![]()
D-Lib Magazine
July/August 2000
Volume 6 Number 7/8
ISSN 1082-9873
Robust Hyperlinks and Locations
Thomas A. Phelps and Robert Wilensky
Division of Computer Science
University of California, Berkeley
[email protected] , [email protected]
http://www.cs.berkeley.edu/~phelps/Robust/
Abstract
We suggest that building "permissive, but robust" digital library systems and services is an attractive alternative to the library and computer science tradition of building "strict, but fragile" systems. Strict, but fragile, systems are efforts to engineer complete systems that ensure desired properties, but which often prove impractical in distributed environments without a central authority to coordinate change. In the permissive, but robust, approach, we permit individual components to change in ways that might, in fact, cause a desired property to fail to persist. However, we engineer components to be robust, so that it is likely that desired properties persist even under a great deal of uncoordinated change.
We have applied the permissive, but robust, approach to two related problems of reference in distributed information systems. The first application yields robust hyperlinks, and the second, robust locations. Robust hyperlinks address the familiar issue of providing persistent reference to networked resources, such as Web pages, given changing, uncooperating services. Robust locations concern a somewhat less familiar, but, we suspect, soon-to-be just as big a problem, namely, references to changing sub-document resources. Robust locations, we suggest, provide essential grounding for next-generation web functionality, such as annotations that survive document editing.
In both cases, robustness is achieved by providing multiple, independent descriptions across boundaries where change is likely to be uncoordinated. If the different descriptions are property selected, then most uncoordinated changes will be unlikely to cause all the descriptions to fail. Thus, while there is no guarantee that references will remain coherent, a single failure is unlikely to be catastrophic. Instead, the failure of one, even a primary, method will generally allow graceful recovery via other methods.
Introduction
An important tension in the ongoing evolution of information systems is that between disciplined, carefully structured information resources, and the haphazard, uncoordinated nature of loosely federated, distributed systems. That information resources should be carefully structured has a long tradition in computer science, and an even longer tradition in library science. Both traditions largely presume that they are providing tools and services that a single authority will use to administer its own information resources for its own use. Thus, database management systems allow, and require, organizations to schematize their data so as to support their particular anticipated patterns of access; and both database management systems and traditional computer operating systems go to great lengths to provide coherent data management services. Similarly, the librarians traditional task focuses on maintaining a particular collection, of managing it, adding to it, organizing it, preserving it, and so forth. In both cases, the maintenance of a relatively isolated collection of data is central.
The centrality of an isolated collection has a number of consequences. System support is generally tailored to local needs and conditions of the collection, which are often intricate and one-of-a-kind. Extending and modifying such a system may be a major undertaking. Moreover, interoperation needs to be effected by external interfaces that adhere to carefully crafted standards, be they SQL, Z39.50 or MARC records. These must be all things to all people, and hence level many distinctions that are significant at the level of particular collections.
Abiding by the traditions of computer and library science has enabled individual organizations to develop systems that operate well, but for which extension, modification and interoperation is difficult. No doubt the success of the World Wide Web is due in part to willfully ignoring these traditions. The Web provides an infrastructure in which interoperation -- albeit at a superficial level -- as well as extension and modification, are easy, but in which it is generally not possible to guarantee any of the overall system properties that both computer scientists and librarians have traditionally worked so hard to insure.
Researchers developing strategies to support digital library services have a number of alternatives available. One is to continue in the traditions of library and computer science, and try to engineer complete systems that ensure important properties. Let us call this strategy the "strict, but fragile" approach. An alternative is to presume the chaotic properties of the Web that have facilitated its explosive growth, and try to incrementally impose on top of these the useful properties we have come to depend upon in individual systems or libraries, without requiring disciplines that have proven impractical on a large scale. Let us call this strategy the "permissive, but robust" approach. In the permissive, but robust, approach, we permit individual components to change in ways that might in fact cause a desired property to fail to persist. However, we engineer components to be robust, so that it is likely that desired properties persist even under a great deal of uncoordinated change.
