The Meta-Information Environment
of Digital Libraries
Terence R. Smith
Director, Alexandria Digital Library Project
University of California at Santa Barbara
Santa Barbara, CA 93106
[email protected]
D-Lib Magazine, July/August 1996
ISSN 1082-9873

The research in this paper was supported in part by NSF IRI94-11330.
Libraries are organized to facilitate access to
controlled collections of information.
Traditional libraries (TL's)
possess three organizational characteristics
that, together, provide a basis for such access.
These are
-
the organization of information into physical
information objects (IO's) such as books;
-
the physical organization of the collections
of IO's according to various attributes,
such as subject matter and author;
-
an organized information environment
that facilitates direct access to the IO's based on
such attributes as author, title, and subject matter,
as well as a limited degree of indirect
access to the information contained in the IO's.
This last characteristic of a TL typically
involves multiple sources of information to support access,
such as librarians, catalogs, and
the manner in which the collections are organized physically.
Since it involves information about information,
we term this characteristic the
meta-information environment of a library.
As currently conceived, digital libraries (DL's) are
libraries in which the controlled collections
are in digital form and access to the information
in the collections is based almost entirely
on digital technology.
From a user's point of view, digital technology
changes the three organizational characteristics of TL's.
First, the organization of information into
physical IO's
is replaceable with a more flexible organization into
logical IO's.
Second, the single physical organization of
a collection of IO's is
replaceable with multiple logical
organizations of IO's.
The third and most significant changes, however, occur
in the meta-information environment of a library.
In terms of advantages, having the IO's
in digital form permits the use of
digital technology in extracting
information from the IO's.
The extracted information may satisfy a user's
ultimate need for information
or it may be employed by ``digital librarians''
in characterizing the IO's in the collection.
In the latter case, this meta-information
may be employed in providing
access to the information encoded in the IO's.
In terms of disadvantages,
important interactions between librarians and users that
occur in the meta-information environments
of TL's may be lost with the near-automation
of information access in DL's.
The goal of this essay is to suggest
a framework for the design of the meta-information
environments for DL's that takes advantage
of digital technology and compensates
for the loss of direct user-librarian interactions.
In the remainder of this essay,
we briefly examine the use of the terms
``metadata'' and ``meta-information''.
We then employ a simple scenario of library use
in order to characterize the meta-information
environment of a TL.
We generalize this characterization
to the meta-information environment of
libraries in general.
The environment is modeled in terms of
a set of high-level services
which are, in turn, supported by sets of lower
level services, some of which are provided
by an extensible set of ``knowledge representation systems''.
Finally, we examine the implications of
this general characterization in terms of a
design for the meta-information environment
of a DL. In particular, we suggest a design
that is implementable within a distributed
object framework.
The term ``metadata'' has been applied
in a large variety of contexts.
For example, the topics of papers at a recent conference on metadata ranged from metadata in data
dictionaries
and its use in controlling the operations of
database management systems;
to metadata used for describing scientific datasets
and supporting
data sharing among scientists;
to metadata used in DL's to support user
access to information [6].
The concept of metadata, when applied
in the context of current libraries,
digital or traditional,
typically refers to information that
-
provides a (usually brief) characterization of the individual
IO's in the collections of a library;
-
is stored principally as the contents of library catalogs
in TL's;
-
is used principally in aiding users to access
IO's of interest.
As an example of its use in the context of TL's,
the term ``metadata'' is sometimes used
to describe the descriptive cataloging
that is specified
by the Anglo-American cataloging rules and the MARC
interchange format [16].
Such information constitutes
a major component of the cataloging information in
most TL's.
As an example of its use
in the context of DL's,
the term ``metadata'' has been used to describe
the information of the ``Dublin Core'' [2]
and the associated ``Warwick Framework'' [9]
which is intended to support access to
information on the World Wide Web.
The Core specifies the concrete syntax
for a small set of meta-information elements,
and the Framework specifies a container architecture
for aggregating
additional metadata objects for interchange.
