|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Justin Littman |
![]()
IntroductionAs the Library of Congress (LC) expands its digital initiatives, one of the most pressing challenges is scaling digital content "transfer processes." Transfer processes are increasing in quantity, size, and diversity of transfer scenarios. Transfer processes comprise the human- and machine-performed tasks that involve:
Transfer processes are also inextricably linked with digital preservation, as many of the tasks performed during transfer are involved with preservation or must be performed properly in order to mitigate preservation risks. The Office of Strategic Initiative's (OSI) Repository Development Team (RDT) is developing a portfolio of services and components to address the challenges posed by scaling transfer processes. While the portfolio is expanding, the focus of this article will be on two core services, the Inventory Service and the Workflow Service.2 Before proceeding to examine these services, it will be useful to further delineate the transfer problem space. After examining these services, their role in mitigating preservation risks will be considered. The Transfer Problem Space at LCAt least at present, the collection of digital content is focused around a project (as opposed to, say, being grouped by department), where at LC that project is staffed by a project team (which is likely to have members from multiple parts of the organization at LC). For example, the National Digital Newspaper Program (NDNP)3 project is focused on the collection of historical newspapers and is staffed by a project team from OSI and Library Services. Depending on how content is acquired, a project may have multiple transfer scenarios. There is no single transfer process that can be used for every transfer scenario for every project at LC. Some of the ways that transfer processes may vary include:
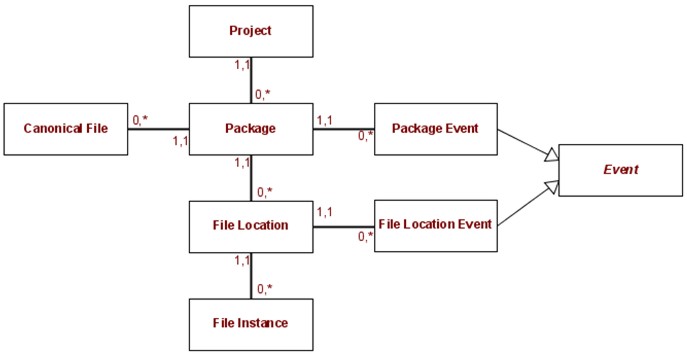
This diversity is driven by the fact that the appropriate transfer process depends on the requirements (preservation, access, cost, control, etc.) of a project, and the requirements at LC vary considerably. Also, for many of the transfer activities, best practices or common approaches are still emerging, which tends to lead to diversity. Despite this diversity, transfer processes can be roughly characterized as either simple or complex. This distinction is important because different solutions may be appropriate for simple and complex transfer processes. A simple transfer process often will only have a few steps and those steps may be performed "by hand" or through simple scripting. Often simple transfer processes are ad hoc, one-time, or infrequent. An example of simple transfer processes are those for the deposit of digital content by National Digital Information Infrastructure and Preservation Program5 (NDIIPP) partners at LC.6 Each partner may deliver its content by a different transport mechanism, e.g., shipping hard drives or network transfer using parallel rsync over Internet2. Once acquired, the digital content must only be inventoried and placed in archival storage. A complex transfer process often will have many steps, some of which are tasks that must be performed by people. Complex transfer processes are usually performed numerous times. An example of a complex process is the NDNP transfer process. In the NDNP transfer process, packages of digitized newspaper prepared by awardees, institutions that are funded by the National Endowment of the Humanities (NEH) to digitize the newspapers, are delivered on external hard drives, validated by an NDNP-specific validation application, manually inspected by a member of the quality review team, copied to archival storage, ingested into an access application, and partially copied to production storage. Initially this transfer process was managed by team members updating a wiki;7 currently it is managed using a ticketing system.8 Both approaches have proven inadequate as the number of transfers and number of awardees have expanded. A further aspect of the transfer problem space is the nature of a "package." The RDT has constrained the object of transfer to a "package," where a package is some related set of digital content that is transferred together. The meaning of "related" may vary from project to project and is determined by the project team. The size of a package may vary, but again is determined by the project team. For example, for NDNP, the average package size is 400gb, largely determined by the capacity of an external hard drive. Furthermore, the digital content of a package must reach a point in its lifecycle in which it is static. Packages of digital content are contrasted against digital content that is transferred a single digital object at a time, e.g., a feed of ejournal articles, digital objects that are under construction, or digital objects that are regularly updated. It is the experiences of the RDT that most projects' transfer processes naturally utilize the package as an object of transfer. Transfer processes that use other objects of transfer may require the extension of existing services and components or the creation of new ones. The Inventory ServiceThe goal of the Inventory Service is to satisfy a complementary set of needs that emerged from the experience of doing transfers "by hand." These include: keeping track of the set of packages for a project and for a particular package; and keeping track of what has happened to that package, the contents of the package, and the locations of the package. The Inventory System has three parts: the Package Modeler, a suite of command line inventory tools, and a reporting web application. The Package Modeler implements a data model for packages that can be updated, persisted, and queried. More exactly, the Package Modeler is implemented using Java objects mapped to a PostgreSQL9 database using Hibernate10 for object-relational mapping. The inventory tools inspect packages and update the Package Modeler. The reporting web application allows users to view reports on packages. (The reporting web application is not stand-alone; it is a part of the Transfer UI described below.) The core of the Inventory System is the data model implemented by the Package Modeler.11 The primary entities in the data model are Projects, Packages, Canonical Files, File Locations, and File Instances. (Capitalization will be used to indicate data model entities.)
