|
||
D-Lib Magazine |
|
| William Y. Arms ([email protected]) |
![]()
BackgroundThe NSDL is a broad program to build a digital library for education in science, mathematics, engineering and technology. It is funded by the National Science Foundation (NSF) Division of Undergraduate Education. (The initials NSDL stand for the National SMETE Digital Library, where SMETE is an acronym for Science, Mathematics, Engineering and Technology Education.) Several articles in D-Lib Magazine have described the vision for the library and the NSF's strategy for reaching that vision [Wattenberg 1998], [Zia 2001]. Currently, NSF is funding 64 projects, each making its own contribution to the library, with a total annual budget of about $24 million. Many projects are building collections; others are developing services; a few are carrying out targeted research. The Core Integration task is to ensure that the NSDL is a single coherent library, not simply a set of unrelated activities. In summer 2000, the NSF funded six Core Integration demonstration projects, each lasting a year. One of these grants was to Cornell University and our demonstration is known as Site for Science. It is at http://www.siteforscience.org/ [Site for Science]. In late 2001, the NSF consolidated the Core Integration funding into a single grant for the production release of the NSDL. This grant was made to a collaboration of the University Corporation for Atmospheric Research (UCAR), Columbia University and Cornell University. The technical approach being followed is based heavily on our experience with Site for Science. Therefore this article is both a description of the strategy for interoperability that was developed for Site for Science and an introduction to the architecture being used by the NSDL production team. The scale of the collectionsThe six Core Integration demonstration projects worked as a loose collaboration, with each project having a different emphasis. At Cornell, our particular focus was on scale. The grand vision is that the NSDL become a comprehensive library of every digital resource that could conceivably be of value to any aspect of education in any branch of science and engineering, both defined very broadly. The following have been suggested as five-year targets for the size of the NSDL.
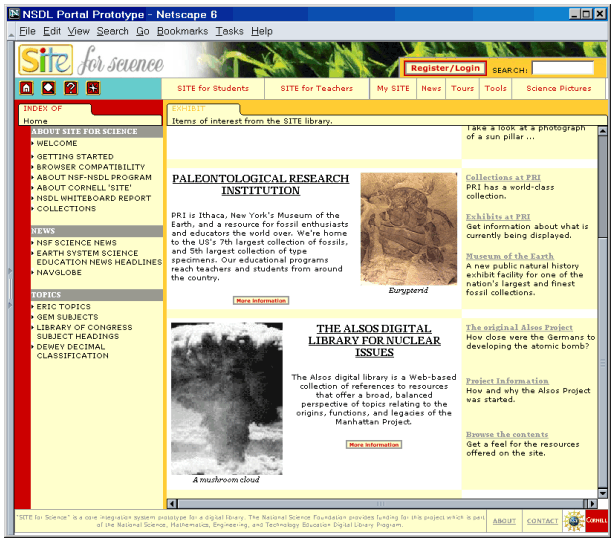
The most interesting figure in Table 1 is the number of possible collections. An informal definition of a collection is a group of items that are managed together. As an example, Figure 1 is a screen dump from the Site for Science web site. It shows images from two typical collections: the Alsos Digital Library for Nuclear Issues, which is an NSDL-funded collection, and the Paleontological Research Institution in Ithaca, New York, which receives no NSDL funding.
