
A major component of the Digital Library Project at the University of California, Berkeley is the development of a large testbed of data and services. This testbed provides public access to important datasets pertaining to the environment, including environmental documents and reports, image collections, maps, sensor data and other collections. At the same time, this testbed serves as the foundation for research efforts for our project. In our Computer Science Division, these efforts include the fields of computer vision, database management, document analysis, natural language processing, and storage management. In our new School of Information Management and Systems, the testbed is used for user assessment and evaluation and for information retrieval research. Finally, researchers in our College of Environmental Design use the testbed for Geographic Information Systems (GIS) experiments.
In this paper we describe our approach to the availability of testbed resources, the architecture of our testbed software and storage systems, the nature of the testbed data, how we process the data, and our plans for the testbed's future.
Table of Contents
In the service of this goal, almost all the data that we have accumulated is entirely unencumbered. Much of our data comes from agencies of the State of California, such as the Department of Water Resources and the Department of Fish and Game, which have an interest in placing information in the public's service. Some of our data is from private sources with similar civic-mindedness. For example, one of our image datasets, the Brousseau Collection of California Wildflowers, was collected privately with the intention that it be made publicly available for non-commercial purposes. We do have some propriety information, e.g., a collection of Corel stock photographs. However, these are available only internally, as they are used by our computer vision researchers, although they also serve to exercise the same testbed services.
To aid in ubiquitous access to our testbed, early on, we made the decision to rely on World Wide Web browsers for all our user interfaces, rather than develop custom applications for accessing data. In some cases, functionality had to be sacrificed in order to provide Web access. For example, the original Tcl-TK implementation of the Cypress image retrieval system allowed users to interact with the system, constructing customized "concept" queries that could be re-used later. Because this feature is difficult to implement via the HTTP protocol, it was not implemented in the WWW version of the image retrieval system. We decided to give up, for the time being, such functionality, in favor of the platform-independent user interface that Web browsers could provide.
The subsequent explosive growth of the World Wide Web has proved this decision fortuitous. Moreover, since several of our applications could not be implemented at the time under existing HTTP protocol, we set about exploring emerging technologies for bringing these applications to the Web. We began to develop Java applications such as the interactive TileBars display for full-text search, and the Multivalent Document Image Browser, both of which are today fairly extensive examples of online access using the client-side capabilities that Java enables.
In addition to making data and services available over the Web, we have
also endeavored to put all
source code online, once it has reached a reasonably consistent
state. Accessible code includes the "horizon finder", an image analysis
algorithm used for identifying photographs that contain a horizon, the
SQL/WWW interface used for our database query forms, and natural
language processing (NLP) code, such as TileBars. Most of our administrative data is also
online, such as weekly meeting notes, quarterly reports, email aliases,
and project calendar.
Software Systems Architecture
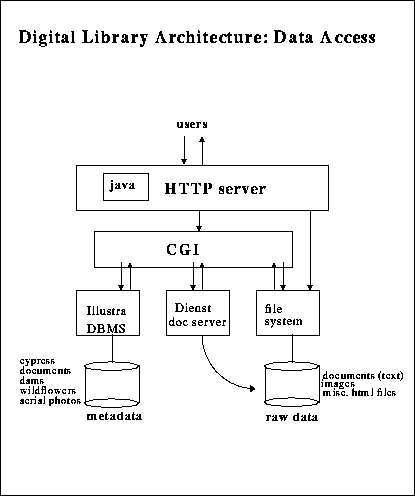
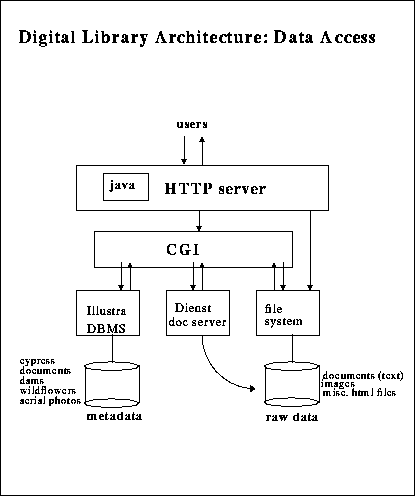
All access to the testbed is provided via the HTTP protocol for public
and project members alike. As shown in the diagram below, the Common
Gateway Interface (CGI) mechanism is used to provide interaction between
WWW clients and other software systems. Foremost among these systems is
our relational database server, which enables forms-based access to
nearly all data in the Berkeley Digital Library Project. Other methods
besides forms are available for accessing the data, such as clickable
maps and sorted lists. These and many others are available via the Access
Matrix, which provides a top-level access point to all the data in
the testbed.
