machine-Readable Cataloging) format or the Dublin Core (DC), a high level of consistency would be maintained. This, of course, has been the approach in the library community for over a century and is the ultimate solution to the interoperability problem. However, although it is a conceptually simple solution, it is not always feasible or practical, particularly in heterogeneous environments serving different user communities where components or participating collections contain different types of resources already described by a variety of specialized schemas. The uniform standardization method is only viable at the beginning or early stages of building a digital library or repository, before different schemas are adopted by the participants. Examples include the MARC standards used in union catalogs of library collections and the Dublin Core-based Electronic Theses and Dissertations Metadata Standard (ETD-MS) used by members of the Networked Digital Library of Theses and Dissertations (NDLTD). In many communities, the uniform standard approach may not be applicable, therefore other mechanisms of achieving interoperability must be adopted. From a methodological point of view, implementing interoperability may be considered at different levels: schema level, record level, and repository level. (Figure 1)
Figure 1 intends to explain possible paths from creation of schemas to their applications in individual projects or in integrated repositories. The situations could be:
Each of these approaches can have particular focuses, and interoperability efforts can take place at any level. From another perspective, the results of interoperability efforts can be observed at different levels as well:
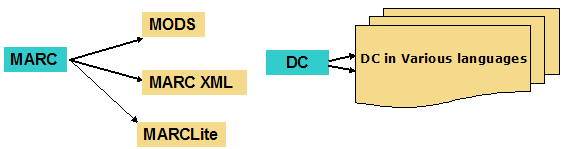
It should be noted that the models to be discussed in this article are not always mutually exclusive. Sometimes, within a particular project, more than one method may be used. 4. Achieving Interoperability at the Schema LevelBefore a project selects and applies a metadata schema to its collection, an important step is to ensure that the data processed according to a given schema will result in a digital collection that is interoperable with other digital collections or systems. At the schema level, interoperability actions usually take place before operational level metadata records are created. The actions focus on the elements (independent of individual applications). Methods used to achieve interoperability at this stage mainly include: derivation, application profiles, crosswalks, switching-across, framework, and registry. What follows is a discussion of each of these methods. 4.1 DerivationIn this approach, a new schema is derived from an existing one. In a collection of digital databases where different components have different needs and different requirements regarding description details, an existing complex schema such as the MARC format may be used as the "source" or "model" from which new and simpler individual schemas may be derived. Specific derivation methods include adaptation, modification, expansion, partial adaptation, translation, etc. In each case, the new schema is dependent on the source schema. This approach ensures a similar basic structure and common elements while allowing different components to vary in depth and details. For example, the TEI Lite is derived from the full Text Encoding Initiative (TEI). Both MODS (Metadata Object Description Schema) and MARC Lite are derived from the full MARC 21 standard. Changes could also occur in the encoding format (e.g., MARCXML), but the basic original content elements are retained (Figure 2). A similar approach to derivation is translation of an existing schema into a different language. The content remains largely the same as the source schema. Examples include different language versions of the Dublin Core element set.
Yet another variation is the adaptation of an existing schema with modifications to cater to local or specific needs. This approach reflects the extensibility principle of metadata. Extensible metadata systems must allow for extensions and expansions so that particular needs of a given application can be accommodated. Examples of adaptation/modification include:
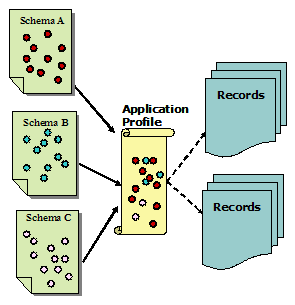
It should be noted that the element sets following the extension approach are sometimes regarded as application profiles as well. 4.2 Application ProfilesEven within a particular information community, there are different user requirements and special local needs. The details provided in a particular schema may not meet the needs of all user groups. Therefore, based on the notion that metadata standards are necessarily localized and optimized for specific contents, the concept of "application profiles", a typical approach to accommodating individual needs, emerged [Johnston, 2003]. While a particular existing schema or schemas are used as the basis for description in a particular digital library or repository, individual needs are met through a set of specific application guidelines or policies established for a particular interest or user group.