In addition to working with NSDL-funded collections, the Site for Science team began a process of working with other collections. A particularly fruitful relationship has been developed between the NSDL and the Institute for Museum and Library Services (IMLS). This relationship has produced two documents on interoperability. The first provides guidance on building good digital collections [IMLS 2001a]. The second addresses collaboration between IMLS and the NSDL [IMLS 2001b]. Other potential collections range in size from very large (for instance the online journals of a major publisher, NASA's collections of images, or the GenBank database of genetic sequences) to small web sites. Even casual browsing of the web reveals an immense quantity of materials. Primary materials include collections of flora and fauna, images of the earth and of space, and a wide variety of data sets. The history of science is particularly well represented online, as is the technology area, with descriptions of how things work and how to build them. Educational materials that should be incorporated in the NSDL include class web sites, which often include class notes, sample examinations and slides. Some of these materials are transitory or of indifferent quality, but many are excellent. Many have been assembled by small organizations or dedicated individuals; some are side products of other work. The Core Integration task is to provide access to these materials so that they appear as a single digital library. InteroperabilityInteroperability among heterogeneous collections is a central theme of the Core Integration. The potential collections have a wide variety of data types, metadata standards, protocols, authentication schemes, and business models. They are managed by large numbers of organizations, some of which have grants from the NSF, but most of which are independent. Some are well funded, but many have limited resources. Some were established specifically for education, but most are not designed primarily for education. All have their own priorities. The Site for Science strategy for interoperability was first articulated in a memorandum that was distributed among the Core Integration demonstration projects in fall 2000 [Arms 2000]. This memorandum described a model based on the concept of "levels of interoperability". (The later term "spectrum of interoperability" comes from an observation by Steve Worona in spring 2001.) The goal of interoperability is to build coherent services for users, from components that are technically different and managed by different organizations. This requires agreements to cooperate at three levels: technical, content and organizational.
Defining these agreements is hard, but the central challenge is to create incentives for independent digital libraries to adopt them. A model for interoperabilityIn 1998 Sarantos Kapidakis suggested that interoperability could be analyzed by comparing cost against functionality [Kapidakis 1998]. The following model, based on that suggestion, was first described in [Arms 1999]. The traditional approach to interoperability is for all participants to agree to use the same standards. If each service implements a comprehensive set of standards then interoperability follows. However, experience has shown that interoperability through comprehensive standardization is hard to achieve. Adoption of common standards provides digital libraries with valuable functionality, but at a cost. Some costs are directly financial: the purchase of equipment and software, or hiring and training staff. More often the largest costs are organizational. Rarely can a single aspect of a digital library be changed in isolation. Introducing a new standard requires inter-related changes to existing systems, altered work flow, changed relationships with suppliers, and so on.
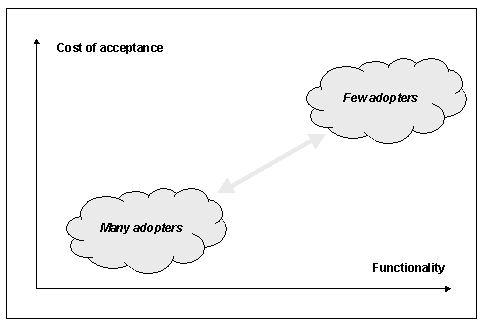
Figure 2 shows a way to look at the trade-offs. The vertical axis shows the cost to an organization of adopting a standard. The horizontal axis shows the functionality that the organization gains. If the cost of adopting a standard is high, it will be adopted only by those organizations that truly value the functionality provided. Conversely, when the cost is low, more organizations will be willing to adopt it, even if the functionality is limited.
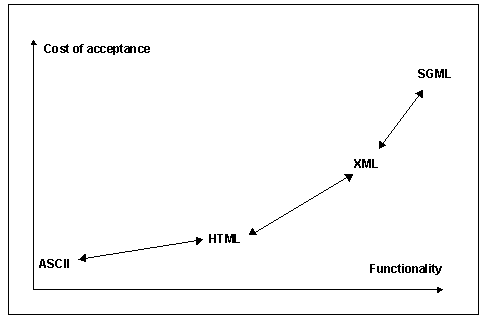
Figure 3 applies this model to methods for representing text. At the left of this figure is ASCII, which has very limited function, but requires essentially no effort to adopt, as it is supported by almost every computer in the English speaking world. At the other end of the scale is SGML, much more powerful, but requiring considerable effort to learn and to integrate into a computing system. SGML is used in publishing and some digital libraries, where the functionality justifies the cost of adoption, but has little penetration elsewhere. Lower down the curve, HTML provides moderate functionality, but has a low cost of adoption and is therefore widely used, while XML is gaining acceptance as an intermediate point. Curves similar to Figure 3 can be constructed for other aspects of digital libraries, such as metadata standards, transaction protocols, authentication, etc. In each case, a variety of options are currently in use, ranging from lost cost with low functionality to higher functionality but with a greater cost of adoption. With very few exceptions, the widely adopted standards are those with the low cost of adoption, even though they usually have restricted functionality. It is important to recognize that there is no best point on these curves. Every point is optimal for some purpose. For example, libraries