Consider, for example, the issue of referential integrity. No self-respecting operating system or database management system (or pre-Web hypertext system, for that matter) would allow a reference to persist after the termination of the referenced entity. But the Web imposes no such constraint. Instead, pointers and the resources to which they refer can come and go completely independently. For the developers of distributed digital library collections, the "strict, but fragile" approach would seek to overcome this deficiency by developing some infrastructure components that, in essence, forbid incoherence to occur. Persistent Uniform Resource Locator [OCLC] might be classified as an instance of such an approach, as might various approaches that involve monitoring and notification to insure referential integrity (e.g., [Ingham et al., 1996]), [Mind-it], [Macskassy and Shklar, 1997], [Francis et al., 1995]). While these approaches may be theoretically attractive, experience has shown that the global coordination they require is too much of a burden in practice.
We suggest that the "permissive, but robust" approach allows for an attractive alternative. Rather than attempting to enforce strict coherence, we can enhance references to make them robust. The basic idea behind robustness is to provide multiple, independent descriptions across boundaries where change is likely to be uncoordinated. If the different descriptions are property selected, then most uncoordinated changes will be unlikely to cause all the descriptions to fail. Thus, while there is no guarantee that references will remain coherent, a single failure is unlikely to be catastrophic. Instead, the failure of one, even a primary, method will generally allow graceful recovery via other methods.
One attractive aspect of "robustness by multiple description" is the following: An existing system, designed without robustness, generally relies on a single method which all components support. Modifying such a component is therefore very difficult. However, it may be possible to add additional components to such a system in a way that is largely non-interfering with its primary function. Therefore, it may be possible to retrofit existing systems to introduce robustness with little or no modification.
Here we discuss two types of robust reference, robust hyperlinks, and robust locations. The first addresses the more familiar issue of references to networked resources, such as Web pages. The latter concerns a somewhat less familiar, but, we suspect, soon-to-be just as big a problem, namely, references to sub-document resources. Robust locations, we suggest, provide essential grounding for next-generation web functionality, such as annotations that survive document editing.
Robust Hyperlinks
To design robust hyperlinks, one needs a number of alternative, independent descriptions of resources from which to create links. Since URLs are, of course, well entrenched in the Web infrastructure, one must find some additional, independent description of Web resources that is largely independent of URLs, which can be readily computable from resources, and which can be easily retrofitted to the existing Web infrastructure.
The basic idea for an alternative description is extremely simple. It is to include in the hyperlink, along with the URL, a piece of the document content, e.g., a small number of well chosen terms. We call this content a lexical signature, as it is meant to identify the given page by its content. A robust-hyperlink-aware agent will generally perform an initial attempt at traditional address-based dereferencing, that is, looking up a URL, ignoring the signature. However, if traditional dereferencing fails, the client enters into a second phase of content-based dereferencing, in which it supplies the signature terms to standard search engines to locate documents whose signature most closely matches that in the robust hyperlink. The user is then presented with the matching documents from which to complete the reference.
Computing Lexical Signatures
The first issue we are faced with is how to create signatures that have appropriate properties. Basically, we want small signatures to effectively select the documents they were computed from, but also, to be robust in the presence of document modification. More precisely, we can list the following desirable properties of signatures:
- Short signatures should effectively pick out few documents.
- Subsequent changes to a document should have minimal impact on signature effectiveness.
- The addition of new documents should have minimal impact on previous signature effectiveness.
- Signature effectiveness should be largely search-engine-independent.
Note that at times, these requirements are at odds, presenting us with a "uniqueness-robustness trade-off", i.e., to effectively pick out documents, simply selecting the rarest terms would be appropriate ([Bharat and Broder 1998], [Martin and Holte 1998]). However, the resulting signatures, while short and effective, may not be robust with respect to minor document changes. For example, a single term that occurs just once in the entire web is by itself a very short and highly effective signature for the lone document that contains it. However, this term may be a typographic error, and hence will soon be changed, rendering it completely ineffective.
We do not have a model of how web pages change, so we have improvised heuristics to capture our beliefs about these. Specifically, we propose the following:
Use as a figure of merit for terms in a document the inverse document frequency of the term (i.e., IDF) times the maximum of the term frequency in the document (TF) and some limit (currently 5).
Select the few best such terms subject to other robustness heuristics.
Note that TF is considered only as a robustness heuristic, in that repeated words are assumed to be less likely to all be deleted, but only up to a point. In addition, other robustness heuristics may be useful to select among high ranking terms. For example, one such heuristic may insure that all the terms should not occur very close by, say, in the same sentence.