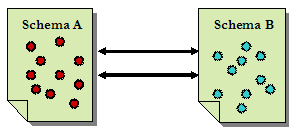
According to the Dublin Core Metadata Initiative (DCMI) Usage Board, "an Application Profile (AP) is a declaration of which metadata terms an organization, information resource, application, or user community uses in its metadata" [Baker, 2003]. The use of application profiles ensures a similar basic structure and common elements, while allowing for varying degrees of depth and detail and for different user communities. Application profiles usually consist of metadata elements drawn from one or more metadata schemas (see Figure 3), combined into a compound schema by implementors, and optimized for a particular local application [Heery and Patel, 2000; Duval et al., 2002]. For example, the Australasian Virtual Engineering Library's AVEL Metadata Set consists of nineteen elements. In addition to supporting 14 DC elements (excluding dc.source element), it also supports one AGLS (Australian Government Locator Service) metadata element (AGLS.Availability), one EDNA (Education Network Australia) element (EdNA.Review), and three Administrative elements (AC.Creator, AC.DateCreated, and AVEL.Comments). An application profile (AP) may also be based on one single schema but tailored to different user communities. For example, DC-Library Application Profile (DC-Lib) clarifies the use of the DC metadata element set in libraries and library-related applications and projects. The DC Government Application Profile clarifies the use of DC in a government context [Cumming et al., 2001]. Another example is the Biological Data Profile of the National Biological Information Infrastructure (NBII), which is based on the Content Standard for Digital Geospatial Metadata (CSDGM) of the Federal Geographic Data Committee (FGDC). A blurred area for AP implementors exists: Can an AP declare new metadata terms (elements and refinements) and definitions? The answer is that, by definition, an AP cannot "declare" new metadata terms and definitions. Heery and Patel (2000) highlighted the characteristics of Application Profiles that may draw on one or more existing namespaces, may introduce no new data elements, may specify permitted schemes and values and, can refine standard definitions. They commented further that "If an implementor wishes to create 'new' elements that do not exist elsewhere then (under this model) they must create their own namespace schema, and take responsibility for 'declaring' and maintaining that schema." Dublin Core Application Profile Guidelines [CEN, 2003] also includes instructions on "Identifying terms with appropriate precision" (Section 3) and "Declaring new elements" (Section 5.7). An AP may also provide additional documentation on how the terms used are constrained, encoded, or interpreted for particular purposes [Baker, 2003]. In practice, then, the implementation of an application profile often involves the following steps: (1) selecting a "base" metadata namespace, (2) selecting elements from other metadata namespaces, (3) defining local metadata elements and declaring new elements' namespaces, and (4) enforcing application of the elements (including cardinality enforcement, value space restriction, and relationship and dependency specification) [Zhang, 2004; Duval et al., 2002]. The SCHEMAS Registry (to be discussed in 4.6 Metadata Registry section), a registry of application profiles maintained by the UK Office for Library and Information Networking (UKOLN), contains several metadata element sets as well as a large number of activity reports that describe and comment on various metadata related activities and initiatives. 4.3 CrosswalksA crosswalk (Figure 4) is "a mapping of the elements, semantics, and syntax from one metadata scheme to those of another" [NISO, 2004]. Currently, crosswalks are by far the most commonly used method to enable interoperability between and among metadata schemas. This method begins with independent metadata schemas. Attempts are made to map or create crosswalks between equivalent or comparable metadata terms (elements and refinements). (Note that sometimes other terms are used to refer to "element," such as "field", "label", "tag", etc.) The mechanism used in crosswalks is usually a chart or table that represents the semantic mapping of data elements in one data standard (source) to those in another standard (target) based on the similarity of function or meaning of the elements [Baca et al., 2000].
