Elizabeth J. Shaw
Digital Project Librarian
[email protected]
Sarr Blumson
Chief Programmer
Digital Library Production Services
[email protected]
Harlan Hatcher Graduate Library, Rm 308
University of Michigan
Ann Arbor, Michigan

Introduction
Project Background
The University of Michigan Online Implementation
In this paper, we will describe the unique aspects of the first phase of the University of Michigan's implementation of the Making of America Project (http://www.umdl.umich.edu/moa/), a collaborative effort with Cornell University. Using "raw" uncorrected results of automated optical character recognition (OCR) of the page images, and SGML-encoding of the ensuing textual information in minimal Text Encoding Initiative (TEI) conformant markup, we can provide a searchable database of the roughly 650,000 page images that comprise our portion of the Making of America Project. We provide access to the page images on the Web without special viewing tools through a page delivery system that converts the requested pages from TIFF to GIF format on the fly. We will also describe how our approach will allow us to extend functionality as time and resources become available.
Making of America (MOA) represents a major collaborative endeavor to preserve and make accessible through digital technology a significant body of primary sources related to American social history. With funding from the Andrew W. Mellon Foundation the initial phase of the project, initiated in the fall of 1995, has focused on developing a collaborative effort between the University of Michigan and Cornell University. Drawing on the depth of primary materials at the Michigan and Cornell libraries, these two institutions are developing a thematically-related digital library documenting American social history from the antebellum period through reconstruction. Approximately 5,000 volumes with imprints between 1850 - 1877 will have been selected. Both institutions are now in the process of having the materials scanned and are making them available via the Word Wide Web. Librarians, researchers, and instructors are working together to determine the content of this digital library and to evaluate the impact of this resource on research and teaching at both institutions. The Cornell Making of America pages are available at: http://moa.cit.cornell.edu/.
When the initial phase of the project is completed, the MOA collection will include over 1.5 million page images. The selection process at Michigan has focused on monographs in the subject areas of education, psychology, American history, sociology, science and technology, and religion. The Cornell process has focused on the major serials of the period, ranging from general interest publications to those with more targeted audiences. At both institutions, subject-specialist librarians are working closely with faculty in a variety of disciplines to identify materials which will be most readily applicable to research and teaching needs.
The thematic focus of the initial phase -- antebellum period through reconstruction, 1850-1877 -- was chosen for several reasons:
At both institutions, the materials in the MOA collection are scanned from the original paper source, with materials disbound locally due to the brittle nature of many of the items. The conversion of the materials has been outsourced to Northern Micrographics, Inc., a service vendor in LaCrosse, Wisconsin. The page images are captured at 600 dpi in TIFF image format and compressed using CCITT Group 4. Minimal document structuring occurs at the point of conversion, primarily linking image numbers to pagination and tagging self-referencing portions of the text (table of contents, indices, etc). Low-level indexing is being added to the serials by the partner institutions after conversion. In an effort to preserve these materials in a variety of formats, the resulting TIFF images are being printed onto acid free paper and bound.
Currently the publicly accessible and searchable University of Michigan implementation contains over 350,000 searchable pages of monographs (from over 1,400 volumes) with more added as scanning and OCR is completed. By the end of the summer, over 2,500 issues of eight serials consisting of approximately 200,000 pages will be available with basic article level indexing of title, author and page range. Search results including bibliographic information and frequency of "hits" are provided as an intermediate step. Requests for individual pages result in display of a page image converted "just in time" from the original TIFF image.
Our system for display and access to the Making of America has developed incrementally from a page image presentation system with searchable bibliographic information to our current full-text search capable system. As time and resources are available we expect that there will be added value and functionality.
This current implementation relies on three key components:
Automated Optical Character Recognition
Conversion of the page images to text through OCR allows us to provide full-text searching of the MOA materials. Although "raw" OCR is not perfect (and thereby will produce both false hits and drops), it provides significantly greater access than simple bibliographic databases.
In order to utilize the OCR fully to point to individual page images (in our search interface), we needed to be able to retain information about page location and document structure. In addition, the sheer number of images in the project required that we automate a process that could run largely unattended despite the challenges inherent in a collection with significant variations in condition, format, typeface, and printing quality of the original materials and the general quality of the images.
We used Xerox's ScanWorx. Although ScanWorx has some scripting and batch processing abilities, it did not provide the level of automation nor the ability to retain as much information about individual pages as we needed. Using Perl5, we developed a series of scripts that a) created ScanWorx scripts that retained individual page information based on the directory structure and naming conventions, b)managed Scanworx' processing of those scripts and, c) provided error information that has enabled us to identify problem files for rescanning or manual intervention. To date we have processed over 450,000 page images in less than three months' actual processing time.
