
D-Lib Magazine
February 1998
ISSN 1082-9873
Digital Libraries
The Next Generation in File System Technology
Mic Bowman and Bill Camargo
Transarc Corporation
Pittsburgh, Pennsylvania
[email protected] and [email protected]

This paper examines file sharing within corporations that use wide-area, distributed file systems. The applications and user interactions strongly suggest that the addition of services typically associated with digital libraries will improve collaboration. Among these services are content-based file location, strongly typed objects, representation of complex relationships between documents, and extrinsic metadata. When these services are added to wide-area file systems, application integration improves significantly.
1.0 Introduction
Wide-area file systems provide a rich infrastructure for sharing large collections of files among individuals and groups within and between organizations. The simplicity of the file system interface encourages collaboration; a universally accessible file system removes the problem of passing files between collaborators. Features of the underlying technology such as caching, replication, and location transparency ensure optimal performance and high availability. Access controls protect sensitive information from unacceptable use. Backups and hierarchical storage schemes provide long-term archival of files.
There are many examples of successful collaborations based on wide-area file systems [Spasojevic96]. However, the ubiquitous storage services offered by the file system do not address information management problems that arise during collaboration. For example, the file system provides only primitive support for locating files, expressing relationships between files, and identifying the operations that can be applied to a file. The federated nature of wide-area file systems often exacerbates problems of scale, and diversity of file format and use.
Digital library technology addresses the restrictions to collaboration caused by accessing and archiving many files with diverse uses and formats distributed throughout a loose federation of cooperating organizations. If we view the problem of sharing files among organizations as a problem of building and managing objects in a digital library, natural extensions to the file system interface that solve problems of collaboration become apparent. Services for explicit types, metadata management, information retrieval, and construction of meta-objects facilitate dramatic improvements in collaboration.
The intention of this paper is threefold. The first is to encourage the file system community to raise the level of interface to include operations currently supported by digital libraries. Second, we hope to convince the digital library community to look at wide-area file system technology as a basis for building repositories of digital objects. Our final purpose is to educate the digital library community about opportunities to apply digital library technology to corporate information sharing.
The remainder of this paper is laid out as follows: Section 2 describes the characteristics and benefits of a wide-area file system. Section 3 lists three collaborative applications that are typical of those observed in wide-area file systems. Section 4 lists several issues that affect file-system based collaboration. Section 5 proposes several new file system services, taken from digital library technology, that add missing information management operations. Section 6 summarizes efforts in this area. Section 7 concludes.
2.0 Wide-Area File System Benefits
Wide-area file systems facilitate collaboration through a full spectrum of robust and efficient file sharing operations on an international scale through support for a global name space, location transparency, client caching, data replication, and access control mechanisms.
AFS, the Andrew File System, serves as an example of the facilities typically available in a wide-area file system [Howard88, Spector89]. Using a set of trusted servers, AFS presents to clients a location-transparent, hierarchical name space. This means that a user operates with a common directory structure whether accessing files from his Unix workstation in Pittsburgh or the personal computer in his satellite office in Tokyo.
An AFS volume consists of a set of files and directories located on one server and forms a partial subtree of the shared name space [Sidebotham86]. The distribution of volumes across servers is an administrative decision. To balance the load among a collection of servers, an administrator can migrate busy volumes from one server to another. Volumes that are frequently read but rarely modified (such as system binaries) may have read-only replicas at multiple servers to enhance availability and to distribute server load. Since the name of a file does not depend on the server where it is stored, volume migration and replication improve availability and reduce server load without changes to the user's view of the file system.
Figure 1. An example of the global name space shared by AFS users. 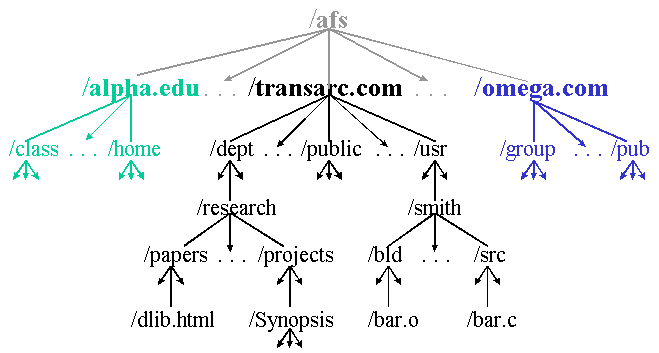
AFS uses an aggressive file caching policy to reduce the network load and access latency [Kazar88]. When a user accesses a file, the wide-area file system first checks the local disk cache for a copy of the file. With a typical file access, a user has a "working set" of files that remains consistent for a period of time. As a result, on average 98% of the requests for file data and 96% of the requests for file status do not require server access [Spasojevic96].