More generally, however, if one surveys the many contexts
in which it has been applied,
it becomes apparent that the concept associated with the
term ``metadata'' is the principal
focus of an emerging area of the information sciences whose
goal is to discover appropriate methods
for the modeling of various classes of IO's.
Since a model of an IO is itself typically an IO,
and since the concept that is generally associated
with the term ``data'' is subsumed by
the concept associated with the term ``information object'',
it seems preferable to use the term ``meta-information''
and to define it as a model of an information object.
To motivate a general characterization of meta-information
in the context of DL's,
we briefly examine a ``typical''
usage scenario of a TL.
We employ this scenario as a basis for constructing
a general model of the meta-information environment of TL's
that may be generalized to encompass the case
of DL's.
For the sake of concreteness, let us assume
a user whose interest is in finding information
on condor re-introduction programs in California.
In order to access such information in a TL,
the user may engage in a variety of activities.
The four most important activities include
consulting a librarian;
consulting available catalog and reference materials;
browsing through the open collections of the library;
and processing the information that has been accessed.
Let us assume that the user
begins a search by consulting a librarian,
and indicates an initial interest
in discovering whether programs for
re-introducing condors from captive breeding populations
have been a success.
Several important processes may co-occur
during these interactions.
First, the librarian may build
a ``cognitive model'' of the user
that is employed in helping the user.
As an example, the librarian may note the user's
level of knowledge about the use of a library,
and discover that the user does not understand
the value of subject heading catalogs
in searching for references to information on
the decline of the condors.
Second, the librarian may build a cognitive
model of the user's information requirements,
or ``query'', typically in an iterative process
during which the user may change the initial query.
The librarian may discover, for example,
that the user would like to know the locations
of the release sites in order to visit them.
Third, and depending on the context of the query,
the librarian may also construct a model
of the user's information processing requirements.
In terms of our example, these might include
estimating the time to hike to the release sites.
In conjunction with these emerging models of
the user's knowledge base and information needs,
the librarian employs a cognitive model
of the library's information resources to determine
an appropriate set of actions that
will lead to the satisfaction
of the user's information needs.
Three classes of activities are
worthy of note.
First, the librarian may
direct the user to meta-information,
such as the subject catalog,
that points directly to IO's of interest.
Second, the librarian may guide the user
to ``general'' meta-information that can be
used in a less direct manner
in finding IO's of interest.
For example, the user may be directed to
a gazetteer in order to find the geographical
coordinates of the release sites,
whose names the librarian may happen to know.
These coordinates may then be used
in accessing the appropriate maps from the library's
map collection.
Third, the librarian may
suggest that the user browse in the ornithology
section of the library to look for books
that may be relevant to the topic of condors.
In so doing, the user may assess meta-information
in the form of titles and tables of contents.
Before leaving the library, the user may
employ the relevant maps to estimate
the time it would take to hike to the condor release areas.
The preceding example, which is by no means artificial,
emphasizes the fact that the meta-information
accessed by users of TL's in satisfying their information
needs is not restricted to the meta-information in the
author, title, and subject catalogs.
In particular, the scenario was devised
to emphasize that, during search,
a user may conceivably employ as meta-information
almost all the information sources in a library.
Such sources range from the librarian's general knowledge of the world
to information encoded in the IO's on the stacks.
Based on the scenario, we are justified in defining the
meta-information environment of a TL to be
-
-
the set of all information services
accessible to users of the library,
together with all available means for co-ordinating
the use of these services,
that enable users to access, evaluate, and use
any information that may be extracted
from the total information resources of the library.
An analysis of the preceding and similar usage scenarios
suggests that one may further characterize
the meta-information environment of a library
in terms of a simple model involving
sets of services for
-
coordinating user interactions with
the meta-information environment,
exemplified in the above scenario in terms of the user's interactions
with the librarian;
-
constructing models of the user, the user's query,
and the user's workspace requirements,
exemplified in our scenario by interactions with the librarian;
-
providing access to models of IO's,
exemplified in our scenario by use of the subject catalog
and browsing among the stacks;
-
making matches between the model of user queries
and models of IO's,
exemplified in our scenario
in part by actions of the librarian
and in part by actions of the user
in relation to such library resources as the subject catalog;
-
extracting information from retrieved IO's,
exemplified in our scenario by the computation
from the maps of the time it would take the user
to hike to the release sites.