Retaining a one to one relationship between the page image and the resulting text allows us to use both information about pagination and page type (Table of Contents, Indices, List of Illustrations, etc.) to generate an SGML encoded version of a volume that can be used to search and point to individual pages. In addition, this allows us to incrementally improve the OCR by enabling us to replace it page by page (see Future Plans for a description).
SGML Encoding Process
Additional automated processes were developed that:
Trade-Offs inherent in Automated OCR and Markup of Multiple Document Types, Formats, and Typefaces
The existing conversion process runs independently of the variations in the document collection. This is both its strength and its weakness. Because the process to distinguish variations in typeface and document layout runs without human intervention, thousands of pages can be processed with almost no staff intervention. However, this approach does not allow us to "train" ScanWorx to improve character recognition as we might if we were working with an individual document.
Formatting variations are also ignored. This allows us to use a single script to do initial mark-up on a document, but again this will slow the process if we ever have the opportunity to do full mark-up. Page headers and footers that might otherwise have been removed in the automated mark-up process cannot be removed because there is no clear way to capture consistent patterns for mark-up and text manipulation among such varied documents.
The Digital Library Production Services at the University of Michigan, through the Humanities Text Initiative (HTI), has considerable experience using SGML encoded texts and Open Text's SGML-aware search engine to search and dynamically display information on the Web. SGML encoded text provides structured information for fielded searches which can display and retain information about context. In this implementation, it allows us to identify the bibliographic information about the document, the number of "hits" on individual pages and information that utilizes the page image presentation system to point to specific page images.
At our current publicly available MOA search site, a user may search over 1,400 monographs. (See Current and Future Plans for a discussion of additional functionality available this fall). The user may choose to search either specific fields (author, title, etc.) or may search the full text of the MOA project. There is also a bibliographic browse available.
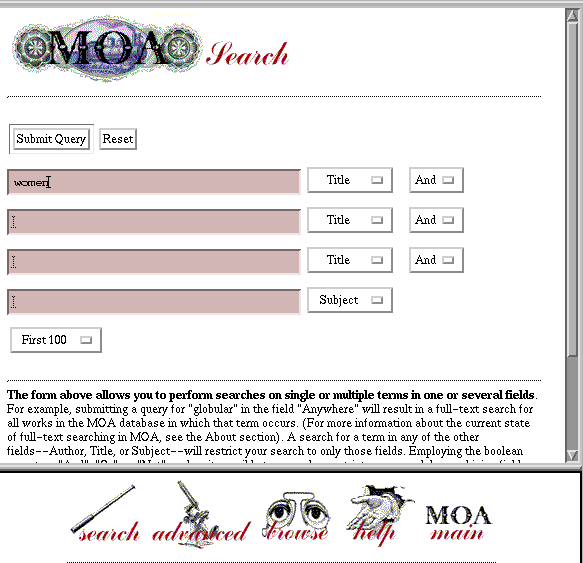
Figure 1. Sample Search Page with pull down menus for boolean options and fielded searches
In both search and browse functions, a CGI script, which extends templates developed at HTI, manages the information from the form and resolves the search into the search language of Open Text's search engine. Using two modules (developed at the University of Michigan) that manage the interaction and its results, the search is handed off to the search engine to search the indexed SGML. Results are passed back to the CGI script. The CGI script filters and displays the resulting data. The first results screen provides a list of documents matching the search query. If the search has been a full text search it also displays the number of hits in that document.

Figure 2. Results of a title search for the word "women"
After choosing an individual document, the second level screen displays specific bibliographic information. When the search is in the full text, it also provides information about the number of hits on each page.
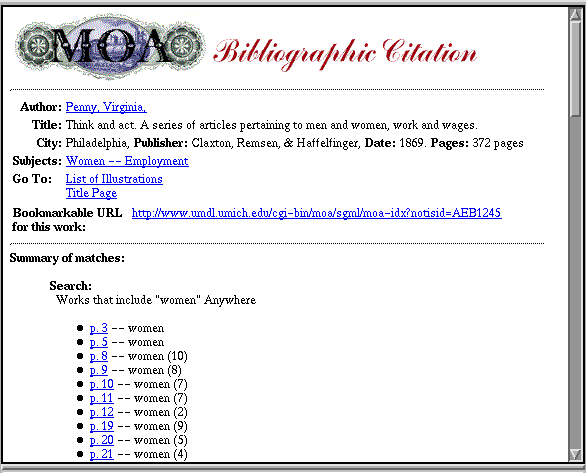
Figure 3. Results of a full text search for the word women in a book by V. Penney
Each page on the list is linked to its page image utilizing the image delivery system described below.
The Making of America uses "just in time" (see John Price-Wilkin's article - Just-in-time Conversion, Just-in-case Collections in the May issue of D-Lib Magazine for a rationale behind just in time delivery) image formatting. The TIFF images produced in the conversion process are copied to disk but otherwise left unprocessed. The files are created using CCITT Group 4 compression which provides a relatively compact format without compromising resolution or image quality.