Security in a wide-area file system is founded on an authentication mechanism and secure RPC between servers and clients. While all participating sites have to agree on the common protection and authorization model, each site has full control in implementing individual security policies. AFS uses access control lists for protection. An access control list is a set of pairs; the first item in each pair is a name of a user or a group, and the second is the information regarding the rights granted to that user or a group. Users are allowed to create new groups and also to specify negative rights. This authorization model allows fine grain specification of access control rights for every user and every part of the wide-area file system. For performance reasons the granularity of protection is an entire directory rather than individual files.
AFS supports multiple administrative cells, each with its own servers, clients, system administrators and users. Each cell is a completely autonomous environment. But a federation of cells can cooperate in presenting users with a uniform, seamless file name space. For example, Figure 1 shows a fictitious name space for a federation of three organizations. At the time of writing this paper, more than 149 organizations around the world are part of the publicly accessible AFS wide-area distributed file system and many others participate in corporate federations.
3.0 Characteristics of Use
Organizations that deploy wide-area file system products use them for a variety of purposes. This section describes common file sharing activities among customers of wide-area file system technology. These examples demonstrate three kinds of collaboration that wide-area file system technology facilitates: collaborative administration, focused collaboration, and dissemination of shared information.
3.1 Managing Software Configurations
Managing software configurations in a large enterprise requires significant effort. The task is truly daunting, if the requirement is that a user can sit at any machine anywhere in the internationally distributed organization and operate in the same application and data environment.
One way to ensure uniformity is to install all software on the disk attached to each computer. Tools to replicate files and disk images simplify this task for small organizations. However, for large distributed enterprises the administrative overhead of ensuring consistency among all systems is significant, and there will always be periods where there are inconsistencies between machines that violate the uniformity requirement.
In contrast, an enterprise-wide software repository stored in a wide-area file system provides a single point of administration, and instant access to new software configurations. Rather than install software on the local disk of each computer, the package is installed in the shared file system. The file system cache on each machine notices the change, flushes the old version, and loads the new. At no time is the uniformity requirement is violated.
While a shared software repository simplifies the problem of deploying software configurations, it does not help administrators decide what should be contained in the repository. Dependencies between packages -- e.g., applications that require a particular version of the operating system to work correctly -- complicates the process of deciding what software can be removed from the archive. Once the decision is made to remove a package, the administrator must identify the various pieces of the package. This is complicated by the common approach to installation where files are placed in several different directories; i.e. binaries in one, libraries in another, and documentation in a third. Third-party installation utilities solve some of these problems through an application specific "Uninstall" facility.
3.2 Software development
Wide-area file systems provide a solid foundation for managing the data for large group projects. The software development environment at Transarc exemplifies properties of this form of collaboration. Employees from development, system test, documentation, training, and product support groups interact through the file system to design, develop, package, and maintain several software applications. The collection of shared files includes source code, product documentation, training manuals, design notes, software defects, and many other kinds of files.