-
creating models of IO's
which, although an important service of the meta-information
environment of libraries,
is not exemplified in the preceding scenario.
The scenario emphasizes the key role
played by librarians in providing services
in the meta-information environment of many TL's.
We note that the widespread use of the services of electronic
catalogs in many TL's does not diminish the significance
of this emphasis for present purposes.
In order to analyze further
the manner in which the preceding sets of services
provide support for user access to information,
it is useful to introduce the concept
of knowledge representation systems (KRS's).
We argue that an important component of the
functionality of the six sets of meta-information
services in TL's is provided by a diverse set of KRS's.
This conceptualization in terms of KRS's provides a useful
theoretical framework for the design and analysis of DL's.
A KRS may be defined as
a system for representing and reasoning about
the knowledge in some domain of discourse,
and is generally comprised of:
-
an underlying knowledge representation language (KRL),
whose expressions are intended to represent
knowledge about some domain of discourse;
-
a semantics that gives meaning to the expressions
of the KRL in terms of the domain of discourse;
-
a set of reasoning rules that may be employed
in inferring further useful expressions from a given set
of expressions;
-
a body of knowledge about the domain of discourse
expressed in terms of the KRL.
Concepts similar to the concept of a KRS
that have been used by other researchers in relation
to meta-information
include formal systems with interpretations [15]
and semi-formal systems [7]
In general, we may view the KRS's of a library
as providing a diverse set of services
that are of particular value
in the modeling of both IO's and user queries.
They are, for example, of particular significance in
supporting the modeling of IO's in terms of their content,
since, in principle,
the content of library materials may refer to
any representable aspect of our knowledge.
In order to gain further insight
into the nature and significance of KRS's,
we provide examples of their use
in supporting key sets of services
in the meta-information environments of TL's.
Thesauri are an
important class of KRS's that are employed in constructing
models of the subject matter
(or ``content'') of IO's for the catalog
systems of TL's.
The motivation for the use of thesauri
is the difficulties that
arise from using a KRS based on natural language (NL)
in this context.
These difficulties arise from
the syntactic and semantic
complexity and the high levels of ambiguity
that are typically associated with general
expressions in NL.
The KRL of a thesaurus, on the other hand,
is designed to possess a restricted syntax
and semantics that permits the representation
of restricted domains of discourse
in an unambiguous manner.
These restrictions result in the construction of many domain-specific
thesauri, which in essence represents
a ``divide-and-conquer'' approach
to building unambiguous representations of a complex world.
For the present purpose,
we may use a highly-simplified view of a thesaurus
that is
abstracted from the ANSI-NISO standard for thesauri [10].
-
The KRL of a thesaurus may be viewed as specifying
the terms of a simple language and a few relations
(or predicates) defined on the terms.
These predicates include the three ``broad term/narrow-term''
predicates, the ``related term'' predicate, and the
``synonymous term'' predicate.
-
In relation to the semantics associated
with its KRL, a term defined in a thesaurus
is intended to denote a single concept.
Typically, terms represent classes of entities,
although class instances are permitted.
Ambiguity arising from synonymous and homonymous
terms is effectively removed. The mapping from terms
to concepts is provided informally
by the cognitive processing of the reader of the terms.
-
With respect to reasoning procedures, the use of the
basic inference rules of logic (such as ``if A and A implies B are both true, then B is true"),
together with axioms involving the various predicates
(such as ``if A is a narrow term for B, and B is a narrow
term for C, then A is a narrow term for C''),
it is possible to carry out simple reasoning
that is interpretable in terms of the concepts
being represented in the KRL.
-
In terms of viewing a thesaurus as representing
a body of knowledge about some aspect of the world,
the terms and predicates of a thesaurus represent
a set of concepts and their relations that
model some aspect of the world.