We also have no model of what new documents will be added, and hence assume that the current distribution of terms will persist. Therefore, choosing rare terms also minimizes the chance that another document will be added with this term.
Empirical Results
Preliminary empirical results suggest that lexical signatures of about five terms are sufficient to determine a web resource virtually uniquely, out of the more than one billion pages on the web [Inktomi 2000]. That is, in most cases, a query to a search engine requesting documents which contain all of the terms in the signature will cause a unique document to be returned, namely, the desired document. In those few cases in which more than one document is returned, the desired document is among the highest ranked. In those cases in which a particular search engine returns no matching documents, this is generally because the document has not yet been indexed, or has been substantially edited since it was last indexed.
Indeed, fewer than five terms will probably suffice. Nevertheless, we advocate at least these many terms because the redundancy that is provided is useful with respect to document change and because the additional terms may be needed to distinguish documents as the web continues to grow.
Encoding Signatures in URLs
Given that lexical signatures are a good way to augment URLs, we are left with the issue of how to associate these with hyperlinks. Our primary requirement is that the solution fit into the existing Web infrastructure moderately well. Our proposal is to append a signature to a URL as if it were a query term. That is, if the URL is http://www.something.com/a/b/c, and the designated resource has the signature w1,...,w5, then the robust URL is
http://www.something.com/a/b/c?lexical-signature="w1+w2+w3+w4+w5"
(If the URL already includes a query, the signature expression is appended as another name-value pair conjoined with an "&".)
This proposal seems largely non-interactive with current web infrastructure. Most widely used HTTP servers seem to ignore query terms for non-script URLs (and most services seem to ignore what appear to be gratuitous query parameters). The "signatures as queries" scheme is not foolproof, but the drawbacks seem minimal and well within the spirit of our "permissive, but robust" approach.
Example
The URL for the NSF DLI2 initiative is http://www.dli2.nsf.gov/. Enhancing this URL to become a robust URL, using 5 word signatures, produces the following:
http://www.dli2.nsf.gov/?lexical-signature=nsdl+multiagency+imls+testbeds+extramural
Feeding the signature into the Google search engine <http://www.google.com/search?num=10&q=nsdl+multiagency+imls+testbeds+extramural>, for example, produces the original DLI2 page as the unique result.
Recommended System Support for Robust Hyperlinks
To take advantage of robust hyperlinks conveniently, relieving users of the mechanics of content-based recovery, some piece of software needs to exploit them. Ideally, browsers will support them directly. Browser support would require no changes in servers or other infrastructure, so users would benefit as soon as they update their browser. However, robust hyperlinks can be made effective without any change to existing web infrastructure. For example, we provide a page of JavaScript that one may bookmark, and manually select after (most) broken link errors, which will perform the signature resolution. We also provide software users can run to make web pages and bookmark files robust.
Alternative Approaches
In principle, one could find other, independent descriptions with which to supplement URLs. For example, Uniform Resource Names (URNs) [Sollins and Masinter, 1994], handles [Kahn and Wilensky, 1995], and Common Names [CNRP] are alternative naming schemes at various stages of deployment. Should supporting infrastructure for these schemes come into widespread use, each could make a useful alternative, or addition, to the lexical signature approach advocated here.
A more detailed description of robust hyperlinks is available in [Phelps and Wilensky 2000-1].
Robust Locations
We turn now to the issue of referencing "sub-resources", that is, fragments or locations within a target resource. Intuitively, a location is a place in a document that has some semantic distinction (as opposed to, say, a geometric position on a page or a character or word offset). Generally, one can identify locations even after editing, by scanning for the area of the document that most closely resembles that of the old location. Perhaps because the notion of place can be made concrete in many different ways, and is media-dependent, it currently exists in only a rather limited form in practice. For example, in the World Wide Web, a URL can refer to a named anchor within an HTML document, while the XML Pointer Language [XPointer] provides a general scheme for addressing internal XML document structures.