Figure 2. Relationships between files used to fix a software defect. 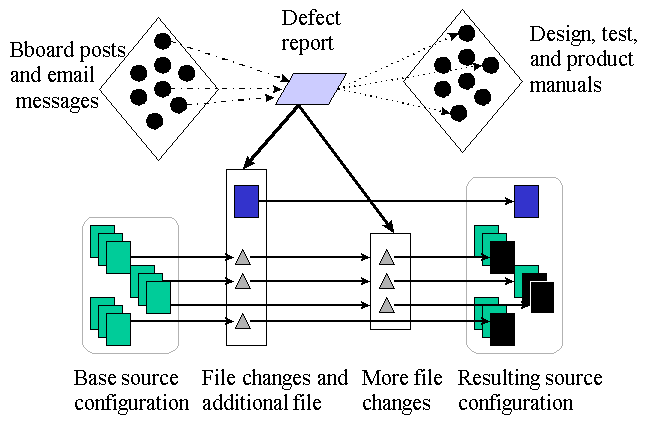
To understand the complexity of interactions in this environment, consider the actions that occur when a customer reports a problem with a product, as shown in Figure 2. First, the support specialist who handles the call creates a defect report and begins to search through product documentation, release notes, and other defect reports for similar problems. Since many of the repositories of information available to the support specialist are not designed for finding solutions for software defects, locating relevant documents is a complex and time consuming process. If there are no documents that describe solutions to the defect, the support specialist might post a request to a bulletin board asking for help. As a last resort, the defect is handed to the development organization for investigation.
The developer who receives a defect report retrieves the source files from which the customer's software was created. However, since the files that contain source for a product are constantly being revised as defects are fixed and features are added, the files used to build a particular product must be reconstructed. To manage these changes, Transarc uses a version control system that tracks changes to individual source files. Since changes to a single file often leave the system in an inconsistent state, the version control system identifies batches of changes that take the collection of source files from one stable state to another.
To fix the defect, the developer examines the defect report and any explanatory material that is associated with it, initiates a change in the state of the product source code, fixes the problem, and indicates that the new state is stable. Since developers frequently change the same files in parallel, it is necessary to merge stable states. The developer responsible for the merge examines the changes, initiates a state change, resolves the conflicts, and marks the state as stable.
At this point, the newly created stable state is given to the system test group and, if it passes the regression tests, to product engineering where a patch is created. The patch is added to the repository of patches and the original product support specialist is notified. When the customer finally retrieves the patch, the defect report is marked "closed".
The participants in this process make extensive use of the shared file system. All relevant documents are stored as files (including bulletin board posts). Developers use a personal "sandbox" to modify files so that stable versions of the source code are isolated. System test and product engineering receive references to stable configurations of the source code.
3.3 Corporate Information
A corporation generates large quantities of information that it disseminates to employees. Handbooks, earnings statements, expense reports, presentations, minutes of meetings, white papers, and many other pieces of information represent a large corpus of data with diverse formats, access restrictions, and distribution characteristics.
Electronic mail is one way to provide this information to employees. As push technology, electronic mail is useful as a notification agent. However, several benefits come from archiving corporate information in a wide-area file system. First, keeping a single copy of each file in the file system is more efficient than keeping a copy on each machine. Second, file system administrators ensure that backups are performed regularly. Most users, however, do not backup files consistently. Finally, access controls placed on files ensure that confidential information is protected from unauthorized access. As with backups, file system administrators can create drop-off locations for files that require special protection so that users need not worry about writing the correct access controls.
Many organizations now use HTTP servers to disseminate corporate information [Rein97]. The presence of a universally accessible shared file system simplifies document publishing (especially when the HTTP server is configured to pull documents directly from the shared file system) and allows some of the load for accessing documents to be off-loaded to the file system. In particular, requests for files can be handled efficiently by the file system [Spasojevic94]. The HTTP server continues to process requests for dynamic documents such as the output of CGI scripts and files merged with server-side includes.
4.0 Issues and Challenges
The collaborative activities listed in the previous section demonstrate the viability of wide-area file systems as a foundation for collaboration. However, there are limitations in the file system interface that affect the construction and integration of tools for collaboration. In particular, file system technology focuses on robust and efficient storage and archival of files, but provides very few facilities for handling content. This section lists several issues commonly faced by those building and using tools for collaboration.
4.1 Scale
Enterprise computing is the primary domain for wide-area file systems. As a result, deployed file systems are typically very large. For example, the 450 employees of Transarc access 830 gigabytes of shared files from several offices in the United States and two international offices. The collection of files at Transarc is one of 149 collections available through the public AFS name space. During studies three years ago (when the number of participating organizations was 80) the total amount of file system data available through AFS was measured to be approximately 5 terabytes [Spasojevic96].