Large numbers of thesauri are currently employed
in library contexts. The representation
of the content of IO's is typically achieved
by choosing a relatively small number of terms
from some domain-specific thesaurus.
Other classes of KRS that are also
employed in the modeling of IO's for the catalog
systems of TL's include subject headings
and descriptive cataloging systems.
The Library of Congress Subject Headings
now bear great apparent similarities to thesauri.
They are different in the sense that
single terms do not necessarily denote a single concept [3].
The descriptive cataloging that is used to
represent such contextual information
about IO's as title and author,
may also be interpreted in terms of KRS's.
In particular, the KRL that is employed
for most of the descriptive cataloging
in TL's is specified by the Anglo-American cataloging
rules (AACR2) and the MARC interchange format for
exchanging such information between libraries [15].
In TL's, there are a variety of KRS that may
aid a user in expressing a query that
is answerable in terms of the catalog.
A gazetteer is a good example of such a KRS
and is essentially a set of terms
that represent classes of features on the surface
of the Earth, such as rivers and towns,
and a large set of named instances of such features,
such ``Ohio River''.
The spatial coordinates of the feature instances
on the surface of the Earth are provided
as an essential component of a gazetteer.
One may therefore view a gazetteer as
a geographic thesaurus of limited extent,
in which large numbers of class instances
are given, and a function is defined on these
instances that assigns geographic
coordinates to the instances.
In TL's with electronic catalogs,
KRS's may be employed in representing user queries.
A simple example is the use of the terms of
the KRL of some thesaurus in order to represent
the content that a user wishes to find in acceptable IO's.
In the case of representing queries,
the user is frequently permitted to
define the content of IO's in terms
of boolean expressions of the terms
from acceptable thesauri.
The reasoning procedures of the thesaurus may be used
to expand the representation of the query
by replacing, for example, one synonym with another,
or a narrow term with a broad term.
Finally, we note that
in relation to their interactions
in the meta-information
environment of a TL, it is not unreasonable
to view a librarian as providing the services of
a large set of KRS's,
each focused on a specific domain of discourse.
These KRS's are employed in the various roles
played by the librarian in the meta-information
environment of a library.
The meta-information environments of current DL's
may be viewed as special cases of the preceding model.
In terms of the testbed for the
Alexandria Digital Library (ADL) [13] [4],
for example, the system provides services that:
support access to models of IO's in terms
of USMARC and Federal Geographic Data Committee (FGDC)
standards [5];
support the construction of models of user queries
in terms of regions of interest,
defined in part by the services of a background map
and in part by the services of a gazetteer,
as well as models of IO's based USMARC/FGDC standards:
support the computation of
exact matches between query and IO models;
and support a simple workspace
involving a local cache
in which users may save retrieved items.
It currently appears reasonable, therefore,
to use the general model of
the meta-information environment of a TL developed above
as a basis for designing
the meta-information environment of a DL.
Figure 1 illustrates a high-level design
for a meta-information environment for DL's.
The design is based on the model
developed above and is intended to be extensible.
It views the meta-information environment of a DL as a set
of high-level services that provide the essential
functionality of a library.
We view these high-level services, in turn,
as being supported by the services of an appropriate set of KRS's.
Such services may be implemented
within a distributed object framework
which may be based upon standards such as CORBA [11].
We note that the Figure is intended to be
neither exhaustive in showing all
possible meta-information services,
nor indicative of the flow of processing.
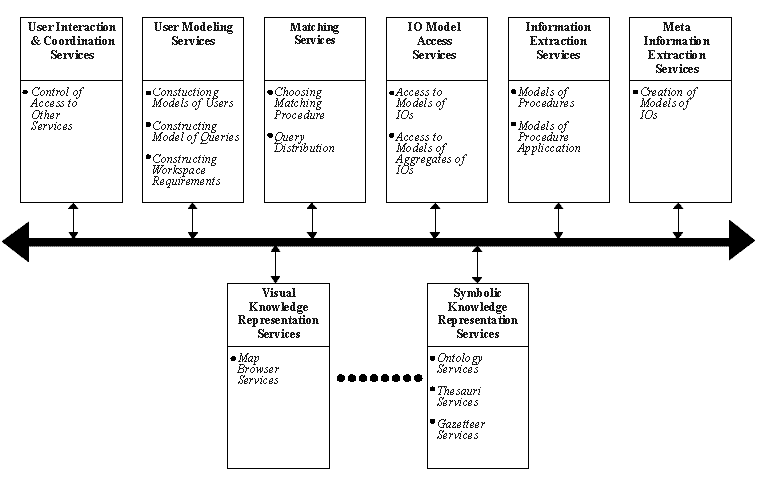
Figure 1: A High-Level Design for the Meta-information Environment of
a DL
We briefly summarize the main clusters of services.