Crosswalks allow systems to effectively convert data from one metadata standard to another. They enable heterogeneous collections to be searched simultaneously with a single query as if they were a single database (semantic interoperability). In recent years, major efforts in metadata mapping have produced a substantial number of crosswalks. Almost all schemas have created crosswalks to popular schemas such as DC, MARC, LOM, etc. Metadata specifications may also include crosswalks to a previous version of a schema as well as to other metadata schemas. An example is the VRA Core 3.0, which lists mapped elements in target schemas VRA 2.0 (an earlier version), CDWA, and DC. The predominant method used in crosswalking is direct mapping or establishing equivalency among elements in different schemas. Metadata "mapping" refers to a formal identification of equivalent or nearly equivalent metadata elements or groups of metadata elements from different metadata schemas, carried out in order to facilitate semantic interoperability [Baca et al., 2000]. Quite a few metadata properties need to be brought into consideration in the mapping. According to the NISO document Issues in Crosswalking Content Metadata Standards [St. Pierre and LaPlant, 1998], common properties may include:
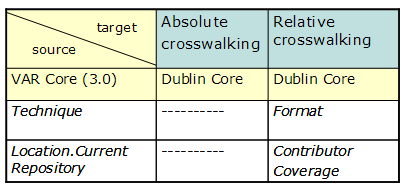
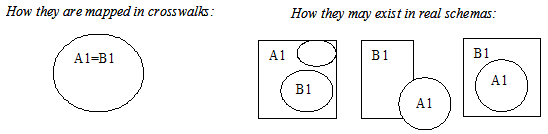
Two approaches have been used in crosswalking practice. The "absolute crosswalking" approach requires exact mapping between the involved elements (say, vra.title → dc.title) of a source schema (e.g., VRA Core) and a target schema (e.g., DC). Where there is no exact equivalence, there is no crosswalking (e.g., vra.technique → [empty space]) (see Figure 5). Absolute crosswalking ensures the equivalency (or closely-equivalent matches) of elements, but does not work well for data conversion. The problem is that data values in non-mappable space will be left out, especially when a source schema has a richer structure than that of the target schema. To overcome this problem, an alternative approach, "relative crosswalking", has been used to map all elements in a source schema to at least one element of a target schema, regardless of whether the two elements are semantically equivalent or not (e.g., vra.technique → dc.format) (also see Figure 5). The relative crosswalking approach appears to work better when mapping from complex to simpler schema (e.g., from MARC to DC, but not vice versa).
One of the problems of crosswalking is the different degrees of equivalency: one-to-one, one-to-many, many-to-one, and one-to-none [Zeng and Xiao, 2001]. These situations occur in many metadata crosswalks. The level of details may extend from elements-only to elements-plus-qualifiers/refinements or sub-elements. However, usually only the names of the elements and their definitions are taken into consideration in a crosswalk.
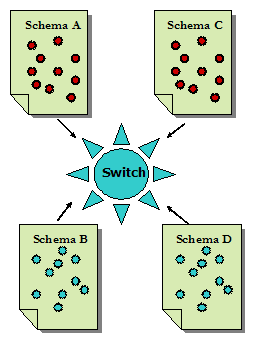
This means that when mapping individual elements, often there are no exact equivalents. Meanwhile, many elements are found to overlap in meaning and scope. For this reason, data conversion based on crosswalks could create quality problems. This issue will be discussed further in section 2.1 Conversion of Metadata Records in Part II of the article. 4.4 Switching-acrossWhile crosswalking works well when the number of schemes involved is small, mapping among multiple schemas is not only extremely tedious and labor intensive but also requires enormous intellectual effort. For example, a one-way crosswalk requires one mapping process (A→B), and a two-way crosswalk requires two mapping processes (A→B and B→A). The process becomes more and more cumbersome when more schemas are involved. A four-schema crosswalk would require twelve (or six pairs of) mapping processes. As a result, using a switching schema (new or existing) to channel crosswalking among multiple schemas has become a well-accepted solution (see Figure 7).