Scale introduces many system-level problems -- e.g., performance and reliability-that are addressed by the underlying technology. However, user-level problems remain unaddressed. In particular, finding files is a key limitation to collaboration. Name space manipulation -- placing a file in a particular directory -- is the only method that the file system provides to simplify file location. While this approach works well for managing small collections, there are limitations to its usefulness for organizing large collections.First, the name space in an enterprise-wide file system is vast. User directories at Transarc start four directories deep. Product development source trees frequently reach depths in excess of ten directories. In this environment, finding files through interactive browsing is extremely difficult without additional information.
Second, since a file can be placed only in a single directory, its location in the name space can represent only one aspect of the file. This restriction frequently causes problems when collections of related files must be placed in separate directories to accommodate existing hierarchies, as is the case when installing many software packages. Documentation is placed in one directory, binaries in another, shared libraries in a third, and configuration files in a fourth. This occurs because the system administrators deem that the most useful organization requires placement of all binaries in a single directory. Without additional resources, it is difficult to find all components of the application once it is installed.
Finally, the top levels of the name space contain very little information that is useful for finding a file. Frequently, file systems divide the top level of the name space according to organizational boundaries. From the file system perspective, this division is necessary to distribute administrative responsibilities. From the user's perspective, this division potentially forces files with semantic similarities into different parts of the hierarchy. To find a file, a user must know more than just "what it is" or "what it does"; she must also know what organization is responsible for it.
4.2 Internal Structure
The traditional file system interface treats files as untyped byte streams. However, we observe that most files have an identifiable structure determined by format and role. The format of the file is a grammar that represents the physical layout of information in a file. The role associates a particular vocabulary with the grammar. For example, a word processing application defines a particular file format, but a given file can contain a letter, an article or a book.
There are degrees of disparity among files in both format and role. There are many application-specific formats for a calendar, but the common role implies a fundamental set of operations that are shared by all: list appointments, read an appointment, and write an appointment. Applications often specialize the role; i.e. add operations to the interface. Likewise, there are many different kinds of documents-letters, journal submissions, books -- that can be represented by a single file format like LaTeX.
In the file system, both format and role are often layered. From the perspective of an application that sends and receives electronic mail, a message contains a structured header and an unstructured body. However, the body itself may be MIME encoded as multiple parts, each with a particular format. Packaging, compression, and encryption applications are other common examples where layering is used.
4.3 Heterogeneity
Any time files are shared, heterogeneity introduces the problem of mapping data to applications. To avoid multiple conversions, two people who collaborate to write a paper choose a common application that will be used to format the paper. Wide-area file systems enable hundreds of thousands of users from universities, government labs, financial institutions, and other commercial organizations to share files through a single uniform name space. Agreements among users for hardware, applications, formats, and organization are impossible. As a result heterogeneity is prevalent in many forms:
The information in a file system is stored in diverse formats. While there is some motivation to choose applications similar to those used by others in the community, user preferences and task-specific requirements typically lead to diversity even among small groups. The proliferation of applications implies a rich set of data formats. Similarities in semantic content are not necessarily reflected by similarities in syntactic representation. For example, while the basic content of two spreadsheets may be identical, the file format depends on the particular program.
There are many ways to use a file. Although there is an implicit type associated with most files, the file system interface does not constrain the way applications manipulate a file. It is possible to run a program that expects input files of one type on files that do not have the correct format. While the results are unpredictable, the power of the file system interface is that unpredictable results might still be useful. Although there are many examples of users changing binary files with an editor, the most common situation is that a file partially conforms to the expected format. For example, during the development of a program, the value of an application that identifies references between modules is not lessened when syntax errors in the source code files result in a small number of incorrect references. 4.4 Implicit Relationships
Extensive use of relationships between files is a common property of the collaborative activities that we observed in the wide-area file system. There are many kinds of relationships that exist among files such as the relationship within administrative units, explanations, dependencies between files or file sets, derivation of one file from another, and equivalent representations.
Collections of files are often grouped into packages that represent a single administrative unit. Co-locating the files in a directory specifies a grouping relationship between the files. However, this facility is not sufficiently expressive to accommodate the kinds of multiple-use relationships that exist. For example, when installing an application, documentation is often placed in a directory distinct from the directory in which the binaries are placed. With only directory placement as a grouping mechanism, there is no way to represent the common origination of the documentation and binaries.