A Package is associated with a single Project. Each Package has an identifier, which is unique across that Project. The project team determines the identifier scheme used for a Project and the identifier that is assigned to a Package. A Package may have a set of Canonical Files. Canonical Files are assertions made by a project team about the files that constitute a package. In other words, the project team is asserting, "To have a copy of this package, you must have these files." Canonical Files are abstract, in the sense that they do not represent a particular set of files on a storage system. It is up to a project team to determine when and what version of a package should be canonicalized; it is not necessarily the version that is delivered to LC. For each Canonical File, relative path, filename, and fixity information is recorded. A Package may also have a set of File Locations. File Locations represent places where files are stored. A File Location has a base path, and a storage system or a storage device, e.g., "File Location A is the /ndnp/batch1 directory on the RS15 storage system" or "File Location B is the / directory of the external hard drive with the serial number 12345". It is also recorded whether the files at a File Location conform to the BagIt12 specification, as this is important for how applications may process a File Location. A File Location may have a set of File Instances. File Instances are assertions made by a project team about the set of files at a File Location. In other words, the project team is asserting, "If everything is normal, you should find these files at this location." For each File Instance, filename and fixity information is recorded. From the definition of these data model entities, it follows that in general, it is an error if the files on the storage system are examined and anything less than the complete set of File Instances at the File Location is found. Also, in some cases, finding additional files at the File Location may be an error. There are a number of possible relationships between the set of File Instances at a File Location and a Package's set of Canonical Files. The set of File Instances at a File Location may be:
Since the Package Modeler must also represent the history of a package, it also includes entities for events. Events are actions that apply to one of the other data model entities. In particular, there are events that apply to Packages (Package Events) and File Locations (File Location Events). Examples of Package Events include:
Examples of File Location Events include:
While a particular type of Event may have some individual attributes, Events have a number of common attributes including:
It is important to note that Events are distinct from both logging and auditing. Events are distinct from logging, because they record higher-level actions, rather than software-level, debugging statements. Events are distinct from auditing, since they are not independent of the entities to which they apply. That is, they do not record redundant information that is adequate for double-entry auditing. Two principles, in particular, influenced the design of the Package Modeler. The first principle is that the Package Modeler is unaware of the intellectual content of the digital objects, except where that awareness is necessary for