have developed a framework for interoperability based on the Z39.50 protocol, the Anglo American Cataloguing Rules and MARC. This combination of standards provides an excellent choice for libraries, because they value the functionality and have catalog records in this form, but the cost of adopting these standards is high unless an organization already has metadata that meets them. Hence, few other collections of information on the Internet have adopted these standards because, for most other organizations, the cost of adoption is high relative to the functionality gained. A heterogeneous digital library, such as the NSDL, will include some collections that support powerful standards, such as Z39.50 or SGML, but must expect that most collections will use standards with lower functionality, such as HTTP or HTML, because of the lower cost of adoption. Lowering the curve and movement along the curveA curve such as Figure 3 is not static. The curve can be changed, either by lowering the cost of adoption or by developing new methods that increase the functionality. If an alternative is introduced that is to the right or below the current curve, then it will become optimal for some group of users. Current research and development on web information systems and digital libraries are often aimed at such changes. For instance, text-based applications clearly gain functionality if they support a range of scripts beyond English. Recently, the cost of building such applications has been reduced by the development of UTF-8, an encoding of Unicode that can coexist with ASCII, and Unicode support from vendors such as Microsoft. These developments have lowered the curve and stimulated widespread adoption. Much of the research of the authors of this paper aims at lowering the middle section of this curve, looking for approaches to interoperability that have low cost of adoption, yet provide substantial functionality. One of these approaches is the metadata harvesting protocol of the Open Archives Initiative (OAI), which is discussed later in this paper. Also, although every point of the interoperability curve is optimal in some context, this does not imply that every digital library must remain at a fixed point on the curve. Libraries can move along the curve. If either the cost can be reduced or the functionality enhanced, collections may be motivated to move towards the right, towards stronger interoperability. Functionality is increased if many collections adopt the same standard. This creates a bandwagon effect. It is one of the reasons that scale is important to the NSDL. The concept of encouraging movement along the interoperability curve comes from discussions with Lee Zia at the NSF. He points out that the NSF can use its resources to encourage movement. When the NSFnet backbone was created in the late 1980s, the NSF gave grants to universities to help them connect to it. This lowered their costs and stimulated the expansion of the backbone into today's Internet. In the same way, NSDL grants from the NSF help lower the cost to collections of adopting standards, such as the recommended metadata standards and the OAI harvesting protocol. Levels of interoperability in the NSDLFor Site for Science, we identified three levels of digital library interoperability:
In this list, the top level provides the strongest form of interoperability, but places the greatest burden on participants. The bottom level requires essentially no effort by the participants, but provides a poorer level of interoperability. The Site for Science demonstration concentrated on the harvesting and gathering, because other projects were exploring federation. FederationFederation can be considered the conventional approach to interoperability. In a federation, a group of organizations agree that their services will conform to certain specifications (which are often selected from formal standards). The libraries that share online catalog records using Z39.50 are an example of a federation. Another federation is the ADEPT project for geospatial materials, led by the University of California at Santa Barbara, one of our partners in the Core Integration production team [Alexandria]. Smete.org is an NSDL project that is building a federation among some of the leading collections of education materials [Smete.org]. Smete.org began as another Core Integration demonstration project and is continuing as an NSDL collection project. As discussed above, the principal challenge in forming a federation is the effort required by each organization to implement and keep current with all the agreements. Since the cost of participation is high, typical federations have small but dedicated memberships. HarvestingThe difficulty of creating large federations is the motivation behind recent efforts to create looser groupings of digital libraries. The underlying concept is that the participants agree to take small efforts that enable some basic shared services, without being required to adopt a complete set of agreements. The Open Archives Initiative (OAI) is based around the concept of metadata harvesting [OAI 2001]. Each digital library makes metadata about its collections available in a simple exchange format. This metadata can be harvested by service providers and built into services such as information discovery or reference linking. Two members of the Site for Science team act as the executive for the OAI, and Site for Science was one of the alpha test sites for the metadata harvesting protocol. Metadata harvesting was first developed by the Harvest project in the early 1990s, but the approach was not widely adopted [Bowman 1994]. The concept was revived in 1998/99 in a prototype