In contrast to inter-document links, the issue of the coherence of intra-document locations has received very little attention. For example, most HTML browsers silently fail if they can locate the document but not the fragment within the document given by the URL. However, we suggest that intra-document locations will become increasingly important, and that, as they do, the issue of their coherence will become crucial: As the web develops as an increasingly sophisticated hypertext platform, many types of advanced functionality will emerge that gainfully exploit intra-document locations. For example, "stand-off" (or "out-of-line" or "out-of-band") annotation, in which annotations are stored separately from the annotated document, has numerous advantages over embedded annotation. Also, multimedia formats tend to come into existence independently from web authoring, and therefore, any structuring must be imposed upon them externally, hence mandating sub-resource referencing.
At the same time as the need for intra-document location increases, the openness of the web will allow resources and locations to continue to change independently and chaotically. It is probably the case that resources will be modified with some frequency, even as the resource persists, hence creating the possibility that fragile sub-resource locations will fail to persist even if the persistence of resources is achieved.
Describing Robust Locations
We now describe a strategy, called robust locations, which addresses this problem. The core of the strategy is to (i) provide automatically generated location descriptors, which comprise multiple descriptions of a location, each of which captures different aspects of the document, and (ii) use heuristics when a descriptor does not resolve directly to a location to hypothesize the intended location, along with a measure of the degree of confidence in the hypothesized location.
Robust location descriptors describe locations independently, using a number of different data records. Each record type provides different quality-of-reattachment and robustness characteristics. Taken together, they provide considerable resilience.
We propose a core set of location descriptor records that are easy to generate, simple to understand and implement, and appear to work well in practice. Implementors are free to supplement these records with additional records in their applications.
- A Unique Identifier (UID) is a name unique within the document, as per ID attributes in SGML/XML. These survive the most violent document changes, except its own deletion. However, such identifiers will be available only through the foresight of the document author, and even then, only for locations corresponding to document elements, but not sub-element or non-element content.
A Tree Walk describes the path from the root of the document, through internal structural nodes, to a point within media content at a leaf.
In practice, tree walks are the central component of robust locations. Since tree walks incrementally refine the structural position in the document as the walk proceeds from root to leaf, they are robust to deletions of content that defeat unique ID and context locations. Thus, tree walks are especially helpful for documents such as those that transclude dynamic content, as with stock quotes, where the content itself changes while the structural position remains constant.
We describe tree walks with a sequence of node child numbers and associated node tags (generic identifiers), terminating with an offset into a media element. This is both a simpler, less expressive, and more redundant, representation than is allowed by XPointer. For example, consider the following tree walk into a particular HTML document:
21/Professor/8 0/<TEXT> 0/ADDRESS 1/H3 0/BODY 0/HTML
Reading right to left, the example can be decoded as starting at the root, taking its 0th child element, which should be labelled "HTML", then taking that node's first child (numbered zero) to a node named "BODY", taking its second child, a node named "H3", taking its first child, "ADDRESS", then taking its first element, which should be a media leaf element labelled with its type, here "<TEXT>". The final portion of the descriptor, here 21/Professor/8, is always medium-specific. We propose that TEXT can profitably be divided into words, as this provides robustness to any editing within other words. Thus, here the 21/Professor portion follows the pattern of the tree walk in implicitly treating its words as child nodes, such that the 22nd word should be "Professor". The 8 is then an offset eight chracters into this word, resolving to the point between the "o" and "r".
Context is a small amount of previous and following information from the document tree. We propose a context record containing a sequence of document content prior to the location, and a sequence of document content following the location. For example, for the location described by the tree walk above, let us suppose the word "Professor" is found in a sentence fragment that reads "congratulations on her promotion to Professor in the Computer Science Division". The context descriptor could be:
her+promotion+to+Professo r+in+the+Computer+Science
with the previous and following context separated by a space, and metacharacters, including space, encoded with the same method as URL metacharacters. The amount of context to be saved can be arbitrarily large. (We use up 25 characters, which may be truncated at text element boundaries.)
Context records work well for short documents, which can be searched quickly. Moreover, in event of a failure, the saved context can be reported to the user as a facsimile of the former location. Without supporting location methods, however, simple context can easily be confused by the same pattern of words elsewhere in the document, a danger that grows larger the longer the document.