the transfer process itself. So, for example, when an NDNP package is modeled, the Package Modeler does not represent any information about the newspaper issues contained in the package. It is assumed that some other application, e.g., an access application, will introspect the digital objects to gain awareness of the intellectual content as appropriate. The second principle is that the data model for packages be extensible to meet the unique modeling requirements of a project. This is satisfied by allowing projects to extend the Package entity, as well as allowing the addition of other entities, including additional Events. So, for example, the NDNP project team has extended the Package object to allow a package to be associated with an awardee (recall, the organization that provided the content) and the award phase, which is the phase of NEH funding. While the Inventory System can be used by itself, it can also be invoked by other services, such as the Workflow Service described below. The Workflow ServiceThe goal of the Workflow Service is to enable the management of complex transfer processes. The Workflow Service is a framework developed by the RDT that integrates a workflow engine, a message broker for asynchronously invoking remote services that perform processing as part of the workflow, and the Package Modeler. The underlying workflow engine is jBPM,14 an open-source workflow system from JBoss. The drivers of the Workflow Service are process definitions, which represent the steps of a transfer process and are written in a process definition language. jBPM Process Definition Language (jPDL), the native process definition language of jBPM, is encoded as XML but can be designed using the Graphical Process Designer, a visual editor implemented as a plugin for the Eclipse platform.15 jPDL is extremely powerful and flexible. However, to summarize its capabilities, jPDL provides the ability to:
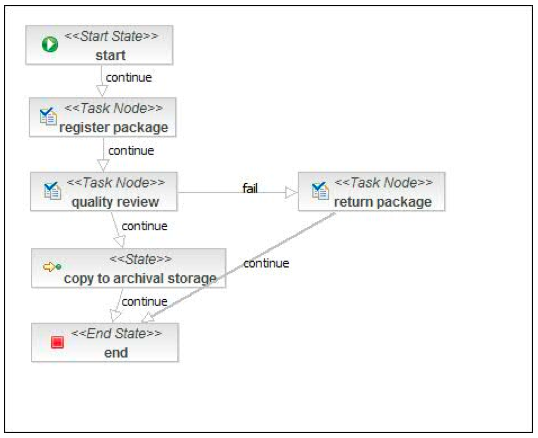
jPDL supports various mechanisms for determining how tasks are assigned to people or groups. For developers, one particularly useful feature of jBPM is the ability to write unit tests to ensure that process definitions are correct. The following shows the visual representation of a simple process definition produced by the Graphical Process Designer, as well as the XML encoding:
The XML Encoding
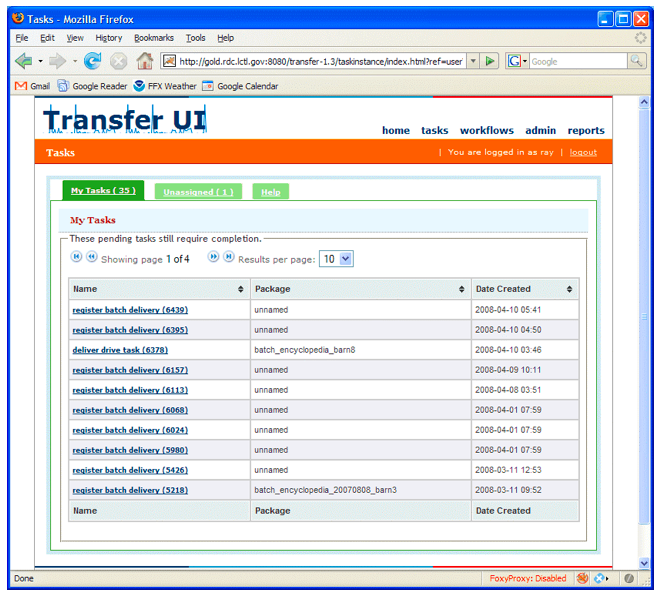
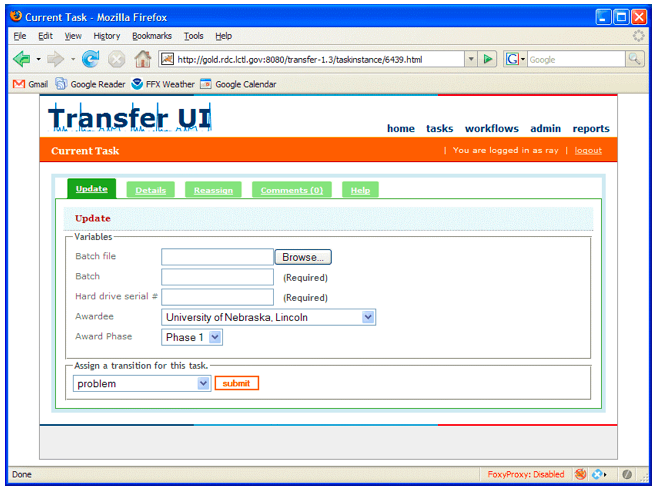
Each project team defines one or more process definitions for that project's transfer scenarios. These process definitions are deployed to the workflow engine, which upon request creates new instances of processes and executes the process instances. Executing the process instance may involve invoking services or components that are local or remote and synchronous or asynchronous, updating the Package Modeler, or requesting that people perform tasks. Users interact with the workflow engine using the Transfer UI, which is a web application implemented using Spring MVC.16 The Transfer UI allows users to initiate, monitor and administer process instances; get lists of tasks to be performed; and update tasks, i.e., notify the workflow engine that the task has been completed. The Transfer UI also provides information required by the workflow engine, including the outcome of the task.