known as the Universal Preprint Server [Van de Sompel 2000]. This prototype concluded in favor of metadata harvesting as a strategy to facilitate the creation of federated services across heterogeneous preprint systems. The OAI work, which is derived from this experiment, emphasizes the core functionality that can be achieved by digital libraries sharing metadata. It minimizes the cost by using a simple protocol based on HTTP, by providing software that is easily added to web servers, and by documentation, training and support [Lagoze 2001]. While services built by metadata harvesting are usually less powerful than those provided by federations, the burden of participating is much less. As a result, many more organizations are likely to join and keep their systems current. This is confirmed by the rapid acceptance of the metadata harvesting protocol of the OAI. GatheringEven if the various organizations do not cooperate in any formal manner, a base level of interoperability is still possible by gathering openly accessible information using a web crawler. The premier examples of this approach are the web search engines. Because there is no cost to the collections, gathering can provide services that embrace large numbers of digital libraries, but the services are of poorer quality than can be achieved by partners who cooperate directly. Some of the most interesting web research at present can be thought of as adding extra function to the base level, which will lead to better interoperability, even among totally non-cooperating organizations. Even though the concept of a fully semantic web is a pipe dream, it is reasonable to expect that the level of services that can be provided by gathering will improve steadily. ResearchIndex (formerly known as CiteSeer) is a superb example of a digital library built automatically by gathering publicly accessible information [ResearchIndex]. MetadataIn an ideal world all the collections and services that the NSDL wishes to encompass would support an agreed set of standard metadata. The real world is less simple. For example, when we asked the various NSDL collections about their plans, one project replied quite openly, "We are pleased with the technical side of the database and web access but we are complete novices in terms of how to make our collection part of the digital library. I assume this hinges on appropriate metadata, but I am not sure exactly what kinds " However, the NSDL does have influence. We can attempt to persuade collections to move along the interoperability curve. The prospect of obtaining NSF's funding provides useful incentive for collections. The Site for Science metadata strategy is based on two principles. The first is that metadata is too expensive for the Core Integration team to create much of it. Hence, the NSDL has to rely on existing metadata or metadata that can be generated automatically. The second is to make use of as much of the metadata available from collections as possible, knowing that it varies greatly from none to extensive. Based on these principles, Site for Science, and subsequently the entire NSDL, developed the following metadata strategy:
Metadata formatsEarly in 2001, the NSDL Standards and Metadata Workgroup, which represents all NSDL projects, identified the following list of preferred metadata element sets.
Some of the collections that we would like to see in the NSDL support one of these standards, but far from all do. The collections that have good metadata using the preferred standard are outnumbered by those that have poor or idiosyncratic metadata, or none at all. Even those collections that purport to support one of the standards often have local variations. The strategy developed by Site for Science and now adopted by the NSDL is to accumulate metadata in the native formats provided by the collections, hopefully in the eight preferred standards. If a collection supports the protocols of the Open Archives Initiative, it must be able to supply unqualified Dublin Core (which is required by the OAI) as well as the native metadata format. Other than that, we do not ask the collections to supply any specific metadata format. Tools are available to convert from the preferred standards to Dublin Core. Thus, three categories of metadata are available and can be stored in a metadata repository:
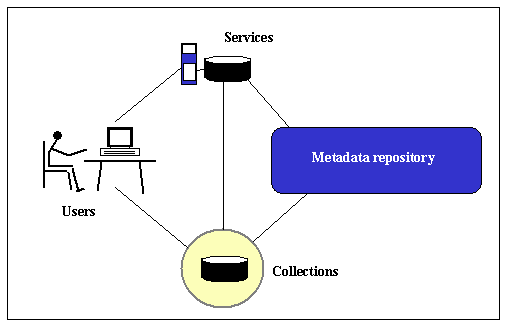
By providing item-level metadata both in its original form and also as normalized metadata, the repository offers service providers a choice. Services that are able to make use of the original metadata can use it. Others can use the simpler, normalized records. No Core Integration effort is being put into the creation of item-level metadata by hand. Every item-level record in the repository is either received from the collections or generated automatically. However, we are prepared to put human effort into creating collection-level metadata for important collections. For collections that do not provide item-level metadata, we attempt to generate minimal records automatically. Site for Science developed tools for automatically creating Dublin Core records, both collection-level and item-level. We are now working with the NSDL service project "GEM: Breaking the Metadata Generation Bottleneck", at Syracuse University [GEM]. The metadata repositoryFrom a computing viewpoint, the metadata repository is the key component of the Site for Science system. The repository can be thought of as a modern variant of the traditional library union catalog, a catalog that holds comprehensive catalog records from a group of libraries. Figure 4 shows how the metadata repository fits into the Site for Science architecture.