The Robust Location Reattachment Algorithm
Algorithms that exploit the multiple location descriptors can detect and correctly reattach many otherwise unresolvable references in the presence of a large class of changes. We define a "basic" reattachment algorithm, which reflects how we designed location descriptions to be used, and which we believe exploits them well. We do not claim this to be an optimal reattachment algorithm -- many sensible variations of this algorithm, not to mention altogether different algorithms, are certainly possible, and determining the best algorithm requires empirical data we have yet to collect. Note, though, that the robust reference scheme does not require that user agents all implement the same reattachment algorithm.
Our algorithm first uses the unique identifier, then the tree walk descriptor, and then the context descriptor, continuing only if the previously tried methods are ineffective. If the location has a UID, and the same UID is located in the document, the location is presumed to be resolved. However, we presume that UIDs will generally only be available at key points in a document. In practice, the tree walk submethod is the workhorse reattachment method, due to the usual absence of a UID and the fact that its strong robustness properties are quite successful in resolving locations.
The tree walk exhibits strong natural robustness, in that in resolving the walk from root to leaf, changes of any magnitude within following sibling subtrees are safely contained. The walk is also invariant with non-structural changes to previous sibling trees, although it is affected by structural changes to them. For example, introducing a new previous sibling, or removing one, can invalidate the walk. Tree walks can made much more robust with heuristics that repair broken paths. We check that a walk is valid by checking each node name, which is redundantly recorded in a robust location; for media indices, the general algorithm only checks that the indexed element can be found, after which control is passed to a medium-specific model that may have its own robustness methods.
If matching a tree walk of a robust location against the actual runtime tree fails at the exact saved offset, matching is tried on, first, the following sibling node, then the previous sibling, then the second following, the second previous and so on until the node names match. If the match fails previously, the same strategy is employed, with the proviso that the rest of the walk succeeds (possibly with additional approximations to exact matches). If no match can be found, we hypothesize that a new level of hierarchy was introduced, and skip a level of the tree. If still no match is found, we hypothesize that a level of hierarchy was removed, and skip the current location node/offset descriptor pair. If none of these attempts yields a match, the match attempt fails.
Each level of departure from the original description adds a weighted value to an overall "unreliability" factor for the match thus far. Moving to the following or previous sibling adds a small amount of uncertainty, with increasingly larger amounts as the siblings tested grow farther away, and skipping or assuming a level of hierarchy adds a larger amount. If the factor exceeds a client-defined bound, the tree walk match attempt fails.
This algorithm makes saved tree paths robust against any number and combination of sibling insertions, deletions and reorderings at any or numerous levels of the document tree. The search pattern prefers siblings closest to the saved location, rather than, say, searching from the parent's first child to its last, reasoning that the closest match is most likely the best match. This search tactic has the desirable algorithmic property that the first match found is also the closest.
If the structural document tree has been changed too much for the tree walk's tactics to succeed, re-registration is attempted using the context data record. As with the tree walk, the closest match to the original position is the preferred. A search is done forward and backward, with the nearer match chosen. If neither direction matches, more and more of the context is shed until a match is found, or until the length of the string used for the search drops below a threshold.
As with tree walk matching, an overall unreliability factor for the match is maintained. As the search examines ever larger subtrees, the unreliability is increased. If some but not all of the context is matched, unreliability is increased.
Rolling Out Robust Locations
Since intra-document locations are themselves not commonplace, there is less of a need to find a way to fit them into existing infrastructure. (It would not be hard, however, to find a place for a robust location within the current syntax for fragments, though, should this be deemed useful.) Instead, we have implemented robust locations within the Multivalent Document system [Phelps 1998], [Wilensky and Phelps 1998]. There it is used for a variety of applications that realize a form of stand-off distributed annotation. Our implementation lacks application to a variety of media types and testing by a large user community, but otherwise has proven robust beyond expectation.
Properly testing robust locations requires real use by a user community. Our Multivalent client is still a prototype, so such studies have not yet been undertaken. However, we tested the algorithms described here by creating a number of robust locations for some documents we manage, and then mutating the documents in various ways. The algorithm performed extremely well. Indeed, to generate an example of unattachable links (shown below), we tried to make the algorithm fail by repeated modifications of the base document, but gave up in frustration, as a different robustness submethod would continually correctly identify the proper location. Instead, we eventually broke the location descriptor itself manually.