Thus, the Workflow Service provides a compelling solution for complex transfer processes, especially those that involve the orchestration of work performed by people and automated processes. Preservation RiskIn addition to facilitating transfer, the Inventory Service and the Workflow Service assist project teams in mitigating preservation risks.17,18 The Inventory System helps mitigate the loss of context by keeping track of packages, especially the location and history of packages. It also helps mitigate the risk from various forms of storage failures, including bit rot, by storing information that can be used in the discovery, assessment, and recovery from such failures. There have been cases in the past where it has been problematic to determine exactly what has been lost when a storage failure occurred or verify that a restore was correct. This same information can also be used to mitigate the risk of data corruption over noisy or bad networks by checking digital content both before and after transport. The Workflow Service mitigates the risk of human error by facilitating the reduction of the number of transfer tasks performed by humans. More importantly, it takes the management of transfers out of human hands. The use of these new services does entail some additional risk, both preservation risk and more general project risk. Additional software systems involve risk of programmer error. The services also require additional software and hardware infrastructure, some which involves technologies that require additions or modifications to the LC infrastructure. And finally, there is risk that codifying transfer processes in code will reduce flexibility and the ability to rapidly respond to change. ConclusionAt present, the Inventory Service has been implemented and will shortly be put into production for NDIIPP's simple transfer processes. The core components of the Workflow Service have been implemented and the process definition for the NDNP transfer process is complete. They will be moved into production as soon as acceptance testing is complete. Both services and the NDNP process definition will undergo continual refinement. The RDT hopes to begin developing process definitions for other projects shortly, as well as developing other services, e.g., a service for performing external audits of storage systems and a web application facilitating the deposit of packages. While some aspects of transfer that the Inventory Service and the Workflow Service are intended to address are unique to LC, it is likely that other institutions are already encountering or soon will be encountering similar challenges. This is especially true with the number of transfers, the size of transfers, the diversity of transfer processes, and the associated need to mitigate preservation risks. It is hoped that these services, and the experience gained from using them, will inform the practice of other institutions collecting and managing digital content. AcknowledgmentsThanks to Dan Chudnov, Jim Gallagher, Mike Giarlo, Babak Hamidzadeh, Leslie Johnston, and Ed Summers for reviewing this article. Notes1. Despite seemingly endless discussions among Repository Development Team members, attempts to more precisely characterize "transfer" were fruitless, so for present purposes we will merely gesture at it. Many of my colleagues disagree with this characterization of transfer, generally preferring to limit the term "transfer" to the movement of digital content. 2.Though these may be exposed as web services, "services" here is meant in a more general sense. 3. <http://www.loc.gov/ndnp/>. 4. <http://hul.harvard.edu/jhove/>. 5. <http://www.digitalpreservation.gov/>. 6. <http://www.loc.gov/today/pr/2004/04-171.html>. 7. <http://www.mediawiki.org/wiki/MediaWiki>. 8. <http://www.mantisbt.org/>. 9. <http://www.postgresql.org/>. 10. <http://www.hibernate.org/>. 11. This description is a simplification of the data model. 12. <http://tools.ietf.org/html/draft-kunze-bagit-01>. 13. While the data model for events drew inspiration from PREMIS (http://www.loc.gov/standards/premis/), it neither adopted the PREMIS data model for events nor the XML representation. However, the two data models are compatible, and in an earlier prototype, it was demonstrated that Events from the Package Modeler could be mapped to PREMIS's XML representation. 14. <http://www.jboss.com/products/jbpm>. 15. <http://www.eclipse.org/>. 16. <http://www.springframework.org/>. 17. Rosenthal, David S. H., Thomas Robertson, Tom Lipkis, Vicky Reich, Seth Morabito. Requirements for Digital Preservation Systems: A Bottom-Up Approach. D-Lib Magazine. <doi:10.1045/november2005-rosenthal>. 18. Baker, Mary, Kimberly Keeton, Sean Martin. Why Traditional Storage Systems Don't Help Us Save Stuff Forever. HPL-2005-120. <http://www.hpl.hp.com/techreports/2005/HPL-2005-120.pdf>. |
||
| |
||
|
Top | Contents | ||
| | ||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/january2009-littman
|