Dependency relationships between files occur when access to a file or a group of files depends on the availability of another collection of files. The most simple example is the relationship between a data file and the associated application. Complexity in dependency relationships occurs when applications require a particular environment for correct operation such as a particular version of the operating systems, third-party libraries, or configuration data files. Understanding dependency relationships is an important problem in application deployment.
A common operation with files is the application of a program to one file in order to generate another. For example, a compiler creates an object file when applied to a file that contains program source and a linker merges a collection of object files into an application or a shared library. The "derived-from" relationship chronicles the history of a file and is used to track software defects to the source and to reconstruct missing files.
Annotations -- i.e. files that explain or expound the content in another file -- occur in many forms in a wide-area file system. A reply message annotates the original message. A group of messages that contain interactions between a company and a particular customer serves as an annotation for a sales report. The document that describes the design of a software component provides additional detail for a series of changes to the source of a program.
As with traditional digital libraries, file systems must accommodate alternate representations of a document. For example, enterprise-wide computing frequently involves heterogeneous hardware architectures. To simplify application deployment, system administrators prefer a single name space for all architectures. File systems frequently provide context-specific directory names to address this need. For example, in AFS the name "@sys" expands to the name of the hardware architecture of the client machine. On a Sun Sparcstation, the name "/afs/transarc.com/@sys/bin" is equivalent to the name "/afs/transarc.com/sun4c_55/bin". On a personal computer running Windows NT, the same name expands to "/afs/transarc.com/i386_nt35/bin".
Context-specific names accommodate hardware heterogeneity, but provide only limited support for situations where equivalence is less easily identified. For example, many word processing applications can export files in several different formats. Although each exported file is, in a sense, equivalent to the original, the format of the files causes distinct differences in the presentation of the document.
5.0 Digital Library Services
While wide-area file systems score high marks for providing ubiquitous file services, a focus on storage issues ignores the collaborative activities that take place in this environment. To overcome the challenges to collaboration listed in the previous section, it is helpful to view the wide-area file system as a large repository of digital objects that requires both storage and content management.
The file system already provides some of the basic building blocks from which digital libraries are constructed [Kahn95]. A file is a digital object that manages some simple digital material (the contents of the file) and metadata (e.g., the owner and size of the file). Associated with the file are access controls that provide crude limits on how an object is used. The name of the file is a universal handle for the object that identifies the file server where the object resides and the file's location within that server.
Although these basic building blocks provide some of the necessary services, several enhancements are required for managing a large digital library. Our experience building systems that integrate file services with digital library technology suggests that the following list of enhancements is necessary [Bowman94,Bowman96].
First, the file system must accommodate extensible, user-level metadata to represent properties of a file such as its history and relationship to other files. Simple field/value pairs with a limited set of base types (e.g., string, integer, and reference) and constructors (e.g., record, list, and set) provide most of the functionality necessary for the collaborative activities listed in Section 3. However, more expressive representations might be necessary to represent more sophisticated properties of files.
Second, the file system must explicitly type each object. The primary purpose for associating a type with an object is to constrain the metadata stored with the object. That is, the type defines a schema for metadata attributes. The type also provides information about the operations that can be performed on an object. For example, the data file for a calendar application supports operations such as "Add Appointment". In this way, the type system makes files self-describing.
Through the use of relationships between types, the type system can accommodate the diversity of format that accompanies federated systems with minimal loss of interoperability. In particular, our experience suggests that the use of inheritance to relate types is a powerful tool for providing best-effort interoperability within federated systems [Bowman97]. Inheritance enables the specification of a common role for files with different format. The role of the file determines the schema in a base type. Each format is managed by a subtype of the role where the implementation of the operations depends on the format of the file. In addition, inheritance represents specializations among types. A specialization is a type that customizes the basic structure of another type. Within the file system, this happens frequently when one application assumes a structure within a region of a file considered unstructured by another application that operates on the file. For example, a compiler throws out any comments that are contained in a file. The application that manages the development environment, however, assumes a structure for the initial comments in the file and extracts function references, author names, and modification history.