Perhaps more compelling is our use of this robust location implementation on a number of documents that were not under our control. In one case, we posted some annotations on the DARPA home page, which we left unchanged for over one year. During this time, each annotation reattached correctly through many alterations of the page, including one in which the page was apparently imported into an HTML authoring tool, which placed the entire document content into cells of a newly introduced table, and another, in which a major website redesign caused the resulting location to be resolved in a newly created frame.
We have also implemented one strategy for handling failed reattachments. It presents to the user a floating note listing unattachable spans, which have been reconstituted within the note from the saved context, to which the locations, here paired in a span annotation, are placed. An associated user interface we have implemented allows the user to manually reposition an un-attachable span.
Figure 1 shows our MVD client displaying a number of stand-off annotation on an HTML document: a "Replacement" copyedit annotation on the main document text, a PostIt-style note, and "Comment" copyedit annotation on the text in the note. Each of the annotations is separate from the HTML page, the two copyedit annotations referring to their targets via robust locations. (Actually, each uses two robust locations, one for each of the starting and ending locations of the span over which the annotation extends.)

Figure 1. Some stand-off annotations on an HTML document.
Figure 2 shows one strategy for handling failed reattachments. Here we have damaged one robust location by hand so that the heuristics described above fail to recover an acceptable target location. The client then presents to the user a floating note listing unattachable spans, which have been reconstituted within the note from the saved context, to which the locations, here paired in a span annotation, are placed.
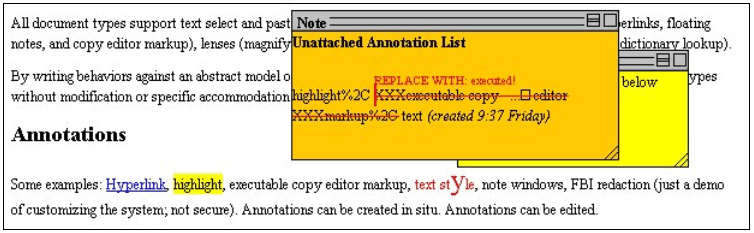
Figure 2. In the Multivalent system, locations that cannot be reattached manually, here paired in an span annotation, are represented to the user, reconstituted with the "context" text and carrying the same annotation.
Figure 3 shows an associated user interface that allows the user to manually reposition an un-attachable span. The user first makes a selection, whose end points will serve as the new start and end points of the annotation, moves the cursor into the unattachable span in the note, clicks the mouse, and finally, chooses Morph to Current Selection to move the reconstituted span to its new location.
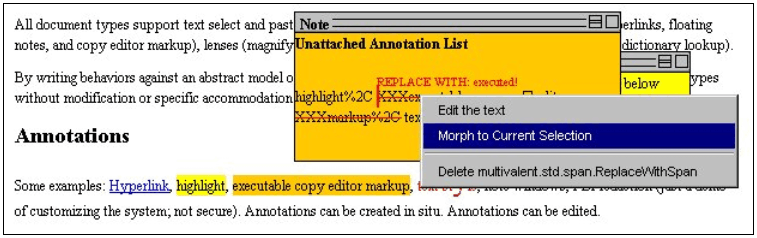
Figure 3. The user can reassociate a span annotation by selecting the correct location and making a choice from a pop-up context menu in the reconstituted span.
A more detailed description of robust locations is available, [Phelps and Wilensky 2000-2].
Conclusion
Robust hyperlinks and robust locations are examples of the "permissive, but robust" approach to distributed systems. Instead of strictly enforcing desirable policies, which is problematic given independently administered distributed resources, the approach provides for the possibility of putting together systems that mostly provide the desired properties, and whose performance degrades gracefully with respect to those properties.
The principle upon which robustness is exploited here is that of multiple, independent descriptions. No doubt there are many other applications of this principle waiting to be realized, and other principles upon which robust systems may be engineered.
More detailed description, examples, and available software for robust hyperlinks and locations is available at the Robust web site, <http://www.cs.berkeley.edu/~phelps/Robust/>.