Networked Testbed Services
HTTP enables other potentially generally available
services, which are currently used by the project to enhance the
functionality of our own software. Two examples of implemented
distributed networked services are "XDOC-to-Wordbox" translation and
dictionary lookup.
The first instance pertains to our use of Xerox's Optical Character Recognition (OCR) software. This commercial package produces ASCII text files, extracted from document images, along with so-called "XDOC" files. The latter encode information such as word position information, but in a rather inscrutable format. In order to implement some "behaviors" for Multivalent Documents, we need to turn the XDOC-formatted information into a more straightforward "wordbox" format, i.e., a simple description of where words appear in an image. To produce this more convenient format, we set up a translation service at the site of one of our project partners, Xerox PARC. We do so by dynamically passing the XDOC files to the PARC translation service, which returns the desired wordboxes. For efficiency, we cache these mappings on our server once they have been obtained.
Another behavior available in our Multivalent Document implementation allows users to select a word in the page image, and view the dictionary entry for that word. This service is provided by passing the word to a standard dictionary service, and appropriately filtering the result.
Other services are planned, such as a text categorizer, and image object
recognizer, and a service that generates document recognizers.
Data in the Testbed
By early July 1996, total data in the testbed exceeded 268 GB; this
represented over 39,000 images, more than 41,000 pages of documents, and
a myriad of other data currently available online. We hope to have
processed and put online over 3.5 TB of data by the time the project
comes to an end. The table below shows the breakdown of data as of July
3, 1996 along with projected sizes. Data statistics for documents,
images, and derived data are updated daily and more detailed information
is available using the Data Statistics
query form.
| Types | Datasets | Current Count | Current Size | Projected
Count / Size |
|---|---|---|---|---|
| Documents | articles,EIRs, water reports | 41,373 pages | 20.6 GB (.5 MB/page) | 300,000 pages / 150 GB |
| Images | DWR library wildflowers Corel stock | 14838 images 2905 images 22,000 images 39,743 total | 238 GB (6 MB/image) | 560,000 images / 3.4 TB |
| Aerial Photos | Suisun Marsh, Sac-SJ Delta | 500 images | 3.4 GB (6 MB/image) | 10,000 images / 68 GB |
| Sensor Data | Delta fish flow | 30 days | .02 MB | 3 years / 1 MB |
| Derived Data & Other Data | dams, fishes, water districts, html pages | various | 50 MB | 1 GB |
| Orthophotos | SF Bay Area | 102 images | 5 GB (50 MB/image) | 102 images / 5 GB |
| TOTALS | 268 GB | 3.5 TB |
The two largest datasets in our collection are documents and images, which are added to on a daily basis. The source for most of this data is the Department of Water Resources (DWR).
The DWR documents are mostly reports and bulletins about water conditions around the state. However, we also have received many other types of documents such as Environmental Impact Reports and educational pamphlets. Recently we have begun receiving detailed environmental plans for all the counties in the state. These are complex documents that include fold-out maps, charts, and the like. We collect documents that the project's user needs evaluation team has identified as useful to a given user community. This evaluation continues after the data becomes available online. Thus the document collection not only provides public access to important state government environmental reports but it also serves as a testbed for the Berkeley Digital Library Project's research efforts. In addition to its role in user evaluation, the document collection is also used for document-oriented research, which includes work in natural language research, document image decoding, and new document models.
In terms of storage requirements, the image collection is the largest dataset in the Digital Library testbed. Its size will eventually exceed 3.4TB and it is composed of three sets of pictures. The largest of these is represented by images from DWR. The DWR Film Library manages over 500,000 slides and prints of California natural resources. A few years ago, DWR began a project to scan these images to Photo-CD; the 14,800 images that have been scanned so far are available and searchable online via the Digital Library project.
The two other image datasets are the Corel collection of stock photographs, and the California wildflowers pictures of the Brousseau Collection. These images form the testbed for the project's computer vision research group, which is attempting to exploit the shape, color, and texture information available in these images, together with geometric and kinematic constraints, to identify the presence of objects such as horizons, trees, animals, and people. As is the case for documents, the Berkeley project's user evaluation researchers help to identify features in the image retrieval system that are desirable for users as well as to evaluate its effectiveness.