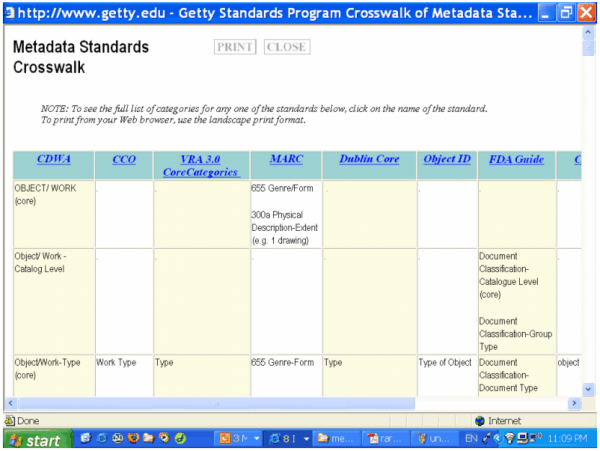
In this model, one of the schemas is used as the switching mechanism among multiple schemas. Instead of mapping between every pair in the group, each of the individual metadata schemas is mapped to the switching schema only. An example is Getty's crosswalk in which seven schemas all crosswalk to CDWA [Harpring et al., 2000].
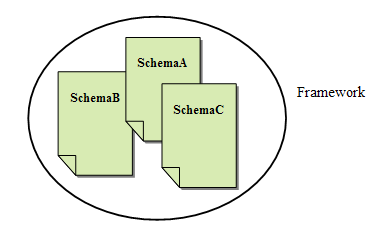
4.5 Metadata FrameworkA framework can be considered as a skeleton upon which various objects are integrated for a given solution (see Figure 9). The need for a metadata framework is best demonstrated by emerging digital preservation efforts. While many organizations have developed metadata for digital preservation in support of their own activities, such efforts have been conducted largely in isolation, lacking any substantial degree of cross-organizational coordination. It becomes obvious that a metadata framework is needed to represent a consensus of leading experts and practitioners and could be readily applied to a broad range of such activities [OCLC/RLG Working Group on Preservation Metadata, 2002]. In 2002, a conceptual framework for a generic digital archiving system emerged in the form of an Open Archival Information System (OAIS) reference model and was issued as a recommendation by the ISO Consultative Committee for Space Data Systems (CCSDS). It establishes a common framework of terms and concepts that comprise an Open Archival Information System, providing a basis for further standardization within an archival context.
Another example comes from the metadata framework currently used in the DLESE (Digital Library for Earth System Education) Discovery System. After a few years' exploration of establishing a framework for DLESE metadata based on IMS (Instructional Management Systems) Learning Resource Meta-data Specification, the Alexandria Digital Earth Prototype (ADEPT ) project, DLESE, and NASA's Joined Digital Library (JDL) decided in June 2001 to create an ADN metadata framework that all three organizations can use [ADN]. The purpose of the ADN framework, as stated on its web page, is to "describe resources typically used in learning environments (e.g., classroom activities, lesson plans, modules, visualizations, some datasets) for discovery by the Earth system education community" [ADN Framework webpage, 2005]. The content information in a metadata record includes the following categories of elements, among which Educational and Spatial & Temporal (highlighted by the authors) are unique:
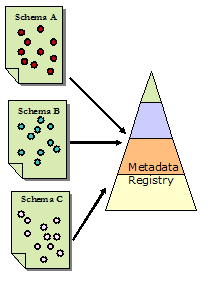
(Source: ADN Framework webpage) The examples cited above show that two approaches are possible for building a metadata framework: 1) establishing a framework before the development of individual schemas and applications, and 2) building a framework based on existing schemas. Regardless of which approach is used, the function of a metadata framework is to provide a suitable environment for the diverse audiences of involved communities. 4.6 Metadata RegistryThe purpose of a metadata registry is fairly straightforward: to collect data regarding metadata schemas. Because the reuse of existing metadata terms is essential to achieving interoperability among metadata element sets, the identification of existing terms becomes a prerequisite step in any new metadata schema development process. Thus the presence of a metadata registry application "promotes the wider adoption, standardization and interoperability of metadata by facilitating its discovery, and reuse, across diverse disciplines and communities of practice" [Dublin Core Metadata Registry]. Metadata registries are expected to "provide the means to identify and refer to established schemas and application profiles, potentially including the means for machine mapping among different schemas. In addition, it is expected that such registries will contain, or link to, important controlled vocabularies from which the values of metadata fields can be selected" [Duval et al., 2002]. The preliminary functions of metadata registries include registering, publishing, and managing schemas and application profiles, as well as making them searchable. A registry also provides services for crosslinking and crosswalking among schemas and application profiles (see Figure 10).