-
A first set of services provides support for
the coordination of interactions between
the user and the meta-information environment.
-
A second set of services
is employed in modeling the user, the queries
presented by the user, and the workspace
requirements of the user.
The services are intended to represent
some of the functionality
of a librarian in relation to similar services in TL's.
In modeling a user, for example,
there may be a service for determining a user's area
of expertise and, on this basis, choosing a KRL
in which the user's query may be expressed.
-
A third set of services supports storage of, and access to,
models of the IO's
available in the collections of the library,
as well as other corresponding libraries.
In general, the models of IO's
may be interpreted in terms of various relations
between some symbolic representation of the IO
itself and representations of the characteristics of the IO.
In particular, the representations of the IO itself
may be provided in terms of access paths
and the representations of the characteristics of the IO
expressed in some KRL.
As in the catalog of a TL, therefore,
these services support direct access to IO's
on the basis of the characteristics of the IO's.
These services may be generalized to provide
models of aggregates of IO's
and even of whole libraries.
Such aggregate representations
are of value for realizing the efficiencies
associated with hierarchical search [2].
-
A fourth set of services supports
choosing and applying appropriate matching procedures
between models of user queries and models of IO's.
The goal of these services is to return appropriate IO's
to the user.
The matching services may involve, for example,
query translation
(since the models of IO's
may be represented in languages that are different
from the languages in which the user's query
is represented);
branching by search type,
hierarchical search, and iterative search.
Matching may employ different matching services
depending on the nature of the query
using, for example, standard information retrieval
procedures for text information or a browsing-type
search for images based on a relevance feedback algorithm.
The process may proceed iteratively and hierarchically,
by returning to the user information that allows
the user to have input into the search process.
The system may present, for example,
generalized information about the
content of various subcollections
in order to obtain information on the most
appropriate subcollections to search.
There may also be services that support the
distribution to other libraries
of queries that cannot be satisfied.
-
A fifth set of services
supports access to, and application of,
procedures that may be applied to retrieved IO's
in order to extract useful information.
Such services may, for example, include the modeling of
procedures and the modeling of
the results of applying procedures to IO's.
-
A sixth set of services provides support for librarians
in creating models of IO's.
These services may also support, for example, the automated creation
of aggregate representations of collections of IO's
and of whole libraries.
We note that this list of sets of services is not
intended to be exhaustive.
As noted above, we envisage
the high-level services of a DL
as being supported, in part, by
other sets of services that are provided by various KRS's.
The services of a given KRS
may support several sets of high-level services,
as in the case of the services of a thesaurus
supporting the modeling of both queries and IO's.
We now provide a few examples of classes
of KRS's that may be of value in supporting the high-level
services of the meta-information environment of a DL.
Services of particular importance
in the meta-information environment of a DL
are those supporting the construction of models
of both user queries and the IO's of the library.
Digital technology
makes it possible to construct relatively
complete and complex models of queries and IO's.
Important categories of characteristics of
IO's, for example, that may
be modeled by meta-information include
the access path of the IO;
the type of the IO (such as book, map, or video);
the logical structure of the IO
(including such structural components
as title page, preface, chapters, and index if it is a book);
the representation of the IO, including
its form (html file, or postscript file, or gif file);
and its language (English, or French, or Arabic);
the context of the IO
(including such information as author, publisher, lineage);
the content of the IO;
the terms and conditions of access to,
and use of, the IO;
evaluative information about of the IO,
particularly with respect
to its value in various applications;
the relations of the IO to other IO's.