Metadata from all the collections is stored in the repository and made available to providers of NSDL services. Some of these services, such as a comprehensive search service, are provided by the Core Integration team, some by other NSDL projects, and some by third parties. For distribution to the services providers, the repository makes all the metadata available through the OAI protocol. The only restrictions are that some of the collections impose limitations on the redistribution of their native metadata. In the NSDL, the metadata repository will probably be mirrored and may be distributed over several computers, but it will be managed as a single system. The decision to have a centralized metadata repository is a consequence of the spectrum of interoperability. In contrast, tightly knit federations often rely on distributed computing to provide services such as searching. For instance, federations of library catalogs expect every library to have its own catalog. If a user wishes to search several catalogs, the query is sent to each separately. Either the search is broadcast automatically, or the user selects the specific sites to search. Our experience, notably with the Dienst system [Davis 1996], is that this style of distributed searching does not scale well. Federated services decline in responsiveness and reliability as the number of independent servers grows. Services that must communicate with many digital libraries in real time are vulnerable to problems at any one of them. With a hundred or more sites, even if they are well managed, the chance of a network delay or a faulty server is considerable. Furthermore, in the NSDL, there is no expectation that every system will support the same query formats and protocols, so that this style of distributed search is impossible. Therefore, Site for Science followed the more robust strategy of gathering metadata to a centrally managed system. It is notable that all the web search engines follow the same strategy of providing services from a central system, not by distributed processing across all the collections. The metadata repository is a generalization of this approach. Site for Science developed a prototype of the repository, with simple, well-documented interfaces that can be used by all NSDL service providers. During the current year, this repository is being reimplemented and its scope extended to include metadata for all NSDL collections. The most important of the interfaces is to make the metadata available via the OAI protocol. To enable collections to contribute their metadata to the repository, Site for Science offered three options: metadata harvesting, FTP, and web crawling. The preferred method is to use the OAI metadata harvesting protocol. Metadata harvesting allows digital libraries to share metadata about their collections, without the need to support real-time, distributed services. This protocol is very simple, but it still requires a certain level of commitment from the participants. For important collections that have suitable metadata but are unable to make that commitment, Site for Science provided batch transfer of metadata files using FTP. This is slightly more labor-intensive, but it is well proven and sometimes is the only option. The Site for Science demonstration used web crawling to gather specific collections. We are now working with the Mercator crawler, developed by Compaq Computer, in a series of experiments to identify and evaluate collections. The goal of this research is not simply to gather known collections. The aim is to use focused web crawling to identify potential NSDL collections automatically. Using the metadata repository to support the Site for Science portalsAs shown in Figure 4, end users do not interact directly with the metadata repository. Their access to the library is through services or directly with the collections. Some services may also interact directly with collections. Another part of the Core Integration work, which is not described in this paper, is to provide portals that present these aspects of the library to users.