We are also acquiring a large collection of geographically located data. Examples include aerial photographs from DWR, sensor data such as the Delta Fish Flow count from the Department of Fish and Game, and digital orthophotos from the United States Geographical Survey (USGS), i.e., aerial photos of the San Francisco Bay Area that have been rectified and geopositioned. A large part of our current research effort is focused on ways to bring geographical data like this to the Web using the Multivalent Document model.
One of the more interesting datasets in the project is the derived data. This is data that came to us in one form, but then was transformed into a different type of data. An example is the California Dams database. Originally a 141-page paper document from DWR listing all the dams in California, it underwent document-specific decoding to extract its underlying structure, which, on paper, appears to be a database dump. In this process, a document recognizer is created, which is capable of understanding the structure of this class of document. The recognizer produces a suitably marked up version of the text extracted from the document. Among other things, the marked up text was used to automatically generate a dams database table. This database can then be queried through the usual means, e.g., via an html form. In addition, locational information for each dam was taken from the decoded document and used to generate points on a clickable map of California. Other datasets derived in a similar manner include Water Districts and Fishes of the Delta.
Documents are received in paper form by the boxful from agencies like DWR. We manually extract bibliographical metadata such as title, author, and publication date; scan the documents to obtain images of each page; and run OCR on the images to produce plain ASCII text along with word location information (i.e., XDOC files). We load the metadata into a relational database and then install page images, text and XDOC files into the filesystem. More details about document processing are available.
Aerial photographs are most often received in paper form, which we scan using a color scanner. We obtain from markings on the photographs as much metadata as possible, such as flightline numbers and photo dates; this metadata is loaded into a database. We use GIS software to position the aerial photos in a coordinate system, which is also stored in the database. The Bay Area orthophotos come in digitized form which we load directly onto our storage device and then convert to a more portable format.
All other images, and some aerial photos, are received on Photo-CD,
about 100 images to the CD, each image containing 5 or 6 resolutions.
We copy these to our tertiary storage devices, and then return the CDs
to the data providers. We convert the lowest resolutions to a more
portable format and store then on local disks for fast browsing. Our
primary image datasets - the DWR and wildflower collections - arrive
with metadata that has been collected by the data provider. (See DWR Schema for
an example of the metadata for the DWR collection.) These textual data
are converted to a format used by our relational database and loaded.
The images are then processed to extract content information, such as
color and texture; this information is also stored in the database.
Storage Architecture
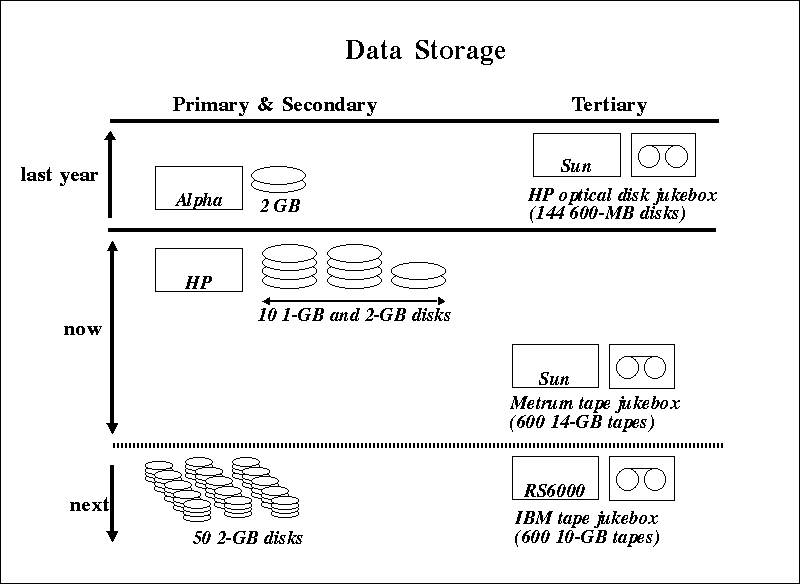
As the testbed has grown in size, storage requirements have changed
dramatically. The diagram below shows the evolution of the Berkeley
Digital Library storage architecture. Recently we have received a
6-18TB capacity tape storage jukebox from IBM, which we are planning to
use to store all our data, locking browsable images and other frequently
accessed data into a 100GB disk cache. We are currently in the process
of migrating data from the Metrum tape jukebox to this new storage
device.
After the End of the Project
Because of the size of our testbed, and because it contains important
data, we must pay careful attention to what will become of this data at
the end of the research project two years hence. Our primary goal is to
encourage and to help establish distributed archives and servers that
will continue to provide access to the data. Our efforts in this regard
include the following:



hdl://cnri.dlib/july96-ogle