The basic components of a metadata registry may include the identifications of data models, elements, element sets, encoding schemes, application profiles, element usage information, and element crosswalks. Despite these common components, each registry usually has a specific scope. The following examples represent four different registry ranges:
As Duval et al. (2002) have pointed out, the importance of the management and disclosure roles of registries will increase as more metadata and application profile schemas are developed. 5. Other ApproachesIn the open, networked environment that encompasses multiple user communities using a multitude of standards for description of digital resources, the need for interoperability among metadata schemas is paramount. To enable federated searches and to facilitate metadata management, much effort has been devoted to achieving or improving interoperability among metadata records. As discussed in this article, efforts to improve interoperability can take place at different levels – schema, record, and repository levels. So far we have discussed methods used by selected projects to achieve interoperability at the schema level. The second part of this article (published in this same issue) summarizes methodologies used at the record level and the repository level. At the record level, approaches widely applied include converting metadata records and reusing and integrating data. At the repository level, metadata harvesting and federated searches benefit from the Open Archives Initiative (OAI) Protocol. Meanwhile, there also exist repositories that support multiple formats without record conversion. Other interesting processes or ideas related to ensuring interoperability at the repository level include aggregation, crosswalking services, value-based mapping for cross-database searching, and value-based co-occurrence mapping. As mentioned earlier, the models discussed in this article are not always mutually exclusive. Sometimes, within a particular project, more than one method may be used. AcknowledgementsThe authors express their thanks for the help and support of Dr. Theodora Hodges (Berkeley, CA), Katy Ginger (DLESE), Dr. Athena Salaba (Kent State University), and Samantha Nicholson (Kent State University). Sources and ReferencesSources(Metadata schemas, application profiles, and registries mentioned in Part I of the article)
ADN (ADEPT/DLESE/NASA) Framework
AGLS (Australian Government Locator Service) Metadata Standard
AVEL (Australasian Virtual Engineering Library) Metadata Set
Biological Data Profile of the Content Standard for Digital Geospatial Metadata
Categories for the Description of Works of Art (CDWA)
Content Standards for Digital Geospatial Metadata (CSDGM)
CORES Registry
DC (Dublin Core) Metadata Element Set
DC-Education Application Profile
DC-Library Application Profile (DC-Lib)
Dublin Core Metadata Registry
Encoded Archival Description (EAD)
ETD-MS: an Interoperability Metadata Standard for Electronic Theses and Dissertations.
GEM (The Gateway to Educational Materials) Element Set
IMS (Instructional Management Systems) Learning Resource Meta-data Specification
Learning Object Metadata (LOM)
MARC (MAchine-Readable Cataloging) Formats
MARCLite
MARCXML
MEG Registry (Registry of MEG-related schemas)
OAIS (Reference Model for an Open Archival Information System)
SCHEMAS Registry – Application Profiles
TEI: The Text Encoding Initiative
TEL (The European Library) Application Profile for Objects