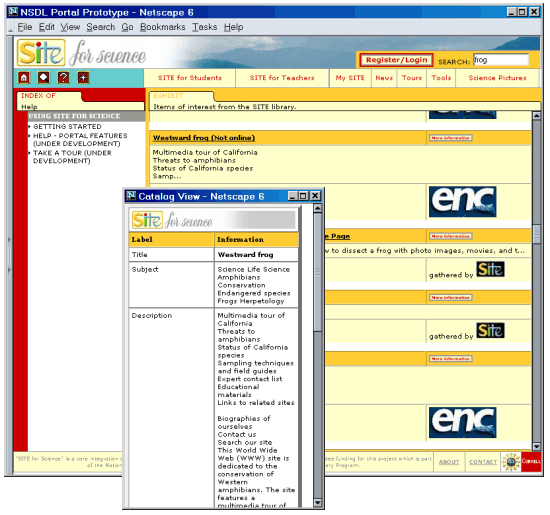
Figure 5 is an illustration of how information in the metadata repository is used to build services and how the services can be presented to the user. In this example, a user has searched on the term, "frog". In Site for Science, the query is matched against an index of all the records in the metadata repository. In a panel in the main window, short records are displayed for each item found. Several of the records in this example come from the Eisenhower National Clearinghouse for K-12 education in science and mathematics [Eisenhower]. Since the source of the information is stored in the metadata repository, the portal can display an ENC icon as part of the record. This acknowledges the source of the item. At this stage, the user has several choices. In this example, the user has clicked on a button labeled "More information" and the full metadata record has been displayed in a separate window. Where the item is available online, the user could also have clicked on a link that goes directly to the resource. (The Eisenhower National Clearinghouse is a mixed collection with only some of the materials available online.) The Site for Science demonstration used a very simple search service. For the production version, a search service is being developed by the Center for Intelligent Information Retrieval at the University of Massachusetts, Amherst [CIIR]. This service will extract metadata from the metadata repository, by harvesting using the OAI protocol. It will also access collections directly and, where possible, index textual materials. This example highlights the heterogeneous nature of the NSDL and the challenges in building coherent services across collections. The search service has the challenge of finding materials when the amount of information about each varies greatly. This is a particular challenge for non-textual materials where it is not possible to combine metadata with full text indexing. The portal has the challenge of presenting the results to the user in a comprehensible manner. The futureSite for Science was a successful technology demonstration, but it was comparatively small. While we have demonstrated the technology, we have not yet shown its scalability and effectiveness. The philosophy of a spectrum of interoperability appears to offer the best hope of building a very large library without a large staff, but there are some real uncertainties. They concern the two basic criteria of cost and functionality. The first challenge is cost. The NSDL is conceived of as the largest and most heterogeneous digital library ever built. Yet the entire NSDL budget is less than the budgets of many university libraries. Clearly, the NSDL has to rely heavily on automated processes, but, even so, to build a very large library will require relentless simplification. Technology will be acquired from many sources and many partners, but some code will have to be written by the team; systems integration will be a major task. Can we build, maintain and operate the Core Integration system with the small technical team that is envisaged? Can a small team of librarians manage the collection development and metadata strategies for a very large library? The second challenge is functionality. The inevitable simplifications combined with high variation in the collections mean that the NSDL services will be less than perfect. Perhaps the biggest uncertainty comes from following a metadata strategy that accepts such enormous variations in the quality of metadata and includes no provision for creating item-level metadata. For example, we know that the search service will be hampered by the inconsistencies in the metadata and the differences between textual and other materials. Can the NSDL actually build services that are significantly more useful than the general web search services? As yet there are no examples of the metadata harvesting approach of the Open Archives Initiative being used to create large-scale heterogeneous services. Will it prove adequate for the scale and variety envisioned? Fortunately, the NSF understands that the Core Integration strategy combines implementation with innovation. While the foremost goal is to build a system that will be of practical value in education, the NSF recognizes and encourages the element of research. We are now at the time when planning has to end and a real system has to be built. Our responsibility to the NSF is to develop the NSDL through a series of phases, each of which is worthwhile individually and each of which builds towards the long-term goals. The ideas described in this paper provide a starting point. The end point may look very different. AcknowledgementsThe ideas on interoperability in this paper draw on discussions with numerous people over several years. The authors would particularly like to thank Sarantos Kapidakis, Dave Fulker, Steve Worona, Lee Zia, Dale Flecker and Priscilla Caplan for their insights, comments and criticisms. This work is funded by the National Science Foundation under grant number 0127308. The ideas in this paper are those of the authors and not of the National Science Foundation. References[Alexandria] Alexandria Digital Library home page. <http://www.alexandria.ucsb.edu/>. [Arms 2000] Arms, William Y., "Thoughts about Interoperability in the NSDL". Draft for discussion, August 2000. <http://www.cs.cornell.edu/wya/papers/NSDL-Interop.doc>. [Arms 1999] Arms, William Y., Digital Libraries, page 208. MIT Press, 1999. <http://mitpress.mit.edu/book-home.tcl?isbn=0262011808>.