An example of a characteristic of
an aggregate of IO's that may be modeled by
meta-information
is the number of items in the aggregate that
possess specified values for a given characteristic
of the individual IO's.
The services of an extensible set of KRS's
may be employed in constructing models of
queries and IO's in terms of such categories of
meta-information.
These KRS include digital versions of some
of the KRS mentioned in the context of TL's,
such as thesauri, subject headings, and gazetteers.
Digital technology, however, makes it
possible to support a wide variety of other KRS.
We briefly discuss a few of these possibilities.
-
As the power and efficiency of NL processing increases,
it is likely that partial modeling
of IO's in terms of NL as the KRL of choice
will become important.
It is reasonable to assume, for example,
that NL representations of the abstracts of
text documents will be used as partial models of IO's.
-
There is widespread current interest
in using ontologies
as a basis for modeling IO's [8].
An ontology may be generally defined as a linguistic
representation of a conceptualization
of some domain of knowledge.
Hence an ontology may be viewed as a KRS.
In general, ontologies specify fairly general languages,
and typically include specifications of
classes, relations, functions, and other objects [8].
They differ from the representation schemes
provided by thesauri, for example,
insofar as the semantic relations
defined over the terms are not necessarily strictly
hierarchical.
In the general case, the KRL's of ontologies are equivalent
to first order predicate calculus.
An advantage of such KRS's is that predicate
calculus is well-understood, particularly in terms of the
inferential mechanisms associated with this logic.
-
There is also a growing interest
in KRS whose KRL's are graphical in nature.
Conceptual Structures, for example,
represent a class of KRS's
for which the KRL's have an expressive power equivalent
to that of the predicate calculus,
and whose expressions have a graphical
form [14].
It is also possible to employ
KRS with iconic KRL's, in which
there is a natural relationship
between the form of the expressions and their meaning.
An example of such a KRL for modeling image IO's
would be reduced resolution images
(see, for example, [13].)
-
Finally, we note a variety of special KRS's
that have been developed for
the purpose of modeling specific classes of IO's.
One such class of KRS's are
various metadata content standards,
such as the FGDC metadata content standard,
which was designed
specifically to model digitized maps and images.
In particular, we note that the
FGDC specification permits the use of iconic terms.
Finally, we note a few of the issues
that relate to the provision of the services of KRS's.
Since a DL with heterogeneous holdings
will generally need to employ several KRS's
of different types, it
is important that designs for the meta-information
environment allow the easy addition of new KRS's
and removal of old KRS's. This is facilitated by distributed
object technology.
A related research issue of some interest
concerns whether it is best to use a large
number of relatively small KRS's,
or a small number of relatively large KRS's.
Another important research issue
concerns the construction of semantic mappings between
the KRL's of different KRS's.
It is possible to employ different
sets of KRS's for modeling user queries
and for modeling IO's.
There is therefore a need for translation
during the application of matching services.
One approach to
constructing such mappings involves the
use of human experts working in a top-down manner,
which is likely to be a time-consuming and
controversial process.
An approach that is promising in terms of automation
involves bottom-up techniques based on
empirical analyses of the use of language [12].
The meta-information environment of a library
is the aspect of library structure that is likely
to be most affected by DL technology.
It is important to design meta-information
environments for DL's that simultaneously
compensate for the loss of many
of the services of librarians
and take advantage of the ability
to apply digital processing to information objects
in the collection of DL's.
In particular, the essay suggests
the importance of a top-down component
that takes the perspective of the user
in the process of designing such environments.
The approach to design suggested in the essay
involves the implementation of a meta-information
environment in terms of six basic sets of services
that are, at least in part, supported by services from a
variety of knowledge representation systems.
Such an environment is probably best implemented
within a distributed object framework.
Terence R. Smith
Wed Jul 10 11:57:38 PDT 1996
Copyright © 1996 Terence R. Smith



hdl://cnri.dlib/july96-smith