References
[Bharat and Broder 1998] Krishna Bharat and Andrei Broder. A Technique for Measuring the Relative Size and Overlap of Public Web Search Engines. Proceedings of the Seventh World Wide Web Conference, Brisbane, Australia, 14-18 April 1998. <http://www-sor.inria.fr/mirrors/www7/programme/fullpapers/1937/com1937.htm>
[CNRP] Common Name Resolution Protocol, 18-Oct-99. <http://www.ietf.org/html.charters/cnrp-charter.html>
[Francis et al. 1995] Paul Francis, Takashi Kambayashi, Shin-ya Sato and Susumu Shimizu. Ingrid: A Self-Configuring Information Navigation Infrastructure. December 11-14, 1995. <http://www.ingrid.org/francis/www4/Overview.html>
[Ingham et al. 1996] David Ingham, Steve Caughey, Mark Little. Fixing the "Broken-Link" Problem: The W3Objects Approach. Computing Networks & ISDN Systems, Vol. 28, No. 7-11, pp. 1255-1268: Proceedings of the Fifth International World Wide Web Conference, Paris, France, 6-10 May 1996. <http://arjuna.ncl.ac.uk/group/papers/p050.html>
[Inktomi 2000] Inktomi. Web Surpasses One Billion Documents. Press Release, 18 January 2000. <http://www.inktomi.com/new/press/billion.html
[Kahn and Wilensky, 1995] Robert Kahn and Robert Wilensky. A Framework for Distributed Digital Object Services. cnri.dlib/tn95-01, May 13, 1995. <http://www.cnri.reston.va.us/k-w.html>
[Macskassy and Shklar 1997] Sofus Macskassy and Leon Shklar. Maintaining information resources. Proceedings of the Third International Workshop on Next Generation Information Technologies (NGITS'97), June 30-July 3, 1997, Neve Ilan, Israel. <http://www.cs.rutgers.edu/~shklar/papers/ngits97/>
[Martin and Holte 1998] Joel D. Martin and Robert Holte. Searching for Content-based Addresses on the World-Wide Web. Proceedings of Digital Libraries '98. <http://ai.iit.nrc.ca/II_public/DL98paper.ps>
[Mind-it] Mind-it. <http://www.netmind.com/html/individual.html>
[OCLC] OCLC PURL Service. <http://www.purl.org/>
[Phelps 1998] Thomas A. Phelps. Multivalent Documents: Anytime, Anywhere, Any Type, Every Way User-Improvable Digital Documents and Systems. Ph.D. Dissertation, University of California, Berkeley. UC Berkeley Division of Computer Science Technical Report No. UCB/CSD-98-1026, December 1998. Also see the general and technical home pages <http://www.cs.berkeley.edu/~phelps/papers/dissertation-abstract.html>, <http://www.cs.berkeley.edu/~wilensky/MVD.html>, <http://www.cs.berkeley.edu/~phelps/Multivalent/>
[Phelps and Wilensky 2000-1] Thomas A. Phelps and Robert Wilensky. Robust Hyperlinks Cost Just Five Words Each. UCB Computer Science Technical Report UCB//CSD-00-1091, 10 January, 2000. <http://www.cs.berkeley.edu/~wilensky/robust-hyperlinks.html>
[Phelps and Wilensky 2000-2] Thomas A. Phelps and Robert Wilensky. Robust Intra-document Locations. Proceedings of the 9th World Wide Web Conference. <http://www.cs.berkeley.edu/~phelps/Robust/Locations/RobustLocations.html>
[Sollins and Masinter, 1994] K. Sollins and L. Masinter. Functional Requirements for Uniform Resource Names, Network Working Group Request for Comments 1737, December 1994. <http://www.w3.org/Addressing/rfc1737.txt>
[Wilensky and Phelps 1998] Robert Wilensky and Thomas A. Phelps. "Multivalent Documents: A New Model for Digital Documents", University of California, Berkeley Computer Science Technical Report, CSD-98-999, March 13, 1998. <http://www.cs.berkeley.edu/~phelps/papers/techrep98-abstract.html>
[XPointer] XML Pointer Language (XPointer). W3C Working Draft 9 July 1999. <http://www.w3.org/1999/07/WD-xptr-19990709>
Copyright © 2000 Thomas A. Phelps and Robert Wilensky
Search | Author Index | Title Index | Monthly Issues
Previous story | Next Story
Home | E-mail the Editor
D-Lib Magazine Access Terms and Conditions
DOI: 10.1045/july2000-wilensky