However, TIFF is not a format that is widely understood by World Wide Web browsers. Because of this, page images that are presented to the user are converted to GIF format, which is universally understood. These GIF files are two to three times larger than the TIFF representation. In addition we offer users three levels of image resolution, in order to accommodate displays of varying size and dot pitch. Precomputing all of these GIF images would require several times the disk storage required for MOA.
We resolve this problem by generating the GIF images only as they are requested. This is facilitated by the use of tif2gif, a specialized utility which converts TIFF images to GIF images quickly, but with a limited set of scaling options. Tif2gif, written by Doug Orr, was originally developed at the University of Michigan and is used in a variety of our digital collections.
In addition, we take several caching actions based on assumptions about patterns in use. A GIF image which has been created is kept for a period of time on the assumption that it has a more than random likelihood of being visited again. Similarly, while a GIF image is being transmitted we begin converting the next page and placing it in the cache, on the assumption that it is likely to be visited next.
This approach is proven successful in practice. As of May 6, 1997, the collection contained over 1000 items totaling over 258,000 pages. Of these items, 794 had been visited at one time or another, but only 11,345 different pages and had been viewed (for a total of 14,648 GIF files, because of different viewing resolutions).
The interface is divided into two frames: the upper frame contains the page image while the lower frame contains navigation buttons; the use of frames guarantees that the navigation buttons are always visible.

Figure 4. Page Display from V. Penney's Book on Women
To minimize interaction between the viewer and the search engine, page navigation uses the page numbering conventions. The page images are stored in files with names of the form XXXXYYYY.tif, where XXXX is the ordinal number of the page in the sequence of bound pages (as shown in parentheses in the example) and YYYY is the printed page number that appears on the page (outside the parentheses). The first digit of YYYY is replaced by an "r" if the page number is a Roman numeral. Using this, the previous (or next) page can be identified by simply subtracting (or adding) one from the "XXXX" portion of the current page file name and locating the corresponding file. Similarly, the "goto page" function is implemented by converting the user's input to the form YYYY (or rYYY if the input was in Roman) and then locating the file named ????YYYY.tif.
The exception to this method of navigation is the pull down menu on the right in the second frame.
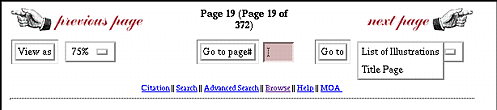
This menu allows the user to jump directly to pages of particular interest such as the title page or the table of contents. Since these page can be identified (and even their existence verified) only by reference to the SGML data, this menu is passed to the page viewer as a CGI variable. Similarly, the links on the bottom row are bound to URLs passed to the viewer.
The "View as" menu on the left in the middle row provides four alternatives for image size/resolution allowing the user to choose the optimal viewing size based on their screen resolution and other viewing factors.
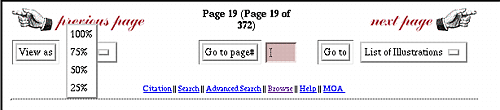
This search and display interface is an early attempt to combine the functionality of our system with navigational tools for the user. As time goes on, we will revisit the interface and provide improved functionality based on user feedback.
This summer staff are encoding bibliographic information (including author, title and page range) at the article level in the auto-generated SGML encoded text for approximately 2,500 serial issues. Using existing table of contents and indices as well as examination of the online images of the documents the project will allow an additional level of access for our online users. In addition to the display of results at the volume level in our monographic collection, we will be able to display results at the article level. This will allow more meaningful access to the serials collection for the researcher.
We will be reprocessing portions or all of our text using Prime OCR, a package developed by Prime Recognition that uses up to 5 OCR engines to dramatically improve OCR accuracy. Our attention to retaining pagination and document structure will allow us to selectively insert improved OCR as it is completed. As we insert the more accurate OCR over time, we expect that the greatly improved OCR will make the searching tools even more effective.
Although we probably can not expect to have the resources available to fully mark up and proof the 650,000 pages of the MOA project, individual texts have been or will be fully marked up in SGML and proofed for various reasons. As these volumes become available we will make them available to the user through the search facility - both as page images and full text SGML.
As we add content, indexing, proofing and functionality, the searching tools will be used to search across the various types of works allowing the user access through a single user interface to all available materials be they page images, fully marked up and proofed texts, serials or monographs.
At the University of Michigan, the Making of America project brings together a number of technologies to provide the greatest possible access to the collection. Just as we have moved from an page image display system to full text searching, we will extend its functionality in the future as time and resources and additional content become available. As more content becomes available, we hope to be able to provide similar access using our automated processes and extensible mechanisms.



hdl:cnri.dlib/july97-shaw