Meta-objects constitute the third enhancement of the file system interface. Kahn and Wilensky use the term meta-object to refer to an object whose primary purpose is to store and manage references to other objects [Kahn95]. There are many uses for meta-objects in the file system. A meta-object contains references to all of the files that are part of a software package. Dependencies between packages are represented by dependencies between meta-objects. A meta-object contains references to the files that belong to a software development configuration. Another meta-object might refer to the set of changes that are required to translate one configuration to another. Finally, meta-objects are useful for managing the multiple, equivalent representations of a file [Daniel97].
Identification and retrieval of objects through queries on the digital material and metadata dramatically simplifies file location and is the final enhancement to the file system interface. One use of the service is to integrate file location with file system browsers and shells. For example, the Semantic File System embeds queries within the name of a directory [Gifford91]. Any application can easily find files within a directory tree by creating a directory whose name is the query. Search embedded within applications is another use of this service. Consider an alternative to mailbox folders where meta-objects with an associated query represent dynamic views on a collection of messages. Rather than copy a message into each relevant folder, the meta-objects contain a reference to a single copy of the message This approach supports multiple classification of messages without adding the administrative overhead of managing multiple copies of each message.
The diversity of file types and metadata complicates the integration of services for content-based retrieval with the file system interface.Specifically, vast differences in the type and use of metadata imply that no single, standard interface for content-based access to files will be sufficient for all types. For example, metadata typically associated with an HDF file that contains satellite telemetry data is numeric, highly structured, and will be used to generate specialized browse structures. In contrast, metadata associated with an HTML file is textual and is used primarily for full-text retrieval. Further, access controls pose an additional performance problem for information retrieval because the number of required authorization checks is large.
6.0 Demonstration
To demonstrate the viability of integrating file system and digital library technology, we implemented an object-oriented extension to the file system called Synopsis [Bowman96]. The traditional file system interface is augmented with a uniform, logical interface for secure, scaleable, distributed information sharing. In addition to traditional untyped files, Synopsis defines an interface to a typed file object called a synopsis. The file system uses static directories to group similar files. Synopsis defines a meta-object, called a digest, to classify synopses dynamically. A digest is very similar to a database view. Path names serve to identify files. To discover files, Synopsis adds content-based addressing through queries on synopsis properties. For operational encapsulation, Synopsis adds method invocation on a synopsis as a way of accessing a file.
In Synopsis, the metadata associated with the file object is represented by a collection of attributes. The attributes associated with a synopsis are partitioned into two sets, search and state, according to purpose. The purpose of search attributes is to store metadata useful in finding and classifying the file. Typically, search attributes are derived from properties of the file -- hence the name "synopsis" implies that the file object is intended as a summary of the file. The purpose of state attributes is to store information that is necessary for method implementation. Minimally, the state contains information about the type of the synopsis, its identifier, access controls, and the associated file.
Synopsis is currently deployed within Transarc. It manages approximately 200,000 files which include program source, product documentation, Web pages, news postings, customer information files, and defect reports. Through a secure HTTP gateway, customers, consultants and product support specialists invoke methods on synopses approximately 10,000 times each week to solve critical (and not-so-critical) customer issues.
In addition to the file location services provided by the HTTP gateway, we implemented several applications that simplify the interface to legacy source code control software, improve processing of electronic messages, and integrate diverse scientific data files. We implemented task and annotation services that simplify information sharing across all applications. Clients of the annotation service use it to leave hints about the relationships that exist between documents.
Other systems attempt to enhance the file system interface with content-management services. The Semantic File System (SFS) uses types to identify transducers that extract and index document summaries to improve file location [Gifford91]. Garlic uses typed object wrappers that are similar to a synopsis to hide heterogeneity among a collection of data sources (including files) [Roth97]. Shore is an object database that provides a shell extension for legacy access through a file system interface [Carey94].
7.0 Conclusions
In conclusion, it is our belief that synergy between file system and digital library technology will dramatically improve wide-area collaboration. Wide-area file systems use mature, distributed systems technology to provide robust and efficient information sharing. Benefits like ubiquitous availability, single source administration, and expressive access controls ensure a solid foundation on which to build collaborative environments. The dependence of several large, internationally distributed organizations on wide-area file systems validates this claim.
However, file system technology provides no explicit support for managing content. As a result, each collaborative application re-implements certain content management services or places the burden of managing content on the end user. Integrating information from several applications is difficult because the implementation of most application-specific services for managing content are hidden within the application itself.