VRA (Visual Resources Association) Core Categories, 3.0 ReferencesADN Framework webpage. (2005). Available: <http://www.dlese.org/Metadata/adn-item/index.htm>. Baca, M. Gill, T., Gilliland, A.J., & Woodley, M.S. (2000). Introduction to metadata: pathway to digital information. Online edition 2.1. Glossary. Available: <http://www.getty.edu/research/conducting_research/standards/intrometadata/glossary.html>. Baker, T. (2003). DCMI Usage Board review of application profiles. Available: <http://dublincore.org/usage/documents/profiles/index.shtml>. CC:DA (ALCTS/CCS/Committee on Cataloging: Description and Access). (2000). Task Force on Metadata: Final report, June 16, 2000. Available: <http://www.libraries.psu.edu/tas/jca/ccda/tf-meta6.html>. CEN (European Committee for Standardization). (2003). Dublin Core application profile guidelines. CEN Workshop Agreement, CWA 14855. Available: <ftp://ftp.cenorm.be/PUBLIC/CWAs/e-Europe/MMI-DC/cwa14855-00-2003-Nov.pdf>. Cumming, M. et al., (2001). Government Application Profile. A DCMI working draft. Available: <http://dublincore.org/documents/2001/09/17/gov-application-profile/>. Duval, E., Hodgins, W., Sutton, S. & Weibel, S.L. (2002). Metadata principles and practicalities. D-Lib Magazine, 8(4). Available: <doi:10.1045/april2002-weibel>. Harpring, P., Woodley, M., Gilliland-Swetland, A., & Baca, M. (Compile). (2000) Metadata standards crosswalks. In: Baca, M. et al. (2000) Introduction to metadata: pathway to digital information. Available: <http://www.getty.edu/research/conducting_research/standards/intrometadata/3_crosswalks/>. Heery, R., & Patel, M. (2000). Application profiles: mixing and matching metadata schemas. Ariadne, Issue 25. Available: <http://www.ariadne.ac.uk/issue25/app-profiles/intro.html>. Johnston, P. (2003). Metadata and interoperability in a complex world. Ariadne, 37. Available: <http://www.ariadne.ac.uk/issue37/dc-2003-rpt/>. Library of Congress, Development and MARC Standards Office. (2003). Development of the Encoded Archival Description DTD. Available: <http://www.loc.gov/ead/eaddev.html>. NISO (National Information Standards Organization). (2004). Understanding metadata. Bethesda, MD: NISO Press. Available: <http://www.niso.org/standards/resources/UnderstandingMetadata.pdf>. OCLC/RLG Working Group on Preservation Metadata. (2002). Preservation Metadata and the OAIS Information Model, A Metadata Framework to Support the Preservation of Digital Objects. Available: <http://www.oclc.org/research/projects/pmwg/pm_framework.pdf>. St. Pierre, M. & LaPlant, W.P. Jr. (1998). Issues in crosswalking content metadata standards. Bethesda, MD: NISO Press. Available: <http://www.niso.org/press/whitepapers/crsswalk.html>. Taylor, A. (2004). The Organization of Information. 2nd ed. Westport, CN: Libraries Unlimited. Tennant, R. (2001). Different paths to interoperability. Library Journal, 126(3):118-119. Van Veen, T. & Oldroyd, B. (2004). Search and Retrieval in The European Library, a new approach. D-Lib Magazine, 10(2). Available: <doi:10.1045/february2004-vanveen>. Yao, B., Zhang, L., Yu, Y., & Miao S. (2004). Rare materials descriptive metadata standard: Its design and implementation. Available: <http://www.idl.pku.edu.cn/pdf/rarebook_metadata.pdf>. Zeng, M.L. (2001). Supporting metadata interoperability: trends and issues. In: C.C. Chen (Ed.): Global digital library development in the new millennium. Beijing: Tsinghua University Press. pp. 405-412. Zeng, M.L., Zhang, F.J., & Zhang, X. (2003). Metadata standards at Internet arena. Journal of Library Science in China, 29(4):10-14. Zeng, M.L. & Chan, L.M. (2004). Trends and issues in establishing interoperability among knowledge organization systems. Journal of the American Society for Information Science and Technology (JASIST) 55(5): 377 – 395 Zeng, M.L., & Xiao, L. (2001). Mapping metadata elements of different format. E-Libraries 2001, Proceedings, May 15-17, 2001, New York: 91-99. Medford, NJ: Information Today, Inc. Zhang, X. (2004). Tutorial on Metadata. In: Tutorials, 7th International Conference of Asian Digital Libraries (ICADL). December 13-17, 2004, Shanghai China: 107-136. Printed by Shanghai Jiaotong University Library. Copyright © 2006 Lois Mai Chan and Marcia Lei Zeng |
|
| |
|
|
Top | Contents | |
| | |
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/june2006-chan
|
{kind=link}