[Bowman 1994] Bowman, C. Mic, Peter B. Danzig, Udi Manber and Michael F. Schwartz, "Scalable Internet Resource Discovery: Research Problems and Approaches." Communications of the ACM, 37(8), pp. 98-107, August 1994. <http://portal.acm.org/citation.cfm?id=179704 [Davis 1996] Davis, James R. and Carl Lagoze, "The Networked Computer Science Technical Report Library". Cornell Computer Science Technical Report, 96-1595, 1996. <http://cs-tr.cs.cornell.edu:80/Dienst/UI/1.0/Display/ncstrl.cornell/TR96-1595>. [CIIR] The Center for Intelligent Information Retrieval home page. <http://ciir.cs.umass.edu/>. [Eisenhower] The Eisenhower National Clearinghouse home page. <http://www.enc.org/>. [GEM] The Gateway to Educational Materials (GEM) home page. <http://geminfo.org/>. [IMLS 2001a] Institute for Museum and Library Services, "A Framework of Guidance for Building Good Digital Collections". October, 2001. <http://www.imls.gov/pubs/forumframework.htm>. [IMLS 2001b] Institute for Museum and Library Services, "Report of the IMLS Digital Library Forum on the National Science Digital Library Program". October, 2001. <http://www.imls.gov/pubs/natscidiglibrary.htm>. [Kapidakis 1998] Kapidakis, Sarantos, Unpublished notes prepared for the NSF-EU collaboration, Resource Indexing and Discovery in a Globally Distributed Digital Library, 1998. [Lagoze 2001] Lagoze, Carl and Herbert Van de Sompel, "The Open Archives Initiative: Building a Low Cost Interoperability Framework. Joint Conference on Digital Libraries, Roanoke VA, June 2001. <http://www.openarchives.org/documents/oai.pdf>. [OAI 2001] Open Archives Initiative, "The Open Archives Initiative Protocol for Metadata Harvesting", edited by Herbert Van de Sompel and Carl Lagoze. Version 1.1, July 2001. <http://www.openarchives.org/OAI_protocol/openarchivesprotocol.html>. [ResearchIndex] ResearchIndex: The NECI Scientific Literature Digital Library home page. <http://www.citeseer.org>. [Site for Science] Site for Science home page. <http://www.siteforscience.org/>. [Smete.org] Smete.org home page. <http://www.smete.org/>. [Van de Sompel 2000] Van de Sompel, Herbert, et al. "The UPS Prototype: An Experimental End-User Service across E-Print Archives". D-Lib Magazine, 6 (2), February 2000 <http://www.dlib.org/dlib/february00/vandesompel-ups/02vandesompel-ups.html>. [Wattenberg 1998] Wattenberg, Frank, "A National Digital Library for Science, Mathematics, Engineering, and Technology Education". D-Lib Magazine, 4 (9), October 1998. <http://www.dlib.org/dlib/october98/wattenberg/10wattenberg.html>. [Zia 2001] Zia, Lee L., "Growing a National Learning Environments and Resources Network for Science, Mathematics, Engineering, and Technology Education: Current Issues and Opportunities for the NSDL Program". D-Lib Magazine, 7 (3), March 2001. <http://www.dlib.org/dlib/march01/zia/03zia.html>. Copyright 2002 William Y. Arms, Diane Hillmann, Carl Lagoze, Dean Krafft, Richard Marisa, John Saylor, Carol Terrizzi, and Herbert Van de Sompel |
|||||||||||||||||
| | |||||||||||||||||
| Top | Contents | |||||||||||||||||
| | |||||||||||||||||
| D-Lib Magazine Access Terms and Conditions DOI: 10.1045/january2002-arms
|