For this reason we turn to digital library technology and the middleware services it provides for building and managing collections of digital objects. Services such as content-based file location, strongly typed objects, representation of complex relationships between documents, and extrinsic metadata solve problems that limit collaboration in file systems. A key feature of the digital library approach is that it is fully general. That is, the metadata and document location services can be applied to many kinds of data and offer a way to integrate various document management applications.
Our experience with Synopsis and its deployment within Transarc suggests that the integration of file system and digital library technology reduces the time to develop collaborative applications and significantly improves integration of information from multiple repositories. The storage and content management middleware services provided by Synopsis blur the distinction between applications and the underlying information substrate; that is, in Synopsis the information becomes the application.
8.0 References
[Bowman94] Mic Bowman, Chanda Dharap, Mrinal Baruah, Bill Camargo and Sunil Potti. A File System for Information Management. Proceedings of the Conference on Intelligent Information Management Systems. Washington, DC. June, 1994. [Bowman96] Mic Bowman and Ranjit John. The Synopsis File System: From Files to File Objects. Workshop on Distributed Object and Mobile Code. Boston, Massachusetts. June, 1996. Available as http://www.transarc.com/~trg/papers/omgw3.html. [Bowman97] Mic Bowman. "Managing Diversity in Wide-Area File Systems". Appeared in IEEE Metadata '97 Conference. Greenbelt, Maryland. September 1997. Also available as http://computer.org/conferen/proceed/meta97/papers/mbowman/mbowman.html. [Carey94] Michael J. Carey, David J. DeWitt, Michael J. Franklin, et. al., Shoring Up Persistent Applications, ACM SIGMOD International Conference on Management of Data. Minneapolis, Minnesota. May 1994. [Daniel97] Ron Daniel and Carl Lagoze. Extending the Warwick Framework: From Metadata Containers to Active Digital Objects. D-Lib Magazine, November 1997. Available as http://www.dlib.org/dlib/november97/daniel/11daniel.html. [Gifford91] David Gifford, Pierre Jouvelot, Mark Sheldon, and James O'Toole, Jr. Semantic File Systems. Proceedings of the Thirteenth ACM Symposium on Operating Systems Principles. October 1991. [Howard88] J. H. Howard, M. L. Kazar, S. G. Menees, D. A. Nichols, M. Satyanarayanan, R. N. Sidebotham, and M. J. West. Scale and performance in a distributed file system. ACM Transactions on Computer Systems, 6(1), February 1988. [Kahn95] Robert Kahn and Robert Wilensky. A Framework for Distributed Digital Object Services. May 1995. Available as http://WWW.CNRI.Reston.VA.US/home/cstr/arch/k-w.html. [Kazar88] M. L. Kazar. Synchronization and caching issues in the Andrew File System. Proceedings of the Winter 1988 Usenix Conference. Usenix Association, January 1988. [Rein97] Gail Rein, Daniel McCue, and Judith Slein. A case for document management functions on the Web. Communications of the ACM, 40(9), September 1997. [Roth97] Mary Tork Roth and Peter Schwarz. Don't Scrap It, Wrap It! A Wrapper Architecture for Legacy Data Sources. Proceedings of the 23rd VLDB Conference. Athens, Greece. 1997. [Sidebotham86] R.N. Sidebotham. Volumes: The Andrew File System data structuring primitive. In European Unix User Group Conference Proceedings, August 1986. [Spasojevic94] Mirjana Spasojevic, Mic Bowman, and Alfred Spector. Using a wide-area file system within the World-Wide Web. Second International World-Wide Web Conference. Chicago, Illinois. October, 1994. [Spasojevic96] Mirjana Spasojevic and M. Satyanarayanan. An empirical study of a wide-area distributed file system. ACM Transactions on Computer Systems, 14(2):200-222, May 1996. [Spector89] Alfred Spector and Mike Kazar. Wide-area file service and the AFS experimental system. Unix Review, 7(3), March 1989.
Copyright © 1998 Corporation for National Research Initiatives
Top | Magazine

Search | Author Index | Title Index | Monthly Issues
Previous Story | Next Story
Comments | E-mail the Editorhdl:cnri.dlib/february98-bowman